
最近、Habré で DIGITSに関するvfdev -5の 投稿はスキップされました 。 それが何であり、何と一緒に食べられるかを詳しく見てみましょう。 一言で言えば。 これは、5分以内に膝の機械学習タスクの30〜50%を解決できる環境です。 プログラミングスキルなし。 もちろん、ベース付きです。 そして、多かれ少なかれNVIDIAからの適切なカード。
入手先
公式ページ 。 そしてここからすべてが揺れる。 指示があります。 Ubuntu 14およびUbuntu 16で正式にサポートされています。14番目のubuntuおよびdockerにはdebパッケージがあります。 第16回アセンブリー指示の下。 最初にカフェを収集し、次にDIGITSを収集する必要があります。 数時間、どこかで楽しんでください。
3つの言葉は何ですか
DIGITSは、有名なフレームワーク(caffeとTorch 7)の視覚的なフロントエンドラッパーです。 ボックスからグリッドを既知/再トレーニングできます。 多数の準備されたケースがあります。
フォームファクターによると、これはターミナルで実行されるWebサービスであり、ローカルマシンのlocalhost :5000 /アドレスで利用できます。 次のようになります。

何らかの理由で、木星によってキャストされます。 さらに、 TensorBoardのように見えます。 残念ながら、私は彼と比較するためにあまり働いていませんでした。
この奇跡を扱う方法
メインには2つの大きなボタンしかありません。 それらが必要です。 まず、「新しいデータセット」を確認する必要があります。

デフォルトでは、DIGITSは以下のデータセットを使用できます。
- 分類-N個の画像クラスのメンバーシップを認識することを学習します
- オブジェクトの検索-画像内のオブジェクトの長方形の検索を学習します。 明日、この作品に関するより詳細な記事を公開します。
- セグメンテーション-画像のピクセルセグメンテーション 。 チュートリアルがありますが、理解できませんでした。
- 処理-私はそれが何であるかをよく理解していません。 チュートリアルもありません。
最も単純なオプションとして分類を検討してください。

データセットの準備段階では、数百万のリクエストに負担をかけることなく、数字がデータベースを便利な形式に圧縮して、データベースをすばやく処理できるようにします。 原則として、すべてが明確です:
- 左側のブロック-画像がどのフォーマットで準備されるかを説明します。 機械学習の標準ルール:データベースの画像を人が正常に認識できるように見える必要があります。 これ以上でもそれ以下でもありません。
- 右側のブロックはベースについてです。 そこで、ベースの場所を示す必要があります。 DIGITSが噛むことができるデータには2つのタイプがあります。 最初の形式:N個のフォルダー。各フォルダーには独自のクラスがあります。 2番目の形式:イメージはどこにでもありますが、「<path> <class name>」という形式のテキストファイルがあります。 検証用%-トレーニング中のテストにデータベースのどの部分が使用されるか。 テスト用の%-最終テストに使用される量。
- 以下のブロックは、DIGITSが準備するデータベースの形式です。 実際、これはユーザーにとってほとんど問題ではありません。
データベースの作成結果は動的に表示されます 。 また、データベースの最終統計も表示されます。

