
現代のコンピュータビジョンには1つのトピックがありますが、これは多くの場合舞台裏に残っています。 複雑な数学や深い論理はありません。 しかし、それが何らかの方法で照らされていないという事実は、多くの新規参入者をst迷に追い込みます。 しかし、このトピックは単純ではありません。それは、あなたが踏むまで知らない多くの熊手を持っています。
このトピックはそう呼ばれています:さらなるトレーニングのために画像データベースを準備します。
記事では:
- 良いベースを区別する方法
- 良いベースの例
- データベースのレイアウトに便利なプログラムの例
はじめに、最もシンプルで最も愛されている例を示します。車の番号の認識です。 システムをゼロから作成するとします。 この画像で示す必要があるもの:

私の意見では、理想的なオプションは次のとおりです。

ここに注意してください:
- 表示される各番号のフレーム。 キーポイント:数字の角度+その位置を強調する必要があります。
- 表示される各数値の値。 システムは写真を見ている人よりもよく認識しないため、ほとんど見えない数字を示すことはできません。
- 番号内の各文字の位置。
繰り返しますが、これは完璧なマークアップです。 おそらくそれはいくらか冗長ですが、それに基づいて、ほとんどすべてのアルゴリズムを構成/トレーニングできます。 私自身は、解決した問題でこのような詳細なマークアップを行ったことはありません。 通常、あなたが望むものとあなたが力を持っているものとの間には完璧なバランスがあります。
それがどこから来たのか考えてみましょう。 そして、それで十分なのです。 従来の番号割り当てアルゴリズムは次のとおりです。

さらに、各部分は通常、独自のアルゴリズムまたはそれらのグループを担当します。
最初の部分-数字を見つける必要があります。 HaarカスケードまたはHOG記述子を使用して番号の割り当てを実装するとします。 次に、学習アルゴリズムの入力に一連の正と負の例を提出する必要があります。
ポジティブ:

マイナス:

ニューラルネットワークを介して番号検索を実装する場合、ネットワークのトレーニングの目標は次の長方形のセットです。

ご覧のとおり、マークアップしたデータから、両方のオプションを取得するだけです。
番号が見つかったら、処理する必要があります。 繰り返しますが、多くのアプローチがあります。 しかし、一般的に、2番目の部分は「番号の正規化」です。 ここで説明するように、手動で境界を検索するアルゴリズムを作成できます 。

