テストがソフトウェア製品の開発において重要な役割を果たすと言ったら、それが啓示にならないことを願っています。 テストがうまくいけば、最終製品も良くなるはずです。
多くの場合、プログラムコードのテストが非常に骨の折れる状況に遭遇する可能性があり、データベースをテストする時間が残っていないか、残余の原則に従って行われます。 この言葉遣いは非常に抑制されており、実際にはすべてがさらに悪化することを強調します。
その結果、データベースの操作がアプリケーションのパフォーマンスのボトルネックになる可能性があります。
この種の問題を解決するには、データベーステストのさまざまな側面を検討することをお勧めします。 これらには、単体テストの助けを借りたSQL Server全体の負荷テストとパフォーマンステストが含まれます。
いくつかの抽象的なタスクを取ります。 たとえば、オンラインストア用のエンジンを開発しています。 顧客の販売量、商品の種類が異なる場合がありますが、過負荷にならないように、構造を比較的単純なベースにします。
データベーススキーマ
USE [master] GO IF DB_ID('db_sales') IS NOT NULL BEGIN ALTER DATABASE [db_sales] SET SINGLE_USER WITH ROLLBACK IMMEDIATE DROP DATABASE [db_sales] END GO CREATE DATABASE [db_sales] GO USE [db_sales] GO CREATE TABLE dbo.Customers ( [CustomerID] INT IDENTITY PRIMARY KEY , [FullName] NVARCHAR(150) , [Email] VARCHAR(50) NOT NULL , [Phone] VARCHAR(50) ) GO CREATE TABLE dbo.Products ( [ProductID] INT IDENTITY PRIMARY KEY , [Name] NVARCHAR(150) NOT NULL , [Price] MONEY NOT NULL CHECK (Price > 0) , [Image] VARBINARY(MAX) NULL , [Description] NVARCHAR(MAX) ) GO CREATE TABLE dbo.Orders ( [OrderID] INT IDENTITY PRIMARY KEY , [CustomerID] INT NOT NULL , [OrderDate] DATETIME NOT NULL DEFAULT GETDATE() , [CustomerNotes] NVARCHAR(MAX) , [IsProcessed] BIT NOT NULL DEFAULT 0 ) GO ALTER TABLE dbo.Orders WITH NOCHECK ADD CONSTRAINT FK_Orders_CustomerID FOREIGN KEY (CustomerID) REFERENCES dbo.Customers (CustomerID) GO ALTER TABLE dbo.Orders CHECK CONSTRAINT FK_Orders_CustomerID GO CREATE TABLE dbo.OrderDetails ( [OrderID] INT NOT NULL , [ProductID] INT NOT NULL , [Quantity] INT NOT NULL CHECK (Quantity > 0) , PRIMARY KEY (OrderID, ProductID) ) GO ALTER TABLE dbo.OrderDetails WITH NOCHECK ADD CONSTRAINT FK_OrderDetails_OrderID FOREIGN KEY (OrderID) REFERENCES dbo.Orders (OrderID) GO ALTER TABLE dbo.OrderDetails CHECK CONSTRAINT FK_OrderDetails_OrderID GO ALTER TABLE dbo.OrderDetails WITH NOCHECK ADD CONSTRAINT FK_OrderDetails_ProductID FOREIGN KEY (ProductID) REFERENCES dbo.Products (ProductID) GO ALTER TABLE dbo.OrderDetails CHECK CONSTRAINT FK_OrderDetails_ProductID GO
また、シンクライアントが事前に作成されたストアドプロシージャを介してデータベースを操作するとします。 それらはすべて非常に単純です。 新しいユーザーを挿入するか、既存のユーザーのIDを取得します 。
CREATE PROCEDURE dbo.GetCustomerID ( @FullName NVARCHAR(150) , @Email VARCHAR(50) , @Phone VARCHAR(50) , @CustomerID INT OUT ) AS BEGIN SET NOCOUNT ON; SELECT @CustomerID = CustomerID FROM dbo.Customers WHERE Email = @Email IF @CustomerID IS NULL BEGIN INSERT INTO dbo.Customers (FullName, Email, Phone) VALUES (@FullName, @Email, @Phone) SET @CustomerID = SCOPE_IDENTITY() END END
新しい注文をする:
CREATE PROCEDURE dbo.CreateOrder ( @CustomerID INT , @CustomerNotes NVARCHAR(MAX) , @Products XML ) AS BEGIN SET NOCOUNT ON; DECLARE @OrderID INT INSERT INTO dbo.Orders (CustomerID, CustomerNotes) VALUES (@CustomerID, @CustomerNotes) SET @OrderID = SCOPE_IDENTITY() INSERT INTO dbo.OrderDetails (OrderID, ProductID, Quantity) SELECT @OrderID , tcvalue('@ProductID', 'INT') , tcvalue('@Quantity', 'INT') FROM @Products.nodes('items/item') t(c) END
要求を実行するときに最小限の応答を保証するタスクに直面していると仮定します。 空のベースでは、たとえパフォーマンスが問題になっても、ほとんど期待できません。 したがって、手順のパフォーマンスをテストするには、少なくともいくつかのテストデータが必要です。 オプションとして、スクリプトを使用して、 Customersテーブルのテストデータを生成します。
スクリプト
DECLARE @obj INT = OBJECT_ID('dbo.Customers') , @sql NVARCHAR(MAX) , @cnt INT = 10 ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b) SELECT @sql = ' DELETE FROM ' + QUOTENAME(OBJECT_SCHEMA_NAME(@obj)) + '.' + QUOTENAME(OBJECT_NAME(@obj)) + ' ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b) INSERT INTO ' + QUOTENAME(OBJECT_SCHEMA_NAME(@obj)) + '.' + QUOTENAME(OBJECT_NAME(@obj)) + '(' + STUFF(( SELECT ', ' + QUOTENAME(name) FROM sys.columns c WHERE c.[object_id] = @obj AND c.is_identity = 0 AND c.is_computed = 0 FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '') + ') SELECT TOP(' + CAST(@cnt AS VARCHAR(10)) + ') ' + STUFF(( SELECT ' , ' + QUOTENAME(name) + ' = ' + CASE WHEN TYPE_NAME(c.system_type_id) IN ( 'varchar', 'char', 'nvarchar', 'nchar', 'ntext', 'text' ) THEN ( STUFF(( SELECT TOP( CASE WHEN max_length = -1 THEN CAST(RAND() * 10000 AS INT) ELSE max_length END / CASE WHEN TYPE_NAME(c.system_type_id) IN ('nvarchar', 'nchar', 'ntext') THEN 2 ELSE 1 END ) '+SUBSTRING(x, (ABS(CHECKSUM(NEWID())) % 80) + 1, 1)' FROM E8 FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 1, '') ) WHEN TYPE_NAME(c.system_type_id) = 'tinyint' THEN '50 + CRYPT_GEN_RANDOM(10) % 50' WHEN TYPE_NAME(c.system_type_id) IN ('int', 'bigint', 'smallint') THEN 'CRYPT_GEN_RANDOM(10) % 25000' WHEN TYPE_NAME(c.system_type_id) = 'uniqueidentifier' THEN 'NEWID()' WHEN TYPE_NAME(c.system_type_id) IN ('decimal', 'float', 'money', 'smallmoney') THEN 'ABS(CAST(NEWID() AS BINARY(6)) % 1000) * RAND()' WHEN TYPE_NAME(c.system_type_id) IN ('datetime', 'smalldatetime', 'datetime2') THEN 'DATEADD(MINUTE, RAND(CHECKSUM(NEWID())) * (1 + DATEDIFF(MINUTE, ''20000101'', GETDATE())), ''20000101'')' WHEN TYPE_NAME(c.system_type_id) = 'bit' THEN 'ABS(CHECKSUM(NEWID())) % 2' WHEN TYPE_NAME(c.system_type_id) IN ('varbinary', 'image', 'binary') THEN 'CRYPT_GEN_RANDOM(5)' ELSE 'NULL' END FROM sys.columns c WHERE c.[object_id] = @obj AND c.is_identity = 0 AND c.is_computed = 0 FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 8, ' ') + ' FROM E8 CROSS APPLY ( SELECT x = ''0123456789-ABCDEFGHIJKLMNOPQRSTUVWXYZ abcdefghijklmnopqrstuvwxyz'' ) t' EXEC sys.sp_executesql @sql
スクリプトは、任意の構造を持つテーブルのランダムテストデータを生成するために作成されました。 その結果、汎用性は得られましたが、リアリズムは失われました。
CustomerID FullName Email Phone ----------- ------------------------------------ ---------------- --------------- 1 uN9UiFZ9i0pALwQXIfC628Ecw35VX9L i6D0FNBuKo9I ZStNRH8t1As2S 2 Jdi6M0BqxhE-7NEvC1 a12 UTjK28OSpTHx 7DW2HEv0WtGN 3 0UjI9pIHoyeeCEGHHT6qa2 2hUpYxc vN mqLlO 7c R5 U3ha 4 RMH-8DKAmewi2WdrvvHLh w-FIa wrb uH 5 h76Zs-cAtdIpw0eewYoWcY2toIo g5pDTiTP1Tx qBzJw8Wqn 6 jGLexkEY28Qd-OmBoP8gn5OTc FESwE l CkgomDyhKXG 7 09X6HTDYzl6ydcdrYonCAn6qyumq9 EpCkxI01tMHcp eOh7IFh 8 LGdGeF5YuTcn2XkqXT-92 cxzqJ4Y cFZ8yfEkr 9 7 Ri5J30ZtyWBOiUaxf7MbEKqWSWEvym7 0C-A7 R74Yc KDRJXX hw 10 D DzeE1AxUHAX1Bv3eglY QsZdCzPN0 RU-0zVGmU
もちろん、同じCustomersテーブルに対してより現実に近いデータを生成するクエリを作成することを誰も気にしません。
DECLARE @cnt INT = 10 DELETE FROM dbo.Customers ;WITH E1(N) AS ( SELECT * FROM ( VALUES (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N) AS (SELECT 1 FROM E1 a, E1 b), E4(N) AS (SELECT 1 FROM E2 a, E2 b), E8(N) AS (SELECT 1 FROM E4 a, E4 b) INSERT INTO dbo.Customers (FullName, Email, Phone) SELECT TOP(@cnt) [FullName] = txt , [Email] = LOWER(txt) + LEFT(ABS(CHECKSUM(NEWID())), 3) + '@gmail.com' , [Phone] = '+38 (' + LEFT(ABS(CHECKSUM(NEWID())), 3) + ') ' + STUFF(STUFF(LEFT(ABS(CHECKSUM(NEWID())), 9) , 4, 1, '-') , 7, 1, '-') FROM E8 CROSS APPLY ( SELECT TOP(CAST(RAND(N) * 10 AS INT)) txt FROM ( VALUES (N'Boris_the_Blade'), (N'John'), (N'Steve'), (N'Mike'), (N'Phil'), (N'Sarah'), (N'Ann'), (N'Andrey'), (N'Liz'), (N'Stephanie') ) t(txt) ORDER BY NEWID() ) t
これはもう少し現実的になりました。
FullName Email Phone --------------- -------------------------- ------------------- Boris_the_Blade boris_the_blade1@gmail.com +38 (146) 296-33-10 John john130@mail.com +38 (882) 688-98-59 Phil phil155@gmail.com +38 (125) 451-73-71 Mike mike188@gmail.com +38 (111) 169-59-14 Sarah sarah144@gmail.com +38 (723) 124-50-60 Andrey andrey310@gmail.com +38 (193) 160-91-48 Stephanie stephanie188@gmail.com +38 (590) 128-86-02 John john723@gmail.com +38 (194) 101-06-65 Phil phil695@gmail.com +38 (164) 180-57-37 Mike mike200@gmail.com +38 (110) 131-89-45
ただし、テーブル間に外部キーがあることを忘れないでください。他のすべてのエンティティの一貫性のあるデータを生成することは、すでに一桁難しくなっています。 この問題の解決策を考え出さないために、データベース内のテーブルに意味のあるテストデータを作成できる日付ジェネレーターのいずれかを使用することをお勧めします。
SELECT TOP 10 * FROM dbo.Customers ORDER BY NEWID()
CustomerID FullName Email Phone ----------- -------------- ----------------------------------- ----------------- 18319 Noe Pridgen Doyle@example.com (682) 219-7793 8797 Ligia Gaddy CrandallR9@nowhere.com (623) 144-6165 14712 Marry Almond Cloutier39@nowhere.com (601) 807-2247 8280 NULL Lawrence_Z_Mortensen85@nowhere.com (710) 442-3219 8012 Noah Tyler RickieHoman867@example.com (944) 032-0834 15355 Fonda Heard AlfonsoGarcia@example.com (416) 311-5605 10715 Colby Boyd Iola_Daily@example.com (718) 164-1227 14937 Carmen Benson Dennison471@nowhere.com (870) 106-6468 13059 Tracy Cornett DaniloBills@example.com (771) 946-5249 7092 Jon Conaway Joey.Redman844@example.com (623) 140-7543
テストデータの準備ができました。 ストアドプロシージャのパフォーマンスのテストに移りましょう。
クライアントIDを返すGetCustomerIDプロシージャがあります;存在しない場合は、 Customersテーブルに対応するエントリを作成します。 まず、現在の実行計画の表示を有効にして、実行してみましょう。
DECLARE @CustomerID INT EXEC dbo.GetCustomerID @FullName = N'' , @Email = 'sergeys@mail.ru' , @Phone = '7105445' , @CustomerID = @CustomerID OUT SELECT @CustomerID
実行計画は、クラスターインデックスのフルスキャンがあることを示しています。

これを行うには、 SQL Serverがテーブルから200回の論理読み取りを行う必要があり、これにはすべて約20ミリ秒かかります。
Table 'Customers'. Scan count 1, logical reads 200, physical reads 0, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 20 ms.
しかし、私たちは1つのリクエストの実行時間について話しています。 このストアドプロシージャが非常にアクティブな場合 インデックスを常にスキャンすると、サーバーのパフォーマンスが低下します。
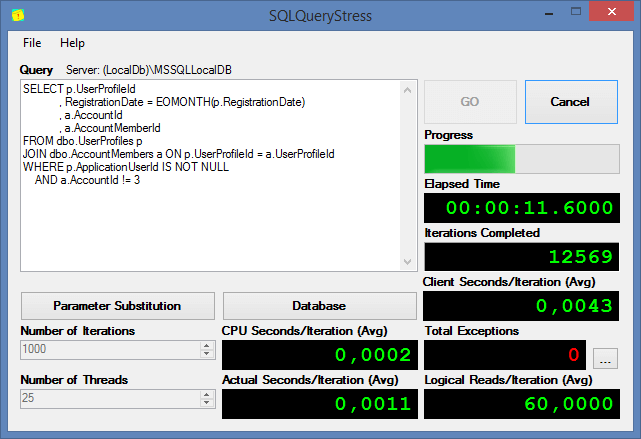
Adam Machanicが開発した興味深いオープンソースSQLQueryStressツール ( GitHubへのリンク)を使用して、ストアドプロシージャのストレステストを試してみましょう。

2つのスレッドでGetCustomerIDプロシージャを2000回呼び出すのにかかる時間は、サーバー上で4秒弱でした。 次に、検索を実行するフィールドにインデックスを追加するとどうなるかを見てみましょう。
CREATE NONCLUSTERED INDEX IX_Email ON dbo.Customers (Email)
実行計画では、 インデックススキャンの代わりにインデックス シークが表示されました。

論理読み取りと全体的なランタイムの削減:
Table 'Customers'. Scan count 1, logical reads 2, ... SQL Server Execution Times: CPU time = 0 ms, elapsed time = 8 ms.
SQLQueryStressでストレステストを繰り返すと、この手順によりサーバーの負荷が軽減され、実行速度が速くなることがわかります。

SQLQueryStressを使用して、一括注文をエミュレートしてみてください。
DECLARE @CustomerID INT , @CustomerNotes NVARCHAR(MAX) , @Products XML SELECT TOP(1) @CustomerID = CustomerID , @CustomerNotes = REPLICATE('a', RAND() * 100) FROM dbo.Customers ORDER BY NEWID() SELECT @Products = ( SELECT [@ProductID] = ProductID , [@Quantity] = CAST(RAND() * 10 AS INT) FROM dbo.Products ORDER BY ProductID OFFSET CAST(RAND() * 1000 AS INT) ROWS FETCH NEXT CAST(RAND() * 10 AS INT) + 1 ROWS ONLY FOR XML PATH('item'), ROOT('items') ) EXEC dbo.CreateOrder @CustomerID = @CustomerID , @CustomerNotes = @CustomerNotes , @Products = @Products

2つのスレッドで同時に100回プロシージャを実行すると、2.5秒かかりました。 期待値の統計をクリアしましょう:
DBCC SQLPERF("sys.dm_os_wait_stats", CLEAR)
もう一度SQLQueryStressを実行し、ストアドプロシージャの実行中に発生したことを確認します。
wait_type wait_time --------------------------------- ----------- WRITELOG 2.394000 PARALLEL_REDO_WORKER_WAIT_WORK 0.264000 PAGEIOLATCH_SH 0.157000 ASYNC_NETWORK_IO 0.125000 PAGEIOLATCH_UP 0.097000 PREEMPTIVE_OS_FLUSHFILEBUFFERS 0.049000 IO_COMPLETION 0.048000 PAGEIOLATCH_EX 0.043000 PREEMPTIVE_OS_WRITEFILEGATHER 0.037000 LCK_M_IX 0.033000
そもそもWRITELOGであることがわかります。これは、ストレステストの合計実行時間にほぼ対応しています。 この遅延はどういう意味ですか? 各挿入コマンドはアトミックであるため、実行後はログの変更が物理的に固定されます。 多数の短いトランザクションがある場合、データファイルとは異なり、ログの操作は同期的に発生するため、キューが発生します。
SQL Server 2014では、データベースレベルで有効になっている遅延耐久性ログへの遅延ログを構成する機能が追加されました。
ALTER DATABASE db_sales SET DELAYED_DURABILITY = ALLOWED
そして、ストアドプロシージャをわずかに変更するだけで済みます。
ALTER PROCEDURE dbo.CreateOrder ( @CustomerID INT , @CustomerNotes NVARCHAR(MAX) , @Products XML ) AS BEGIN SET NOCOUNT ON; BEGIN TRANSACTION t DECLARE @OrderID INT INSERT INTO dbo.Orders (CustomerID, CustomerNotes) VALUES (@CustomerID, @CustomerNotes) SET @OrderID = SCOPE_IDENTITY() INSERT INTO dbo.OrderDetails (OrderID, ProductID, Quantity) SELECT @OrderID , tcvalue('@ProductID', 'INT') , tcvalue('@Quantity', 'INT') FROM @Products.nodes('items/item') t(c) COMMIT TRANSACTION t WITH (DELAYED_DURABILITY = ON) END
統計をクリアして、ストレステストを再度実行します。

合計実行時間が半分になり、 WRITELOGの遅延が最小になったことがわかります。
wait_type wait_time -------------------------- ---------- PREEMPTIVE_OS_WRITEFILE 0.027000 PAGEIOLATCH_EX 0.024000 PAGELATCH_EX 0.020000 WRITELOG 0.014000
次に、特定のリクエストのパフォーマンスを定期的にチェックする必要がある場合の別の状況を検討します。 これにSQLQueryStressを使用するのはそれほど便利ではありません。アプリケーションを開き、そこにクエリをコピーして実行を待機する必要があるからです。
これは自動化できますか?..
2014年、私は最初にtSQLtに出会いました 。これは非常に素晴らしい無料の単体テストフレームワークであることが判明しました。 tSQLtをインストールし、 それを使用して自動テストを作成して、ストアドプロシージャのパフォーマンスをテストしてみましょう。
tSQLtの最新バージョンをダウンロードし、 CLRと連携するようにSQL Serverのインスタンスを構成します。
EXEC sys.sp_configure 'clr enabled', 1 RECONFIGURE GO ALTER DATABASE [db_sales] SET TRUSTWORTHY ON GO
その後、データベースのアーカイブからtSQLt.class.sqlスクリプトを実行します。 スクリプトは、独自のtSQLtスキーマ、 CLRアセンブリ、および多くのスクリプトオブジェクトを作成します。 一部のプロシージャには、フレームワーク自体による内部使用を目的としたPrivate_プレフィックスが含まれます。
すべてが正しくインストールされている場合、 出力に次のメッセージが表示されます。
+-----------------------------------------+ | | | Thank you for using tSQLt. | | | | tSQLt Version: 1.0.5873.27393 | | | +-----------------------------------------+
次に、自動テストを作成する回路を作成します。
USE [db_sales] GO CREATE SCHEMA [Performance] GO EXEC sys.sp_addextendedproperty @name = N'tSQLt.Performance' , @value = 1 , @level0type = N'SCHEMA' , @level0name = N'Performance' GO
拡張プロパティは、オブジェクトがtSQLt機能に属するかどうかを決定することに注意してください。
テスト名にテストプレフィックスを指定して、パフォーマンススキーマにテストを作成します。
CREATE PROCEDURE [Performance].[test ProcTimeExecution] AS BEGIN SET NOCOUNT ON; EXEC tSQLt.Fail 'TODO: Implement this test.' END
作成された自動テストを実行しようとします。 これを行うには、次のいずれかを実行できます。
EXEC tSQLt.RunAll
または、スキームを明示的に指定します。
EXEC tSQLt.Run 'Performance'
または特定のテスト:
EXEC tSQLt.Run 'Performance.test ProcTimeExecution'
最後に完了したテストを実行する場合、パラメーターなしでRunを呼び出すことができます。
EXEC tSQLt.Run
上記のコマンドのいずれかを実行すると、次の情報が取得されます。
[Performance].[test ProcTimeExecution] failed: (Failure) TODO: Implement this test. +----------------------+ |Test Execution Summary| +----------------------+ |No|Test Case Name |Dur(ms)|Result | +--+--------------------------------------+-------+-------+ |1 |[Performance].[test ProcTimeExecution]| 0|Failure|
自動テストの内容をもっと便利なものに変更してみましょう。 たとえば、未処理の注文のリストを返すGetUnprocessedOrdersプロシージャを使用します。
CREATE PROCEDURE dbo.GetUnprocessedOrders AS BEGIN SET NOCOUNT ON; SELECT o.OrderID , o.OrderDate , c.FullName , c.Email , c.Phone , OrderSum = ( SELECT SUM(p.Price + d.Quantity) FROM dbo.OrderDetails d JOIN dbo.Products p ON d.ProductID = p.ProductID WHERE d.OrderID = o.OrderID ) FROM dbo.Orders o JOIN dbo.Customers c ON o.CustomerID = c.CustomerID WHERE o.IsProcessed = 0 END
そして、n番目の回数だけプロシージャを実行し、平均実行時間が指定されたしきい値よりも大きい場合はエラーで終了する自動テストを作成します。
ALTER PROCEDURE [Performance].[test ProcTimeExecution] AS BEGIN SET NOCOUNT ON; DECLARE @time DATETIME , @duration BIGINT = 0 , @cnt TINYINT = 10 WHILE @cnt > 0 BEGIN SET @time = GETDATE() EXEC dbo.GetUnprocessedOrders SET @duration += DATEDIFF(MILLISECOND, @time, GETDATE()) SET @cnt -= 1 END IF @duration / 10 > 100 BEGIN DECLARE @txt NVARCHAR(MAX) = 'High average execution time: ' + CAST(@duration / 10 AS NVARCHAR(10)) + ' ms' EXEC tSQLt.Fail @txt END END
自動テストを実行します。
EXEC tSQLt.Run 'Performance'
そして、次のメッセージが表示されます。
[Performance].[test ProcTimeExecution] failed: (Error) High execution time: 161 ms +----------------------+ |Test Execution Summary| +----------------------+ |No|Test Case Name |Dur(ms)|Result| +--+--------------------------------------+-------+------+ |1 |[Performance].[test ProcTimeExecution]| 1620|Error |
リクエストを最適化して、テストに合格してみましょう。 まず、実行計画を見てください。

多くの場合、問題はProductsテーブルのクラスター化インデックスにアクセスしていることがわかります。 多数の論理読み取り値もこのステートメントを確認します。
Table 'Customers'. Scan count 1, logical reads 200, ... Table 'Orders'. Scan count 1, logical reads 3886, ... Table 'Products'. Scan count 0, logical reads 73607, ... Table 'OrderDetails'. Scan count 1, logical reads 235, ...
どうすれば状況を修正できますか? 非クラスター化インデックスを追加し、そこに[ 価格]フィールドを含めたり、別のテーブルで値の予備計算を行ったり、集約インデックス表現を作成したりできます。
CREATE VIEW dbo.vwOrderSum WITH SCHEMABINDING AS SELECT d.OrderID , OrderSum = SUM(p.Price + d.Quantity) , OrderCount = COUNT_BIG(*) FROM dbo.OrderDetails d JOIN dbo.Products p ON d.ProductID = p.ProductID GROUP BY d.OrderID GO CREATE UNIQUE CLUSTERED INDEX IX_OrderSum ON dbo.vwOrderSum (OrderID)
そして、ストアドプロシージャを変更します。
ALTER PROCEDURE dbo.GetUnprocessedOrders AS BEGIN SET NOCOUNT ON; SELECT o.OrderID , o.OrderDate , c.FullName , c.Email , c.Phone , s.OrderSum FROM dbo.Orders o JOIN dbo.Customers c ON o.CustomerID = c.CustomerID JOIN dbo.vwOrderSum s WITH(NOEXPAND) ON o.OrderID = s.OrderID WHERE o.IsProcessed = 0 END
オプティマイザーがビューのインデックスを常に使用するように強制するには、 NOEXPANDヒントを指定することをお勧めします。 さらに、 Ordersからの論理読み取りの数を減らすために、フィルター処理されたインデックスを作成できます。
CREATE NONCLUSTERED INDEX IX_UnProcessedOrders ON dbo.Orders (OrderID, CustomerID, OrderDate) WHERE IsProcessed = 0
これで、ストアドプロシージャを実行するときに、より単純なプランが使用されます。

論理読み取り値が少なくなります。
Table 'Customers'. Scan count 1, logical reads 200, ... Table 'Orders'. Scan count 1, logical reads 21, ... Table 'vwOrderSum'. Scan count 1, logical reads 44, ...
ストアドプロシージャの実行が削減され、テストが成功します。
|No|Test Case Name |Dur(ms)|Result | +--+--------------------------------------+-------+-------+ |1 |[Performance].[test ProcTimeExecution]| 860|Success|
私たちは管理したと言える。 すべてのボトルネックを最適化し、本当にクールな製品を作りました。 しかし、それに直面しましょう。 データには蓄積する機能があり、 SQL Serverは予想される行数に基づいて実行計画を生成します。 現在、成長のテストを行っていますが、1年の作業の後、実装計画が効果的である、スキームが変更されない、誰かが誤って目的のインデックスを削除しないなどの保証はありません...したがって、この種の自動テストを定期的に実行することは非常に重要です、問題をすばやく特定します。
それでは、単体テストの助けを借りて、このような有用な方法を他に何ができるかを見てみましょう。
たとえば、すべての実行プランで、セクションMissingIndexGroupがあるかどうかを確認できます。 存在する場合、SQL Serverは特定のクエリのインデックスが欠落していると見なします。
CREATE PROCEDURE [Performance].[test MissingIndexes] AS BEGIN SET NOCOUNT ON DECLARE @msg NVARCHAR(MAX) , @rn INT SELECT t.text , p.query_plan , q.total_worker_time / 100000. FROM ( SELECT TOP 100 * FROM sys.dm_exec_query_stats ORDER BY total_worker_time DESC ) q CROSS APPLY sys.dm_exec_sql_text(q.sql_handle) t CROSS APPLY sys.dm_exec_query_plan(q.plan_handle) p WHERE p.query_plan.exist('//*:MissingIndexGroup') = 1 SET @rn = @@ROWCOUNT IF @rn > 0 BEGIN SET @msg = 'Missing index in ' + CAST(@rn AS VARCHAR(10)) + ' queries' EXEC tSQLt.Fail @msg END END
未使用のインデックスの検索を自動化することもできます。 これはすべて非常に簡単に行われます-dm_db_index_usage_statsの特定のインデックスの使用に関する統計を見つけるだけです :
CREATE PROCEDURE [Performance].[test UnusedUndexes] AS BEGIN DECLARE @tables INT , @indexes INT , @msg NVARCHAR(MAX) SELECT @indexes = COUNT(*) , @tables = COUNT(DISTINCT o.[object_id]) FROM sys.objects o CROSS APPLY ( SELECT s.index_id , index_usage = s.user_scans + s.user_lookups + s.user_seeks , usage_percent = (s.user_scans + s.user_lookups + s.user_seeks) * 100. / NULLIF(SUM(s.user_scans + s.user_lookups + s.user_seeks) OVER (), 0) , index_count = COUNT(*) OVER () FROM sys.dm_db_index_usage_stats s WHERE s.database_id = DB_ID() AND s.[object_id] = o.[object_id] ) t WHERE o.is_ms_shipped = 0 AND o.[schema_id] != SCHEMA_ID('tSQLt') AND o.[type] = 'U' AND ( (t.usage_percent < 5 AND t.index_usage > 100 AND t.index_count > 1) OR t.index_usage = 0 ) IF @tables > 0 BEGIN SET @msg = 'Database contains ' + CAST(@indexes AS VARCHAR(10)) + ' unused indexes in ' + CAST(@tables AS VARCHAR(10)) + ' tables' EXEC tSQLt.Fail @msg END END
大規模で複雑なシステムを開発する場合、多くの場合、システムにテーブルが追加され、そこにデータが挿入され、その存在を忘れたという状況に対応することができます。
そのようなテーブルを定義するには? たとえば、それらへのリンクはありません;サーバーが起動してからこれらのテーブルからの選択は発生していませんが、サーバーが1週間以上実行されている場合に限ります。 条件は相対的であり、特定のタスクごとに変更できます。
CREATE PROCEDURE [Performance].[test UnusedTables] AS BEGIN SET NOCOUNT ON DECLARE @msg NVARCHAR(MAX) , @rn INT , @txt NVARCHAR(1000) = N'Starting up database ''' + DB_NAME() + '''.' DECLARE @database_start TABLE ( log_date SMALLDATETIME, spid VARCHAR(50), msg NVARCHAR(4000) ) INSERT INTO @database_start EXEC sys.xp_readerrorlog 0, 1, @txt SELECT o.[object_id] , [object_name] = SCHEMA_NAME(o.[schema_id]) + '.' + o.name FROM sys.objects o WHERE o.[type] = 'U' AND o.is_ms_shipped = 0 AND o.[schema_id] != SCHEMA_ID('tSQLt') AND NOT EXISTS( SELECT * FROM sys.dm_db_index_usage_stats s WHERE s.database_id = DB_ID() AND s.[object_id] = o.[object_id] AND ( s.user_seeks > 0 OR s.user_scans > 0 OR s.user_lookups > 0 OR s.user_updates > 0 ) ) AND NOT EXISTS( SELECT * FROM sys.sql_expression_dependencies s WHERE o.[object_id] IN (s.referencing_id, s.referenced_id) ) AND EXISTS( SELECT 1 FROM @database_start t HAVING MAX(t.log_date) < DATEADD(DAY, -7, GETDATE()) ) SET @rn = @@ROWCOUNT IF @rn > 0 BEGIN SET @msg = 'Database contains ' + CAST(@rn AS VARCHAR(10)) + ' unused tables' EXEC tSQLt.Fail @msg END END
そして、そのようなテストは、私が上で引用したように、あなたはもっと多くを作成することができます...
結論として、私は正直に、以前に書かれたものに他に何を追加できるかを知りません。 おそらく1つだけです。 tSQLtとSQLQueryStressを試してください。 これらの製品は完全に無料であり、実際には、 SQL Serverのストレステストおよびサーバーのパフォーマンスの最適化中に何度も助けてくれました。