市場には膨大な数の企業知識ベースWikiエンジンがあります。 Atlassian Confluenceを使用している場合、システムの標準wiki機能を拡張する方法を学ぶことに興味があるでしょう。 Confluenceを使用します。たとえば、次のような有用な情報を動的に表示するためのショーケースとして使用できます。
- 製品のメトリックス、
- アジャイルチームの指標
- チームの成長チャート、
- 今後の誕生日のリスト、
- など
解決すべき問題
明確にするために、過去の有名な科学者の例を使用して、会社の従業員の会計処理のタスクを検討します。 つまり、DBMSには、各レコードが個別の従業員であるテーブルがあり、このレコードの各フィールドは従業員の特性(氏名、生年月日、電話番号など)です。 簡単にするために、 Atlassian JIRA DBMSをDBMSとして使用し、プロジェクト、タスクなどに関する情報を保存します。
結果を表示する方法
そして今、最も興味深いのは、Confluenceのページで動的な情報がどのように見えるかです。 以下では、従業員に関する情報を表示するいくつかの方法を比較できます。
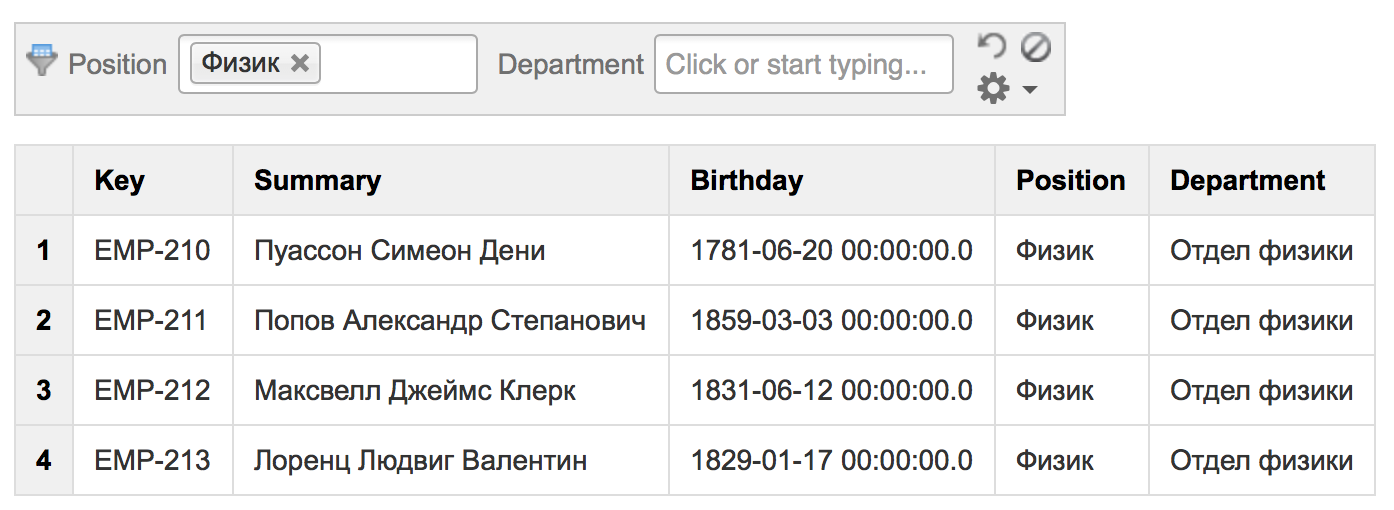
0. JIRAフィルター
Confluenceのページに情報を表示する前に、JIRAでどのように表示されるかを見てみましょう。
これを行うには、簡単なクエリを作成し、表示する目的の列を選択する必要があります。
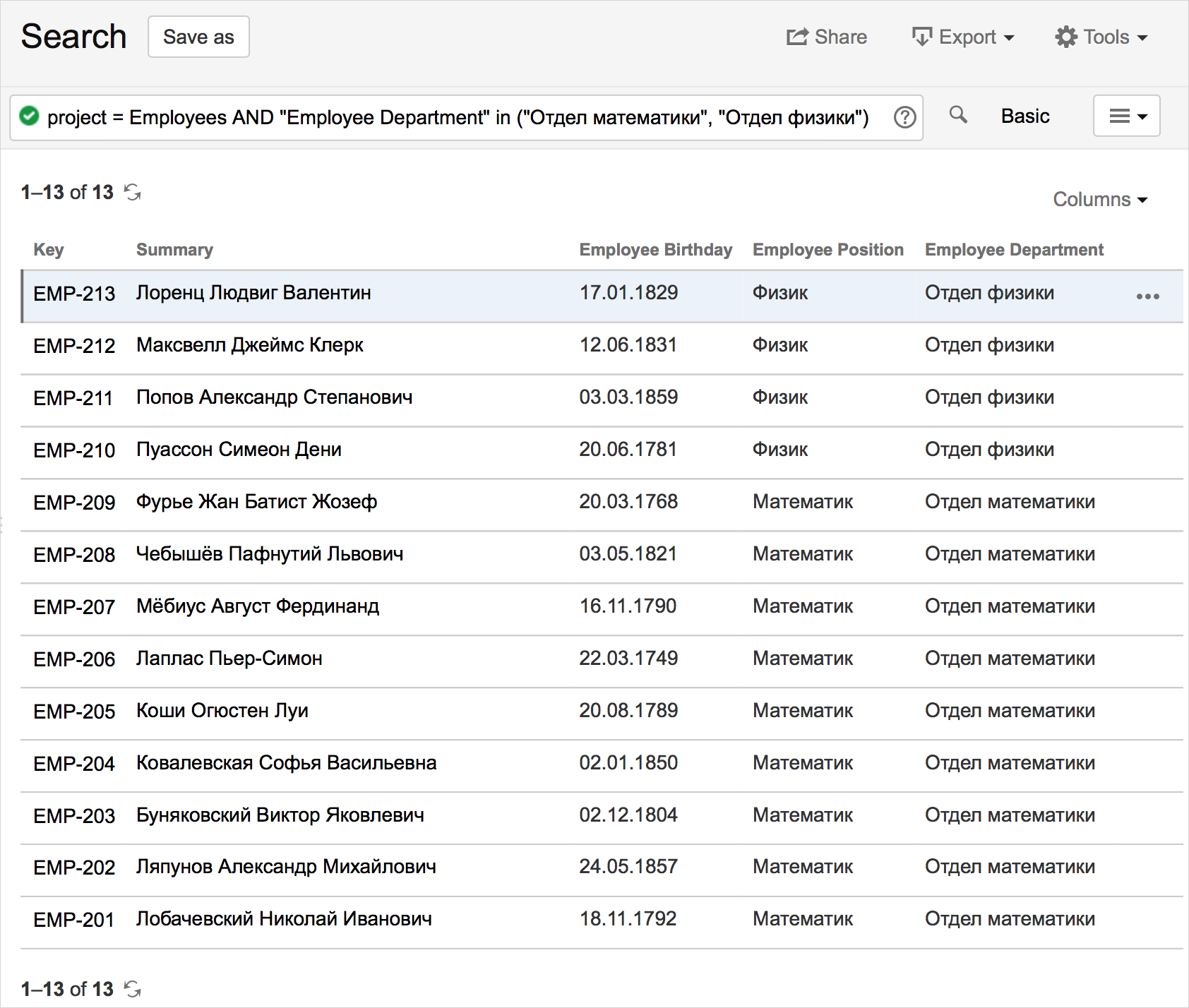
そして、将来のために、リクエストをフィルターとして保存します:

1. JIRAマクロ
アトラシアン製品同士が密接に統合されていることは周知の事実です。 たとえば、Confluenceページでは、数回クリックするだけで、特定のプロジェクト内のタスクのリストを表示したり、指定したフィルターで表示したりできます。
まず、マクロを追加する必要があります。
次に、JIRAプロジェクトと従業員部門でリクエストを作成します。
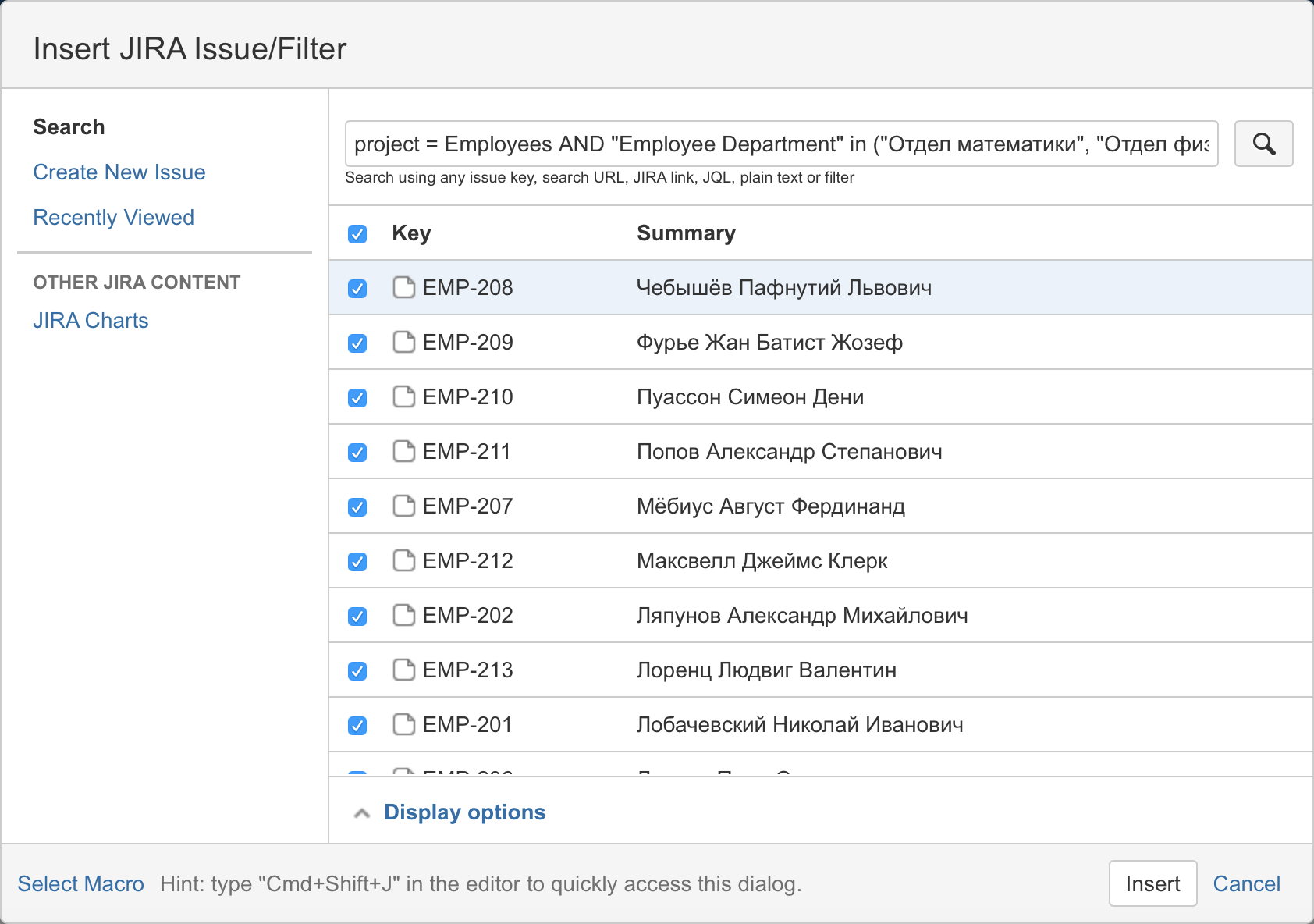
次に、サマリーテーブルに表示する列を選択します。

結果は次のとおりです。

結果のテーブルは、Confluenceページをリロードするか、「更新」をクリックすると動的に更新されます。
さらに、列名をクリックしてテーブルをソートできます。 列の名前はフィールドの名前と一致するため、名前を変更することはできません。 エントリが多すぎる場合のページングも使用できます(この例では、ページサイズは20エントリです)。
2. JIRAガジェット
多くのJIRAユーザーは、 ポートレット/ガジェットを使用して、ダッシュボードに重要なプロジェクト情報を表示します。

JIRAガジェットの従業員のリストは次のとおりです。

おそらく、 JIRAガジェットをConfluenceページに表示できることを誰もが知っているわけではありません。 前のケースとの違いは、HTMLコードがJIRA側で生成され、Confluenceにそのまま表示されることです。
3.直接SQLクエリ
JIRAマッピングメカニズムの特殊なケースを試した後、任意のDBMSのより一般的なケースとそのクエリに移りましょう。
比較を明確にするために、同じJIRA DBMSに対してSQLクエリを作成しました。

前の3つのケースとは異なり、ConfluenceとJIRA間の統合メカニズムなしで、通常のJDBCを介して起動されます。
開発環境でリクエストを実行した結果は次のとおりです。

このクエリを実行し、Confluenceページで結果を表示するには、Bob SwiftのSQL for Confluenceマクロがあります 。
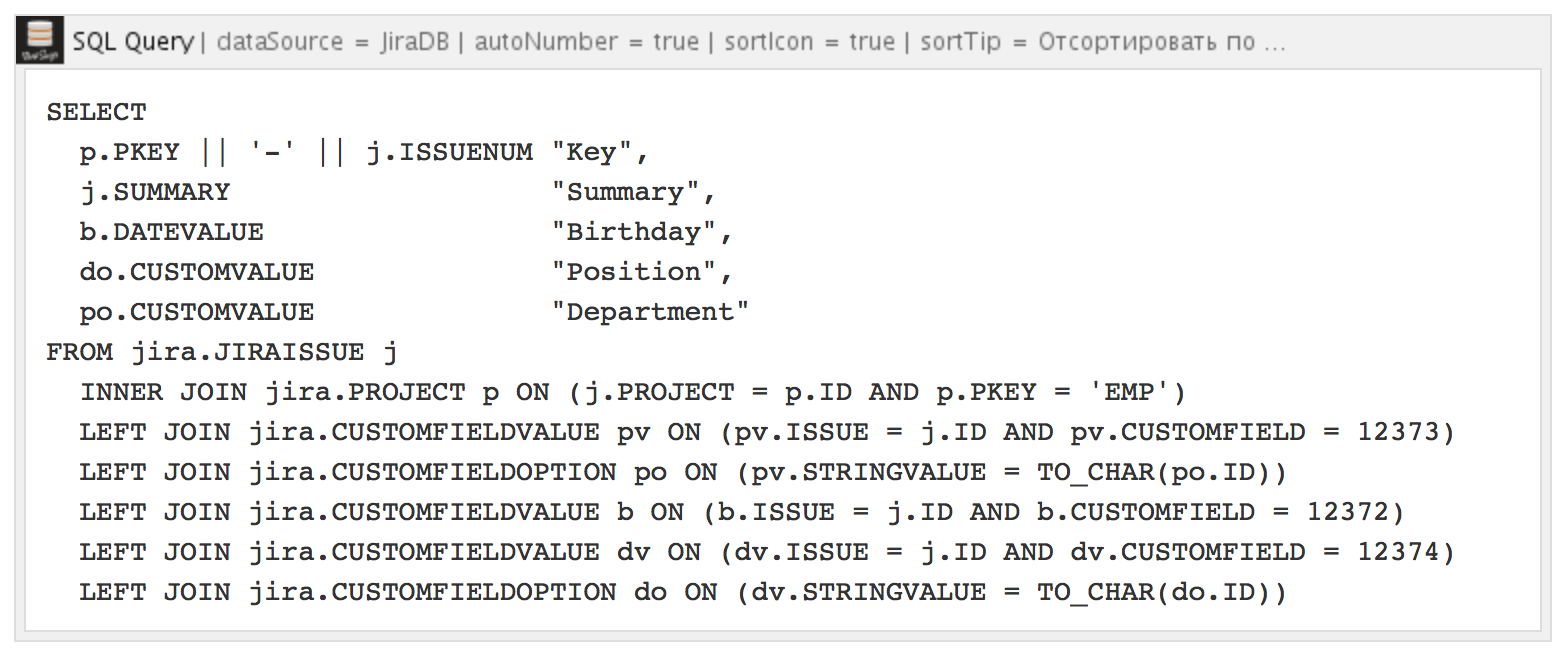
クエリの結果は次のとおりです。
以前のメカニズムとは異なり、SQL for Confluenceには結果をページ分割する機能がありません。 ただし、マクロ設定では、実行されたクエリの行の自動番号付けモードをオフにすることができます。 さらに、列の合計値、平均値、最大値を計算することもできます(この例では、無関係です)。
セキュリティの観点から、マクロを使用すると、DBMSで任意のSQLクエリを実行できます。 データの漏えいや破損を防ぐには、最初にSQLクエリが起動されるテクニカルユーザーの権限を設定する必要があります。 少なくとも、記録を禁止します。 第二に、Confluenceの権限を制限して、リクエストでページを編集します。
クエリ結果をフィルターする機能を追加するために、SQL for Confluenceマクロは別のマクロ(StiltSoftのConfluence用テーブルフィルター)と連携して動作します。
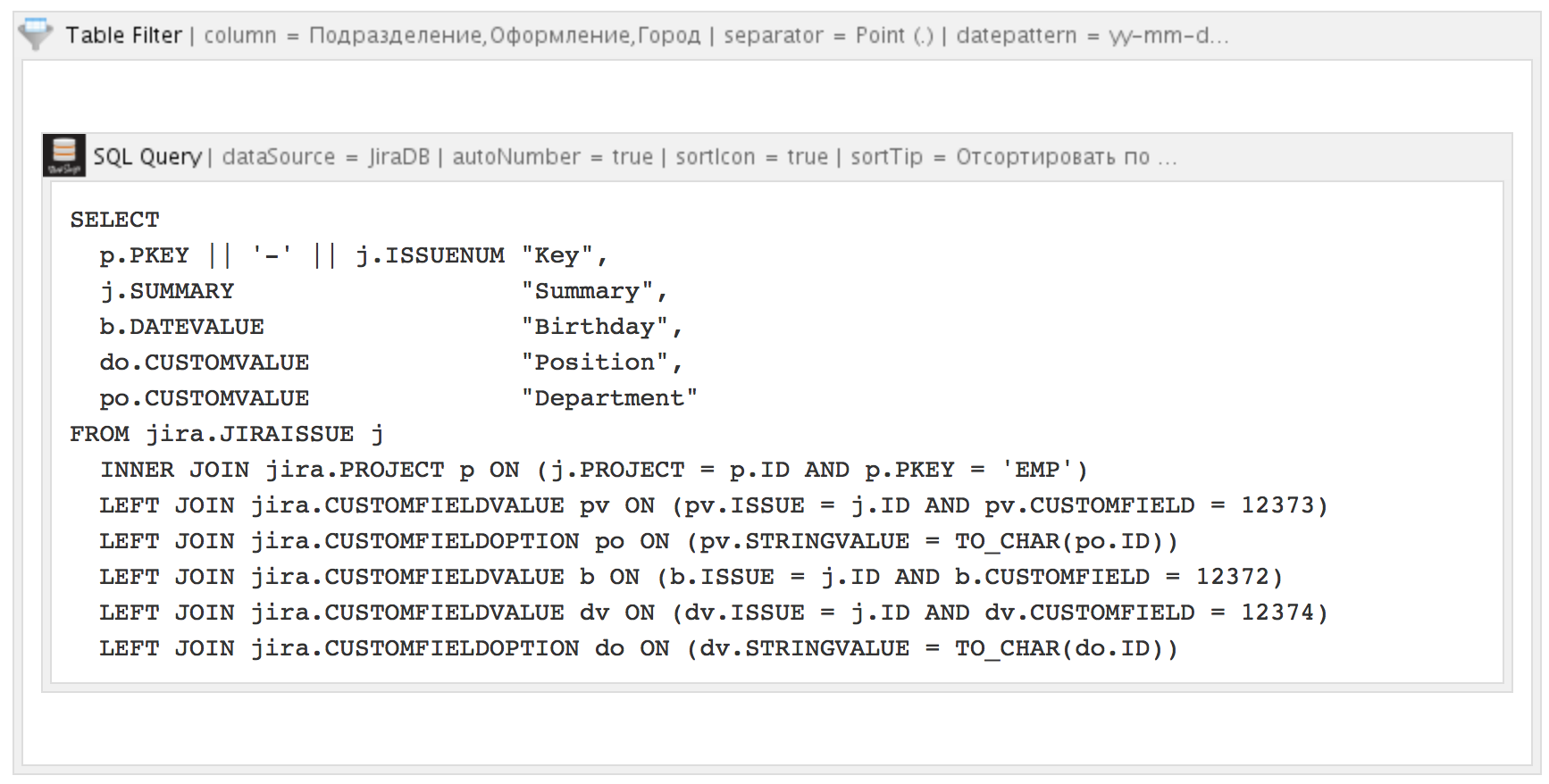
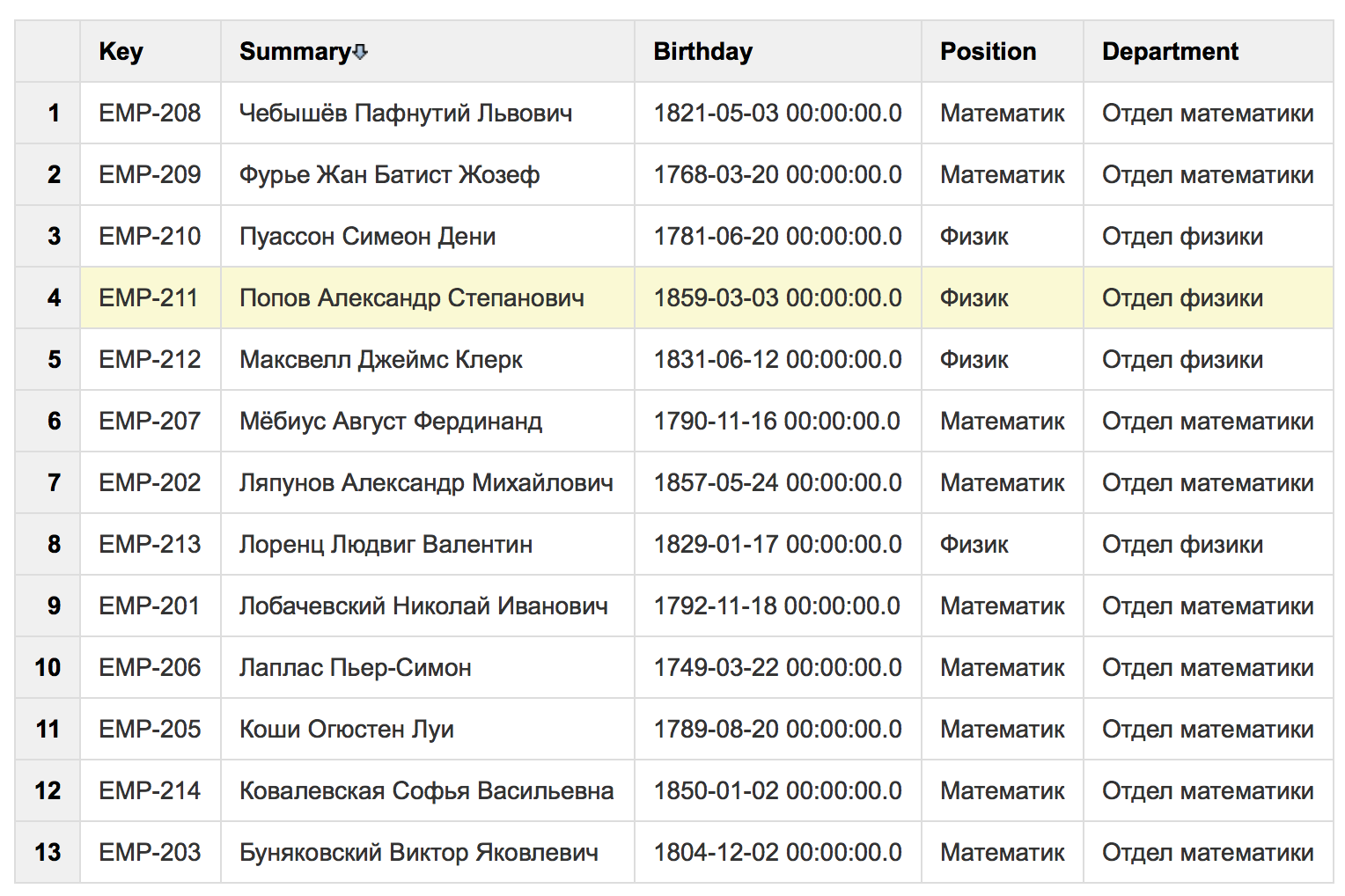
その結果、上記のテーブルに一連のフィールドが添付され、その値が変更され、フィルタリングできます:
4. eazyBI
そして、 eazyBIと呼ばれる最後の、最もリッチで最も複雑なマクロは 、同名の会社によって提供されています。 この製品は、BIの方向でより複雑なタスクを解決するために強化されており、別の記事に値します。 しかし、eazyBIは私たちのタスクに非常に適しています。
まず、データソースを構成し、データを選択するSQLクエリを指定する必要があります。
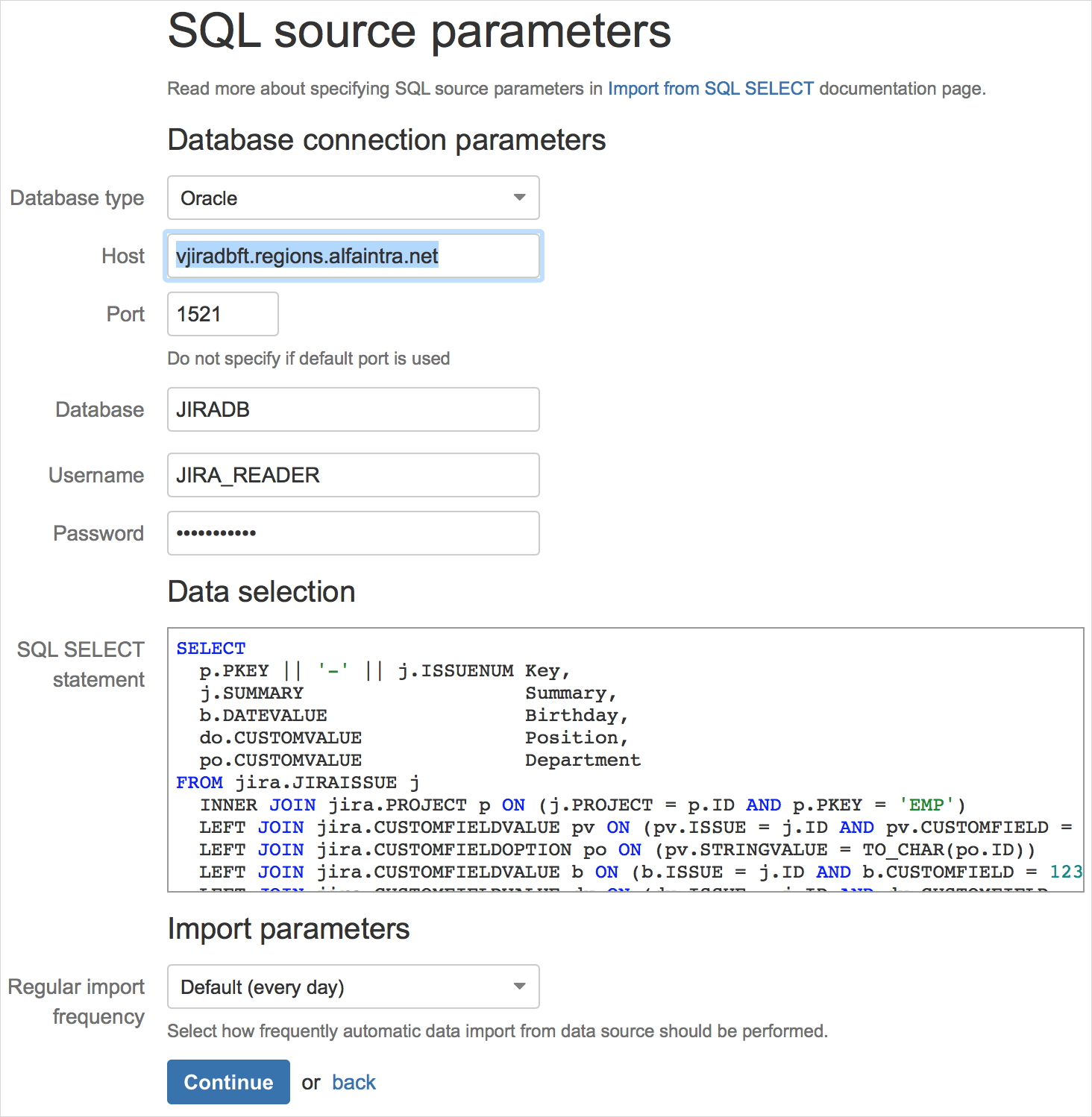
eazyBIエンジンはリクエストを実行し、列名と結果の最初の行をアップロードします。
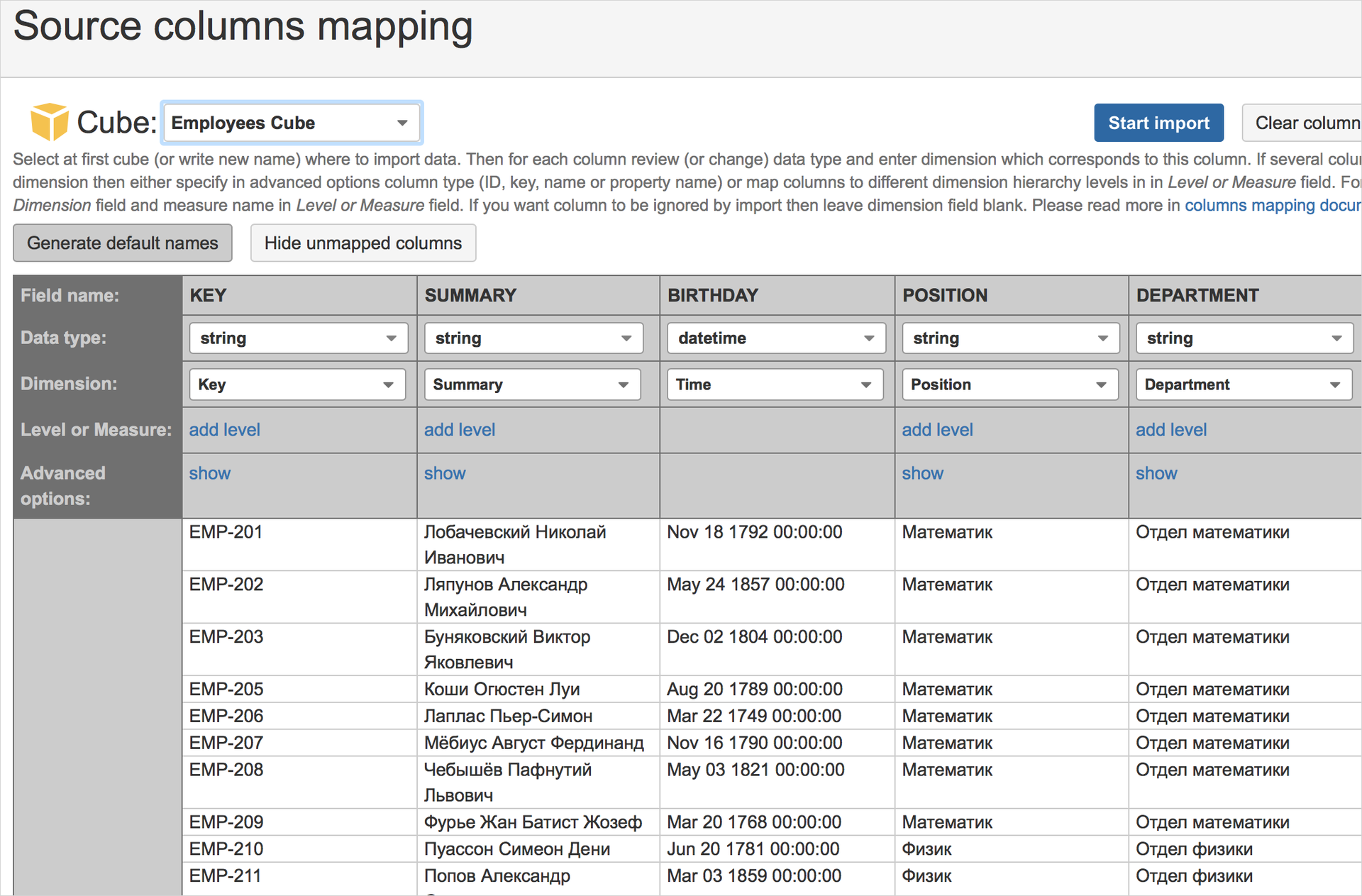
次に、データのインポートを開始し、それらからキューブを作成します。 キューブのディメンションを目的の順序で組み合わせると、次のアンロードが行われます。
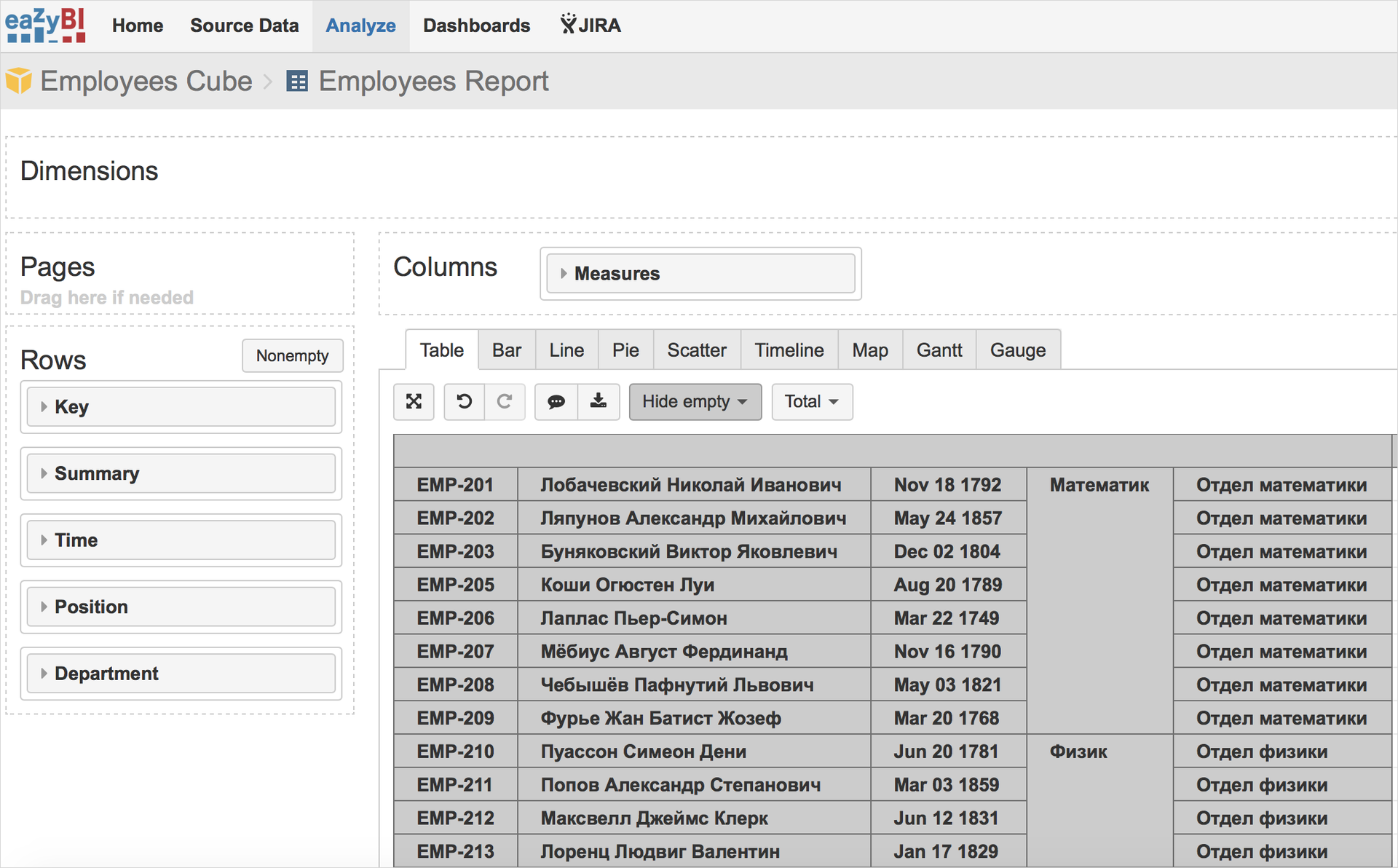
対応するマクロを介してConfluenceページに追加されます。
EazyBIには、上記のメカニズムのように、すべての機能があります。 さらに、自動更新、Excelへのエクスポート、便利な日付のグループ化などがあります。
欠点の中で、BIエンジンの作業の特性を強調したいと思います。表示する前に、クエリ結果は別のDBMSにアップロードされ、Confluenceへのマッピングは既に進行中です。 このような要求はリアルタイムではなく、頻度(5分から1日)で起動されます。 したがって、クエリの実行速度が重要で(結果としてDBMSの負荷)、データの鮮度はそれほど重要ではない大規模データ配列でeazyBIを使用することをお勧めします。
まとめ
一番下の行です:
| 見る | 仕分け | ページング | 列名の変更 | フィルタリング | ナンバリング | リアルタイム実行 | |
| 0. JIRAフィルター | いや | はい | はい | いや | いや | いや | はい |
| 1. JIRAマクロ | はい | はい | はい | いや | いや | いや | はい |
| 2. JIRAガジェット | はい | はい | はい | いや | いや | いや | はい |
| 3. SQLクエリ | はい | はい | いや | はい | はい | はい | はい |
| 4. eazyBI | はい | はい | はい | はい | はい | はい | いや |
したがって、データをJIRAに保存する場合は、ニーズを満たすまで標準のメカニズムを使用してください。 満足できない場合、またはデータがJIRA DBMSに保存されていない場合は、SQL +テーブルフィルターを試してください。 大量のデータがある場合、リソースを集中的に使用して関連性を取得することはそれほど重要ではありません。eazyBIを使用してください。
PS Confluenceのデータ視覚化エンジンの詳細については、昨年のサンドボックス記事をご覧ください。 含む、テーブルフィルターが記載されています。