ベースの作成が完了しました! トレーニングに行くことができます。 メインメニューに移動し、「New Dataset」の代わりに「New Model」を入力します。 再度、分類を選択します。 ここで、パラメーターはわずかに大きくなっています(1,2)。 必ず選択してください:
- [データセットの選択]列の準備されたベース
- 使用済みネットワーク
細かい設定がたくさんあります:
- トレーニング期間の数(ベースが実行される回数)
- 保存とテストの構成
- 降下アルゴリズムのパラメーター:降下速度、トレーニング中の変化
- ネットワークを構成する機能:既存のものを変更することも、独自に設定することもできます
- データセットの最も単純な増分:切り取り、平均の減算
現在のグリッドは次のように表示されます。
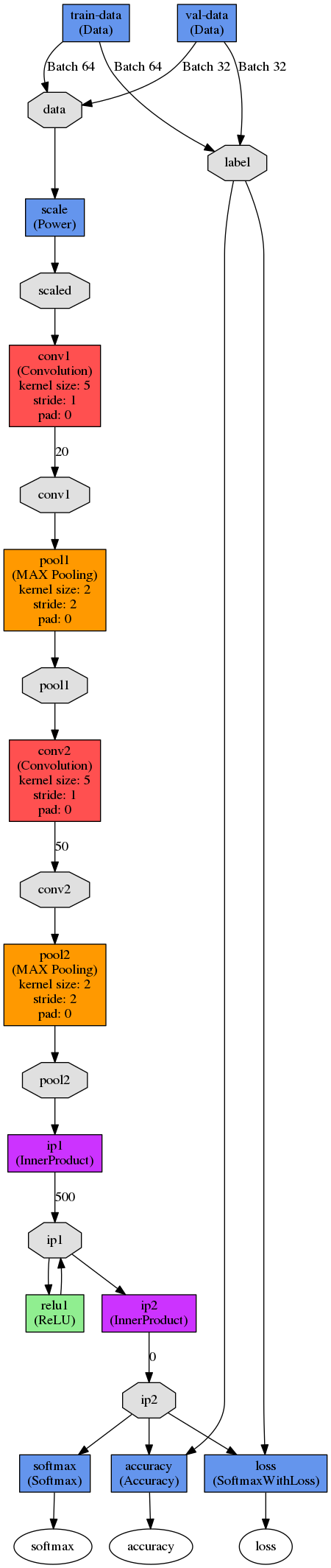
打ち上げ
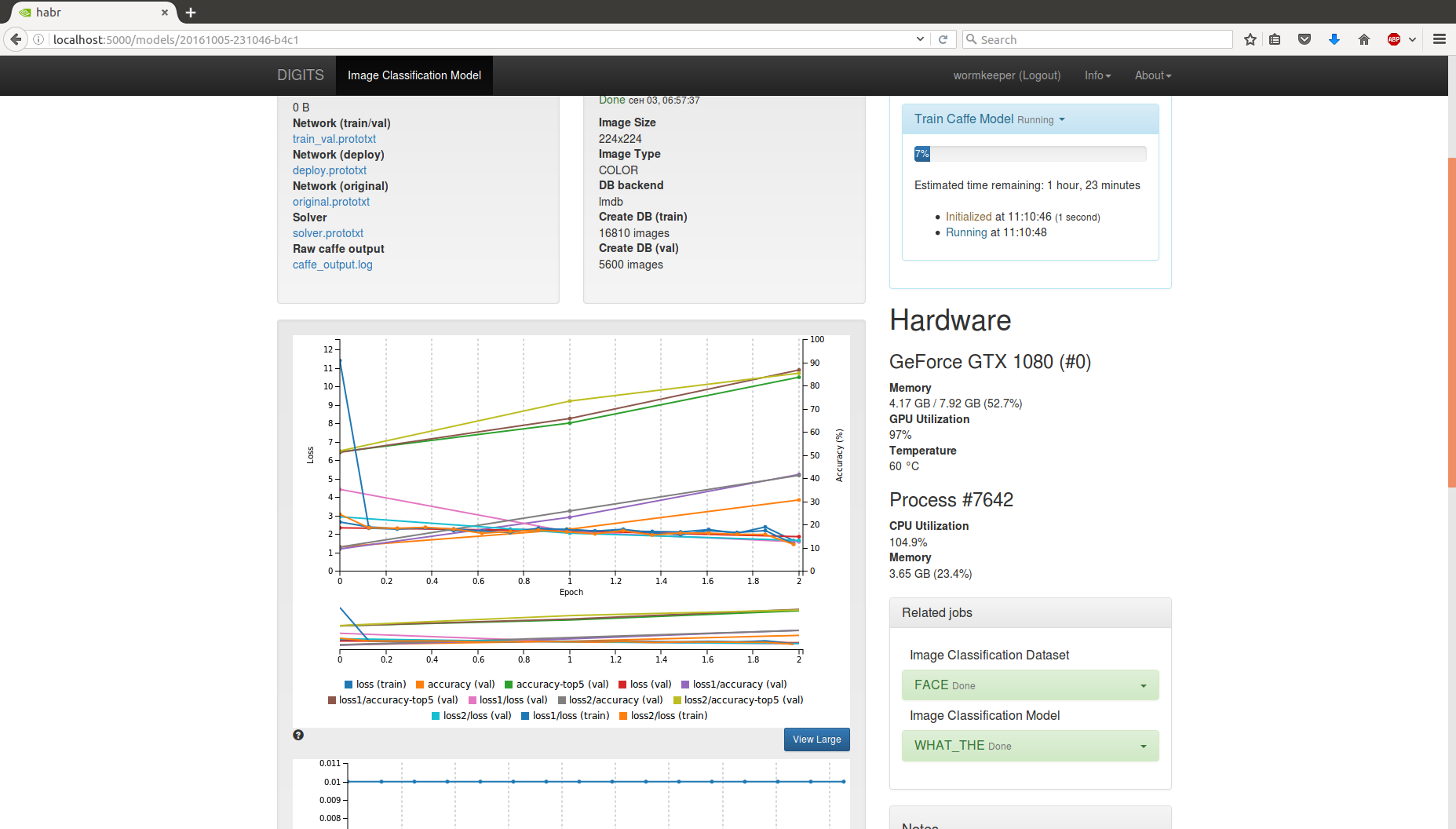
お使いのコンピューターは死んでいます。 しかし、進行中のトレーニング、時間評価、現在の結果などの美しいオンライングラフが表示されます。
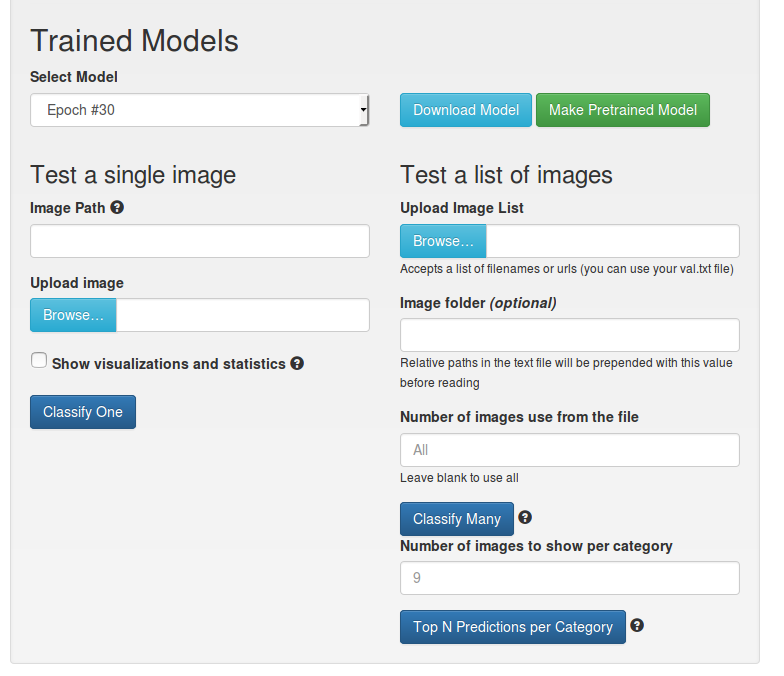
トレーニング後、最終モデルを保存して1つまたは複数の画像を認識できるメニューが表示されます。 統計を作成します。
