
確かに、メモリの問題に苦しんだことのない幸運なRuby開発者がいます。 しかし、他のすべての人は、メモリ使用量が制御不能である理由を解明し、原因を排除するために信じられないほどのエネルギーを費やさなければなりません。 幸い、Rubyの最新バージョン(2.1以降)を使用している場合は、一般的な問題を解決するための優れたツールとテクニックを使用できます。 メモリの最適化は喜びと満足感をもたらすことができるように思えますが、私は一人でいることができます。
あらゆる形態の最適化で起こるように、おそらくこれはより複雑なコードにつながるでしょう。 したがって、測定可能な大きなメリットが得られない場合は、これを行うべきではありません。
以下で説明するすべての手順は、標準のMRI Ruby 2.2.4を使用して実行されますが、他のバージョン2.1+も同様に動作するはずです。
これはメモリリークではありません!
メモリーの問題が発生すると、最初に思い浮かぶのはリークだけです。 たとえば、サーバーを起動した後、毎回同じ関数を繰り返し呼び出すと、より多くのメモリが消費されることがWebアプリケーションで確認できます。 もちろん、リークは発生しますが、リークのように見えるより一般的な問題があると主張したいと思いますが、そうではありません。
架空の例を考えてみましょう。何度もハッシュを作成してダンプします。 この記事のさまざまな例で使用されるコードは次のとおりです。
# common.rb require "active_record" require "active_support/all" require "get_process_mem" require "sqlite3" ActiveRecord::Base.establish_connection( adapter: "sqlite3", database: "people.sqlite3" ) class Person < ActiveRecord::Base; end def print_usage(description) mb = GetProcessMem.new.mb puts "#{ description } - MEMORY USAGE(MB): #{ mb.round }" end def print_usage_before_and_after print_usage("Before") yield print_usage("After") end def random_name (0...20).map { (97 + rand(26)).chr }.join end
配列を作成します。
# build_arrays.rb require_relative "./common" ARRAY_SIZE = 1_000_000 times = ARGV.first.to_i print_usage(0) (1..times).each do |n| foo = [] ARRAY_SIZE.times { foo << {some: "stuff"} } print_usage(n) end
get_process_memは、現在のRubyプロセスが使用しているメモリに関する情報を取得する便利な方法です。 上記の動作、つまりメモリ消費が徐々に増加することがわかります。
$ ruby build_arrays.rb 10 0 - MEMORY USAGE(MB): 17 1 - MEMORY USAGE(MB): 330 2 - MEMORY USAGE(MB): 481 3 - MEMORY USAGE(MB): 492 4 - MEMORY USAGE(MB): 559 5 - MEMORY USAGE(MB): 584 6 - MEMORY USAGE(MB): 588 7 - MEMORY USAGE(MB): 591 8 - MEMORY USAGE(MB): 603 9 - MEMORY USAGE(MB): 613 10 - MEMORY USAGE(MB): 621
しかし、さらに繰り返しを実行すると、消費の増加は止まります。
$ ruby build_arrays.rb 40 0 - MEMORY USAGE(MB): 9 1 - MEMORY USAGE(MB): 323 ... 32 - MEMORY USAGE(MB): 700 33 - MEMORY USAGE(MB): 699 34 - MEMORY USAGE(MB): 698 35 - MEMORY USAGE(MB): 698 36 - MEMORY USAGE(MB): 696 37 - MEMORY USAGE(MB): 696 38 - MEMORY USAGE(MB): 696 39 - MEMORY USAGE(MB): 701 40 - MEMORY USAGE(MB): 697
これは、リークに対処していないことを示しています。 または、リークが非常に小さいため、使用されている他のメモリと比較して気付かない。 しかし、最初の反復後にメモリ消費が増加する理由は明らかではありません。 はい、大きな配列を作成しますが、それを正しくゼロにし、同じサイズの新しい配列を作成し始めます。 前のアレイと同じメモリを使用することはできませんか?
いや
ガベージコレクタを設定することに加えて、開始時間を制御することはできません。
build_arrays.rb
例
build_arrays.rb
は、ガベージコレクターが古い破棄されたオブジェクトを削除する前に、新しいメモリ割り当てが行われることがわかります。
アプリケーションによるメモリ消費の予期しない増加を発見しても心配する必要はありません。 リークだけでなく、これには多くの理由があります。
Rubyに特有の悪夢のようなメモリ管理については話していないと言わざるを得ません。 しかし、質問全体は、ガベージコレクターを使用するすべての言語に関連しています。 これを確認するために、Goで上記の例を再現し、同様の結果を得ました。 確かに、Rubyライブラリが使用されているため、このメモリの問題が発生する可能性があります。
分割して征服する
したがって、大量のデータを処理する必要がある場合、大量のRAMを失う運命にありますか? 幸いなことに、そうではありません。 前の例を使用して配列のサイズを小さくすると、メモリ消費が早く均等化されることがわかります。
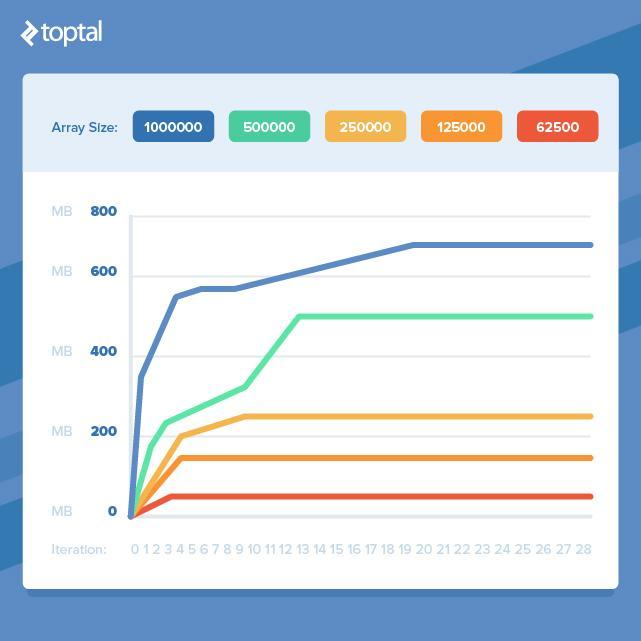
これは、作業を小さなフラグメントに分割し、それを処理して多数のオブジェクトの同時使用を除外できる場合、メモリ消費の大幅な増加を回避できることを意味します。 残念ながら、このためには、きれいで美しいコードを取得し、よりかさばるコードに変換する必要があります。これは同じことを行いますが、メモリの点では効率的です。
メモリ消費ホットスポットの分離
多くの場合、コード内のメモリ問題の原因は
build_arrays.rb
例ほど明白ではありません。 問題の原因について誤った結論を出すのは簡単なので、最初に原因を特定し、それから調査を開始する必要があります。
通常、私は2つのアプローチを使用して、メモリの問題を特定します。
- コードは変更せずにプロファイラーでラップします。
- プロセスによるメモリ使用量を監視し、問題の原因となっている可能性のあるコードのさまざまな部分を削除/追加します。
ここでは 、プロファイラーとしてmemory_profiler ( ruby-profも人気です)を使用し 、モニタリングには、Railsに典型的ないくつかの素晴らしい機能を備えたderailed_benchmarksを使用します。
大量のメモリを使用するコードの例を次に示します。 どの段階で最も消費されているかはすぐにはわかりません。
# people.rb require_relative "./common" def run(number) Person.delete_all names = number.times.map { random_name } names.each do |name| Person.create(name: name) end records = Person.all.to_a File.open("people.txt", "w") { |out| out << records.to_json } end
get_process_memを使用すると、
Person
レコードの作成に最も多くのメモリが使用されているものをすばやく見つけることができます。
# before_and_after.rb require_relative "./people" print_usage_before_and_after do run(ARGV.shift.to_i) end
結果:
$ ruby before_and_after.rb 10000 Before - MEMORY USAGE(MB): 37 After - MEMORY USAGE(MB): 96
このコードには、大量のメモリを消費する可能性のある場所がいくつかあります:文字列の大きな配列を作成し、
#to_a
を呼び出してActive Recordオブジェクトの大きな配列を作成し(良いアイデアではありませんが、デモのため)、Active Recordオブジェクトから配列をシリアル化します。
コードをプロファイルして、メモリの割り当てが行われる場所を理解しましょう。
# profile.rb require "memory_profiler" require_relative "./people" report = MemoryProfiler.report do run(1000) end report.pretty_print(to_file: "profile.txt")
ここでの
run
は、前の例の10分の1になります。 プロファイラー自体は大量のメモリを消費するため、すでに大量に使用されているコードのプロファイリング中に使い果たされる可能性があります。
ファイルは非常に長く、gem内のメモリとオブジェクト、ファイル、および配置レベルの分散と保持が含まれます。 いくつかの興味深い部分がある情報の本当の富:
allocated memory by gem ----------------------------------- 17520444 activerecord-4.2.6 7305511 activesupport-4.2.6 2551797 activemodel-4.2.6 2171660 arel-6.0.3 2002249 sqlite3-1.3.11 ... allocated memory by file ----------------------------------- 2840000 /Users/bruz/.rvm/gems/ruby-2.2.4/gems/activesupport-4.2.6/lib/activ e_support/hash_with_indifferent_access.rb 2006169 /Users/bruz/.rvm/gems/ruby-2.2.4/gems/activerecord-4.2.6/lib/active _record/type/time_value.rb 2001914 /Users/bruz/code/mem_test/people.rb 1655493 /Users/bruz/.rvm/gems/ruby-2.2.4/gems/activerecord-4.2.6/lib/active _record/connection_adapters/sqlite3_adapter.rb 1628392 /Users/bruz/.rvm/gems/ruby-2.2.4/gems/activesupport-4.2.6/lib/activ e_support/json/encoding.rb
ほとんどの配布はアクティブレコード内で発生します。 これは、
records
配列内のすべてのオブジェクトのインスタンスの作成、または
#to_json
を使用した
#to_json
いずれかを示しているよう
#to_json
。 次に、プロファイラーなしでメモリの使用をテストし、疑わしい場所を削除します。
records
の抽出をオフにすることはできませんので、シリアル化から始めましょう。
# File.open("people.txt", "w") { |out| out << records.to_json }
結果:
$ ruby before_and_after.rb 10000 Before: 36 MB After: 47 MB
これは、ほとんどのメモリが消費される場所のようです。前と後の比率は81%です。 大量のレコードのアーカイブを強制的に作成するのをやめると、何が起こるかわかります。
# records = Person.all.to_a records = Person.all # File.open("people.txt", "w") { |out| out << records.to_json }
結果:
$ ruby before_and_after.rb 10000 Before: 36 MB After: 40 MB
メモリ消費も削減されますが、シリアル化を無効にする場合よりも1桁少なくなります。 これで主犯がわかったので、最適化を決定できます。
これは架空の例ですが、ここで説明するアプローチは実際のタスクに適用できます。 結果のプロファイリングでは、明確な結果と問題の特定の原因が得られない可能性があり、さらに、それらは誤って解釈される可能性があります。 そのため、コードの一部を含めたり無効にしたりして、実際のメモリ使用量をさらに確認することをお勧めします。
次に、メモリ使用量が問題になるいくつかの一般的な状況を見て、どのような最適化ができるかを調べます。
逆シリアル化
XML、JSON、またはその他のデータシリアル化形式から大量のデータを逆シリアル化すると、メモリの問題がしばしば発生します。 Active Supportの
JSON.parse
や
Hash.from_xml
などのメソッドは非常に便利ですが、大量のデータがある場合、巨大な構造をメモリにロードできます。
データソースを制御できる場合は、フィルタリングサポートを追加するか、パーツにサポートをロードすることにより、受信する情報の量を制限できます。 ただし、ソースが外部にある場合、またはソースを制御できない場合は、ストリーミングデシリアライザーを使用できます。 XMLの場合、 Oxを使用できます。JSONの場合、 yajl-rubyが適しています。 どうやら、彼らはほぼ同じように動作します。
メモリが限られているからといって、大きなXMLまたはJSONドキュメントを安全に解析できないわけではありません。 ストリームデシリアライザを使用すると、メモリ消費を抑えながら、必要なものを徐々に抽出できます。
Hash#from_xml
を使用して1.7 MBのXMLファイルを解析する例を次に示します。
# parse_with_from_xml.rb require_relative "./common" print_usage_before_and_after do # From http://www.cs.washington.edu/research/xmldatasets/data/mondial/mondial-3.0.xml file = File.open(File.expand_path("../mondial-3.0.xml", __FILE__)) hash = Hash.from_xml(file)["mondial"]["continent"] puts hash.map { |c| c["name"] }.join(", ") end $ ruby parse_with_from_xml.rb Before - MEMORY USAGE(MB): 37 Europe, Asia, America, Australia/Oceania, Africa After - MEMORY USAGE(MB): 164
ファイルあたり111 MB 1.7 MB! 絶対に不適切な比率。 そして、これがストリーミングパーサーのバージョンです。
# parse_with_ox.rb require_relative "./common" require "ox" class Handler < ::Ox::Sax def initialize(&block) @yield_to = block end def start_element(name) case name when :continent @in_continent = true end end def end_element(name) case name when :continent @yield_to.call(@name) if @name @in_continent = false @name = nil end end def attr(name, value) case name when :name @name = value if @in_continent end end end print_usage_before_and_after do # From http://www.cs.washington.edu/research/xmldatasets/data/mondial/mondial-3.0.xml file = File.open(File.expand_path("../mondial-3.0.xml", __FILE__)) continents = [] handler = Handler.new do |continent| continents << continent end Ox.sax_parse(handler, file) puts continents.join(", ") end $ ruby parse_with_ox.rb Before - MEMORY USAGE(MB): 37 Europe, Asia, America, Australia/Oceania, Africa After - MEMORY USAGE(MB): 37
メモリ消費量がわずかに増加し、今でははるかに大きなファイルを処理できます。 しかし、妥協は避けられませんでした。今では、以前は必要なかった28行の処理コードがあります。 これによりエラーが発生する可能性が高くなるため、実稼働環境ではこの部分を追加でテストする必要があります。
連載
メモリホットスポットの分離に関する章で見たように、シリアル化は大きな損失につながる可能性があります。
people.rb
の
people.rb
例の重要な部分を
people.rb
示し
people.rb
。
# to_json.rb require_relative "./common" print_usage_before_and_after do File.open("people.txt", "w") { |out| out << Person.all.to_json } end
100,000レコードのデータベースで実行すると、次の結果が得られます。
$ ruby to_json.rb Before: 36 MB After: 505 MB
ここで
#to_json
の問題は、各エントリのオブジェクトのインスタンスを作成し、JSONでエンコードすることです。 一度に記録オブジェクトが1つだけになるように、レコードごとにJSONレコードを生成することにより、メモリ消費を大幅に削減できます。 人気のあるRuby JSONライブラリはどれもこれを行うことができないようです。通常、JSON文字列を手動で作成することをお勧めします。 これに適したAPIはgem json-write-streamによって提供されており、この例は変換できます。
# json_stream.rb require_relative "./common" require "json-write-stream" print_usage_before_and_after do file = File.open("people.txt", "w") JsonWriteStream.from_stream(file) do |writer| writer.write_object do |obj_writer| obj_writer.write_array("people") do |arr_writer| Person.find_each do |people| arr_writer.write_element people.as_json end end end end end
再度、最適化にはより多くのコードを記述する必要がありましたが、結果には価値があります。
$ ruby json_stream.rb Before: 36 MB After: 56 MB
怠け者になる
Ruby 2.0から、遅延列挙子を作成する絶好の機会がありました。 これにより、列挙子メソッドチェーンを呼び出すときのメモリ消費を大幅に削減できます。 遅延コードから始めましょう:
# not_lazy.rb require_relative "./common" number = ARGV.shift.to_i print_usage_before_and_after do names = number.times .map { random_name } .map { |name| name.capitalize } .map { |name| "#{ name } Jr." } .select { |name| name[0] == "X" } .to_a end
結果:
$ ruby not_lazy.rb 1_000_000 Before: 36 MB After: 546 MB

チェーンの各段階で、すべての要素を反復処理し、チェーンで呼び出される次のメソッドなどを含む新しい配列を作成します。これを怠doな方法で実行するとどうなるかを見てみましょう。列挙子:
# lazy.rb require_relative "./common" number = ARGV.shift.to_i print_usage_before_and_after do names = number.times.lazy .map { random_name } .map { |name| name.capitalize } .map { |name| "#{ name } Jr." } .select { |name| name[0] == "X" } .to_a end
結果:
$ ruby lazy.rb 1_000_000 Before: 36 MB After: 52 MB
最後に、多くのコードを追加せずにメモリ消費を大幅に増加させる例を示します! 最後に結果を蓄積する必要がない場合、たとえば、各要素がデータベースに保存されていて忘れられる可能性がある場合、メモリの消費はさらに少なくなることに注意してください。 チェーンの最後に列挙子の結果を取得するには、最後の呼び出しを
force
追加するだけです。
また、最初にtimeが呼び出され、次に
lazy
が呼び出されることに注意する必要があります。これは、最初の呼び出しがメモリをほとんど消費せず、各呼び出しで整数を生成する列挙子を返すだけだからです。 そのため、チェーンの先頭で配列の代わりに列挙子を使用できる場合、これもプラスになり、メモリ消費が削減されます。
すべてを巨大な配列とコレクション(マップ)に保持すると便利ですが、実際の状況ではこれはまれな場合にのみ許可されます。
ページ分割されたデータを操作する場合など、遅延データ処理用の列挙型を作成できます。 すべてのページを照会して1つの大きな配列に入れる代わりに、列挙子を使用してページを発行できます。これにより、ページネーションのすべての詳細が著しく隠されます。 たとえば、次のように:
def records Enumerator.new do |yielder| has_more = true page = 1 while has_more response = fetch(page) response.records.each { |record| yielder record } page += 1 has_more = response.has_more end end end
おわりに
Rubyのメモリ使用量を説明し、メモリの問題を追跡するためのいくつかの基本的なツールを調べ、一般的な状況と最適化の方法を調べました。 議論された状況は包括的であるふりをせず、私が個人的に遭遇した最も多様な問題を示しています。 ただし、この記事の主な結果は、コードがメモリ消費にどのように影響するかを考えることです。