
/写真オジーデラニー CC
1cloudでは 、仮想インフラストラクチャプロバイダーと連携した私たち自身の経験と、内部プロセスの整理の複雑さについて多くのことを話します。 今日、データベースの最適化について少し話すことにしました。
多くのDBMSは、データを保存および管理できるだけでなく、サーバー上でコードを実行できます。 この例は、ストアドプロシージャとトリガーです。 ただし、たった1つのデータ変更操作で複数のトリガーとストアドプロシージャをトリガーでき、それらはさらに2つ以上の「ウェイクアップ」を行います。 例は、テーブル内の1行を除外すると他の多くの関連レコードが変更される場合のSQLデータベースのカスケード削除です。
明らかに、高度な機能を使用する場合は、サーバーをロードしないように注意する必要があります。これは、このデータベースを使用するクライアントアプリケーションのパフォーマンスに影響を与える可能性があるためです。
以下のチャートをご覧ください。 データベースで作業するユーザーの数(青色のグラフ)が徐々に50に増えたときに、アプリケーションの負荷テストを実行した結果を示しています。 (黄色)徐々に増加します。
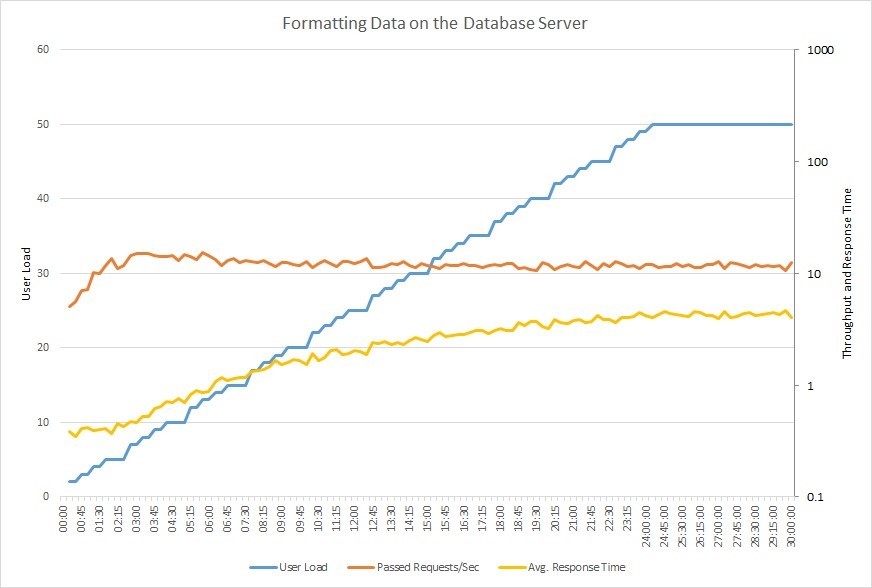
大規模なデータベースを使用する場合、わずかな変更でも、プラスとマイナスの両方の方法で生産性に深刻な影響を与える可能性があります。 中規模および大規模の組織では、管理者がデータベースのセットアップを担当しますが、多くの場合、これらのタスクは開発者の負担になります。 そのため、以下では、SQLデータベースのパフォーマンスを向上させるのに役立つ実用的なヒントを紹介します。
インデックスを使用する
インデックス作成は、データベースをチューニングするための効果的な方法であり、開発中はしばしば無視されます。 インデックスを使用すると、書籍のインデックスを使用して必要な情報をすばやく見つけることができるように、テーブルのデータ行にすばやくアクセスできるため、クエリが高速化されます。
たとえば、主キーでインデックスを作成し、主キーの値を使用してデータ行を検索すると、SQLサーバーは最初にインデックス値を検索し、それを使用してデータ行をすばやく検索します。 インデックスなしでは、テーブルのすべての行のフルスキャンが実行されますが、これはリソースの無駄です。
ただし、INSERT、UPDATE、およびDELETEメソッドを使用してテーブルが「ボンバード」される場合、インデックス作成に注意する必要があります。上記の操作を実行した後、すべてのインデックスを変更する必要があるため、パフォーマンスが低下する可能性があることに注意してください。
さらに、テーブルに多数の行(たとえば、100万を超える行)を一度に追加する必要がある場合、DBAはしばしば挿入プロセスを高速化するためにインデックスを削除します(挿入後、インデックスが再作成されます)。 インデックス作成は広範で興味深いトピックであり、簡単な説明では不十分です。 このトピックの詳細については、 こちらをご覧ください 。
繰り返しの多いループを使用しないでください
1000件のクエリがデータベースに連続して送信される状況を想像してください。
for (int i = 0; i < 1000; i++) { SqlCommand cmd = new SqlCommand("INSERT INTO TBL (A,B,C) VALUES..."); cmd.ExecuteNonQuery(); }
