Web上には、ハッシュテーブルの構造とその実装について詳しく説明している素晴らしい記事がたくさんあります。 http://preshing.com/から始めることができます。 ただし、無数のハッシュテーブル構造のオプションがあり、それらのいずれも完全ではなく、プロセッササイクル、メモリ使用量、またはスレッド環境の適切なスケーリングの最適化にもかかわらず、それぞれにトレードオフがあります。 データを追加する場合はより良いオプション、検索する場合は他のオプションなどがあります。より重要なものに応じて実装を選択します。
PHP 5のハッシュテーブルについては、PHP 7のハッシュテーブルに関する優れた記事の著者であるNikicと一緒に書いたphpinternalsbookで詳しく説明されています。 おそらくあなたもそれを面白いと思うでしょう。 確かに、それはリリースの前に書かれたので、その中のいくつかのものはわずかに異なります。
ここでは、PHP 7でハッシュテーブルがどのように配置されるか、C言語の観点からハッシュテーブルを操作する方法、およびPHPツールを使用して(配列と呼ばれる構造を使用して)ハッシュテーブルを管理する方法を詳しく見ていきます。 ソースコードのほとんどはzend_hash.cで入手できます。 ハッシュテーブルはどこでも(通常は辞書として)使用することを忘れないでください。したがって、プロセッサですばやく処理され、メモリをほとんど消費しないように設計する必要があります。 ハッシュテーブルが使用される場所はローカル配列だけではないため、これらの構造はPHPの全体的なパフォーマンスに決定的な影響を及ぼします。
ハッシュテーブルの設計
以下で詳細に検討する多くの規定があります。
- キーは文字列または整数です。
zend_string
場合はzend_string
構造がzend_string
、zend_string
場合はzend_string
がzend_string
ます。 - ハッシュテーブルは、要素が追加される順序を常に記憶している必要があります。
- ハッシュテーブルのサイズは自動的に変更されます。 状況に応じて、独立して減少または増加します。
- 内部実装の観点から見ると、テーブルのサイズは常に2度に等しくなります。 これは、パフォーマンスを改善し、メモリ内のデータ配置を調整するために行われます。
- ハッシュテーブル内のすべての値は、他の場所ではなく、
zval
構造に格納されます。Zval
は、任意のタイプのデータを含めることができます。
HashTable
構造について考えてみましょう。
struct _zend_array { zend_refcounted_h gc; union { struct { ZEND_ENDIAN_LOHI_4( zend_uchar flags, zend_uchar nApplyCount, zend_uchar nIteratorsCount, zend_uchar reserve) } v; uint32_t flags; /* 32 */ } u; uint32_t nTableMask; /* — nTableSize */ Bucket *arData; /* */ uint32_t nNumUsed; /* arData */ uint32_t nNumOfElements; /* arData */ uint32_t nTableSize; /* , */ uint32_t nInternalPointer; /* */ zend_long nNextFreeElement; /* */ dtor_func_t pDestructor; /* */ };
一部のフィールドはめったに使用されないため、それらについては説明しません。
この構造のサイズは56バイトです (LP64モデルによる)。
最も興味深いデータフィールドは、
Bucket
チェーンのメモリ領域へのポインタの一種である
arData
です。
Bucket
自体は配列内の単一のセルです。
typedef struct _Bucket { zval val; /* */ zend_ulong h; /* ( ) */ zend_string *key; /* NULL */ } Bucket;
お気づきかもしれませんが、
zval
は
Bucket
構造に保存されます。 これは
zval
へのポインタではなく、構造自体であることに注意してください。 これは、PHP 7では
zval
がヒープに配置されなくなったためです(PHP 5とは異なります)が、PHP 7では、
zval
ポインターとして保存されたターゲット値(PHP文字列など)を配置できます。
メモリ内の配置がどのように発生するかを見てみましょう。

ご覧のとおり、ハッシュテーブルに配置されたデータは、隣接するメモリセクション
arData
保存されます。
順序を維持しながらアイテムを追加する
PHPは、要素が配列に追加されるときに要素の順序を維持する必要があります。
foreach
を配列に適用すると、キーに関係なく、配列に配置された正確な順序でデータを受け取ります。
$a = [9=>"foo", 2 => 42, []]; var_dump($a); array(3) { [9]=> string(3) "foo" [2]=> int(42) [10]=> array(0) { } }
これは、ハッシュテーブルの実装に多くの制限を課した重要なポイントです。 すべてのデータは、互いに隣り合うメモリに配置されます。
zval
では、
arData
C-arrayのフィールドにある
Bucket
パックされて格納されます。 このようなもの:
$a = [3=> 'foo', 8 => 'bar', 'baz' => []];

このアプローチのおかげで、ハッシュテーブルを簡単に反復できます
arData
配列を
arData
だけです。 本質的に、これはメモリの迅速な順次スキャンであり、プロセッサキャッシュリソースをほとんど消費しません。
arData
からのすべてのデータは1行に配置でき、各セルへのアクセスには約1ナノ秒かかります。 注:プロセッサキャッシュの使用効率を高めるために、
arData
64ビットモデルに従ってアライメントされます(64ビットフル命令のアライメントの最適化も使用されます)。 ハッシュテーブルの反復コードは次のようになります。
size_t i; Bucket p; zval val; for (i=0; i < ht->nTableSize; i++) { p = ht->arData[i]; val = p.val; /* - val */ }
データはソートされ、次の
arData
セルに渡されます。 この手順を完了するには、
nNumUsed
フィールドに格納されている、この配列で次に使用可能なセルを覚えておいて
nNumUsed
。 新しい値が追加されるたびに、
ht->nNumUsed++
を追加し
ht->nNumUsed++
。
nNumUsed
の要素数がハッシュテーブルの要素数(
nNumOfElements
)に達すると、コンパクトアルゴリズムまたはサイズ変更アルゴリズムを実行します。これについては以下で説明します。
文字列キーを使用してハッシュテーブルにアイテムを追加する簡略化されたビュー:
idx = ht->nNumUsed++; /* */ ht->nNumOfElements++; /* */ /* ... */ p = ht->arData + idx; /* bucket arData */ p->key = key; /* , */ /* ... */ p->h = h = ZSTR_H(key); /* bucket */ ZVAL_COPY_VALUE(&p->val, pData); /* bucket': */
値を消去
値を削除しても、
arData
配列
arData
減少したり再配列
arData
たり
arData
ん。 そうしないと、メモリ内のデータを移動する必要があるため、パフォーマンスが劇的に低下します。 そのため、ハッシュテーブルからデータを削除する場合、
arData
の対応するセルは、
zval
UNDEFという特別な方法で単純にマークされます。

したがって、このような「空の」セルを処理できるように、反復コードを少し再構築する必要があります。
size_t i; Bucket p; zval val; for (i=0; i < ht->nTableSize; i++) { p = ht->arData[i]; val = p.val; if (Z_TYPE(val) == IS_UNDEF) { continue; } /* - val */ }
以下では、ハッシュテーブルのサイズが変更されたときに何が起こるか、および「空の」セルが消えるように
arData
配列を再編成する必要があります(圧縮)。
キーハッシュ
キーはハッシュおよび圧縮され、圧縮されたハッシュ値から変換されて
arData
インデックス付けされる
arData
ます。 キーは整数であっても圧縮されます。 これは、配列の境界に収まるようにするために必要です。
arData
直接あるように、圧縮された値にインデックスを
arData
ことはできないことに
arData
して
arData
。 結局、これは配列のインデックスに使用されるキーがハッシュから取得したキーに直接対応することを意味します。これは、PHPのハッシュテーブルのプロパティの1つ、要素の順序の保持に違反します。
たとえば、最初にfooキーを追加し、次にbarキーを追加すると、最初のキーはハッシュされてキー5に圧縮され、2番目のキーはキー3に圧縮されます
arData[5]
データが
arData[5]
arData[3]
、データバーがデータfooに移動することがわかります。 また、
arData
反復処理する場合
arData
要素は追加された順序ではなく転送されます。

したがって、割り当てられた
arData
境界に収まるように、キーをハッシュしてから圧縮します。 ただし、PHP 5とは異なり、そのまま使用しません。最初に変換テーブルを使用してキーを変換する必要があります。 ハッシュ/圧縮によって取得された1つの整数値と、
arData
配列内のアドレス指定に使用される別の整数値を単純に比較します。
注意点が1つあります。変換テーブルのメモリは、
arData
ベクトルの背後に慎重に配置されます。 これ
arData
テーブルはすでに
arData
隣に
arData
れており、同じアドレス空間に残っているため、テーブルが別のメモリ領域を使用する
arData
ます。 これにより、データの局所性が向上します。 これは、8要素のハッシュテーブル(可能な最小サイズ)の場合に説明されたスキームがどのように見えるかです:

これで、fooキーはDJB33Xでハッシュされ、必要なサイズ(
nTableMask
)にモジュロ圧縮されます。 結果の値は、(直接セルではなく)
arData
変換
arData
にアクセスするために使用できるインデックスです。
これらのセルは、
arData
開始位置からの負のシフトによってアクセスされます。 2つのメモリ領域が結合されたため、メモリにデータを順番に保存できます。
nTableMask
はテーブルのサイズの負の値に対応するため、モジュールとして取得すると0〜–7の値を取得します。 これでメモリにアクセスできます。
arData
バッファー全体を配置する場合、次の式を使用してサイズを計算します。
* bucket' + * (uint32) .
以下に、バッファが2つの部分にどのように分割されているかを明確に示します。
#define HT_HASH_SIZE(nTableMask) (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t)) #define HT_DATA_SIZE(nTableSize) ((size_t)(nTableSize) * sizeof(Bucket)) #define HT_SIZE_EX(nTableSize, nTableMask) (HT_DATA_SIZE((nTableSize)) + HT_HASH_SIZE((nTableMask))) #define HT_SIZE(ht) HT_SIZE_EX((ht)->nTableSize, (ht)->nTableMask) Bucket *arData; arData = emalloc(HT_SIZE(ht)); /* */
マクロが実行されると、次の結果が得られます。
(((size_t)(((ht)->nTableSize)) * sizeof(Bucket)) + (((size_t)(uint32_t)-(int32_t)(((ht)->nTableMask))) * sizeof(uint32_t)))
いいね
衝突解決
それでは、衝突がどのように解決されるかを見てみましょう。 覚えているように、ハッシュテーブルでは、ハッシュおよび圧縮されたときのいくつかのキーが同じ変換インデックスに対応することがあります。 そのため、変換インデックスを受け取ったら、それを使用して
arData
からデータを抽出し、ハッシュとキーを比較して、これが必要かどうかを確認します。 データが正しくない場合、
zval.u2.next
フィールドを使用してリンクリストを
zval.u2.next
ます。このフィールドには、データを入力するための次のセルが反映されます。
リンクリストは、従来のリンクリストのようにメモリスキャッタリングされないことに注意してください。 ヒープから受け取ったいくつかのメモリに配置されたポインタを
arData
では
arData
おそらくアドレス空間に散らばっている)、メモリから完全なベクトル
arData
を読み取ります。 そして、これは、PHP 7および言語全体のハッシュテーブルのパフォーマンスを向上させる主な理由の1つです。
PHP 7では、ハッシュテーブルのデータの局所性は非常に高くなっています。 データは通常、第1レベルのプロセッサキャッシュにあるため、ほとんどの場合、アクセスは1ナノ秒で行われます。
ハッシュに要素を追加し、衝突を解決する方法を見てみましょう。
idx = ht->nNumUsed++; /* */ ht->nNumOfElements++; /* */ /* ... */ p = ht->arData + idx; /* arData bucket */ p->key = key; /* */ /* ... */ p->h = h = ZSTR_H(key); /* bucket */ ZVAL_COPY_VALUE(&p->val, pData); /* bucket': */ nIndex = h | ht->nTableMask; /* */ Z_NEXT(p->val) = HT_HASH(ht, nIndex); /* */ HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx); /* */
削除と同じこと:
h = zend_string_hash_val(key); /* */ nIndex = h | ht->nTableMask; /* */ idx = HT_HASH(ht, nIndex); /* , */ while (idx != HT_INVALID_IDX) { /* */ p = HT_HASH_TO_BUCKET(ht, idx); /* bucket */ if ((p->key == key) || /* ? ? */ (p->h == h && /* ... */ p->key && /* ( ) */ ZSTR_LEN(p->key) == ZSTR_LEN(key) && /* */ memcmp(ZSTR_VAL(p->key), ZSTR_VAL(key), ZSTR_LEN(key)) == 0)) { /* ? */ _zend_hash_del_el_ex(ht, idx, p, prev); /* ! */ return SUCCESS; } prev = p; idx = Z_NEXT(p->val); /* */ } return FAILURE;
変換セルとハッシュの初期化
HT_INVALID_IDX
は、変換テーブルに入れる特別なフラグです。 これは、「この変換はどこにも通じないため、続行する必要がない」ことを意味します。
2段階の初期化には特定の利点があり、作成されたばかりの空のハッシュテーブル(PHPの一般的なケース)の影響を最小限に抑えることができます。 テーブルを作成するときに、
arData
バケットセルと、
HT_INVALID_IDX
フラグを配置する2つの変換セルを同時に作成します。 次に、最初の変換セル(
HT_INVALID_IDX
、ここにはデータはありません)を指すマスクを適用します。
#define HT_MIN_MASK ((uint32_t) -2) #define HT_HASH_SIZE(nTableMask) (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t)) #define HT_SET_DATA_ADDR(ht, ptr) do { (ht)->arData = (Bucket*)(((char*)(ptr)) + HT_HASH_SIZE((ht)->nTableMask)); } while (0) static const uint32_t uninitialized_bucket[-HT_MIN_MASK] = {HT_INVALID_IDX, HT_INVALID_IDX}; /* hash lazy init */ ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC) { /* ... */ ht->nTableSize = zend_hash_check_size(nSize); ht->nTableMask = HT_MIN_MASK; HT_SET_DATA_ADDR(ht, &uninitialized_bucket); ht->nNumUsed = 0; ht->nNumOfElements = 0; }
ここでは、束を使用できないことに注意してください。 静的constメモリゾーンで十分であり、はるかに簡単です(
uninitialized_bucket
)。
最初の要素を追加した後、ハッシュテーブルを完全に初期化します。 つまり、要求されたサイズに応じて、最後に必要な変換セルを作成します(デフォルトでは8セルから始まります)。 メモリ内の配置はヒープから来ます。
(ht)->nTableMask = -(ht)->nTableSize; HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_PERSISTENT)); memset(&HT_HASH(ht, (ht)->nTableMask), HT_INVALID_IDX, HT_HASH_SIZE((ht)->nTableMask))
HT_HASH
マクロを使用
HT_HASH
と、負のオフセットが使用されるメモリ内にあるバッファーのその部分の変換セルにアクセスでき
HT_HASH
。 変換テーブルのセルには
arData
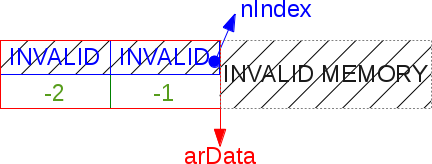
バッファーの先頭からマイナスのインデックスが付けられるため、テーブルマスクは常に負になります。 ここでは、Cでのプログラミングがすべての栄光で明らかになりました。数十億個のセルが利用可能で、無限に泳ぎ、justれないでください。
レイジー初期化(レイジー初期化)ハッシュテーブルの例:作成されましたが、これまでハッシュは配置されていません。
ハッシュの断片化、拡大、および圧縮
ハッシュテーブルがいっぱいで、新しい要素を追加する必要がある場合は、サイズを大きくする必要があります。 これは、Cの従来のハード制限配列と比較したハッシュテーブルの大きな利点です。増加するたびに、ハッシュテーブルのサイズは2倍になります。 テーブルのサイズが大きくなると、メモリにC配列
arBucket
を事前に割り当て、空のセルに特別なUNDEF値を配置することを思い出してください。 その結果、私たちは激しく記憶を失います。 損失は次の式で計算されます。
( – ) * Bucket
このメモリはすべてUNDEFセルで構成され、そこにデータが配置されるのを待ちます。
たとえば、ハッシュテーブルに1024個のセルがあり、新しい要素を追加します。 テーブルは2048個のセルに拡大し、そのうちの1023個は空です。 1023 * 32バイト=約32 Kb。 これは、PHPでハッシュテーブルを実装することの欠点の1つです。
ハッシュテーブルが完全に1つのUNDEFセルで構成されている可能性があることを覚えておく必要があります。 多くの要素を追加および削除すると、テーブルが断片化されます。 ただし、要素の順序を保持するために、
arData
の最後にのみ新しいものをすべて追加し、結果のスペースには挿入しません。 そのため、
arData
の最後に
arData
すると状況が発生する可能性があり
arData
、UNDEFセルはまだ存在しています。
非常に断片化された8セルハッシュテーブルの例:
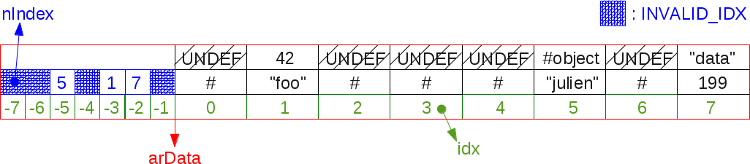
覚えているように、新しい値はUNDEFセルに保存できません。 上記のスキームでは、ハッシュテーブルを反復するときに、
arData[0]
から
arData[7]
ます。
サイズを大きくすると、
arData
ベクトルを減らし、データを再配布するだけで最終的に空のセルを埋めることができます。 テーブルにサイズ変更のコマンドが与えられると、最初にテーブル自体を圧縮しようとします。 次に、圧縮後に再度増加する必要があるかどうかを計算します。 そして、イエスと判明した場合、テーブルは2倍になります。 その後、
arData
ベクトルは2倍のメモリ
(realloc())
arData
始めます。 増やす必要がない場合、データは既にメモリにあるセルに再配布されます。 ここでは、要素を削除するたびに使用できないアルゴリズムを使用します。これは、あまりにも頻繁にプロセッサリソースを消費し、排気量がそれほど大きくないためです。 有名なプログラマーがプロセッサーとメモリーの間で妥協したことを覚えていますか?
この図は、圧縮後の以前の断片化されたハッシュテーブルを示しています。
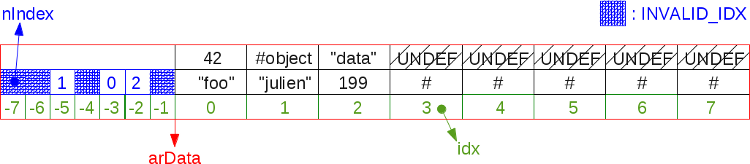
アルゴリズムは
arData
を
arData
、各UNDEFセルに次の非UNDEFセルからのデータを取り込みます。 簡略化すると、次のようになります。
Bucket *p; uint32_t nIndex, i; HT_HASH_RESET(ht); i = 0; p = ht->arData; do { if (UNEXPECTED(Z_TYPE(p->val) == IS_UNDEF)) { uint32_t j = i; Bucket *q = p; while (++i < ht->nNumUsed) { p++; if (EXPECTED(Z_TYPE_INFO(p->val) != IS_UNDEF)) { ZVAL_COPY_VALUE(&q->val, &p->val); q->h = p->h; nIndex = q->h | ht->nTableMask; q->key = p->key; Z_NEXT(q->val) = HT_HASH(ht, nIndex); HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(j); if (UNEXPECTED(ht->nInternalPointer == i)) { ht->nInternalPointer = j; } q++; j++; } } ht->nNumUsed = j; break; } nIndex = p->h | ht->nTableMask; Z_NEXT(p->val) = HT_HASH(ht, nIndex); HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(i); p++; } while (++i < ht->nNumUsed);
ハッシュテーブルAPI
さて、これでPHP 7でハッシュテーブルを実装する主なポイントがわかりました。次に、パブリックAPIを見てみましょう。
特別なことは何もありません(PHP 5では、APIの方がはるかに優れています)。 API関数を使用するときは、次の3つのことを忘れないでください。
- 操作について(追加、削除、クリーニング、破棄など)。
- キーのタイプについて(整数または小文字)。
- 保存するデータの種類について。
キー、小文字、整数にかかわらず、主なこと:小文字のキーには
zend_string
からのハッシュが
zend_string
、整数はすぐにハッシュとして使用されることをAPIが認識する必要があります。 したがって、
zend_hash_add(ht, zend_string, data)
または
zend_hash_index_add(ht, long, data)
を満たすことができます。
キーは単純なペア(char * / int)になる場合があります。 この場合、
zend_hash_str_add(ht, char *, int, data)
などの別のAPIを使用する必要があります。 ハッシュテーブルは
zend_string
にアクセスし、文字列キーに変換してハッシュを計算し、ある程度のプロセッサリソースを消費することに
zend_string
してください。
zend_string
を使用できる場合は、使用します。 ハッシュはすでに計算されているので、APIはそれらを取得します。 たとえば、PHPコンパイラは、
zend_string
ように、使用される文字列の各部分のハッシュを計算します。 OPCacheは同様のハッシュを共有メモリに保存します。 拡張機能の作成者として、すべての
zend_string
リテラルを
zend_string
初期化することをお勧めします。
次に、ハッシュテーブルに保存するデータについて説明します。 繰り返しになりますが、ハッシュテーブルは各
Bucket
zval
にデータを配置します。 PHP 7では、zvalはあらゆる種類のデータを保存できます。 一般に、ハッシュテーブルAPIは、データを
zval
にパックすることを期待しています
zval
は、APIが値として認識します。
ストレージまたはメモリ領域へのポインター(ポインターによって参照されるデータ)がある場合、状況は多少単純化できます。 次に、APIはこのポインターまたはメモリ領域をzvalに配置し、zval自体がポインターをデータとして使用します。
例は、アイデアを理解するのに役立ちます。
zend_hash_str_add_mem(hashtable *, char *, size_t, void *) zend_hash_index_del(hashtable *, zend_ulong) zend_hash_update_ptr(hashtable *, zend_string *, void *) zend_hash_index_add_empty_element(hashtable *, zend_ulong)
データを取得すると、zval *またはNULLが取得されます。 ポインターが値として使用される場合、APIはそのまま返されます。
zend_hash_index_find(hashtable *, zend_string *) : zval * zend_hash_find_ptr(hashtable *, zend_string *) : void * zend_hash_index_find(hashtable *, zend_ulong) : zval *
zend_hash_add_new()
ような_new APIについては、使用しない方が良いでしょう。 内部のニーズにエンジンを使用します。 このAPIは、ハッシュ(同じキー)で既に使用可能な場合でも、ハッシュテーブルにデータを保存させます。 その結果、重複が生じ、作業に最適な効果が得られない場合があります。 したがって、追加しようとしているハッシュにデータがないことを完全に確信している場合にのみ、このAPIを使用できます。 したがって、それらを探す必要はありません。
: 5, API
zend_symtable_api()
:
static zend_always_inline zval *zend_symtable_update(HashTable *ht, zend_string *key, zval *pData) { zend_ulong idx; if (ZEND_HANDLE_NUMERIC(key, idx)) { /* handle numeric key */ return zend_hash_index_update(ht, idx, pData); } else { return zend_hash_update(ht, key, pData); } }
, : , zval…
ZEND_HASH_FOREACH
:
#define ZEND_HASH_FOREACH(_ht, indirect) do { \ Bucket *_p = (_ht)->arData; \ Bucket *_end = _p + (_ht)->nNumUsed; \ for (; _p != _end; _p++) { \ zval *_z = &_p->val; \ if (indirect && Z_TYPE_P(_z) == IS_INDIRECT) { \ _z = Z_INDIRECT_P(_z); \ } \ if (UNEXPECTED(Z_TYPE_P(_z) == IS_UNDEF)) continue; #define ZEND_HASH_FOREACH_END() \ } \ } while (0)
« -»
, :
arData
, ,
arData
. -: -
arData
. - , .
: .
arData
, . , .
« -» (packed hashtable):

, .
arData[0]
. , 2 * uint32 = 8 . . , , .
: , , ( /), - . bucket'.
ZEND_API void ZEND_FASTCALL zend_hash_packed_to_hash(HashTable *ht) { void *new_data, *old_data = HT_GET_DATA_ADDR(ht); Bucket *old_buckets = ht->arData; ht->u.flags &= ~HASH_FLAG_PACKED; new_data = pemalloc(HT_SIZE_EX(ht->nTableSize, -ht->nTableSize), (ht)->u.flags & HASH_FLAG_PERSISTENT); ht->nTableMask = -ht->nTableSize; HT_SET_DATA_ADDR(ht, new_data); memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed); pefree(old_data, (ht)->u.flags & HASH_FLAG_PERSISTENT); zend_hash_rehash(ht); }
-
u.flags
, , -. , -, . , . 例:
static zend_always_inline zval *_zend_hash_index_add_or_update_i(HashTable *ht, zend_ulong h, zval *pData, uint32_t flag ZEND_FILE_LINE_DC) { uint32_t nIndex; uint32_t idx; Bucket *p; /* ... */ if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { CHECK_INIT(ht, h < ht->nTableSize); if (h < ht->nTableSize) { p = ht->arData + h; goto add_to_packed; } goto add_to_hash; } else if (ht->u.flags & HASH_FLAG_PACKED) { /* ... */ } else if (EXPECTED(h < ht->nTableSize)) { p = ht->arData + h; } else if ((h >> 1) < ht->nTableSize && (ht->nTableSize >> 1) < ht->nNumOfElements) { zend_hash_packed_grow(ht); p = ht->arData + h; } else { goto convert_to_hash; } /* ... */
: - , .
- : :
(_ - 2) * (uint32)
. , . - : . , .
(, 42 60), - «». ( — ) . - API:
void ZEND_FASTCALL zend_hash_real_init(HashTable *ht, zend_bool packed)
,
zend_hash_real_init()
— , «» (
zend_hash_init()
). , «», - . , .
, - .
-
(packed array):
function m() { printf("%d\n", memory_get_usage()); } $a = range(1,20000); /* range() */ m(); for($i=0; $i<5000; $i++) { /* , * : * «» */ $a[] = $i; } m(); /* * - «», * */ $a['foo'] = 'bar'; m();
, :
1406744 1406776 1533752
130 ( 25 000 ).
:
function m() { printf("%d\n", memory_get_usage()); } /* - . * 32 768 (2^15). */ for ($i=0; $i<32768; $i++) { $a[$i] = $i; } m(); /* */ for ($i=0; $i<32768; $i++) { unset($a[$i]); } m(); /* . - , * */ $a[] = 42; m();
結果:
1406864 1406896 1533872
, ( , modulo noise).
unset()
arData
32 768 , UNDEF-zval'.
- .
nNumUsed
,
arData
? , , .
?
— , UNDEF-. : , , , . , , , .
/* , , : */ /* (idx). * , */ $a[3] = 42; m();
:
1406864 1406896 1406896
? 32 768 65 538 , . 32 767 .
Bucket
,
zval
,
long
( 42), . zval long. :) , 32 768 , , , . , , . ., , UNDEF-zval' «» .
-, . , , , . «» , (
idx 0
), — UNDEF-zval.
function m() { printf("%d\n", memory_get_usage()); } /* - . * 32 768 (2^15). */ for ($i=0; $i<32768; $i++) { /* , */ $a[' ' . $i] = $i; } m(); /* */ for ($i=0; $i<32768; $i++) { unset($a[' ' . $i]); } m(); /* . * , */ $a[] = 42; m();
:
2582480 1533936 1533936
. 2,5 .
unset()
, . 32 768
zend_string
, 1,5 .
, , . , , . 42 idx 0, . 物語の終わり。
, - , . ? , (, ?) / , . . , . «» 20 32 , .
(Immutable arrays)
— OPCache. OPCache, , . . . OPCache , . , AST-. , — AST-. 例:
$a = ['foo', 1, 'bar'];
$a
— AST-. , , . OPCache AST-, ( ) , . OPCache .
, OPCache , IS_ARRAY_IMMUTABLE IS_TYPE_IMMUTABLE . IS_IMMUTABLE , . , . .
:
$ar = []; for ($i = 0; $i < 1000000; ++$i) { $ar[] = [1, 2, 3, 4, 5, 6, 7, 8]; }
400 OPCache, — 35 . OPCache , 8-
$ar
. 8- . OPCache, 8- IS_IMMUTABLE
$ar
, .
, , ,
$ar[42][3] = 'foo';
, 8-
$ar[42]
.
- , . , PHP- — - Zend. PHP, . - . , / . -. OPArray ( ) ( ). PHP , OPArray: . OPCache IMMUTABLE , . , .
OPCache , . , ( , ). , - OPCache , PHP- . PHP.
. , :
$a = [1]; $b = [1];
. , ( interned strings ), , . — , ( , , ), runtime' PHP. ( ). , OPCache.