このアルゴリズムはトレーニングを必要としませんが、私たちが持っているデータに従って、作業の質を評価できます。
また、複数のニューラルネットワークをトレーニングできます。 たとえば、最初はコーナーを探し、2番目は作物を探しています。
そしてまた。 マークしたデータは完全に十分です。
パート1とパート2を組み合わせて、数字の検索ネットワークを作成し、数字の角度と回転の両方をすぐに表示できます。 彼女にとっても十分なデータがあります。
原則
マーキングの基本原則を定式化してみましょう。
1.タスクが解決できるすべての可能なアルゴリズムを事前に考えます。 各オプションの入力を定義します。 マークアップの際にそれほど労力を必要としない場合は、入力に関する問題を解決するための既存のオプションを提供するマークアップ形式を考えてください。 可能であれば、マークアップは冗長であることが望ましいです。 それ以外の場合、アルゴリズムが機能しない場合は、最初からやり直す必要があります。
2.マークアップをシンプルで検証可能な形式に保つようにします。 コンピュータービジョンのタスクは、デバッグやバグの検索が非常に難しいことに注意してください。 すべての部分は、単純に視覚化され、目で確認しやすいものでなければなりません。 テキストデータ形式またはグラフィックを優先します。 バイナリ形式、または大量のメタデータを持つ形式は避けてください。 考えられるすべての情報を書き込もう。 たとえば、画像のテキスト名を忘れないでください。 何らかの種類の「ファイル名のリストを取得する」機能を使用する場合、Windows、Linux、C#、Pythonでは、これらのファイルの順序が異なる場合があることに注意してください。
3.マークアップは時間がかかることを忘れないでください。 多くの場合、大きなベースのマークアップには数日または数週間かかることがあります。 単調な労働。 プログラムに必要なものをすべて含めるようにしてください。
データベースの例
MSRAデータセット 。 MSRAは一連のデータセットです。 たとえば、オブジェクト検出を使用したデータセットを取り上げます。 各画像について、この画像内のオブジェクトの境界ボックスが設定されます。
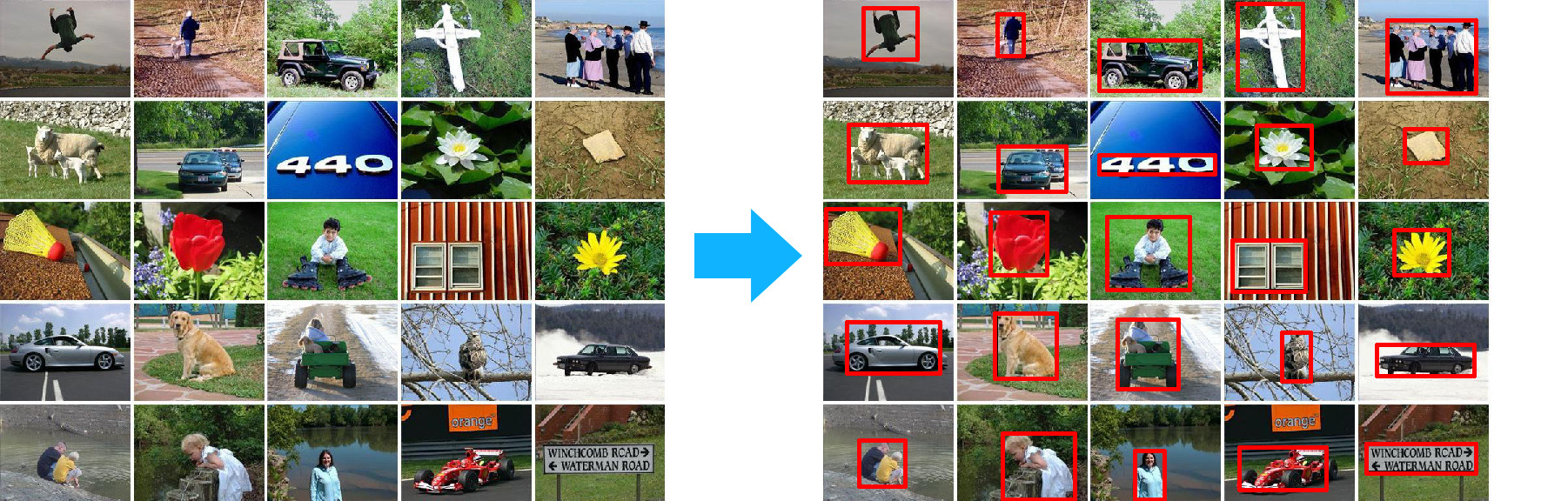
この場合、すべてのパラメーターは次の形式のテキストファイルにあります。
235 - 0\0_101.jpg - 400 300 - 89 10 371 252; 87 9 379 279; 89 11 376 275; - 0\0_108.jpg 400 300 112 4 241 214; 119 0 241 208; 118 0 238 141; .....
さらに、各テキストファイルには、いずれかのクラスのすべてのオブジェクトが記述されています。
VOC2012最も完全なデータセットの1つ。 それは研究目的のために行われました=>彼らはすべてをうまく、高品質で記述しようとしました。 2012年まで、データセットは毎年更新されました(2005-2012)。 記述形式:xml。
すべてのオブジェクトの長方形は、各画像でマークされています。

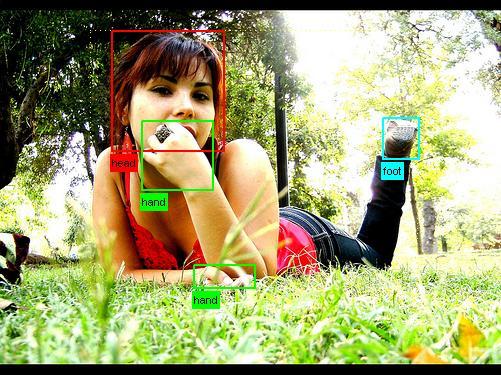
この場合、すべてのデータが書き込まれます。
<annotation> <folder>VOC2007</folder> <filename>000019.jpg</filename> <source> <database>The VOC2007 Database</database> <annotation>PASCAL VOC2007</annotation> <image>flickr</image> <flickrid><owner> <flickrid>Rosenberg1 Simmo</flickrid> <name>?</name> </owner>330638158</flickrid> <source> <size> <width>500</width> <height>375</height> <depth>3</depth> </size> <segmented>0</segmented> <object> <name>cat</name> <pose>Right</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>231</xmin> <ymin>88</ymin> <xmax>483</xmax> <ymax>256</ymax> </bndbox> </object> <object> <name>cat</name> <pose>Right</pose> <truncated>0</truncated> <difficult>0</difficult> <bndbox> <xmin>11</xmin> <ymin>113</ymin> <xmax>266</xmax> <ymax>259</ymax> </bndbox> </object> </annotation>
また、VOCの画像の一部は、クラスに属することで色付けされています。 セグメンテーションの問題( たとえば )には、興味深い領域がマークされる入力画像が必要です。 通常、オブジェクトのタイプは色で設定されます。


この場合、マークアップは本質的に色付けです。
小さな画像を含むCIFAR Researchデータセット。 不都合なデータセットの例。 すべての写真は1つの大きなファイルに収められています。 それらの説明もあります。 ファイルにアクセスするには、PythonおよびMatlabのラッパーがあります。 画像の説明-クラス番号。 データセットには他に何もありません。 データセットはかつて人気がありました。 しかし、設計フォーマットでは失敗しました。 現在では、誰にもめったに使用されません。
ストリートビューの家番号(SVHN)データセット家番号を持つ有名なGoogleデータセット。
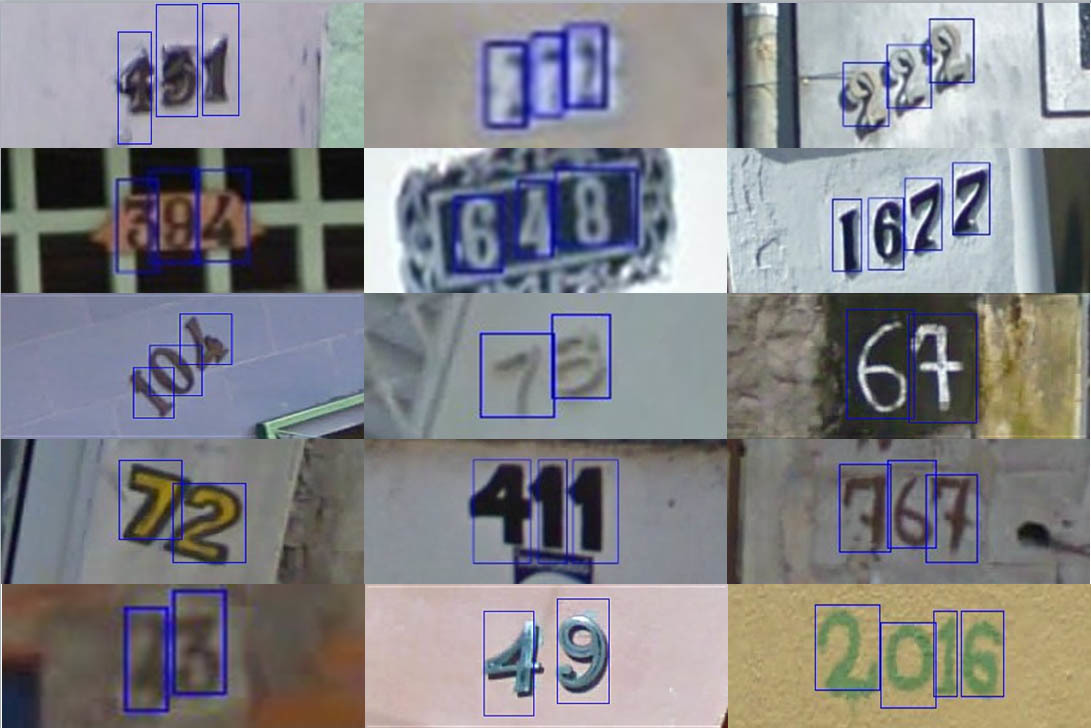
記述形式は、各画像のバイナリmatlabファイルです。 ファイル内で、数値と数値の境界を示す長方形。
MicrosoftのMS COCOデータセット。 おそらく今日の最高の1つです。 構成では、VOCとほぼ同じですが、データが多く、マークアップ情報が多くなります。