そのようなサイクルは推奨されません 。 上記の例は、いくつかのパラメーターを指定した1つのINSERTまたはUPDATEを使用してやり直すことができます。
INSERT INTO TableName (A,B,C) VALUES (1,2,3),(4,5,6),(7,8,9) UPDATE TableName SET A = CASE B WHEN 1 THEN 'NEW VALUE' WHEN 2 THEN 'NEW VALUE 2' WHEN 3 THEN 'NEW VALUE 3' END WHERE B in (1,2,3 )
WHERE操作が同じ値を上書きしないようにしてください。 このような単純な最適化は、SQLクエリの実行を高速化し、更新される行の数を数千から数百に減らすことができます。 検証例:
UPDATE TableName SET A = @VALUE WHERE B = 'YOUR CONDITION' AND A <> @VALUE – VALIDATION
サブクエリの相関を避ける
相関サブクエリは、親クエリの値を使用するサブクエリです。 これは、外部(親)クエリによって返される行ごとに1行ずつ実行され、データベースの速度が低下します。 相関サブクエリの簡単な例を次に示します。
SELECT c.Name, c.City, (SELECT CompanyName FROM Company WHERE ID = c.CompanyID) AS CompanyName FROM Customer c
ここでの問題は、外部クエリが返す各行(SELECT c.Name ...)に対して内部クエリ(SELECT CompanyName ...)が実行されることです。 パフォーマンスを向上させるために、JOINを使用してサブクエリを書き換えることができます。
SELECT c.Name, c.City, co.CompanyName FROM Customer c LEFT JOIN Company co ON c.CompanyID = co.CompanyID
SELECTを使用しないようにしてください*
SELECT *を使用しないようにしてください! 代わりに、各列を個別に接続する価値があります。 簡単に聞こえますが、この時点で多くの開発者はつまずきます。 数百の列と数百万の行があるテーブルを想像してください。 アプリケーションが数列しか必要としない場合、テーブル全体をクエリしても意味がありません。これはリソースの大きな浪費です。
たとえば、どちらが良いですか:SELECT * FROM EmployeesまたはSELECT FirstName、City、Country FROM Employees?
すべての列が本当に必要な場合は、それぞれを明示的に指定してください。 これは、将来的にエラーや追加のデータベース設定を回避するのに役立ちます。 たとえば、INSERT ... SELECT ...を使用し、ソーステーブルに新しい列が表示される場合、この列が宛先テーブルで不要な場合でもエラーが発生する可能性があります。
INSERT INTO Employees SELECT * FROM OldEmployees Msg 213, Level 16, State 1, Line 1 Insert Error: Column name or number of supplied values does not match table definition.
