過去6か月間、私はこの経験を体系化するデータ視覚化アルゴリズムに取り組んできました。 私の目標は、数学的な問題と同じくらい明確かつ一貫して、あらゆるデータを整理し、データの視覚化タスクを解決できるレシピを提供することです。 数学では、リンゴやルーブルを積み重ねたり、ウサギを箱に入れたり、広告キャンペーンの予算に入れたりすることは重要ではありません。加算、減算、除算などの標準的な操作があります。 意味と一意性を考慮しながら、あらゆるデータを視覚化するのに役立つ汎用アルゴリズムを作成したいと思います。
私の研究結果をHabrの読者と共有したいと思います。
問題の声明
アルゴリズムの目的:特定のデータセットを視覚化して、視聴者に最大限の利益をもたらします。 最初のデータ収集は背後で行われ、入力には常にデータがあります。 データがない場合、データを視覚化するタスクはありません。
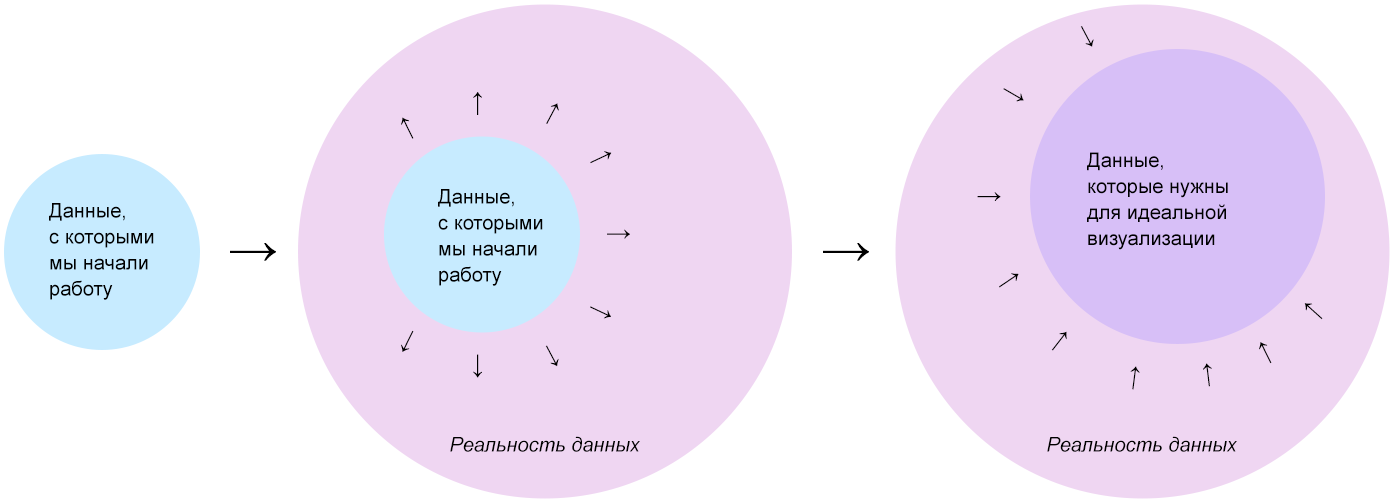
データの現実
通常、データは複数のテーブルを組み合わせたテーブルとデータベースに保存されます。 すべてのテーブルは、それらに基づく円グラフ/棒グラフのように同じように見えます。 すべてのデータは一意であり、それらには意味があり、内部階層に従属し、関係に満ちており、パターンと異常が含まれています。 表は、データの背後にある完全な全体像のスライスとレイヤーを示しています-私はそれをデータの現実と呼びます。
データの現実とは、データを生成するプロセスとオブジェクトの集まりです。 高品質の視覚化のための私のレシピ:データの現実を最小限の損失(メディアの制限により避けられない)でインタラクティブなWebページに転送し、スライスとレイヤーのセットからではなく、全体像からの視覚化に基づいて構築します。 したがって、アルゴリズムの最初のステップは、データの現実を想像して記述することです。
説明例:
バスは公共交通機関で乗客を運びます。 ルートはストップで構成されており、1日に複数のフライトがルート上で実行されます。 各フライトのルートスケジュールは、ストップの到着時間によって設定されます。 各瞬間に、各「車」は、座標、速度、搭乗する乗客の数、およびどのルートでどのフライトを実行し、どのドライバーが運転しているかを知っています。