情報は、付随するjsonファイルに保存されます 。 注釈を付ける方法の例を次に示します。
annotation{ "id" : int, "image_id" : int, "category_id" : int, "segmentation" : RLE or [polygon], "area" : float, "bbox" : [x,y,width,height], "iscrowd" : 0 or 1, } categories[{ "id" : int, "name" : str, "supercategory" : str, }]
データセットの興味深い瞬間の1つ。 セグメンテーション領域は、それらを塗りつぶす画像ではなく、同じjsonファイルに格納されている閉じた複数行によって定義されます。 これにより、データ量が大幅に削減されます。 マークアップの品質は低下しますが。
2番目のポイント-各写真について、何が起こっているのかをテキストで説明します。
The Citycapes Dataset純粋にセグメンテーションタスクのデータセットのセット:路上で起こっていることをマークアップします。 各画像について、マークアップ付きの2番目の画像。 別のファイルで、各色の意味の説明。

kaggle kaggleには多くのデータセットがあり、それらはタスクごとに常に異なります。 これは、データセットの作成方法の例です。 すべてのデータセットは可能な限りシンプルです。 クラスは10個ありますか? ここでは、彼らは不必要なテキストのないパパにいます。 何かを発見する必要がありますか? セグメンテーションマークアップは次のとおりです。
IMAGENET巨大でありながら優雅なデータセット。 正直なところ、私は最終的に彼に利用可能なすべての説明を理解することができませんでした。 ほとんどの説明はmatファイルにあります。 認識タスクでは、表示されたデータの分類が必要です。 そこで、クリエイターは各画像の完全な分類を行うことにしました。

動物→脊索動物→脊椎動物、頭蓋類→鳥→オウム→アフリカ灰色。 -画像の記述形式。
フェイスポイント上のデータセットのセット 。 説明の形式は異なりますが、ほとんどの場合、顔のすべてのポイントの座標のテキスト値のみが与えられます。

