確かに、ロックは一部のプラットフォームで、または非常に競争の激しいコードでゆっくりと動作する場合があります。 また、マルチスレッドアプリケーションを開発している場合、遅かれ早かれ、1つのロックが多くのリソースを使い果たす状況に遭遇する可能性が非常に高くなります(呼び出しの頻度が高すぎるコードのエラーが原因です)。 しかし、これらはすべて、「ロックの動作が遅い」という文には一般的に関係しない特別なケースです。 以下で見るように、ロック付きのコードは非常に生産的に機能します。
ロックの速度に関する誤解の理由の1つは、多くのプログラマーが「軽量ミューテックス」と「OSカーネルのオブジェクトとしてのミューテックス」の概念を区別していないことです。 常に軽量のmutexを使用します 。 たとえば、WindowsでC ++でプログラミングする場合、重要なセクションが選択されます。
 エラーの2番目の原因は、逆説的に、ベンチマークとして役立ちます。 たとえば、この記事の後半では、高負荷下でのロックのパフォーマンスを測定します。各スレッドは、アクションを実行するためにロックを必要とし、ロック自体は非常に短くなります(その結果、非常に頻繁になります)。 これは実験には適していますが、このコード記述方法は実際のアプリケーションで必要なものではありません。
エラーの2番目の原因は、逆説的に、ベンチマークとして役立ちます。 たとえば、この記事の後半では、高負荷下でのロックのパフォーマンスを測定します。各スレッドは、アクションを実行するためにロックを必要とし、ロック自体は非常に短くなります(その結果、非常に頻繁になります)。 これは実験には適していますが、このコード記述方法は実際のアプリケーションで必要なものではありません。
ロックは他の理由で批判されます。 「 ロックフリー 」プログラミングと呼ばれるアルゴリズムとテクノロジーのファミリーがあります。 これは、非常にエキサイティングで挑戦的な開発方法であり、さまざまなアプリケーションのパフォーマンスを大幅に向上させることができます。 何週間もかけて「ロックフリー」アルゴリズムを磨き、100万のテストを書いたプログラマーを知っています。数か月後には、特定のタイミングの組み合わせに関連するまれなバグを見つけるためだけです。 この危険とそれに対する報酬の組み合わせは、一部のプログラマー(私を含む)にとって非常に魅力的です。 「ロックフリー」の力で、古典的なロックは退屈で、時代遅れで、抑制的であるように見え始めます。
しかし、急いでそれらを廃棄しないでください。 ロックがよく使用され、良好なパフォーマンスを示す1つの良い例は、メモリアロケーターです。 Doug Leaの人気のあるmalloc実装は 、ゲーム開発でよく使用されます。 しかし、それはシングルスレッドなので、ロックで保護する必要があります。 アクティブなゲームでは、複数のスレッドが、たとえば1秒あたり15,000回の頻度でアロケーターにアクセスする状況がよくあります。 ゲームのロード中、この数値は1秒あたり最大100,000回に達する可能性があります。 後で見るように、これはロックのあるコードにとってまったく問題ではありません。
ベンチマーク
このテストでは、 メルセンヌ渦アルゴリズムを使用して乱数を生成するストリームを実行します。 作業中、彼は定期的に同期オブジェクトをキャプチャしてリリースします。 キャプチャからリリースまでの時間はランダムですが、平均すると、設定した値になる傾向があります。 たとえば、1秒間に15,000回ロックを使用し、そのロックの50%を保持するとします。 この場合、タイムラインは次のようになります。 赤色はロックがキャプチャされた時間、灰色は解放された時間を意味します。

これは基本的にポアソン過程です。 1つの乱数を生成する平均時間(および、これは、たとえば、2.66 GHzクアッドコアXeonプロセッサで6.349ナノ秒 )がわかっている場合-数秒ではなく、いくつかの単位で行われた作業量を測定できます。 別の記事で説明されている手法を使用して、同期オブジェクトの取得と解放の間の作業単位の数を決定できます。 これがC ++実装です。 関係のない詳細は一部省略しましたが、 こちらから完全なソースコードをダウンロードできます。
QueryPerformanceCounter(&start); for (;;) { // workunits = (int) (random.poissonInterval(averageUnlockedCount) + 0.5f); for (int i = 1; i < workunits; i++) random.integer(); // workDone += workunits; QueryPerformanceCounter(&end); elapsedTime = (end.QuadPart - start.QuadPart) * ooFreq; if (elapsedTime >= timeLimit) break; // EnterCriticalSection(&criticalSection); workunits = (int) (random.poissonInterval(averageLockedCount) + 0.5f); for (int i = 1; i < workunits; i++) random.integer(); // workDone += workunits; LeaveCriticalSection(&criticalSection); QueryPerformanceCounter(&end); elapsedTime = (end.QuadPart - start.QuadPart) * ooFreq; if (elapsedTime >= timeLimit) break; }
ここで、それぞれが独自のプロセッサコアで2つのスレッドを起動したと想像してみましょう。 各スレッドは、その動作時間の50%のロックを保持しますが、別のスレッドが保持している間に1つのスレッドがクリティカルセクションにアクセスしようとすると、強制的に待機します。 共有リソースの闘争の典型的なケース。

これは、実際のアプリケーションでロックがどのように使用されるかのかなりおおよその例だと思います。 上記のコードを2つのスレッドで実行すると、各スレッドが待機時間の約25%を費やし、実際の作業を行う時間の75%しかありません。 2つのスレッドを組み合わせることで、シングルスレッドソリューションと比較して生産性が1.5倍向上します。
このテストは、2.66 GHzクアッドコアXeonプロセッサ(それぞれ1つのコア、2つのスレッド、4つのスレッド)でさまざまなバリエーションで実行しました。 また、ロックキャプチャの期間を、ロックがスレッドの作業時間の100%を費やした反対側に、すぐにロックが解除された縮退した場合から変更しました。 すべての場合において、キャプチャ頻度は一定のままでした-1秒あたり15,000回。
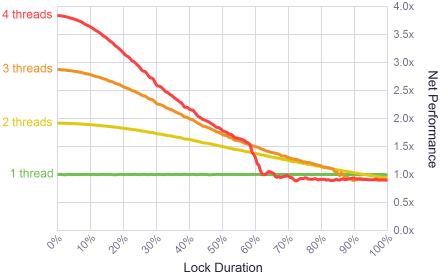
結果は非常に興味深いものでした。 キャプチャ期間が短い場合(時間の10%までと言います)、システムは非常に高い並列度を示しました。 完璧ではないが、それに近い。 ロックは高速に動作します!
実際のアプリケーションの観点から結果を評価するために、プロファイラーを使用してマルチスレッドゲームのメモリアロケーターの動作を分析しました。 ゲーム中に、3つのスレッドから約15,000のアロケーターが呼び出され、アプリケーションのパフォーマンス全体の約2%がブロックされました。 この値は、グラフの左側の「快適ゾーン」にあります。
これらの結果は、ロック内のコードの持続時間がgracinaを合計時間の90%に渡すとすぐに、マルチスレッドコードを記述する意味がなくなることも示しています。 この場合、シングルスレッドアプリケーションはより高速に動作します。 さらに驚くべきことに、これは60%の領域で4つのストリームのパフォーマンスを大幅に低下させます。 それは異常のようなものだったので、テストを数回繰り返し、異なる順序でテストを実行しようとしました。 しかし、毎回同じことが判明しました。 私の最良の推測は、スレッドの数、ロックの期間、およびCPU負荷のこの組み合わせにより、Windowsスケジューラが極端な動作モードになったが、それ以上の調査は行わなかったことです。
ベンチマークロックキャプチャ頻度
軽量のミューテックスでさえ、いくらかのオーバーヘッドを伴います。 Windowsのクリティカルセクションのロック/ロック解除操作のペアは、約23.5ナノ秒(上記のプロセッサで)実行されます。 したがって、1秒あたり15,000のロックでも、パフォーマンスに影響を与える大きな負荷はかかりません。 しかし、周波数を上げるとどうなりますか?
上記のアルゴリズムは、ロック間で実行される作業量を制御する非常に便利な手段を提供します。 別の一連のテストを実行しました。ロック間で10ナノ秒から31マイクロ秒で、これは1秒あたり約32,000のロックに相当します。 各テストでは、2つのスレッドが使用されました。

ご想像のとおり、非常に高い周波数では、ロックのオーバーヘッドが全体的なパフォーマンスに影響を与え始めます。 このような頻度では、ロック内で実行される命令はわずかであり、同期オブジェクト自体のキャプチャ/リリースに匹敵します。 幸いなことに、このような短い(したがって単純な)操作の場合、何らかのロックフリーアルゴリズムを開発して使用することができます。
同時に、結果は、1秒あたり最大320,000回(ロック間の3.1マイクロ秒)までロックを呼び出すことが非常に効果的であることを示しました。 ゲーム開発では、メモリアロケーターはゲームのロード中に同様の頻度で正常に動作できます。 この場合、マルチスレッドから最大1.5倍のゲインが得られます(ただし、ロック自体の期間が短い場合のみ)。
ロックの非常に高いパフォーマンスから、マルチスレッド化自体が意味をなさないケースまで、ロックを使用するさまざまなケースを調査しました。 ゲームエンジンのメモリアロケーターを使用した例では、実際のアプリケーションでは、特定の条件下で高い頻度でロックを使用できることが示されています。 このような議論では、「ロックの動作が遅い」と単純に言うことはできません。 はい、ロックは非効率的な方法で使用できますが、この恐怖に耐える価値はありません。幸いなことに、このような問題を簡単に特定できるプロファイラーがあります。 エキサイティングで危険なロックフリープログラミングの渦に真っ向から突入したいときはいつでも、この記事とロックが非常に迅速に機能するという事実を思い出してください。
この記事の目的は、当然のことながら、ロックに少しだけ敬意を払うことでした。 産業用ソフトウェアでロックを使用するためのすべての豊富なオプションにより、プログラマーは、パフォーマンスのバランスを見つける過程で成功と苦痛の両方を伴うことを理解しています。 これまたはその例があれば、コメントでそれを教えてください。