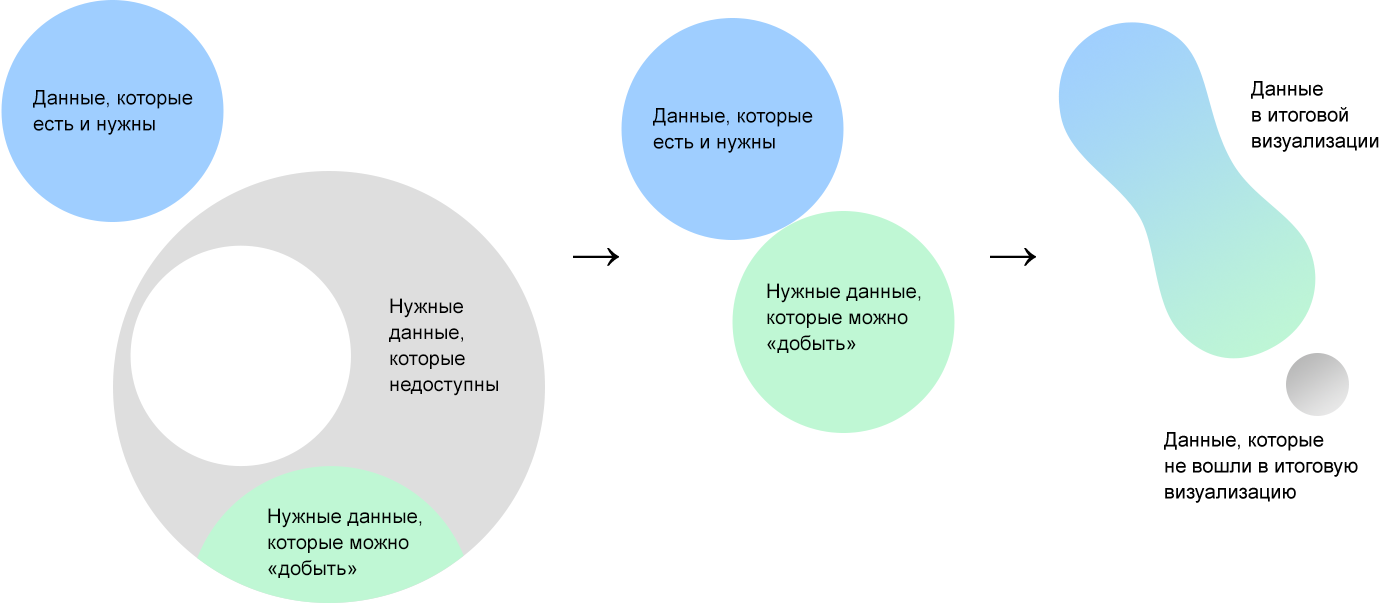
開始するデータは出発点にすぎません。 それらに会った後、私たちはそれらを生成した現実を提示します。そこでははるかに多くのデータがあります。 データの現実では、初期セットを見ずに、視聴者にとって最も完全で有用な視覚化を行うことができるデータを選択します。
理想的なセットのデータの一部は利用できなくなるため、「抽出」します。オープンソースで検索するか、「抽出」できるものに依存して作業します。
データ量とワイヤフレーム
私の最大の発見と、視覚化を大量のデータとワイヤーフレームに分割する際のΔλアルゴリズムの中心的なアイデア。 フレームは剛体で、軸、ガイド、領域で構成されています。 フレームワークは空白の画面のスペースを整理し、データ構造を転送し、特定の値に依存しません。 データの塊は情報の集中であり、データの素粒子で構成されています。 このため、プラスチックであり、任意のフレームに「付着」します。 フレームワークのない大量のデータは形のない山であり、データの大量のないフレームワークは裸の骨組みです。
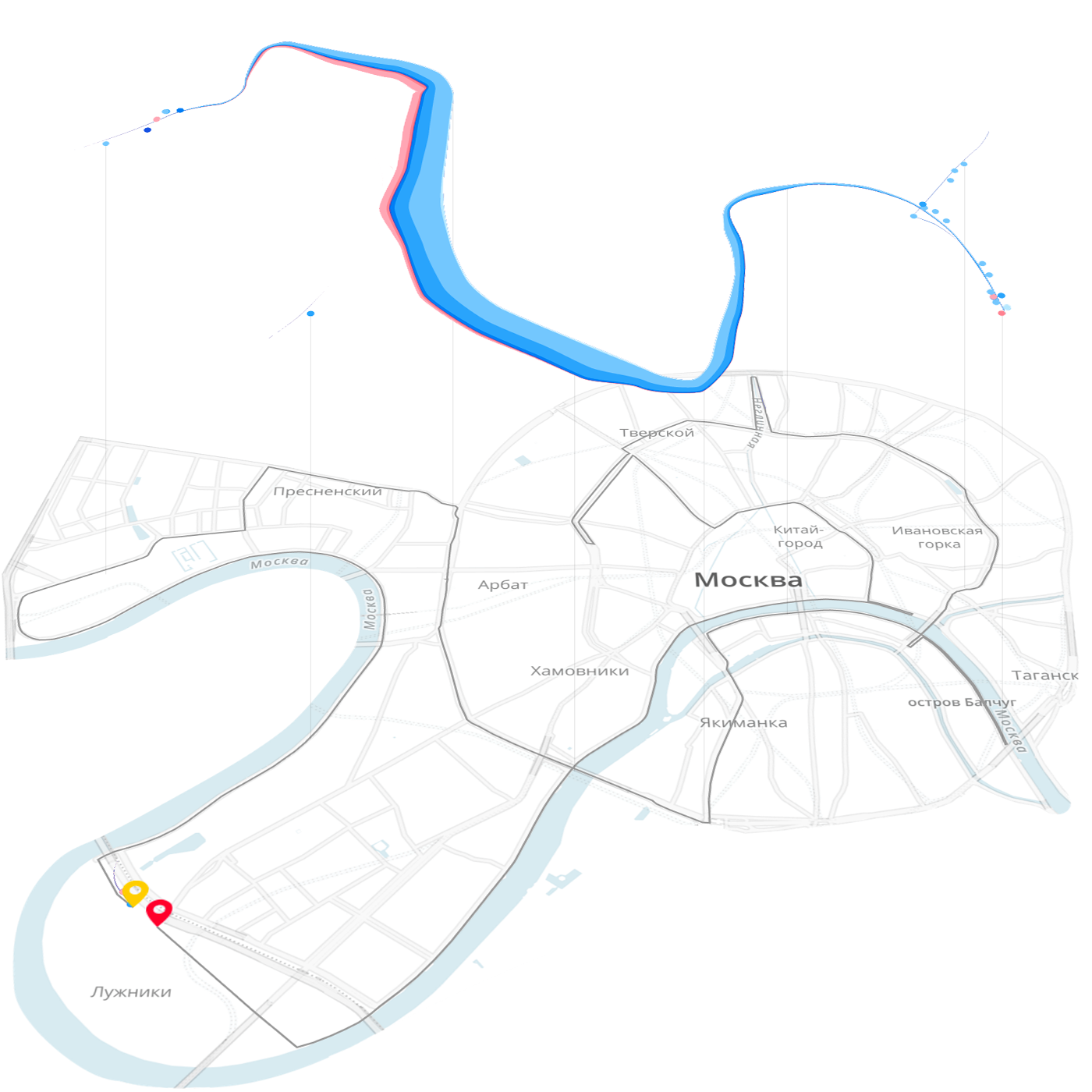
モスクワマラソンの例では 、データの素粒子はランナーであり、質量はランナーの群衆です。 メインビジュアライゼーションのフレームワークは、レースルートと一時的なスライダーを備えたマップです。
時間軸によって形成されたフレーム上の同じ質量は、仕上げの図を示します。
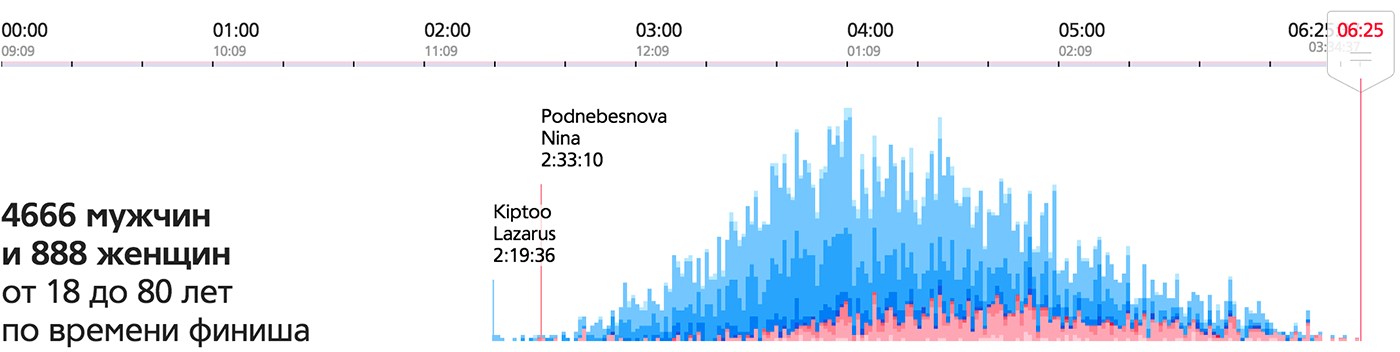
これは、アイデアを見つけるための出発点として役立つため、視覚化の重要な機能です。 データマスは、データの現実を簡単に確認して強調表示できるデータパーティクルで構成されます。
データ粒子と視覚原子
基本データパーティクルは、データの特性を保持するのに十分な大きさであると同時に、すべてのデータを同じ順序または別の順序で粒子に分解して再構築できるほど小さいエンティティです。
