 Python言語のエコシステムは急速に成長しています。 もはや単なる汎用言語ではありません。 これにより、Webアプリケーション、システムユーティリティなどを正常に開発できます。 このノートでは、別のアプリケーション、つまり科学計算に引き続き集中します。
Python言語のエコシステムは急速に成長しています。 もはや単なる汎用言語ではありません。 これにより、Webアプリケーション、システムユーティリティなどを正常に開発できます。 このノートでは、別のアプリケーション、つまり科学計算に引き続き集中します。
数学的なパッケージから通常必要とされる関数を言語で見つけようとします。 MATLAB、Maple、Mathcad、Mathematicaの代わりにpythonを使用するというアイデアの長所と短所を考慮してください。
開発環境
Pythonコードは、拡張子が.pyのファイルに配置し、インタープリターに送信して実行できます。 これは、pyCharmなどの開発環境を使用して通常希釈される古典的なアプローチです。 ただし、Pythonには( だけでなく )インタープリターと対話する別の方法があります-インタラクティブなjupyterメモ帳は、ランダムな順序で実行できるコードのさまざまなブロックの実行の間、プログラムの中間状態を保持します。 この相互作用の方法はMathematicaノートブックから借用されました;後に、アナログがMATLABに登場しました(ライブスクリプト)。
したがって、Pythonコードでのすべての作業はブラウザーに転送されます。 作成されたノートブックはnbviewer.jupyter.orgを使用して開くことができ、 github (およびgist )はそのようなファイルのコンテンツを独立して表示(変換)できます。
その不利な点は、jupyterのブラウザーの性質に由来します。デバッガーの欠如と多くの情報の印刷に関する問題(ブラウザーウィンドウのフリーズ)。 最後の問題は拡張機能によって解決され、単一のセルを実行した結果として表示できる最大文字数が制限されます。
データの可視化
データの視覚化には、通常、 matplotlibライブラリが使用されます。このコマンドは、MATLABと非常によく似ています。 スタンフォードで開発されたライブラリは、matplotlib- seaborn (統計用の異常なグラフ)の機能を拡張します。
生成されたデータサンプルのヒストグラムを作成する例を考えてみましょう。
import numpy as np import matplotlib.mlab as mlab import matplotlib.pyplot as plt # example data mu = 100 # mean of distribution sigma = 15 # standard deviation of distribution x = mu + sigma * np.random.randn(10000) num_bins = 50 # the histogram of the data n, bins, patches = plt.hist(x, num_bins, normed=1, facecolor='green', alpha=0.5) # add a 'best fit' line y = mlab.normpdf(bins, mu, sigma) plt.plot(bins, y, 'r--') plt.xlabel('Smarts') plt.ylabel('Probability') plt.title(r'Histogram of IQ: $\mu=100$, $\sigma=15$') # Tweak spacing to prevent clipping of ylabel plt.subplots_adjust(left=0.15) plt.show()
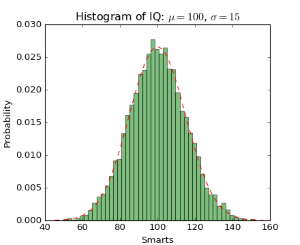
matplotlibの構文は、MATLABの構文と非常に似ていることがわかります。 また、チャートのタイトルにラテックスが使用されていることにも注意してください。
計算数学
Pythonの線形代数の場合、組み込みのリスト言語とは対照的に、 numpyを使用するのが慣習であり、そのベクトルと行列は型指定されています。 科学計算には、 scipyライブラリが使用されます。
特にMATLABユーザーのために、MATLABからnumpyへの移行に関するガイドが書かれています。
import scipy.integrate as integrate import scipy.special as special result = integrate.quad(lambda x: special.jv(2.5,x), 0, 4.5)
この例では、区間[0,0.45]のベッセル関数の特定の積分の値が、QUADPACKライブラリー(Fortran)を使用して数値的に計算されます。
キャラクターコンピューティング
sympyライブラリを使用して、文字計算を使用できます。 ただし、sympyで記述されたコードは、シンボリックコンピューティングを専門とするMathematicaで記述されたコードよりも美しさが劣ります。
# python from sympy import Symbol, solve x = Symbol("x") solve(x**2 - 1)

SympyはMathematicaよりも機能が劣りますが、ニーズによっては、機能がほぼ同等であることが判明する場合があります。 より詳細な比較はsympyリポジトリwikiにあります 。
コードを高速化する
C ++に変換してコードを高速化するには、 theanoライブラリを使用して実装できます。 構文は、そのような高速化に対価を払う代償です。次に、theano指向の関数を記述し、すべての変数のタイプを示す必要があります。
import theano import theano.tensor as T x = T.dmatrix('x') s = 1 / (1 + T.exp(-x)) logistic = theano.function([x], s) logistic([[0, 1], [-1, -2]])
LasagneやKerasなどの畳み込みニューラルネットワークのライブラリでは、計算にtheanoを使用します。 また、theanoはGPUコンピューティングによる加速をサポートしていることも付け加える価値があります。
機械学習
Pythonで最も人気のある機械学習ライブラリはscikit-learnです 。これには、すべての基本的な機械学習アルゴリズム、品質メトリック、アルゴリズムの検証ツール、データの前処理ツールが含まれています。

from sklearn import svm from sklearn import datasets clf = svm.SVC() iris = datasets.load_iris() X, y = iris.data, iris.target clf.fit(X, y) clf.predict(X)
通常、表形式のデータ形式(Excel、CSV)からデータを読み込むには、 パンダが使用されます。 ダウンロードされたデータは、メモリ内でDataFrameとして表され、さまざまな操作を適用できます:行(行ごとの処理)とグループ(フィルター、グループ化)の両方。 パンダの主な機能の概要は、プレゼンテーション「 パンダ:主な機能の概要 」に掲載されています (投稿者:Alexander Dyakonov、モスクワ州立大学教授)。
すべてがそれほどスムーズではない...
ただし、Pythonではすべてがそれほどスムーズではありません。 たとえば、言語2 と言語3の2つのバージョンが相まって、両方が並行して開発されていますが、2番目のバージョンの構文は3番目のバージョンの構文と完全に互換性がありません。
Linuxの所有者ではない場合に発生する可能性のある別の問題。この場合、いくつかのライブラリのインストールが困難になる場合があります。一部のライブラリは、たとえばtensorflowなど、完全に互換性がありません。
- Jupyter (オンラインノートブック)
- Matplotlib (チャート)
- シーボーン (チャート)
- ナンピー (線形代数)
- Scipy (サイエンティフィックコンピューティング)
- Sympy (キャラクター計算)
- Theano (C ++への変換、GPUコンピューティング)
- Scikit-learn (機械学習)
- パンダ (データの読み込みとそれらへの簡単な操作)
PS:この記事で説明したすべてのpythonライブラリはオープンソースであり、無料で配布されています。 それらをダウンロードするには、 pipコマンドを使用するか、すべてのメインライブラリを含むAnacondaアセンブリをダウンロードするだけです。