このようなエラーを回避するには、各列を登録する必要があります。
INSERT INTO Employees (FirstName, City, Country) SELECT Name, CityName, CountryName FROM OldEmployees
ただし、SELECT *の使用が許容される状況があることに注意してください。 例は一時テーブルです。
一時テーブルを賢く使用する
一時テーブルは多くの場合、クエリの構造を複雑にします。 したがって、単純な要求を発行できる場合は、それらを使用しないことをお勧めします。
ただし、1つのクエリでフォーマットできないデータを使用していくつかのアクションを実行するストアドプロシージャを作成する場合は、一時テーブルを「中間体」として使用して、最終結果を取得します。
大きなテーブルから条件を選択する必要があるとします。 データベースのパフォーマンスを向上させるには、データを一時テーブルに転送し、それを使用して既にJOINを実行する必要があります。 一時テーブルは元のテーブルよりも小さいため、結合は高速になります。
一時テーブルとサブクエリの違いは必ずしも明確ではありません。 したがって、例を示します。地域ごとに選択する必要がある数百万のレコードを持つ顧客テーブルを想像してください。 実装オプションの1つは、SELECT INTOを使用した後、一時テーブルに連結することです。
SELECT * INTO #Temp FROM Customer WHERE RegionID = 5 SELECT r.RegionName, t.Name FROM Region r JOIN #Temp t ON t.RegionID = r.RegionID
ただし、一時テーブルの代わりに、サブクエリを使用できます。
SELECT r.RegionName, t.Name FROM Region r JOIN (SELECT * FROM Customer WHERE RegionID = 5) AS t ON t.RegionID = r.RegionID
前の段落で、サブクエリで必要な列のみを記述する価値があることを説明しました。したがって、
SELECT r.RegionName, t.Name FROM Region r JOIN (SELECT Name, RegionID FROM Customer WHERE RegionID = 5) AS t ON t.RegionID = r.RegionID
3つの例のそれぞれは同じ結果を返しますが、一時テーブルの場合、インデックスを使用する機会があります。 一時テーブルとサブクエリの動作原理をより完全に理解するには、スタックオーバーフローに関するトピックを参照してください。
一時テーブルでの作業が完了したら、自動削除が発生するまで待つよりも(データベースサーバーへの接続が閉じられたときに)一時テーブルを削除してtempdbリソースを解放する方が適切です。
DROP TABLE #temp
EXISTS()を使用
レコードの存在を確認する必要がある場合は、COUNT()の代わりにEXISTS()演算子を使用することをお勧めします。 COUNT()がテーブル全体を処理する間、EXISTS()は最初の一致を見つけた後に機能を停止します。 このアプローチにより、パフォーマンスが向上し、コードが読みやすくなります。
IF (SELECT COUNT(1) FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') > 0 PRINT 'YES'
または
IF EXISTS(SELECT FIRSTNAME FROM EMPLOYEES WHERE FIRSTNAME LIKE '%JOHN%') PRINT 'YES'
結論の代わりに
アプリケーションユーザーは、ダウンロードアイコンを長時間見る必要がないとき、すべてがスムーズかつ迅速に機能するとき、それを気に入っています。 この資料で説明されている手法を適用すると、データベースのパフォーマンスを向上させることができ、ユーザーエクスペリエンスにプラスの影響を与えます。
この記事に記載されている重要なポイントを要約して繰り返したいと思います。
- インデックスを使用して、検索とソートを高速化します。
- データを挿入するために繰り返しの多いループを使用しないでください-INSERTまたはUPDATEを使用してください。
- サブクエリの相関を避けます。
- SELECTステートメントのパラメーターの数を制限する-必要なテーブルのみを指定します。
- 一時テーブルは、大きなテーブルを結合するための「中間体」としてのみ使用してください。
- レコードを確認するには、EXISTS()演算子を使用します。この演算子は、最初の一致を判別した後に終了します。
データベースのパフォーマンスのトピックに興味がある場合は、多数の有用なリソースを収集するStack Exchange に関する議論があります。注意してください。 また、世界の大企業がどのようにデータを処理しているかについての資料を読むこともできます。
Habréのブログからの新鮮な素材: