 出版物へのコメントで、 なぜ行くのが平凡よりも優れている 、habrayuzersの1人は無効なパスポートのリストのための検索アルゴリズムを書くための例として提案しました。
出版物へのコメントで、 なぜ行くのが平凡よりも優れている 、habrayuzersの1人は無効なパスポートのリストのための検索アルゴリズムを書くための例として提案しました。
タスクの条件の1つは、この目的でDBMSを使用しないことでした。 また、このソリューションでは、メモリ、ディスク領域、およびCPUの使用を最小限に抑える必要があります。
驚いたことに、標準データベースを使用するソリューションは非常に面倒であるという事実にもかかわらず、ほとんどのコメンテーターが依然としてDBMSの使用を提案していることに気付きました(データ自体にレコードごとに少なくとも5バイト、ほぼ同じ量を使用することに加えてインデックスに配置)。
Sypex Geoのバイナリデータベースでの作業経験があるため、バイナリファイル形式とその検索アルゴリズムの概要を説明することにしました。
データ分析
まず、特別なファイル形式を作成するには、データ自体を分析する必要があります。
ソースデータは、無効なパスポートのリスト(コンマで区切られたシリーズと番号)を含むCSVファイルです。割り当て時には、ロシアのパスポート(4桁のシリーズと6桁の番号)のみが必要です。
bz2アーカイブでは、このリストは359 MBをアンパック形式の1.13 GBで占めています。 約1億2000万件のレコード。 データをMySQLにアップロードし(LOAD DATAを使用してロードする便利なCSVファイルがあります)、すでにそのデータを分析しました。 インデックスがない場合、次の構造を持つテーブルは680 MBでハングしました。
CREATE TABLE `pass` ( `seria` SMALLINT(5) UNSIGNED NOT NULL, `num` MEDIUMINT(8) UNSIGNED NOT NULL ) ENGINE=MyISAM ROW_FORMAT=FIXED
num列にインデックスを追加すると、1.5 GBかかります。2つの列にインデックスを作成すると、すでに1.7 GBになります。
それは判明した:
- 1つのシリーズには、最大600,000個の数字を含めることができます。
- 一方、1つの問題では最大200エピソード。
このことから、すぐに番号で検索すると、さらに検索が大幅に減少するため、より収益性が高いと結論付けます。 そのため、パスポート番号でインデックスを作成します。
独自の形式を作成する
バイナリファイルは2つの部分で構成されます。最初の部分は、一定数の要素、つまり000 000〜999 999の100万の値があるインデックスです。各インデックス要素は4バイトを占有し、ファイルの2番目の部分にオフセットが含まれます対応する番号のシリーズリスト。 シリーズ自体は、ファイルの2番目の部分に2バイト値として保存されます。 特定の番号の系列リスト内の要素の数は、オフセット(検索された番号)と(検索された番号+ 1)の差です。
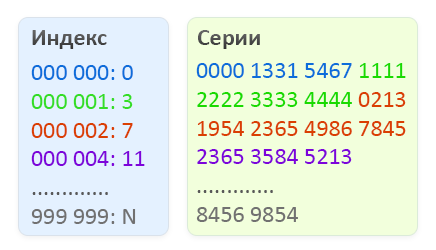
無効なパスポートを検索するためのバイナリファイルの構造の概略図。
パスポートが無効なリストにあるかどうかを確認するには、次の簡単な手順を実行する必要があります。
たとえば、数字2365 000002を使用します。
- パスポートの番号によって、インデックスのオフセットを決定します。これには、番号に4(インデックス要素のサイズ)を掛けます。 4 * 000002 = 8バイト (図の赤いブロック)
- オフセットを実行し、2つのインデックス要素(2 * 4バイト)を読み取って、シリーズリストの始まりと終わりを確認します。 それらを2つの10進32ビット数に変換します。 この場合、 7と11になります (わかりやすくするために、バイト単位のオフセットは表示されませんが、1単位のオフセット= 1シリーズ)
- シリーズリストの先頭から目的の番号のシリーズリストの末尾へのシフトに関するデータを読み取ります。シリーズは2バイトで書き込まれることに注意してください。
- 現在、2バイトシーケンスの中で必要なシリーズを探しています。
- 見つかった場合-パスポートは無効です。それ以外の場合-データベースに無効として表示されません。
各号には200を超えるエピソードがないので、簡単な網羅的検索でシリーズを検索できます。 プロセスを高速化するために、以前にシリーズをソートしたバイナリ検索を使用できます。 しかし、興味深い場合は、別の出版物で追加の最適化について書きます。
テスト中
たとえば、PHPでいくつかのテストスクリプトをスケッチしました。 CSVファイルをバイナリ形式に変換するもの。 2つ目は、正しいパスポートを見つけることです。 スクリプト付きアーカイブはここからダウンロードできます 。
また、結果のソリューションを、データがMySQLにあるオプションと比較します。 データはSSDに保存され(HDDに保存する場合、パフォーマンスが低下します)、さらに、サーバーにはすべてのテーブルをメモリにキャッシュするのに十分なメモリがあります。 MySQLに最適なオプション。
テストはお気に入りのテストサイト-Vultrで実施されました。 お気に入りは、強力なVPS-kuを1時間ごとにすばやく上げることができ、ストレージスナップショットは無料です(つまり、削除してから、テスト環境をすばやく復元する必要がある場合)。
ボーナス
Vultrサービスの料金を支払うためにアカウントに20ドルを受け取りたい場合は、 refリンクを使用できます(新しいユーザーにのみ適用されます)。
VPSの場合、選択されたプランは6 CPU、8 GB、150 GB SSD、MariaDB 10.1.16、PHP 7.0.9です。
数字に
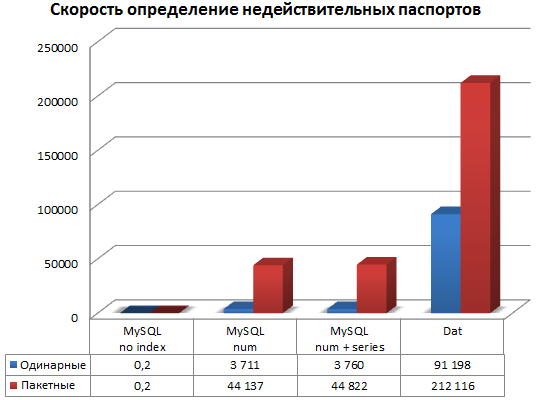
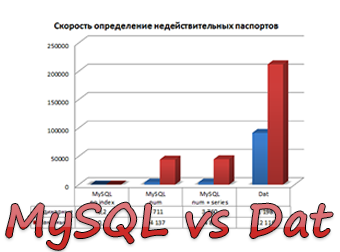
各タイプのデータストレージについて、2つのモードがチェックされました:シングルモード(ファイルを開いてデータベースへの接続が各番号に対して行われる場合)およびバッチモード(ファイルを開いてデータベースへの接続が1回のみ)。
| データファイル | MySQL
インデックスなし | MySQL
数字による索引 | MySQL
番号とシリーズによるインデックス | |
| DBサイズ(インデックスを含む) | 198 MB | 680 MB | 1.5 GB | 1.7 GB |
| インデックスサイズ | 4 MB | 0 MB | 893 MB | 1.07 GB |
| CSVをデータベースにダウンロード(mm:ss) | 3:54 * | 0:31 | 3:38 | 3:42 |
| 単一の検索速度(p /秒) | 91 198 | 0.2 ** | 3,711 | 3,760 |
| バッチ検索速度(p /秒) | 212 116 | 0.2 | 44 137 | 44,822 |
**すべてのメソッドで、インデックスなしのMySQLを除き、1つのパスポートを検索するのに最大10秒かかるため、30万のパスポートが実行されました。
結論
テスト結果からわかるように、目的のタスクに合わせたカスタムソリューションは、汎用DBMSよりもはるかに高速に機能します。さらに、形式はMySQLのテーブルよりも7〜8倍小さくなります。
また、ファイルを検索するスクリプト自体は10行未満(コメントなし)です。
$pass = '0307,000000'; // $fn = fopen('passports.dat', 'rb'); // // 2- , , $seria = pack('n', substr($pass, 0, 4)); $num = substr($pass, 5); // fseek($fn, $num * 4); // 2 4 $seek = unpack('Nbegin/Nend', fread($fn, 8)); // fseek($fn, $seek['begin']); $series = fread($fn, $seek['end'] - $seek['begin']); // echo ($pos = strpos($series, $seria)) !== false && $pos % 2 == 0 ? 'INVALID' : 'VALID';
PSスクリプトは当然最大限に単純化されており、トレーニング目的であり、本番用ではありません(ただし、これはアルゴリズムではなくエラー処理に関係します)。
他のプログラミング言語への翻訳を歓迎します。測定することが可能です:)