市の予算の例でデータの基本粒子を検索します。
下から上に素粒子を検索します。異なる可能性のある粒子を探して、データで試してください。 「お金?」は良いスタート、予算の単位、ルーブルですが、あまりにも普遍的です。 市の予算により特徴的なものが見つからない場合に適しています。 「イベント」は適切ではありません。すべての予算支出がイベントに関連付けられているわけではなく、他の費用があり、素粒子はデータ全体を記述する必要があるためです。 「機関?」-一方では、はい、すべての予算金は特定の予算機関への寄付に分割することができます。 一方、これはすでに単位が大きすぎます。機関内では、定期的なトランザクションを含む複数のトランザクションが存在する可能性があるためです。 機関を素粒子とみなす場合、この機関の一般予算のみで運営され、タイムスライスを失うだけでなく、資金の意図された目的のための可能なカットも失われます。
私の推論では、素粒子はすでに数回点滅しています-控除、特定の目的(イベントなど)のために特定の組織に特定の量(同じルーブル)の予算資金を一度だけ送金し、時間に関連付けられています。 控除は定期的で不規則であり、目標はいくつかの階層レベルで構成できます。イベントの場合→コンサートの開催→出演者の料金。 控除は都市予算の支出項目全体で構成されますが、控除は一緒に追加、比較、およびダイナミクスを追跡できます。 予算収入を視覚化する必要がある場合は、ツインパーティクル-収入を使用します。 収益から、控除と同じ方法で都市予算の形成の写真を得ることができます-その使用の写真。
下から(測定単位を使用して)始め、ますます大きくなるデータパーティクルの役割を試して、このエンティティまたはそのエンティティが適切であるか適切でないかを説明します。 推論では、データの粒子への新しいエンティティと暗示が確実に表示されます。 見つかったパーティクルについては、適切な単語または用語を選択してください。それについて考え、将来問題を解決するのは簡単です。
基本的なデータとは何かという質問に答えた後、そのデータを最も適切に表示する方法を考えてください。 データの基本粒子は原子であり、その視覚的な実施形態は原子でなければなりません。 主な視覚的アトム:ピクセル、ポイント、円、ダッシュ、正方形、セル、オブジェクト、長方形、線、線、ミニグラフ、およびカートグラフィックアトム-ポイント、オブジェクト、エリア、ルート。 ビジュアルがデータパーティクルのプロパティをより良く伝えるほど、結果の視覚化はより視覚的になります。
市の予算の例では、控除には2つの重要なパラメーター-量(定量)と目的-定性があります。 単位幅の長方形の原子は、これらのパラメーターに適しています。列の高さは金額をエンコードし、その色は支払いの目的を表します。 これにより、個人予算の視覚化に似た画像が生成されます。

異なるフレーム上の同一のパーティクル:時間軸に沿って、カテゴリごと、または軸内の時刻/曜日。
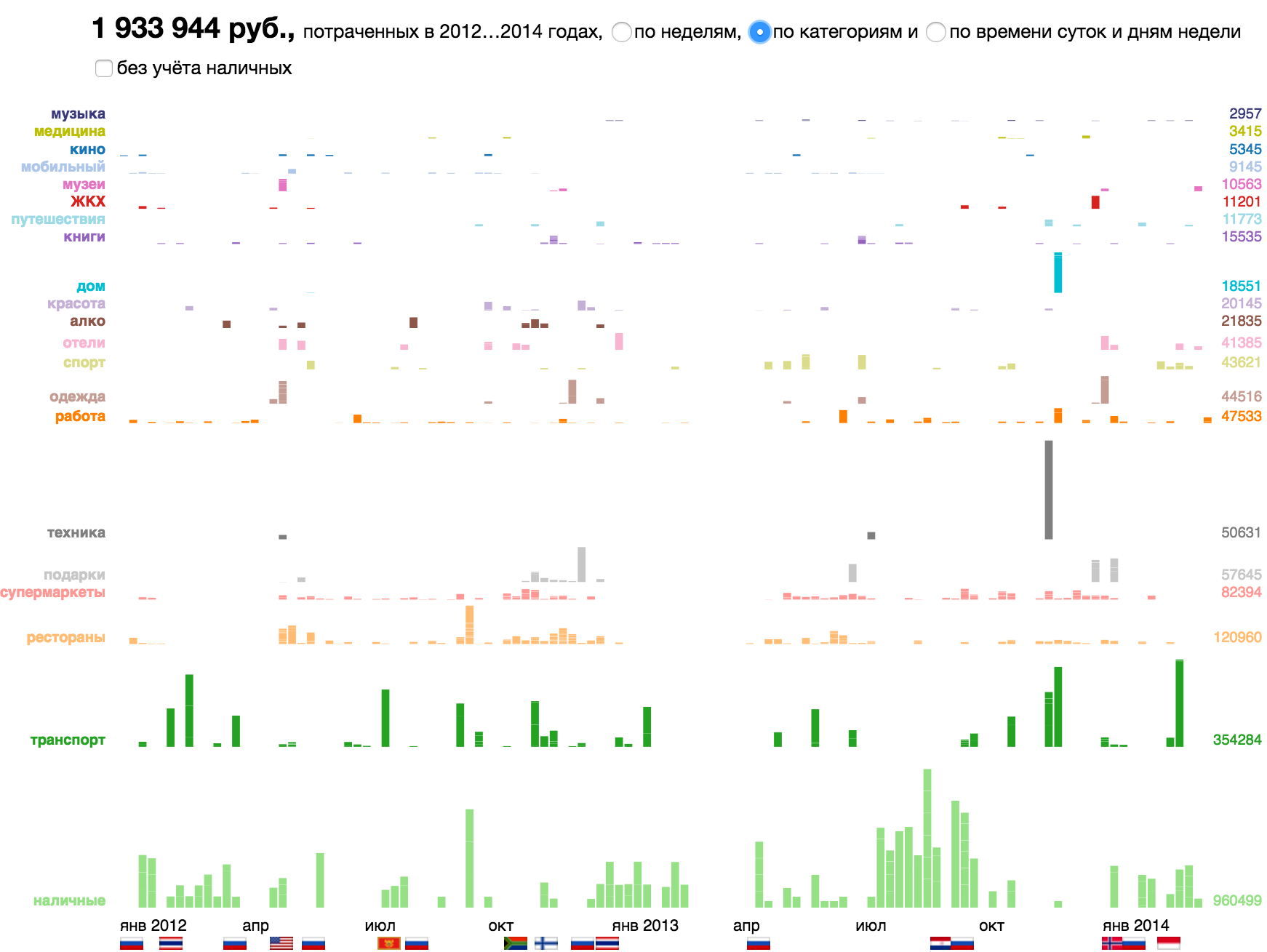

データパーティクルとそれに対応する視覚的アトムの他の例を次に示します。
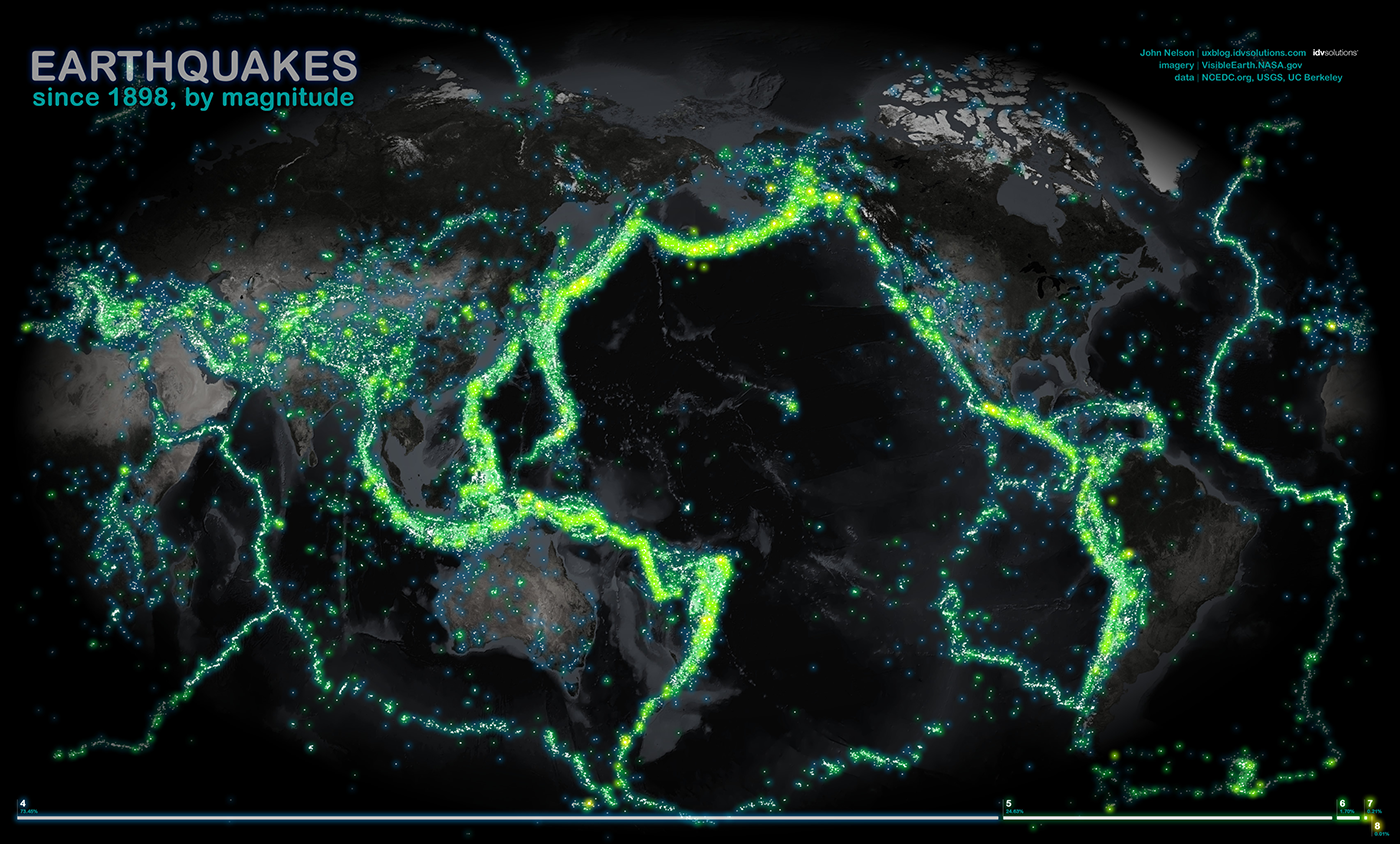
地震の歴史における地震 、視覚原子-地図作成ポイント:
対数マニグラム上のドルとその度、原子-ピクセル:

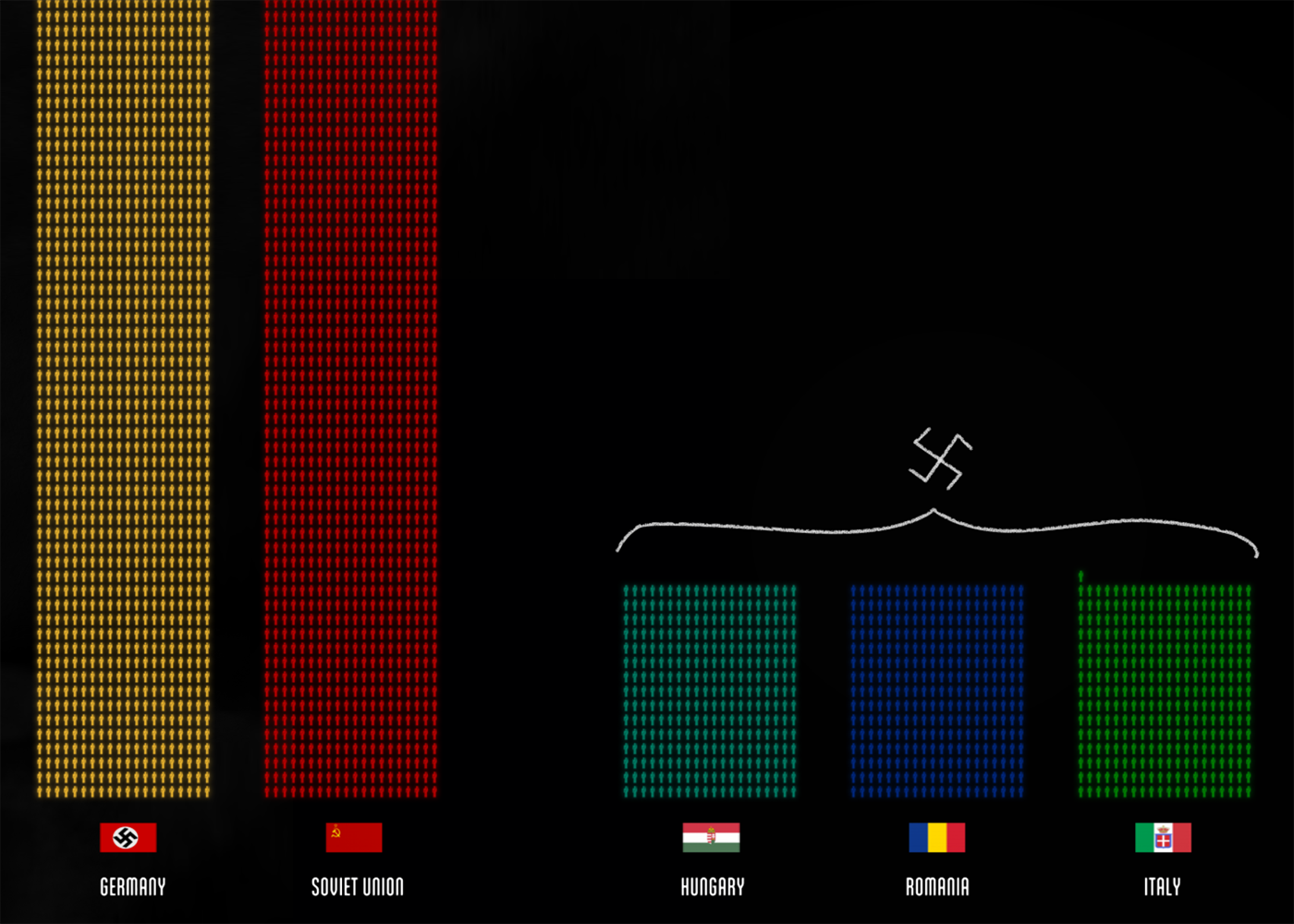
損失の可視化における兵士と民間人"Fallen.io" 、原子-オブジェクト-銃を持った男となしの男の画像:
フラグ可視化のフラグ、 atom-オブジェクト-フラグ画像:

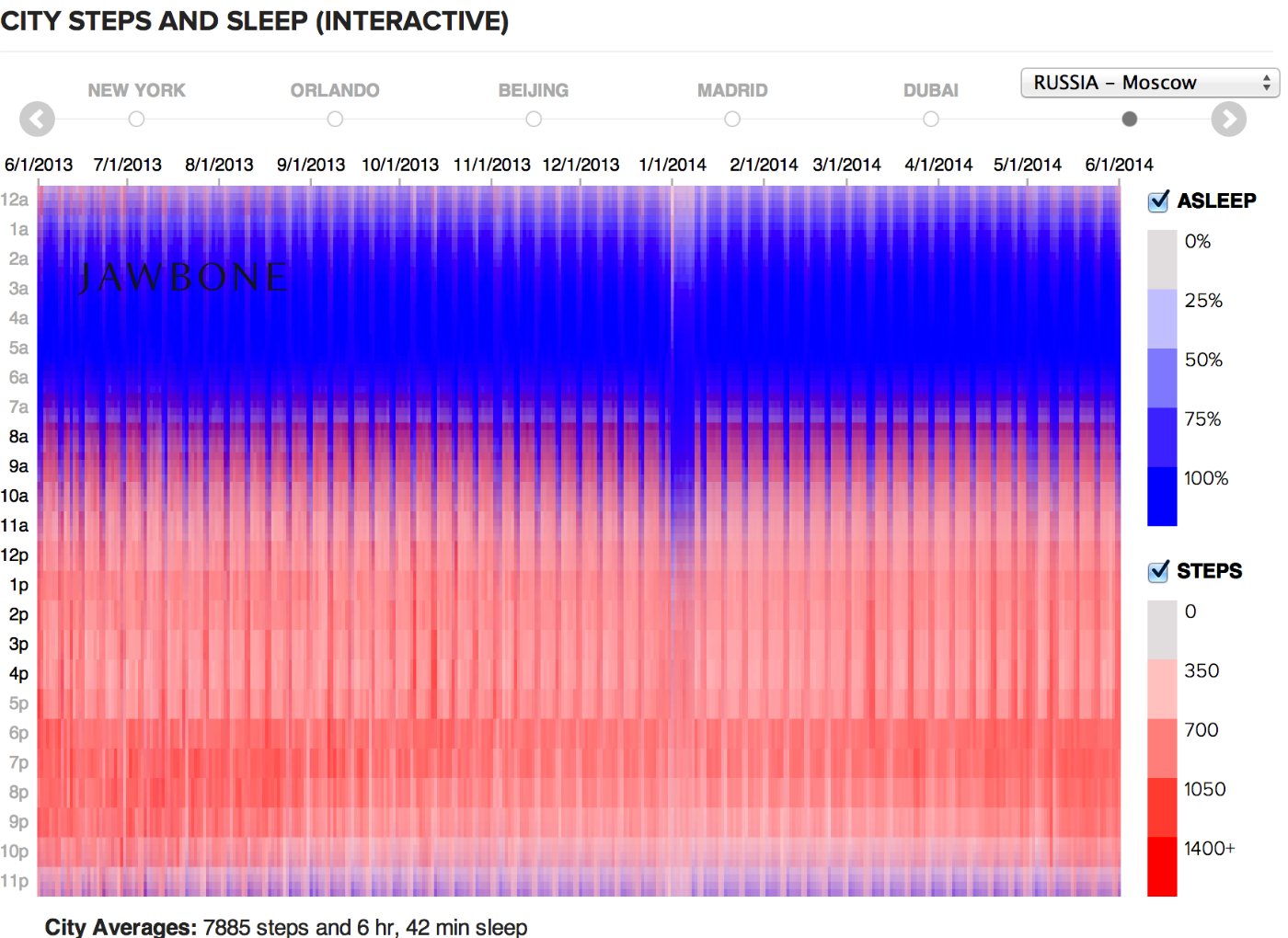
図の都市の生活のリズムに関する時間(アクティビティまたは睡眠)、atom-2色エンコードのセル:
SDAシミュレーターの統計の質問に答えようとする試み、視覚原子は信号勾配のあるセルです:

税率 、原子円の広がりの図表の会社:
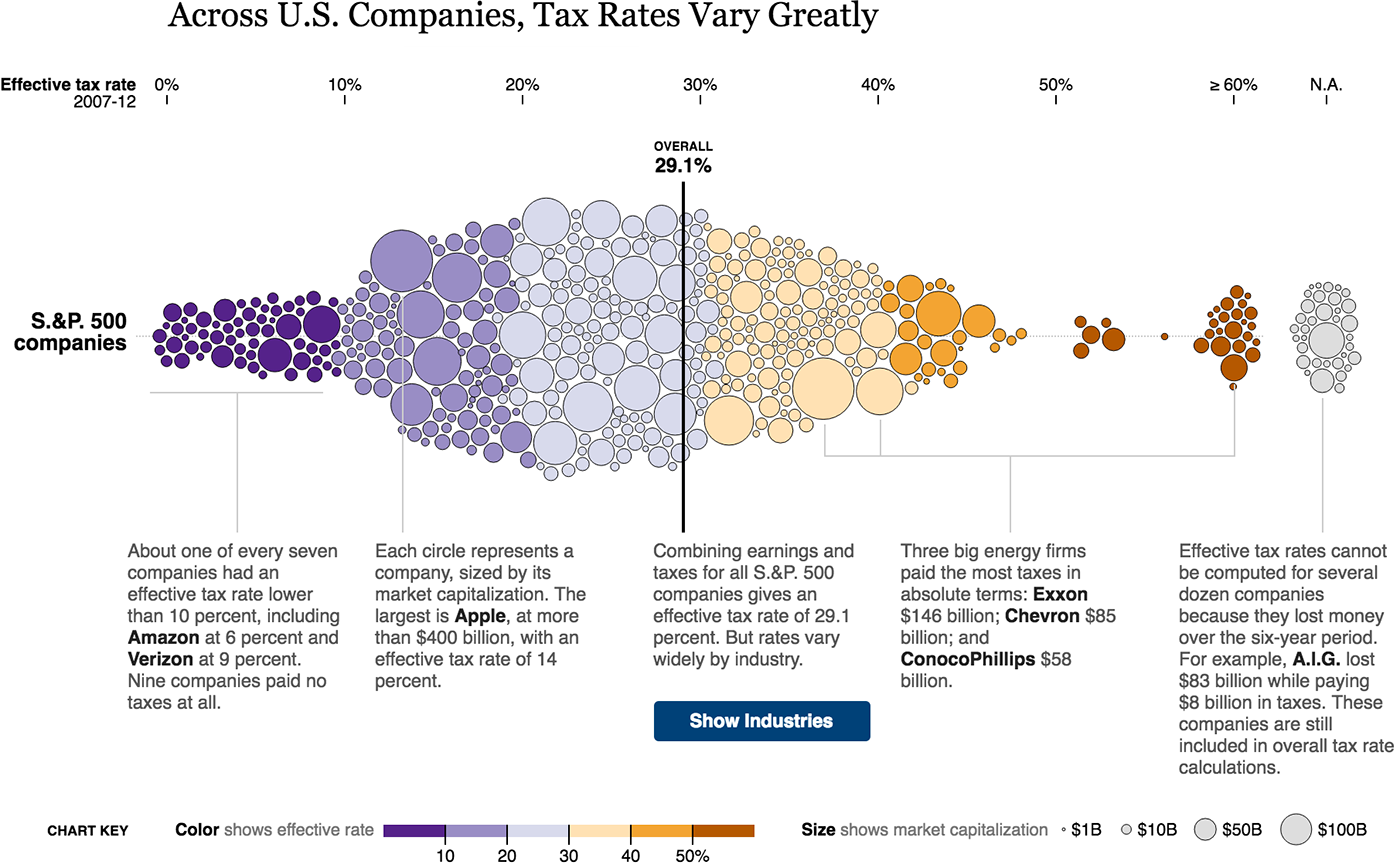
サッカー分析における目標と目標の瞬間、原子-セグメント-サッカー場へのインパクトパス:
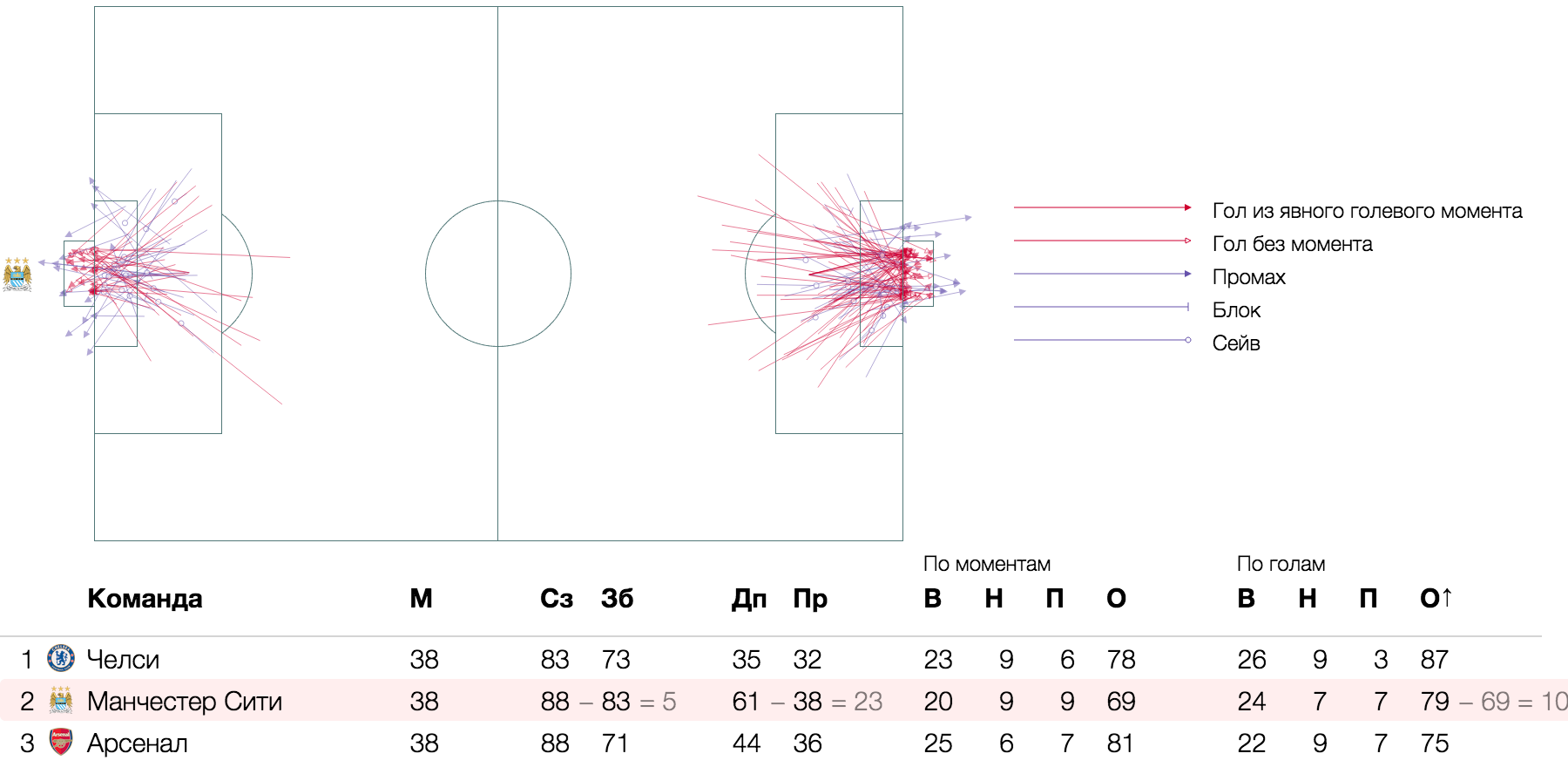
Huntflow採用プロセスの視覚化の候補、atom-ユニットの厚さの線-じょうごの候補のパス:
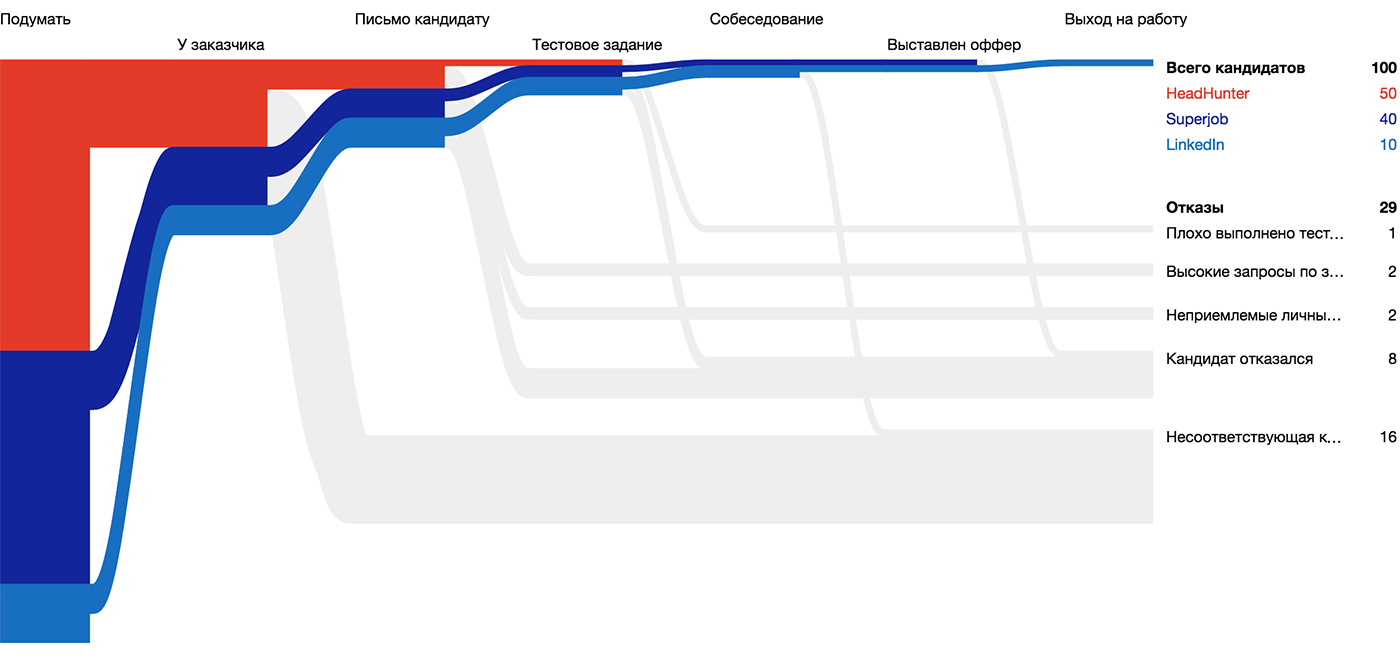
政治的な雰囲気を変えている状態、原子は太さのある線です:
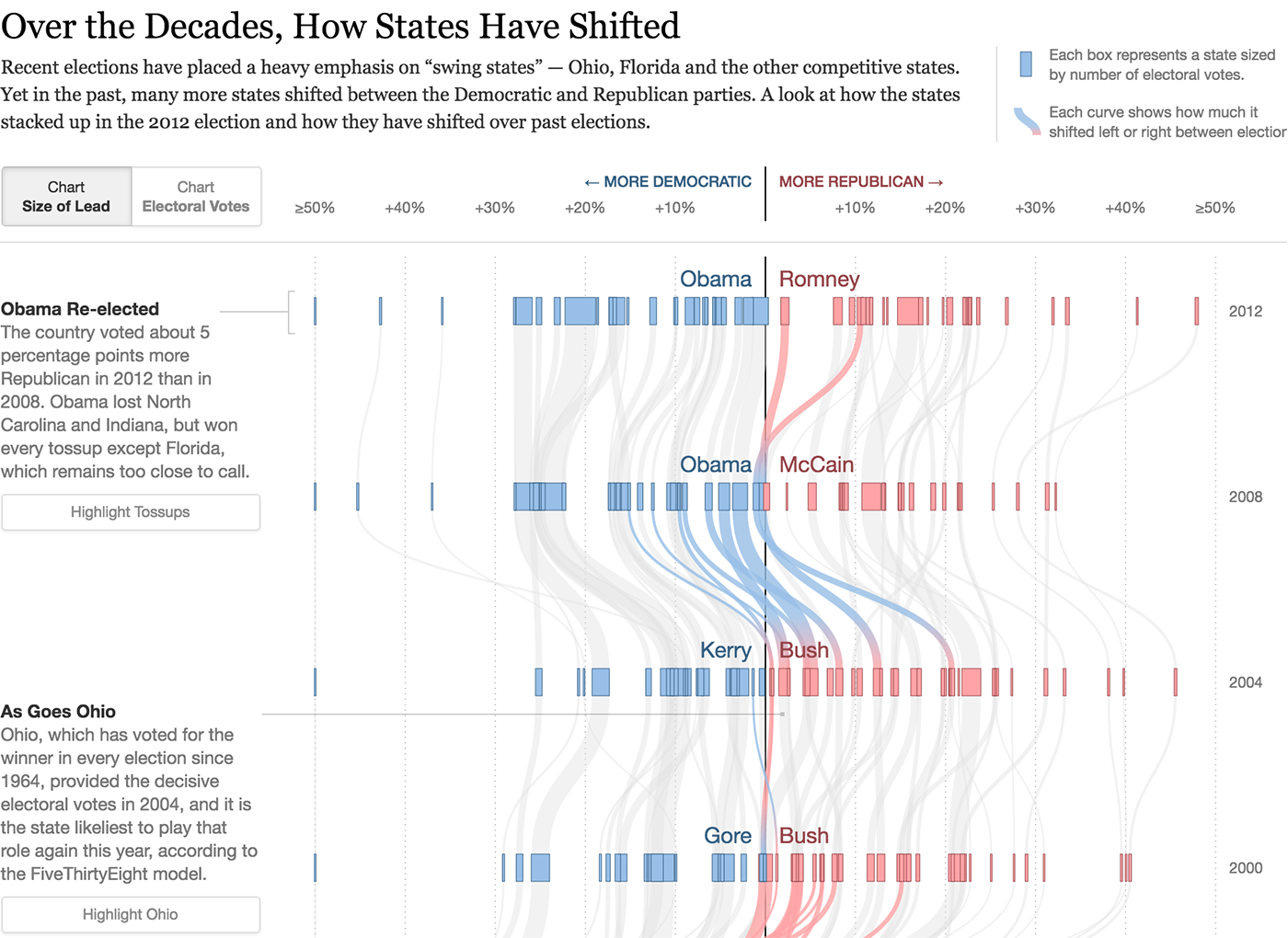
スイスの列車のルート上の駅間のセグメント、原子-太さの地図製作ライン:

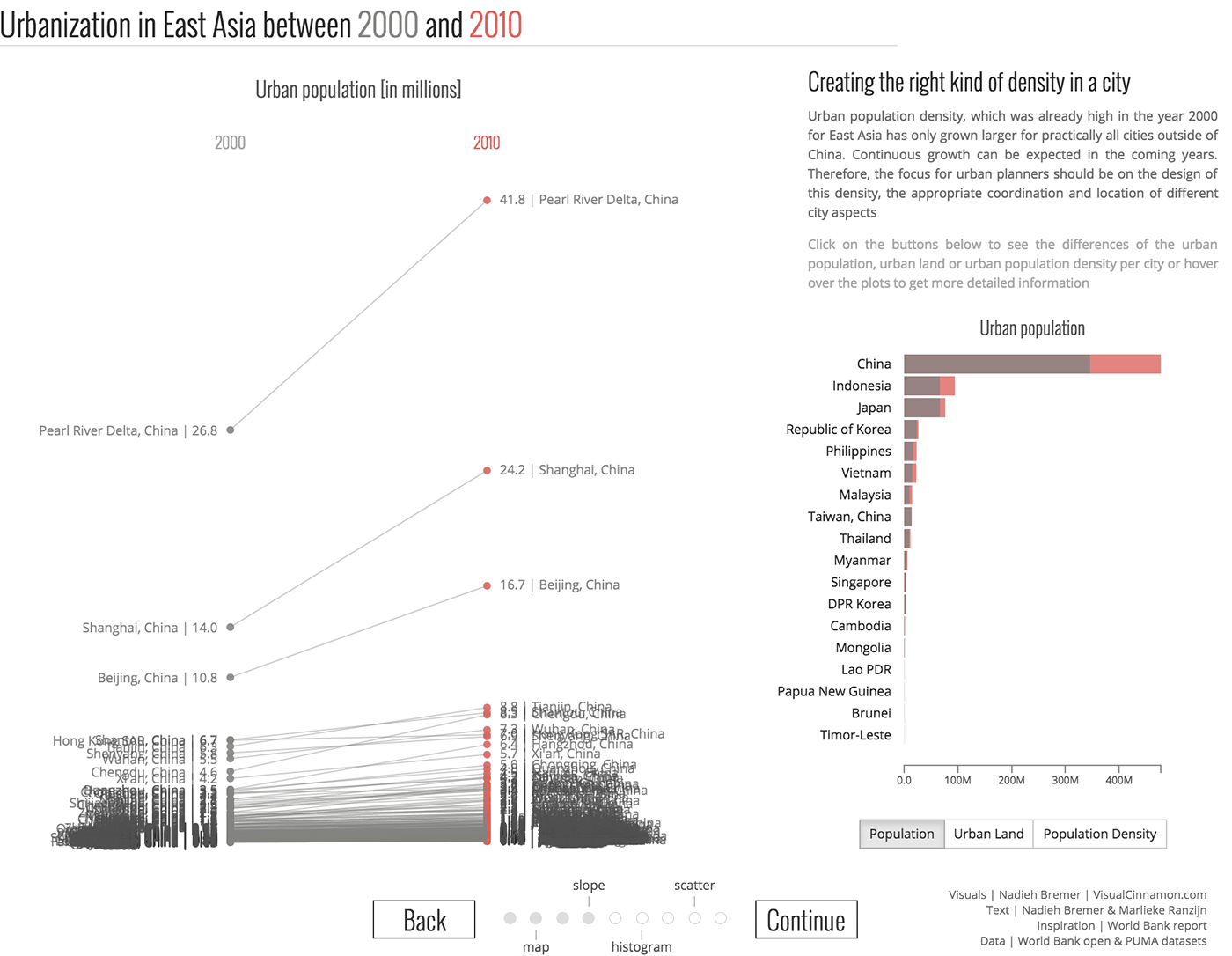
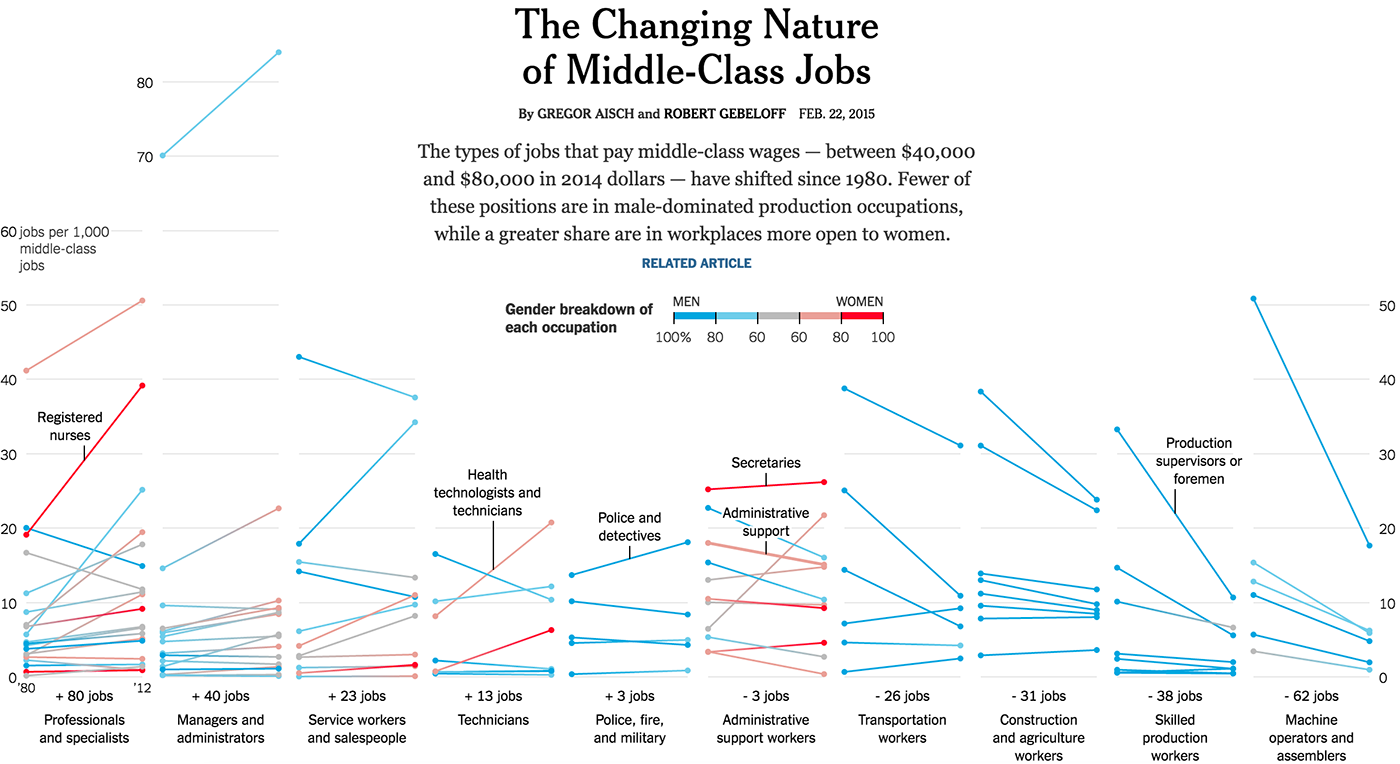
ミネソタ州住民のさまざまな産業における雇用の動態 、Atom-ミニチャート:

視覚原子とそのプロパティの詳細については、 こちらをご覧ください 。
フレームと車軸
インタラクティブな視覚化は、スクリーンプレーンの2次元に存在します。 大量のデータに「剛性」を与え、視覚原子を体系化し、視覚化フレームワークとして機能するのは、これらの2つの次元です。 視覚化により、これらの2つのディメンションの使用方法がどれほど興味深く、有益で、有用であるかがわかります。
適切に視覚化すると、各ディメンションは重要なデータパラメーターを表す軸に対応します。 軸を連続(空間と時間の軸を含む)、間隔、層状、縮退に分割します。
放物線を作成するとき、学校での連続軸について学習します。
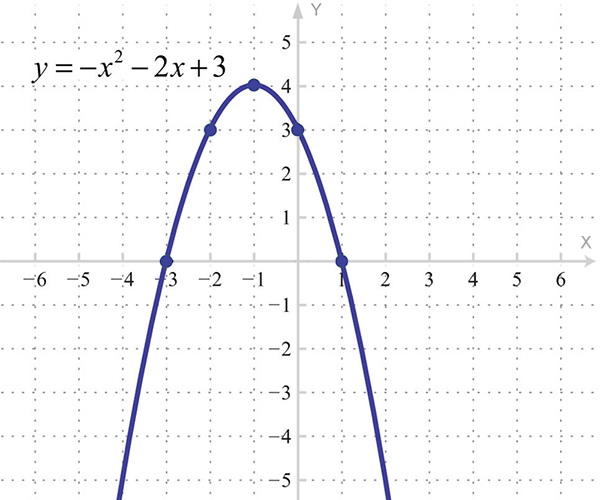
一般に、グラフは通常、2つの連続した軸のまさにそのようなフレームを意味します。 多くの場合、グラフはある量の別の量への依存性を示します。この場合、伝統によれば、独立した量は水平に配置され、おそらく依存する量は-垂直に配置されます:
点オブジェクトを持つ2つの連続軸のグラフ:

時々、平均値が軸上にマークされ、グラフは意味のある四分円(「高価な生産的なプレーヤー」、「安い生産的な」など)に分割されます。
グラフ上に光線を描くこともできます。軸に沿って配置されたパラメーターの比率が表示され、それ自体が重要なパラメーターになることがあります(この場合、業界の競争)。
広範囲の値を持つパラメーターを視覚的に表示するには、対数スケールの軸が使用されます。

連続軸の重要な特殊なケースは、 空間と時間の軸です。たとえば、地理座標やタイムラインです。 マップ、サッカー場またはバスケットボールコートのビュー、生産チャートは、2つの空間軸の組み合わせの例です。
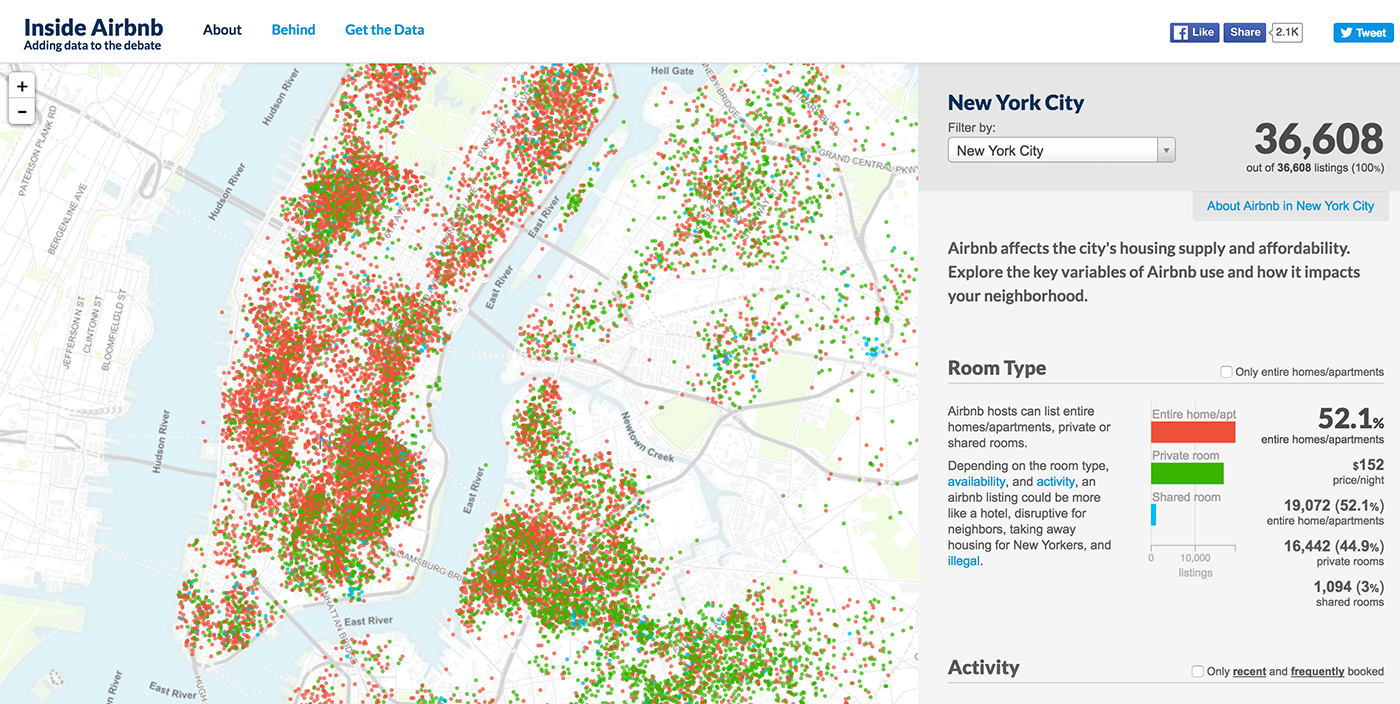

時間軸を持つグラフは、データの視覚化の基礎を築いた最初の抽象的なグラフです。
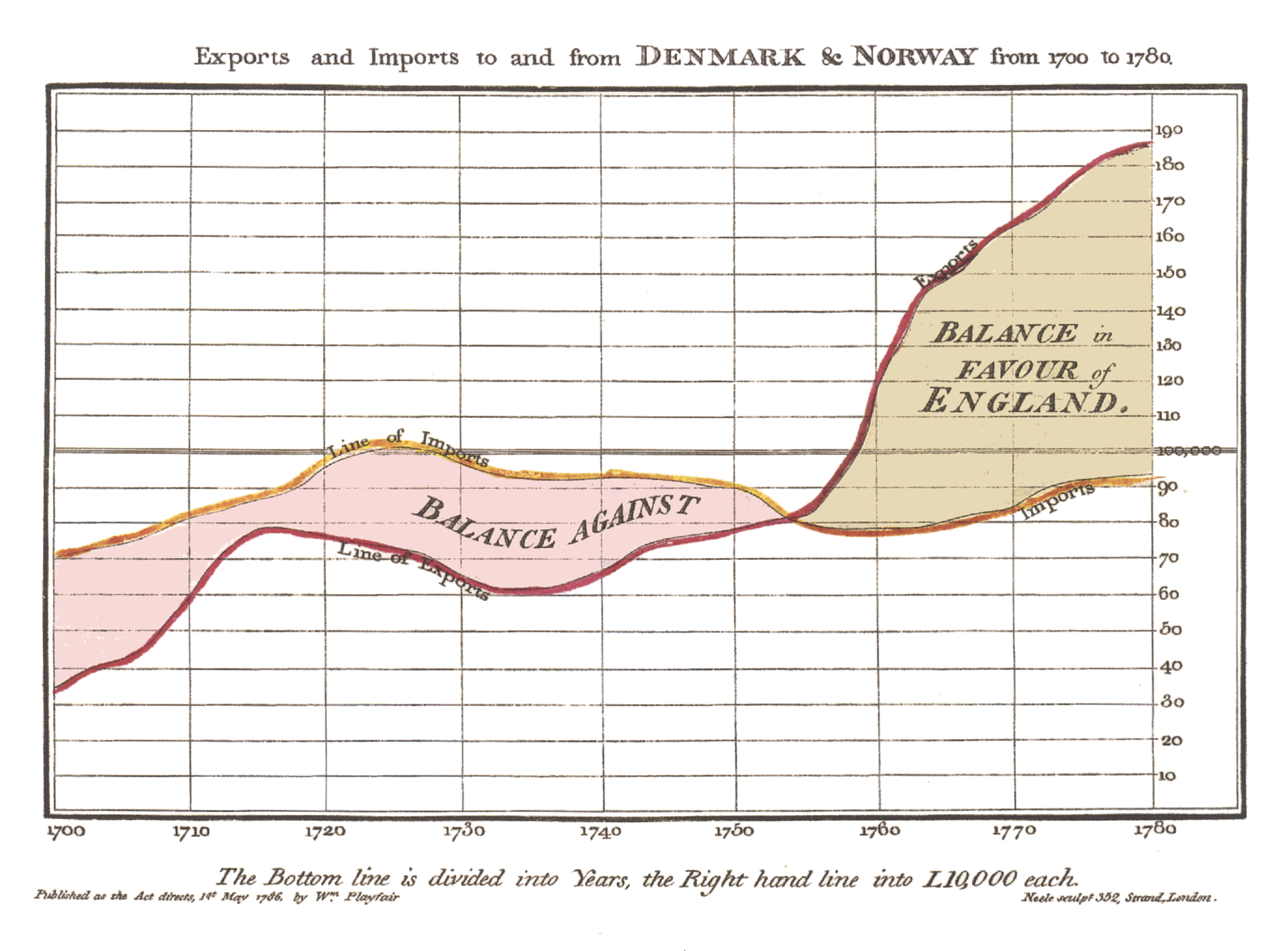
そして、それらはまだ正常に適用されています:
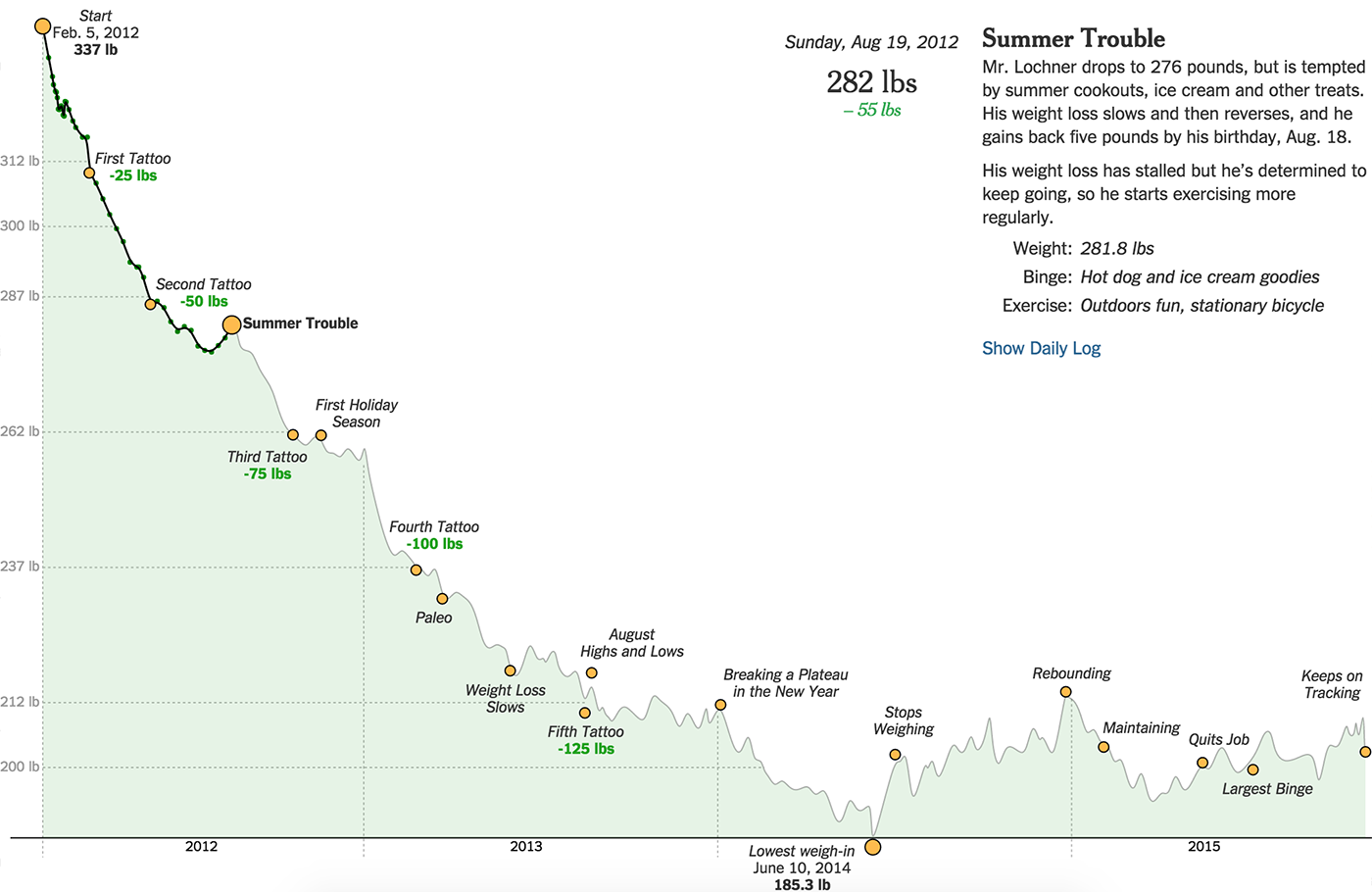
一時的な寸法を表示するもう1つの方法は、スライダーに空間画像を追加することです。
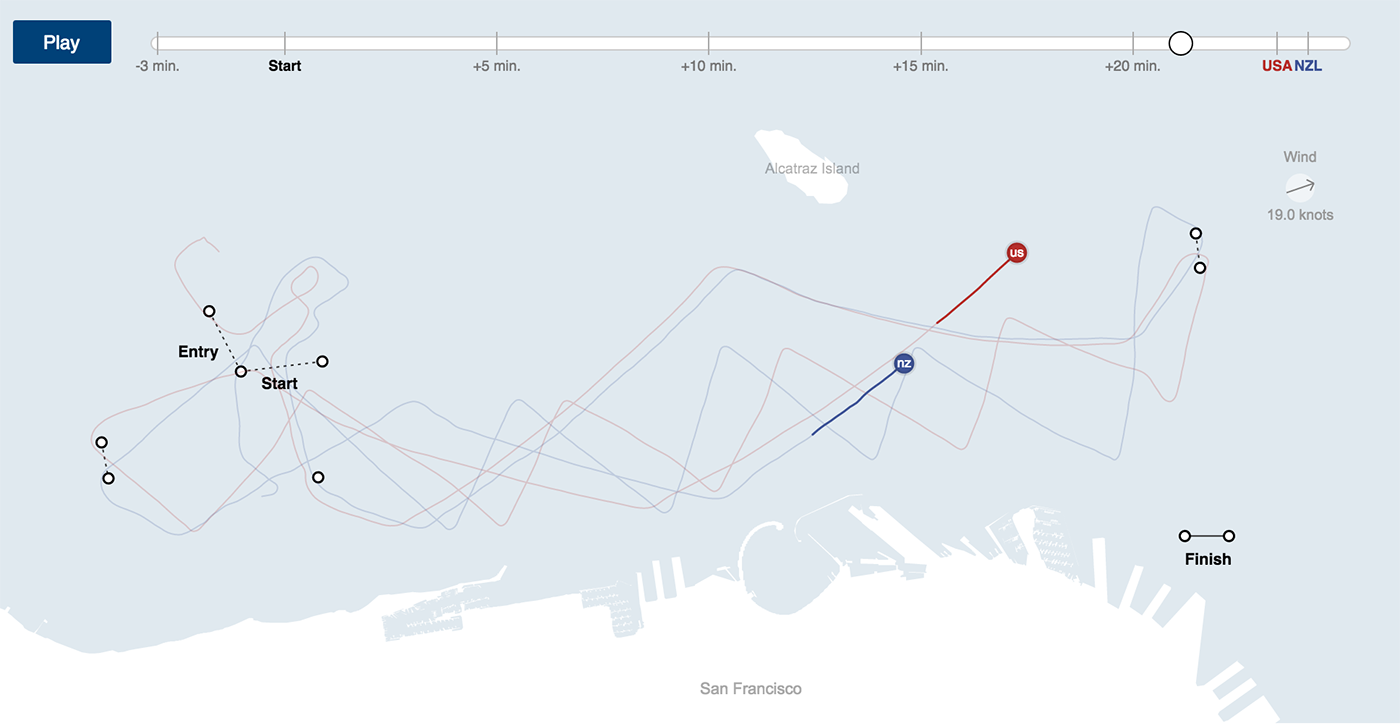
例外的なケースでは、空間と時間をフラットマップ上または同じ空間軸に沿って組み合わせることができます。

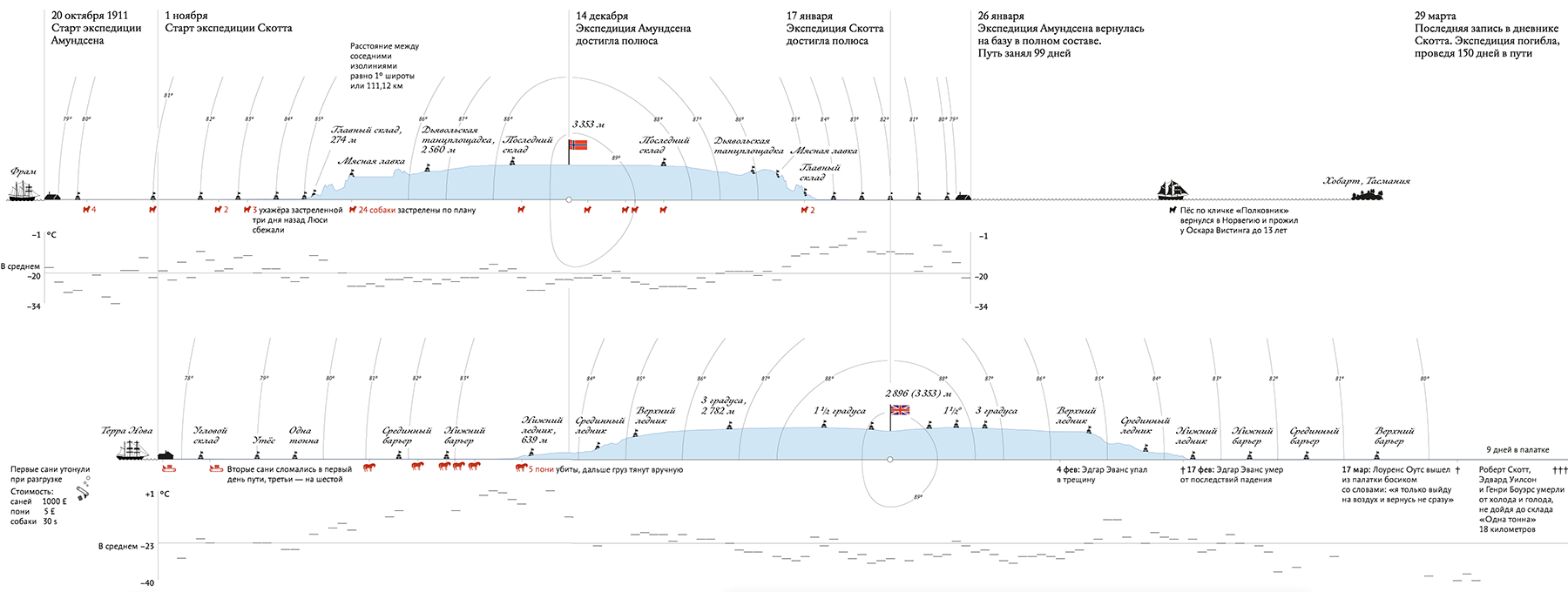
間隔軸はセグメント(等しいまたは等しくない)に分割され、特定のルールに従ってパラメーターの値に対応します。 間隔軸は、定性的および定量的パラメータの両方に適しています。
ヒットメップは、2つの間隔軸の組み合わせの典型的な例です。 たとえば、適切なフレームに表示される州および年ごとの症例数:

棒グラフは、間隔(期間)と連続(値)軸の組み合わせの例です。
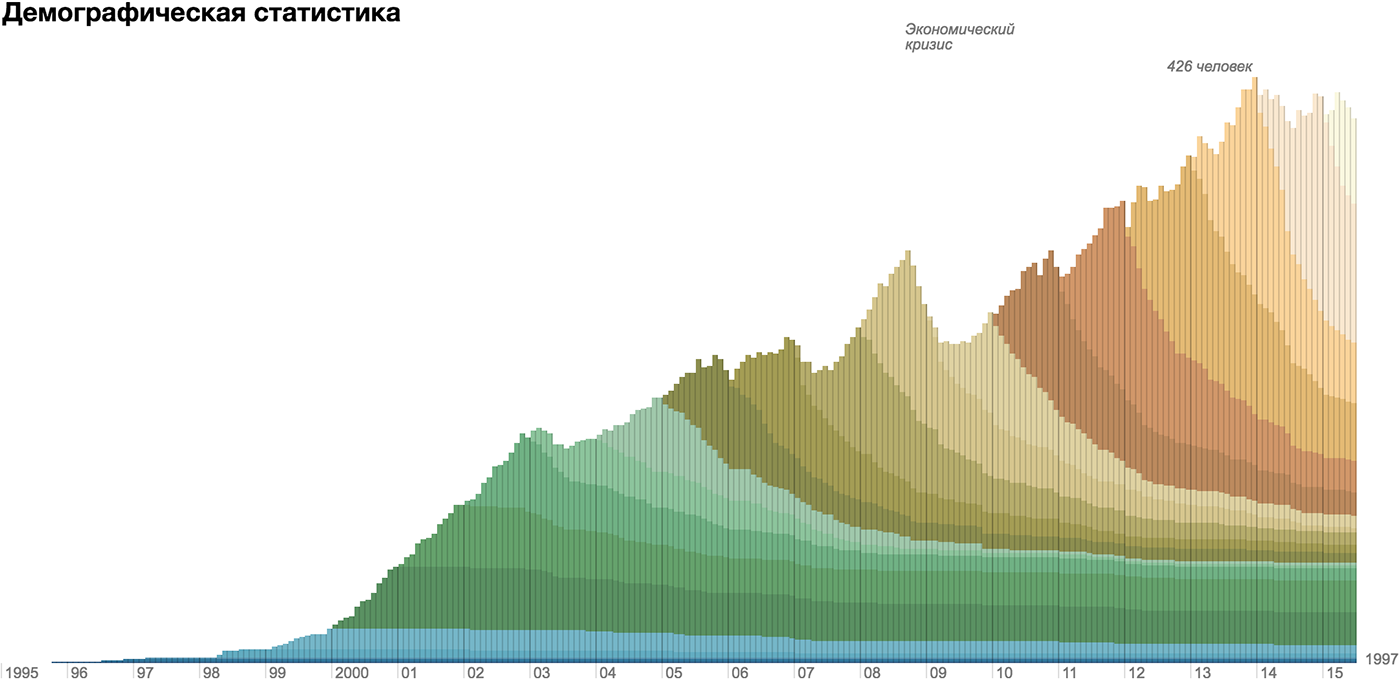
ヒットマップに変換するために2つの間隔軸は必要ありません。
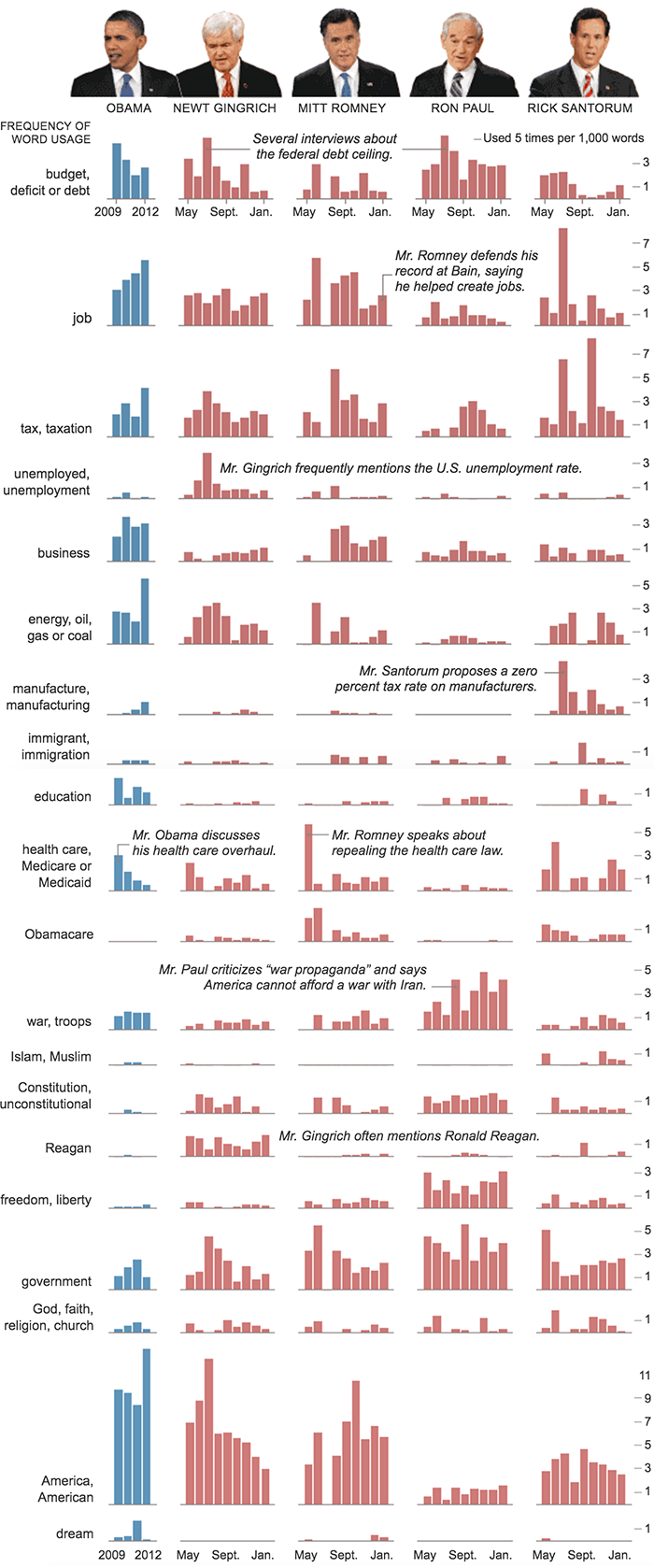
階層化された軸は、複数の平行な軸を1次元で(連続および間隔)一度に積み重ねます。 ほとんどの場合、この手法は、データ、テキスト、グラフィックスを含むレイヤーが1つの時間軸に重ねられている場合、timelansで機能します。
