 ゲームエンジンの内部に入り、そこからあらゆる種類のコンテンツを引き出す方法に関する一連の記事を続けます。 参加したばかりの人たちのために、視覚的な短編小説のような面白いジャンルを研究したことを簡単に思い出します。
ゲームエンジンの内部に入り、そこからあらゆる種類のコンテンツを引き出す方法に関する一連の記事を続けます。 参加したばかりの人たちのために、視覚的な短編小説のような面白いジャンルを研究したことを簡単に思い出します。
ビジュアルノベルエンジンYukaのアーカイブを解析する方法を学んでからかなりの時間が経ちました。そこで、私たちがそこで見つけた最も興味深いもの、実際はスクリプトを取り上げるときが来ました。 スクリプトについては、ファイルを含むアーカイブよりもはるかに複雑な問題であることをすぐに警告します。したがって、1つの記事でそれを理解することはできませんが、今日は、スクリプトがどの部分で構成され、テキストリソース。
バイナリダンプの深さに入る前に、ビジュアルノベルのエンジンのほとんどがどのように機能するかを推定しましょう。 視覚的な短編小説自体は、テキスト(英雄、対話、中間物語の発言)、グラフィックス、および音声で構成されています。 ユーザーに再現するには、何らかの制御アクションを使用してこれらすべてをまとめる必要があることは明らかです。 理論的には、すべてを直接exeファイルに縫うことは可能ですが、99%のケース(大丈夫、嘘、個人的には100%に見られる)では、まだこれを行いませんが、そのような指示を別個のスクリプトプログラムとして個別に保存します。 原則として、スクリプトは次のような特別なプログラミング言語(エンジン固有)で記述されています。
$ tarot = 0 $ memory = 0 scene bg01_1 with dissolve play music "bgm/8.mp3" fadein (2.0) play ambience "amb/forest.mp3" fadein (3.0) "Morning." "Not my favourite time of the day." "The morning is when you're not awake enough to do anything..."
これはRen'Pyの 1つのVNからのスクリプトソースの断片です-最も人気のある無料/無料エンジンの1つです。 この記事では、Ren'Py自体がどれだけ優れているかという質問は別として、今のところは、ビジュアルノベルスクリプトに通常含まれているものと、見つける必要があるものに注目しましょう。
- テキスト-いずれのキャラクターにも属していない(つまり、「ナレーターからのテキスト」-この例のように)、またはまだ誰かによって発音されている
- グラフィックスを表示するチーム-背景/スプライト(
scene bg01_1
)、時には特別な効果(with dissolve
) - 音楽またはサウンドの再生を開始するコマンド(
play music
play ambience
)、いくつかの追加パラメーター、場合によってはフェードインおよびフェードアウトの長さ(音量のスムーズな増加) - 変数を操作:設定(
$ tarot = 0
、チェック、分岐) まだコマンドがあります:
- キャラクターによって配信されたスピーチを再生する
- 管理用
- コメント、タグ、マクロなどのサービス
もちろん、現実の世界では、スクリプトのソースコードにアクセスできないことがよくあります。 人々はすでに(インタープリターではなく)約50年間コンパイラーの作成方法を学んでいるため、通常、スクリプトソースはバイナリコード(バイトコード)にコンパイルされ、ビジュアルノベルエンジン内の仮想マシンによって実行されます。 幸運なこともあり、人気のある一部のエンジンでは、合法的に使用できるツールまたは非常に合法的に使用できないツール(デバッガー、コンパイラー、逆コンパイラー、スクリプトバリデーターなど)がありますが、多くの場合、人生はそれほど単純ではありません。
それでは、以前の記事「 恋する島井の六十三 」で探求し始めたビジュアルノベルに戻りましょう 。 既にアーカイブを解凍し、内部、グラフィックス、サウンド、音楽、そして最も重要で理解できない-拡張子が.yksのファイルを見つけました。 おそらく、彼らは短編小説のスクリプトを構成しています。 ところで、多くのファイルがあります:
YKS/ScriptStart.yks YKS/trial/Yoyaku.yks YKS/trial/trial_00100.yks YKS/trial/trial_00200.yks YKS/all/all_00010.yks ... YKS/all/all_02320.yks
YKS / all /にあるのは103ファイルのみです。 試用版を完全に正直にダウンロードして検討したことを思い出させてください-しかし、どうやら開発者は少し面倒で、どうやら試用版/スクリプトには試用版とすべて/完全版が含まれているようです。
一般に、最小限の経験に基づいて、ビジュアルノベルエンジンのビルダーには2つのアプローチがあります。すべてを1つの巨大なファイルに詰め込むか、多数のファイルがあり、それぞれに独自のシーンまたはイベントがあります。 2番目のようです。 さらに、まだ別のScriptStart.yksがありますが、それ自体はほとんど関心がありません:実際、開発者は多くの場合、エンジンを可能な限り多用途にし、あらゆる種類のユーザーインターフェイス、menus-load-save-optionsなどを実装することを望んでいます.d。 また、そのスクリプト言語によって。 あなたはこれに対処することができますが、むしろ退屈で実りがありません。したがって、私は角で雄牛を取り、ゲームの実際のスクリプトから始めることを提案します。
表面的な目視検査から何が言えるでしょうか? 第一に ゲームはWindows上で実行されるため、実行して外観を確認することは非常に可能です。 n番目の時間を費やし、Windowsマシンを見つけて起動し、新しいゲームのスタートボタンをクリックした直後に何が起こるかを確認します。

物語の始まりが私たちに出会ったようです。 ここには背景があり(BGで簡単に検索した後/この背景を持つbg01_01.pngファイルがあります)、テキストがあります。 このテキストはまだ必要なので、画面から再入力する価値があります。
恋する姉妹の六重奏「セクステット」体験版Ver2をダウンロード頂きありがとうございます。
2つのポイント:
日本語テキストの入力に問題がある場合は、この問題を大幅に簡素化する3つまたは4つのトリックを習得することをお勧めします。少し忍耐強く、波線がまったくわからない人でも日本語テキストを入力できるようにします。 各アイコンを個別に検討します。
- 次のような表の句読点かどうかを確認します。「...」」()。-運がよければコピーします。 ここでは、「コンマ」、「ドット」、および括弧の両方が具体的であるという事実に注意してください。
- そうでない場合は、この表を見てください:あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへまみむめもやゆよらりをれろろろろろろ
- 次に、次のようなものを探します:アイウエオカキクケコサシスセソタチテテトナニヌネノハハヒフヘホマミムメモモヤユヨラリルレロワワワ
- それが役に立たない場合-例えば、恋がキャッチされた-これは漢字です。 次に、フォントを300〜500%増やして、すべての小さな詳細がはっきりと見えるようにし、「ラジカルによる検索」セクションでjisho.orgにアクセスします。 そこで、構成部分(ラジカル)の表を見て、見たものと同様のものを探します。 たとえば、恋-短い瞑想の後、彼はの下にコンポーネントがあることがわかりました-このコンポーネントでボタンを押し続けると、数千のアイコンが数十個しかありません。 彼らの目を通して見て、セクション「10」の問題で最初から5番目のサインを見つけてください-これは望ましいものです。
- Ver2かVSer2があるかはわかりません-これらは異なるフォントではなく、いわゆる全角文字であることに注意してください-Unicodeでは、U + FF01..U + FF5Eリージョンのどこかにあります)。
2つのことについてテキストが必要になります。 まず、テキストとして、何が起こっているのかを理解するために(日本語を話さなくても、Google翻訳に挿入して、このゲームの試用版をダウンロードしてくれたことに感謝します=>つまり、これは本当の始まりではありませんプロット、および特定の紹介、「著者から」)。 次に、このテキストまたはその一部を取得してShiftJISに変換し(前のノートで見たように、すべてがこのエンコーディングに含まれる可能性が高い)、ファイルで検索できます。 最後からピースを取り、探しているものを準備します。
$ echo 'ダウンロード頂きありがとうございます' | iconv -t sjis | hd 00000000 83 5f 83 45 83 93 83 8d 81 5b 83 68 92 b8 82 ab |._.E.....[.h....| 00000010 82 a0 82 e8 82 aa 82 c6 82 a4 82 b2 82 b4 82 a2 |................| 00000020 82 dc 82 b7 |....|
すべての.yksファイルでこの行を探していますが、もちろん見つかりません。 それほど単純ではありません。
別の余談を行ってみましょう。ShiftJISエンコードの仕組みを理解しましょう。 日本語では、明らかに、ヨーロッパよりもはるかに多くのアイコンがあります。ShiftJISでは、各アイコンは少なくとも1バイト、最大2バイトでエンコードされます。 このプレートからわかるように、バイト00..7Fの値はASCIIと同じですが、バイト81..9F E0..EAは、これが2バイトの組み合わせであることを意味します。また、互換性のために、バイナリ読み取りと同様に、2番目のバイトには値がありませんが 、40〜FFの間です。
日本語へのマイクロエクスカーション:言語では3つのグループのアイコンが使用されます。
- ひらがな-次のようになります:ありがとうございます-すなわち 丸みを帯びたシンプルなライティングフォーム。 〜50個のアイコンがありますが、「大i =い、小i =ぃ」など、あらゆる種類のバリエーションがあります。 1音節= 1文字。
- カタカナ-次のようになります:ダウンロード-すなわち 刻まれた正方形のシンプルな印刷フォーム。 音はすべてひらがなとほぼ同じですが、ほとんど借用された単語を録音するために使用されます(ダウンロード= da-un-lo:-do = download)。
- 漢字-次のようになります:体試版-i.e. 原則として、さまざまなパーツとキャップのヒープからの複雑な正方形の構造。 彼らにとって最も難しいことです、それは彼らの多くです。
さらに、句読点があり、プラスまたはマイナスはヨーロッパ言語と同じです。ドット、コンマ、、省略記号、引用符「」
、感嘆符、疑問符など。 しかし、通常、ギャップはありません。 秘trickは、テキストが絶えず漢字で記録される「重要な」単語とひらがなで記録される粒子と交互になり、その結果、この混合物が少なくとも何らかの方法で分類できることです。 たとえば、ゲーム「恋する姉妹の六重奏」の名前を取ります。
- 恋-漢字
- する-ひらがな
- 姉妹-漢字
- の-ひらがな
- 六重奏-漢字
これにより、最終的に何が得られますか? 非常に簡単:頻度表。 日本語の最初のビジュアルノベルの既製のスクリプトを手に入れ、Unicodeの3つのグループすべての範囲の境界をすばやく調べて、このスクリプトを実行します(しゃれでごめんなさい)。
stats = {} $stdin.each_char { |c| t = case c.ord when 0x3041..0x309F then :hiragana when 0x30A0..0x30FF then :katakana when 0x4E00..0x9FCC then :kanji end stats[t] ||= 0 stats[t] += 1 } p stats
出力のようなものが得られます:
{nil=>72384, :kanji=>5731, :hiragana=>15377, :katakana=>2241}
つまり 通常のテキストは、約25%の漢字、65%のひらがな、10%のカタカナです。
ツールを発見し、仕事に真っ向から飛び込む時が来たようです。 新しいオープンソースツールKaitai Structを使用して、理解できない構造のバイナリファイルを分析することを簡単に思い出させてください。これにより、テンプレートをマークアップ言語で記述し、ファイルに適用して、ツリー内の棚に配置されたコンテンツをすばやく視覚化できますメガボーナスとして、-ほぼすべての一般的なプログラミング言語でテンプレートをソースに直接コンパイルします(前の記事の執筆以来、カイタイストラクツはJava、JavaScript、Python、Rubyだけでなく、C ++、C#、Perl、PHPもサポートし始めました)。 つまり、トップ言語のあらゆる種類のリストを見ると、トップ10が完全にカバーされており、トップ20から、ドメイン固有のものをとらないと、Delphi、Visual Basicは十分ではありません(誰もリバースエンジニアリングを行うとは思いませんが)古代のVisual Basicは.NETではありません)、Swift and Go。
記事の最初の部分でKaitai Structテンプレートの基本的な構文を研究したので、それが何であるかを見逃した/忘れた人は、それをよく理解し、メモリでリフレッシュする時です。
そのため、3〜4個のファイルのダンプをすばやく確認し、そのようなテンプレートが出発点として適していることを理解します。
meta: id: yks application: Yuka Engine endian: le seq: - id: magic contents: ["YKS001", 1, 0] - id: magic2 contents: [0x30, 0, 0, 0, 0, 0, 0, 0, 0x30, 0, 0, 0] - id: unknown1 type: u4 - id: unknown2 type: u4 - id: unknown3 type: u4 - id: unknown4 type: u4 - id: unknown5 type: u4 - id: unknown6 type: u4 - id: unknown7 type: u4
YKC形式ですぐに類推できます。 なぜなら 最初に「ヘッダー」の説明があり、その長さから始まり、高い確率でmagic2のすべての場所にある固定の0x30が元のヘッダーの長さであるため、0x30までのすべてを一度に読むことを提案します。 7つの数字が判明しましたが、今ではそれが何であるかを推測しようとします。
Yoyaku.yksの場合(ファイル自体は27741バイト):
[.] @unknown1 = 1845 [.] @unknown2 = 7428 [.] @unknown3 = 795 [.] @unknown4 = 20148 [.] @unknown5 = 7593 [.] @unknown6 = 25 [.] @unknown7 = 0
trial_00100.yks(ファイル91267バイト)の場合:
[.] @unknown1 = 6433 [.] @unknown2 = 25780 [.] @unknown3 = 2376 [.] @unknown4 = 63796 [.] @unknown5 = 27471 [.] @unknown6 = 5 [.] @unknown7 = 0
また、比較のために、すべてのファイル、たとえばall_00010.yks(12968バイト):
[.] @unknown1 = 933 [.] @unknown2 = 3780 [.] @unknown3 = 353 [.] @unknown4 = 9428 [.] @unknown5 = 3540 [.] @unknown6 = 1 [.] @unknown7 = 0
何が見える? まず、ファイルのオフセットやサイズのような壮大なものです。なぜなら、 ファイルサイズが91 Kの場合、数値は25〜63 Kの範囲で、12 Kのサイズは3〜9 Kの範囲で変動します。 よく見ると、オフセットとサイズは、unknown2、unknown4、unknown5のみである可能性が高く、それらは4つに分割され、非常に大きくなっています。 第二に、unknown7は常に0のようです。第三に、unknown6は非常に区分的に何かを設定しているようです。 これは、たとえば、変数用の仮想マシンの予約メモリのサイズ、変化するシーン/スプライト/背景の数、または他の何かです。
0x30の直後、肉眼でも、人間の16進エディタでは、増加する(またはほとんど常に増加する)テーブルが表示されます。 これはほとんどバイトコードそのものではありません。バイトコードの特徴は、同じシーケンスの一定の繰り返しだけです。 これはおそらくいくつかのオフセットでもあります。たとえば、バイトコードのコマンドの先頭、可変長の行の先頭または末尾などを定義するオフセットです。 不明な値は7つありますが、これはそれほど多くありません-調べて、そのうちの1つが次のようになっているかどうかを確認しましょう。
- このセクションの長さ
- このセクションの終わりの絶対オフセット=新しいセクションの始まり
- プロット内の4バイト整数の数
ほぼ最初の試みは非常にうまく適合します。unknown1はこのセクションの要素の数であり、unknown2は次のセクションの先頭へのポインターであることがわかります。 したがって、実際にはunknown2 = 0x30 + unknown1 * 4のようです。すぐに説明を追加し、同時にヘッダーを明示的に選択されたヘッダータイプに移動し、開いたセクションsect1..sectXの呼び出しを開始します。
seq: - id: header type: header - id: sect1 size: header.sect2_ofs - 0x30 type: sect1 types: header: seq: - id: magic contents: ["YKS001", 1, 0] - id: magic2 contents: [0x30, 0, 0, 0, 0, 0, 0, 0, 0x30, 0, 0, 0] - id: sect1_qty type: u4 - id: sect2_ofs type: u4 - id: unknown3 type: u4 - id: unknown4 type: u4 - id: unknown5 type: u4 - id: unknown6 type: u4 - id: unknown7 type: u4 sect1: seq: - id: entries type: u4 repeat: expr repeat-expr: _root.header.sect1_qty
その結果、trial_00100は次のようになり始めます。
[-] @header [.] @magic = 59 4b 53 30 30 31 01 00 [.] @magic2 = 30 00 00 00 00 00 00 00 30 00 00 00 [.] @sect1_qty = 6433 [.] @sect2_ofs = 25780 [.] @unknown3 = 2376 [.] @unknown4 = 63796 [.] @unknown5 = 27471 [.] @unknown6 = 5 [.] @unknown7 = 0 [-] @sect1 [-] @entries (6433 = 0x1921 entries) [.] 0 = 6 [.] 1 = 7 [.] 2 = 3 [.] 3 = 3 [.] 4 = 4 ... [.] 6425 = 2371 [.] 6426 = 2372 [.] 6427 = 34 [.] 6428 = 1 [.] 6429 = 2373 [.] 6430 = 2374 [.] 6431 = 1 [.] 6432 = 2375
実際、これらは単なる増加する値ではなく、バイトコードである可能性があります。 このファイルでは、顕著な増加数は0または1から2375に増加するように見えます。突然、unknown3 = 2376はこれらの値の数に非常に似ています。 つまり バイトコードは、2376の異なる値(明らかに0から2375まで)がある別のテーブルを参照します。 何だろう?
次のセクションでは、画面3〜4で何が起こるかを見ていきます。

私の意見では、これらが16バイト(1行)の長さのレコードであることは多かれ少なかれ明白であり、再び、それらは明らかに不均一に増加するオフセットまたはインデックスに著しく似たものを持っています。 そのような記録は2376個ありますか? unknown3の名前をsect2_qtyに変更し、簡単なスライスを追加して16バイトのレコードからsect2を収集することで確認します。
- id: sect2 size: 16 repeat: expr repeat-expr: header.sect2_qty
そして、ビンゴ、これはそれであり、非常に正確です:

これらの非常に細い16バイトのレコードは、sect2_qtyピースの直後で実際に終了し、完全に異なるものが始まることが肉眼ではっきりとわかります。 ここで何が見えますか? これらは明らかに4バイトの長い数字ではなく、ほとんどすべてゼロではありません。 少なくとも一見すると、明らかに周期的な構造も追跡されません。 豊富な0xaa。 多くの0x28が時間とともに変化します。 ファイルの最後を見て、他のセクションを見つけようとします-最後の同じテクスチャについてはそうではありません:
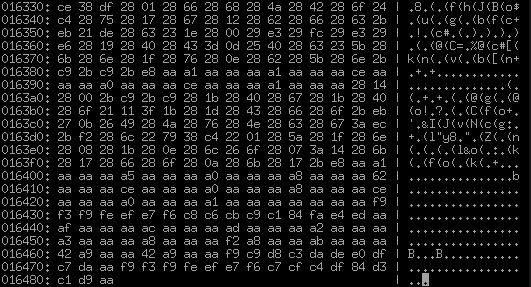
つまり、これはファイルの3番目の最後のセクションであり、それ以上何もありません。 そして、私たちが見たことがないものは何ですか? テキストと行。 どうやら、これは彼らが何であるかですが、明らかに何らかの形でエンコードされています。 絞った? いいえ、そうではありません。 このような0x28と0xaaの繰り返しはありません。 はい、あらゆる種類の28 08 28 1b 28 0e 28 6c 26 6f 28 07 3a 14 28 6b
0x28を繰り返すと、非常に疑わしいように見えます。 比較のために、ShiftJISでの平均的な日本語テキストがどのように見えるか思い出してみましょう: 82 a0 82 e8 82 aa 82 c6 82 a4 82 b2 82 b4 82 a2
。 これは、これが最も単純なワイルドカード暗号であり、各バイトが常に同じ他のバイトに変換されるという仮説がすぐに生じます。 それは何ですか、0x82 => 0x28から取得する方法は? 実際、人類はそれほど多くの選択肢を思いつきませんでした。
- 加算/減算-各バイトに同じ数を加算(または同じものを減算)し、オーバーフローは無視します
- rol / ror-特定のビット数による循環シフト。最も愚かなバージョンでは、正確に4ビットのシフトが右または左に行われ、2桁の16進数が入れ替わります。
- 排他的 "or"(xor)-各バイトで他の固定バイトでxor操作を実行します。 最も愚かな、平凡な、何らかの形で演技し、したがって人気のある方法の一つ
一般に、 XORSearchのようなプログラムの形の「重い」大砲さえあります。これらは総当たりでそのような変換を推測しようとしますが、ここではそれはより一般的であり、私は二度目に推測することができます。 0xaaが豊富にあるということは、0xaaとXORを行うとゼロが多くなり、0xaaが得られることを示しています。 そして、突然0x82 ^ 0xaaは正確に0x28です。 0xaaは一般に、まず最初にチェックする必要がある最も一般的な仮定の1つです。 0xaa = 0b10101010、つまり xorは、2ビットごとにそれをバカにします。
幸いなことに、Kaitai Structには、このような変換のサポートが組み込まれており、 process:
によってアクティブになりprocess:
このように書くだけです:
- id: sect3 size-eos: true process: xor(0xaa)
その後、ようやく信頼スクリプトの文字列定数の豊富な内部世界を観察できるようになります。
000000: 69 66 00 c8 00 00 00 47 6c 6f 62 61 6c 46 6c 61 | if.....GlobalFla 000010: 67 00 3d 00 ff ff 00 00 01 00 00 00 3d 00 7b 00 | g.=.........=.{. 000020: 0d 00 00 00 57 69 6e 64 6f 77 4e 61 6d 65 53 65 | ....WindowNameSe 000030: 74 00 97 f6 82 b7 82 e9 8e 6f 96 85 82 cc 98 5a | t........o.....Z 000040: 8f 64 91 74 28 83 66 83 6f 83 62 83 4f 29 81 7c | .dt(.fobO).| 000050: 46 69 6c 65 20 3a 20 74 72 69 61 6c 68 5f 6d 61 | File : trialh_ma 000060: 79 75 2e 79 6b 73 00 7d 00 09 00 00 00 44 72 61 | yu.yks.}.....Dra 000070: 77 53 74 6f 70 00 47 72 61 70 68 69 63 48 69 64 | wStop.GraphicHid 000080: 65 00 0a 00 00 00 54 72 61 6e 73 69 74 69 6f 6e | e.....Transition 000090: 00 02 00 00 00 64 00 00 00 0a 00 00 00 0b 00 00 | .....d.......... 0000a0: 00 47 72 61 70 68 69 63 4c 6f 61 64 00 00 00 00 | .GraphicLoad....
幸いなことに、特にASCIIラインのクラウドがあり、これにより人生が大幅に簡素化されます。 一見、これらはゼロで終了する単なるCスタイルのラインのように見えますが、詳細に調べると、これは完全に真実ではないことがわかります。 行と、理解できない定数の散在があります。たとえば、 ff ff 00 00 01 00 00 00
または02 00 00 00 64 00 00 00 0a 00 00 00 0b 00 00 00
または02 00 00 00 64 00 00 00 0a 00 00 00 0b 00 00 00
これは、印刷されたASCII文字が1つあるにもかかわらず中央( d
= 0x64)にある可能性が最も高いのは線ではありません。 さらに、最も価値のあるもの-ここにある-は、ShiftJISで82
と同じ行です。
まとめると、成功しました:
- 4バイト整数(おそらくこれはバイトコード)で構成されるsect1、これらの番号を持つsect2の16バイトエントリを部分的に参照
- sect2、内部の数値が増加する16バイトのレコードで構成される(おそらくいくつかのオフセット)
- 主にShiftJISのヌル終了行で構成されているsect3ですが、完全ではありません(おそらく-文字列リソースおよびバイトコードで参照される他のすべての定数)
この小さな勝利で、今日の研究が完了すると思います。記事が再び無数に大きくなったからです。 ある程度、たとえば、タスクがビジュアルノベルの翻訳である場合、今日の成果はすでにテキストを切り取って翻訳者に提供するのに十分です。 sect3を取得し、SJISのように見えるものをすべて見つけ、他のすべてを注意深く破棄します-出来上がり:
恋する姉妹の六重奏(デバッグ)-File : trialh_mayu.yksまゆ「きゃっ……!!」教育的指導を兼ねて、お望み通りメチャクチャにしてやろうじゃないか!! 「あっ……お、おにぃっ……」自分から誘っておきながら、不安そうな表情を浮かべるまゆ。そんなまゆを、ソファーに押しつけて……胸を露出させ、股間が丸見えになる体勢を強いる。 「んぁっ……」
この場所を読んでくれたみんなに感謝します。 次回はバイトコード自体に行き、sect1とsect2がどのように機能するかを理解しようとします。 じゃあね!