生産に送ることができます;)
他に何
DIGITSには、オブジェクトの検出に適したメッシュがまだあります(説明: 1、2 )。 明日、彼女のアカウントに別の短い記事を投稿します。 残念ながら、すべてがあなたが望むほど良いわけではありません。


正しいピクセルセグメンテーションを構成することは可能です。 しかし、ソリューションをカスタマイズしました。これはあまり面白くないです。 それで、DICOM画像を扱う全体の例 :
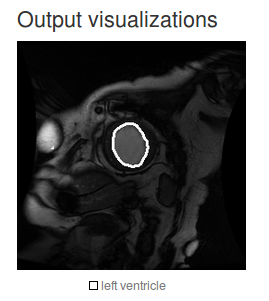
このソリューションは、医療セグメンテーションタスクに適していると位置付けられています。
結論
ニューラルネットワークを操作するために必要な知識のレベルは、台座を徐々に下回っています。 確かに他の類似体があるか、近い将来に表示されます。 同じTensorBoard 。
これは、結果のソリューションが高品質であることを意味するものではありません。 ただし、状況によっては非常にうまく機能します。 もちろん、適切なチューニング、メソッドの選択、ネットワークの手動チューニングにより、パフォーマンスが大幅に向上します。 ただし、プロトタイプを表示するにはDIGITSで十分な場合があります。
私にとって-それは非常に適切なラッパーであることが判明しました。 しかし、彼のnvidiaの何かは特にPRではなく、ほとんどサポートされていません。