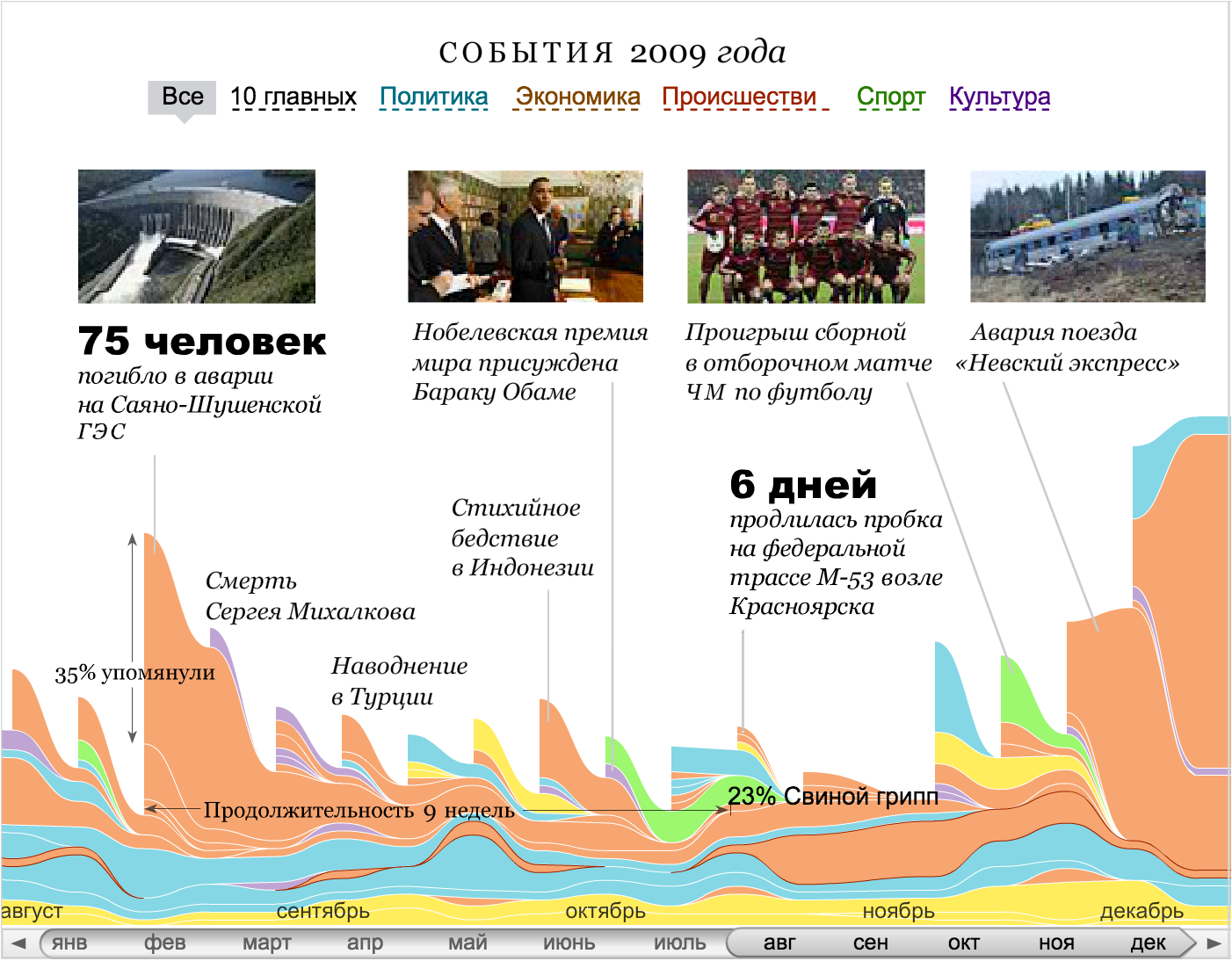
視覚化には、特定のパラメーターが付加されていない、または2つの値のみが表示されている縮退軸が必要な場合があります。 ほとんどの場合、これは視覚化が接続を示すときに起こります。接続を表示するには、オブジェクト間にスペースが必要です。
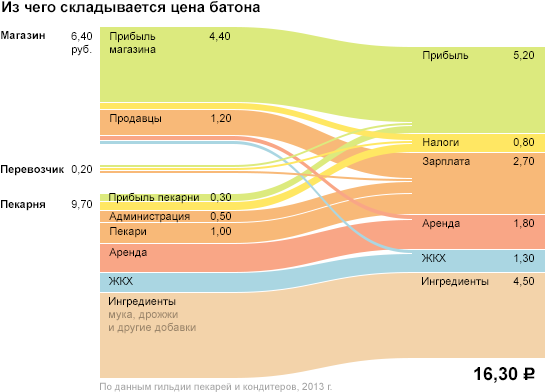
「was-became」形式のデータには、ほとんどの場合、縮退軸が必要です。
しかし、彼女は必ずしも画面の寸法を「食い尽くす」わけではありません。
縮退軸は、重要なデータ機能を示すため、画面全体の損失を「支払う」場合に許容されます。 ただし、最後の手段としてのみ使用してください。 残念ながら、壮大な人気のあるインフォグラフィック形式では、一方または両方の画面軸が退化することがよくあります。
スクリーンスペースを使用する別の方法は、 均一なグリッドの連続ブロックでそれを満たすことです。 グリッド内のオブジェクトは、たとえばアルファベット順に線形に並べられます。
または都市のサイズ:

グリッドは画面のサイズに合わせて調整され、顕著な水平および垂直ガイドはありません。
ほとんどの場合、視覚化フレームワークは上記の軸で構成されます。 3次元の視覚化はまれな例外であり、成功例はさらにまれです。

フレームの選択が明らかでない場合は、軸を重要なパラメーターとほぼランダムに組み合わせ、軸の特定の組み合わせが答える質問を定式化し、最も成功した組み合わせを選択します。 興味深い写真は、おそらく依存するデータパラメーターの接合部で得られます。
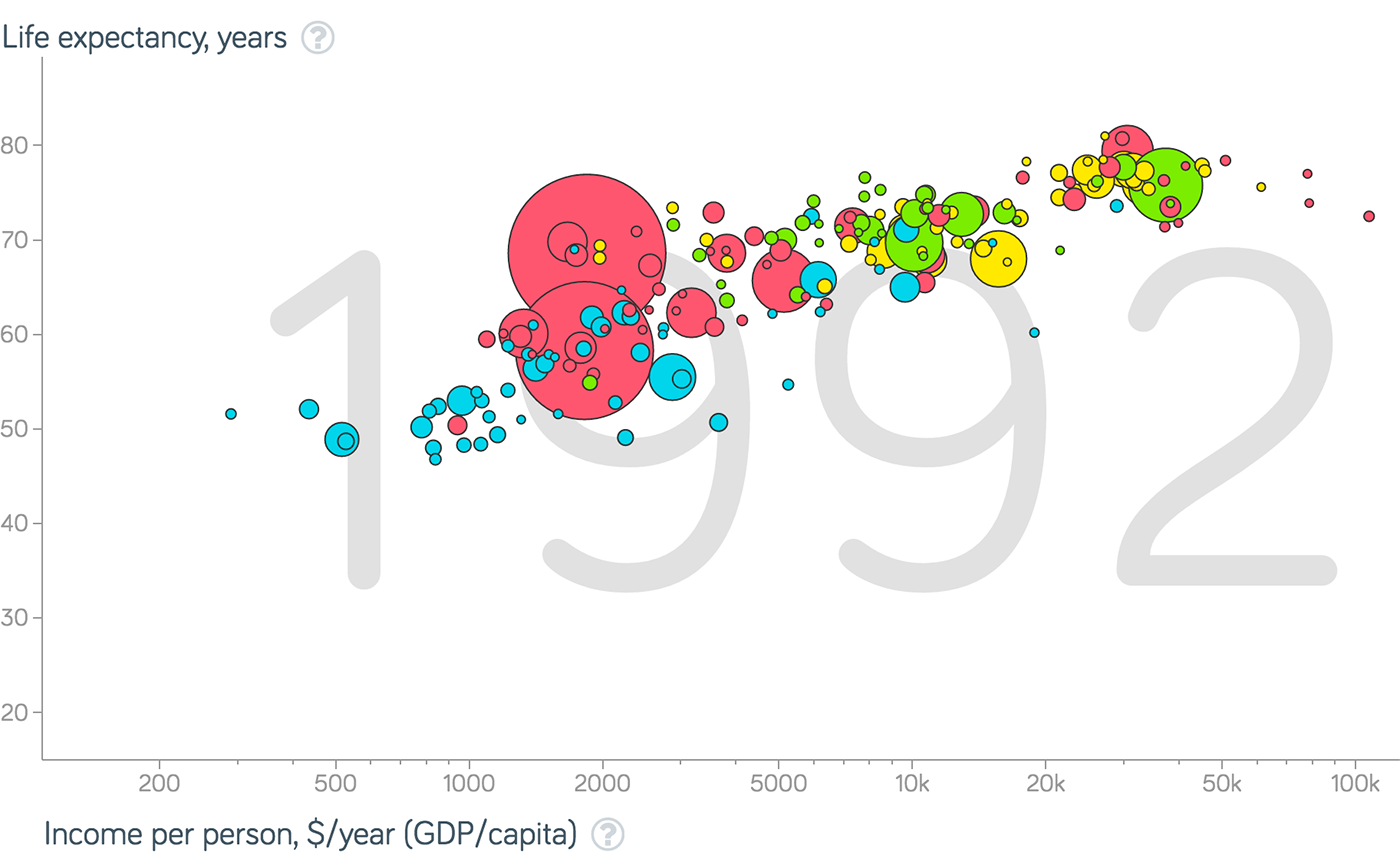
Gepminder分析チャート上の国の行動
そして、異なる軸に沿ったデータ粒子の分布から:
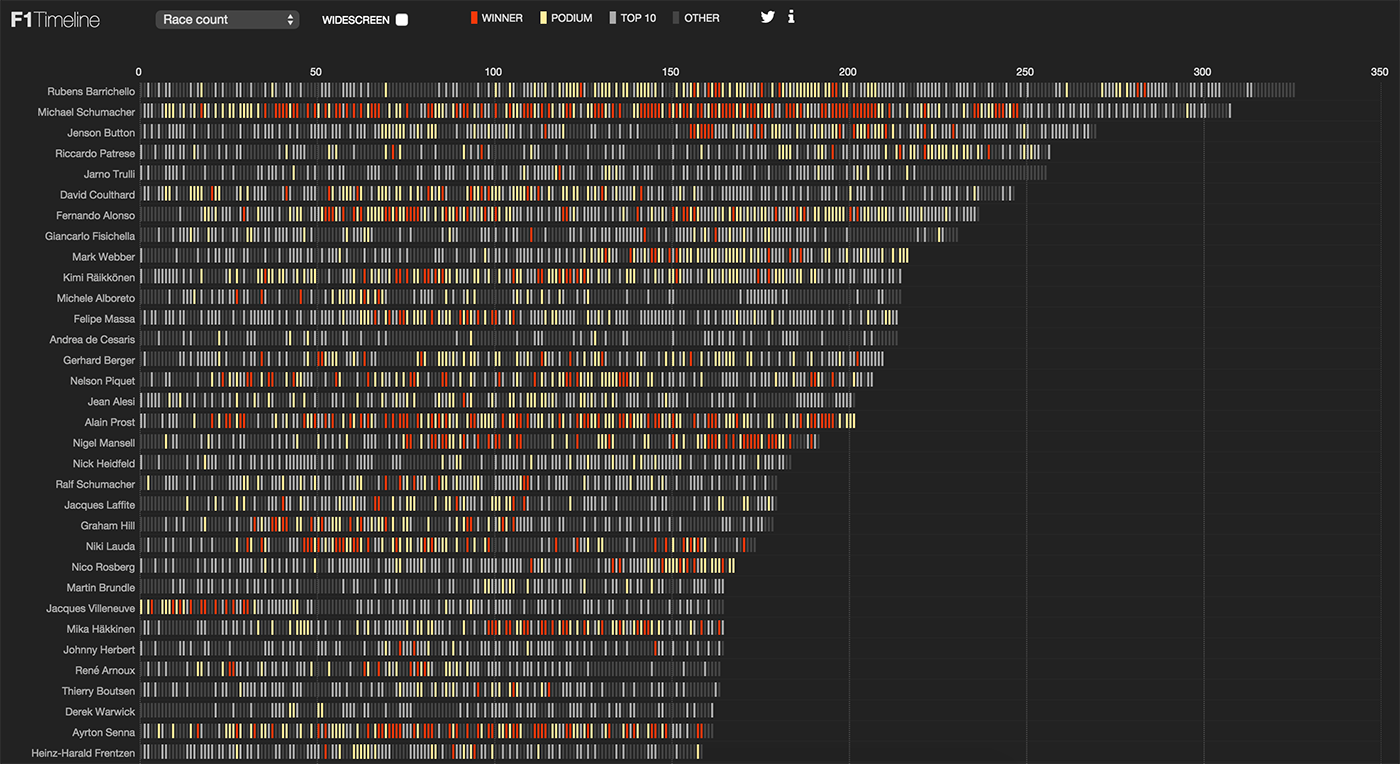
「フォーミュラ1」のパイロットの結果 、時間、レース数、パイロットの年齢
シンプルなワイヤーフレームのインタラクティブな組み合わせで、真に強力な視覚化が生まれます。 タイムライン+マップ:
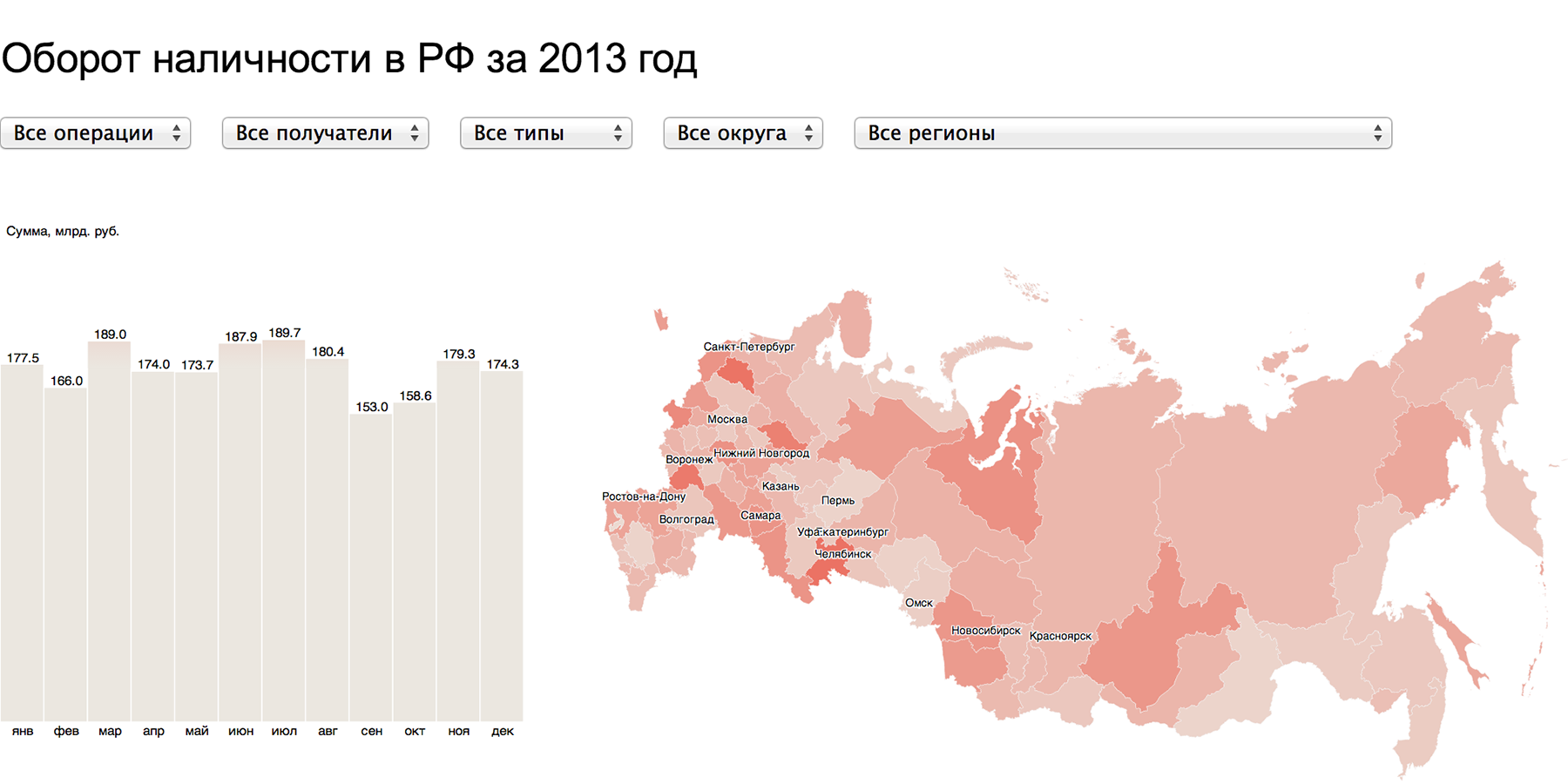
ロシア連邦の現金回転率
マップ+ヒットマップ:
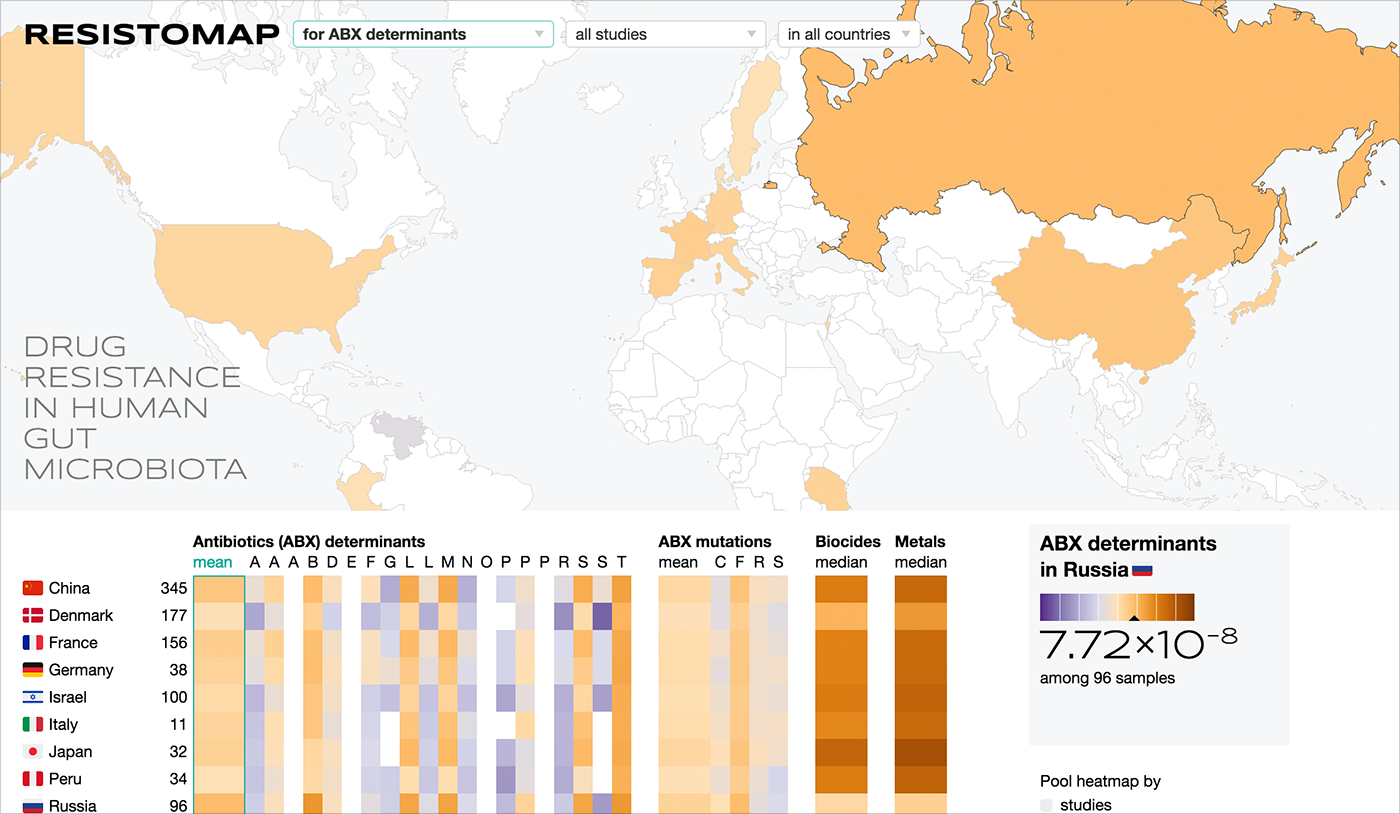
FHM研究所の抵抗マップ
いくつかの同様のグラフ:
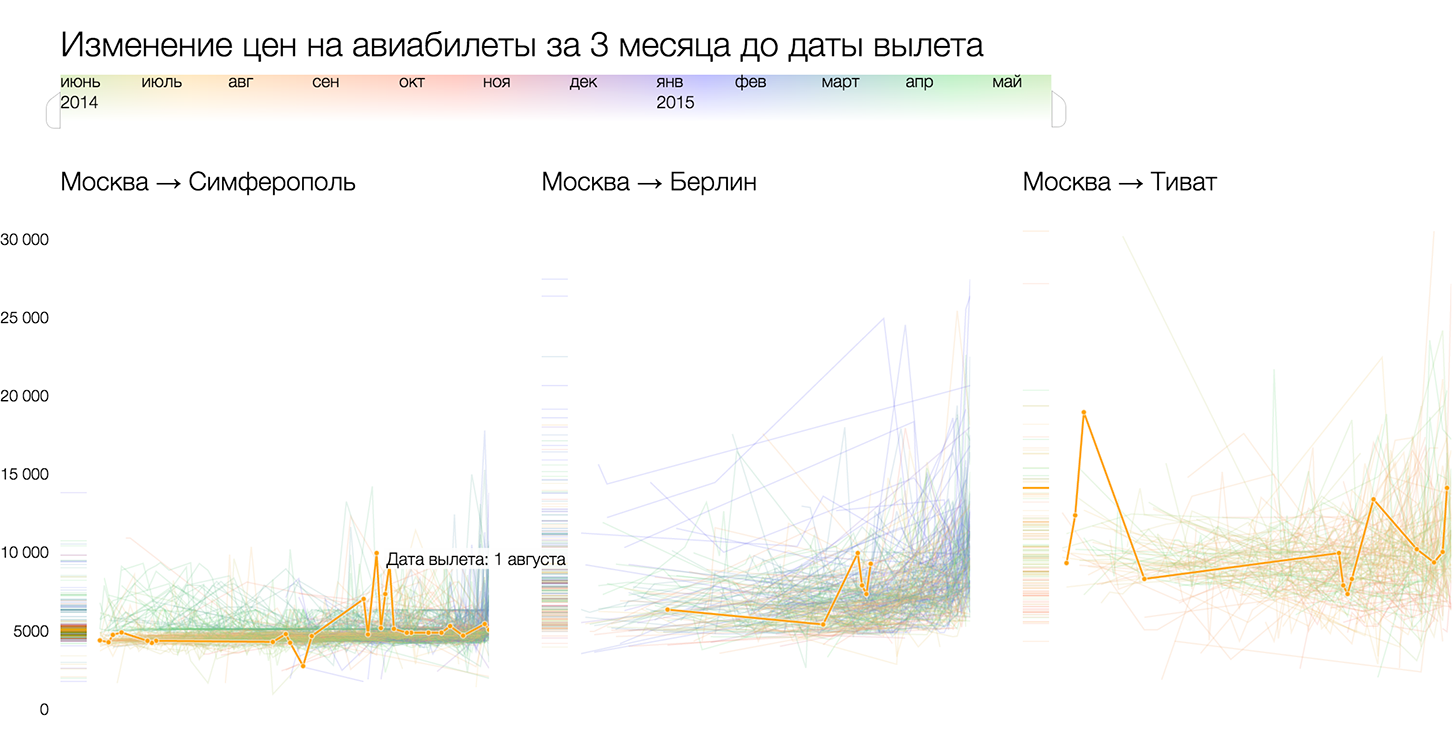
Tutu.ruの航空券価格分析
まとめ
だから、ここに私が最初から最後まで視覚化を作成するプロセスを見る方法があります。
1.テーブルとスライスからデータの現実に移動します。
2.大量のデータの作成元となるデータの粒子を見つけます。
3.データ粒子の実施形態の視覚原子を選択します。 ビジュアルアトムは、データパーティクルのプロパティを完全かつ明確に表示するように選択されます。 視覚的な実施形態が属性の物理的な意味に近いほど、より良い結果になります。
4.画面では、データの質量は視覚的な質量で表されます。 視覚的な質量では、個々の原子が区別できる場合がありますが、他の場合は平均化されて追加されます。
5.大量のデータに加えて、データの現実には、データが存在する一連の次元があります。
6.画面上のこれらの測定値は、フラットフレームに崩壊します。 フレームワークは視覚的な原子を体系化し、大量のデータに「剛性」を与え、特定の側面からそれを明らかにします。
7.視覚化には、大量のデータ(サンプリングや検索など)とワイヤフレーム(軸の設定など)を管理するためのインターフェイスが追加されています。
Δλアルゴリズムは、絶えず更新、補完、改善されています。 私はそれを簡潔かつ一貫して提示しようとしましたが、このための1つのhabrapostの範囲はamp屈で、多くは舞台裏に残りました。 私はコメントできてうれしいです。理解できない瞬間を喜んで説明し、質問に答えます。
直接的なアルゴリズムに精通し、その使用方法を学ぶには、10月8日と9日にモスクワで実施するデータ視覚化のコースをご覧ください。 コースでは、アルゴリズムに加えて、参加者は非標準のデータ視覚化ソリューションを実装するための強力なツールであるD3.jsに精通します。