http://www.absolutely.net/wenn/handy_manny_05_wenn5360250.jpg worker_2 205.056122449 274.885204082 0 409.147959184 276.691326531 0 287.535714286 291.441326531 0 336.903061224 295.956632653 0 249.306122449 268.864795918 0 249.005102041 281.507653061 0 371.821428571 274.283163265 0 373.928571429 282.410714286 0 227.734693878 307.787755102 0 388.840816327 304.416326531 0 273.489795918 309.473469388 0 340.195918367 309.714285714 0 250.371428571 298.636734694 0 252.779591837 314.771428571 0 362.168 296.06 0 365.72244898 312.844897959 0 252.297959184 305.13877551 0 363.073469388 301.526530612 0 275.655102041 378.605612245 0 352.23877551 377.945408163 0 327.151020408 376.625 0 315.92755102 393.790306122 0 244.620408163 413.645918367 0 359.391836735 417.219387755 0 311.255102041 419.11122449 0 310.204081633 424.996938776 0 308.102040816 438.239795918 0 311.044897959 453.794897959 0 118.526530612 259.768877551 0 446.133 275.046 0 145.594897959 364.081122449 0 438.369 380.507 0 142.954081633 321.828061224 0 435.781 330.688 0 317.351020408 518.537755102 0
CASIAの一連の生体認証データセット 。 ここではすべてが非常に簡単です。 生体認証アルゴリズムのデータセット。 一人一人に個別のパパがいて、その中にすべてがノートのように配置されています。異なるスペクトル、多くのアプローチです。
KITTI車から取得したさまざまなデータセットのセット。 各画像について、説明付きの独自のテキストボックス:
Pedestrian 0.00 1 1.43 694.62 175.43 703.96 201.82 1.74 0.75 0.64 5.98 1.92 48.22 1.55 Van 0.00 1 2.15 68.34 174.12 189.52 222.12 1.94 1.88 5.30 -21.22 2.03 32.10 1.57 Misc 0.00 1 2.06 184.58 181.15 230.79 211.99 1.54 0.85 2.84 -20.97 1.97 37.62 1.56 Car 0.00 0 2.01 221.83 183.54 302.47 223.76 1.48 1.61 3.39 -13.87 1.93 28.89 1.56 Car 0.00 1 2.07 168.24 186.13 265.38 223.54 1.44 1.79 4.32 -16.76 2.04 30.95 1.58
説明-優れたデータセットの例。 ここですべてが設定されます:オブジェクトがどれだけ重なるか、オブジェクトの境界。 オブジェクトがカメラの方向にどれだけ回されているか、オブジェクトの実際の深さはどれくらいですか。 しかし、私が理解しているように、ほとんどの研究者はオブジェクトのフレームの座標のみを使用します。
長方形のマークが付いた画像に加えて、データセットには多くの興味深い情報があります。 道路環境用のステレオペアがあります。
各フレームには光学ストリームがあり、各ポイントで移動の方向と速度をエンコードする色を設定します( 1 )、( 2 ):

このデータセットには、多くの興味深い明確な情報が含まれています。
ここには触れていないデータセットがたくさんあります。 それらを結合する主なもの:データセットが深刻な場合-それはよくできています。 彼と仕事をするのは便利です タスクのデータセットを作成するときは、忘れないでください。
オペレーターの利便性
ベースにマークを付けていない場合でも、マークアップするオペレーターの利便性を忘れないでください。 オペレーターの利便性=速度+マークアップ品質。 以下にいくつかの提案を示します。
•キーボードで可能なすべての操作を複製してみてください。 画像内のオブジェクトを選択する操作のみをマウスに残します。 これにより、作業の速度が向上する場合があります。
•常に作業を続けます。 プログラムメモリに保管しないでください。 多くの場合、マークアッププログラムは膝の上に書かれているため、クラッシュする可能性があります。 5,000個のタグ付き画像を失うのは残念です。
•タグ付きデータを編集できるようにします。 間違いは避けられません。
•オペレーターに余分な道具を与えないでください。 すべてがシンプルで、すべてのコーナーが切り取られている必要があります。 3種類のオブジェクトがありますか? 10種類をマークできるプログラムをオペレーターに提供する必要はありません。 あなたのモットーは「必要と充足のみ」です。
いくつかの例
ここで、さまざまなタスクで使用したいくつかの例を示します。 画像を操作するためのEmguCVプラグインを使用してC#+で作成されています(冗長であることは知っていますが、簡単でした)。
リポジトリには2つのプログラムがあります 。1つはセグメンテーションタスクの画像の色付け用、もう1つは四角形の描画用です。 超自然的なものは何もありませんが、誰かが必要とするかもしれません。
その他
Yandex-Tolokサービスが気に入った。 部分的に、彼はベースをマークする問題を解決できます。 しかし、そこに記述されているすべてが強いわけではないことを言わなければなりません。
コメントの少し下のvfdev-5は、マークアップにはまだ悪いことではなく、 このアプリケーションが適していると言っています。