
オオカミと一緒に赤いテープを食べていただろう!
ウラジミール・マヤコフスキー
この記事のレコードの標準化の問題を検討してください。 数十年にわたって蓄積された数百万のレコードをインポートする場合、主に標準化が必要です。 異なる自動システムからの異なるページエンコーディングを持つデータは、情報システムの単一のデータベースに収集されます。 この場合、Unicode形式は書き込みごとに異なるため、QRcharなどのASCII文字列読み取り関数へのアクセスは正当化されません。 さらに、単語のキリル文字には、数字やラテン文字が混じっていることがよくあります(たとえば、「h」の代わりに「4」と書かれている場合)。 同時に、数字とラテン語をキリル文字で一列に直接循環置換することは不可能です。ラテン語の数字は表記法で見つかるからです。
ユーザーディレクトリを使用すると、特定のフラグメントの誤ったスペルのパターンを追跡および記録し、一般的なサイクルで何を変更するかを示すことができます。 エンディングのリファレンスブックにより、スピーチの一部を認識できます。また、スピーチの一部により、行内の単語を移動してテンプレート形式にするためのアルゴリズムを決定できます。

スキャン後に受け取った何千ものレコードを整理するときに、よく似た問題に遭遇します。

不完全なレコード形式を削除しないと、欠陥のあるソートが数回遅くなります。
データをそのまま残す必要がある場合は、レコードの表示のみを変更するユーティリティを使用することをお勧めします。

オプションとして、ADOテクノロジーを使用して、MS Accessに基づいて中間テーブルに同じ2種類のデータを配置します。 クエリの実行時またはループ処理によって、受信したApExレポートのレコードを、事前にクリアされたバックアップ中間テーブルADOTableReserveに移動します。これについては、以下で説明します。 未処理のデータを1つのテーブルADOTableReserveに予約します。 i_RecordCount行とi_ColumnCount列の数、および標準化されるApExレポートレコードを含むi_String列の数を決定します。
openDialog := TOpenDialog.Create(self); openDialog.Filter := '*.xls;*.xlsx|*.xls;*.xlsx'; if openDialog.Execute then begin ApEx := CreateOleObject ('Excel.Application'); try ApEx.Workbooks.Open(openDialog.FileName,0,true); ApEx.DisplayAlerts := false; openDialog.Free; except showmessage (' !'); end; ApEx.Workbooks.Close; ApEx.Application.quit; ApEx := Unassigned; openDialog.Free; end; for i := 1 to i_ RecordCount do begin begin ADOTableReserve.Append; for c:=1 to i_ColumnCount do begin ADOTableReserve.FieldByName('a'+inttostr(ColumnCount)).AsString:= Ap.ActiveSheet.Cells[i, ColumnCount]; end; ADOTableReserve.Post; end;
注意:FieldByNameは、MS Excelレポートの列番号に関する情報を送信します。
別のテーブルADOTableDebugでは、これらのエントリをテンプレート作成に書き込みます。 ADOTableReserveからのデータは、同じ原則に従って、以前にクリアされたADOTableDebugデバッグテーブルに移動されますが、Pattern()関数を参照します。
ADOTableDebug.FieldByName('a'+inttostr(ColumnCount)).AsString:= Trim(AnsiUpperCase(ADOTableReserve.FieldByName('a'+inttostr(ColumnCount)).AsString)); if ColumnCount = i_String then Pattern ();
NB:Pattern()関数は多くのユーザーディレクトリにアクセスし、エントリをテンプレートの外観に導きます。
状況によってエントリをテンプレートのスペルと比較する必要がある場合、ユーティリティには、対応する中間テーブル、これらのテンプレートを格納するユーティリティ内のテンプレートのリストが提供されます。
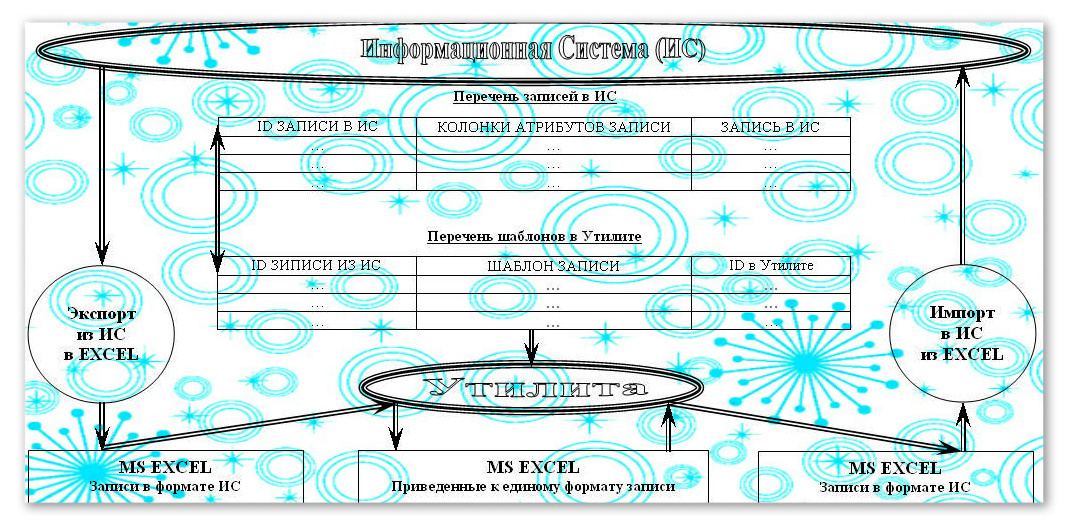
それ以外の場合、語尾のディレクトリに従って名詞を定義し、それらを前に置きます。 数字とラテンアルファベットを名詞のキリル文字に変更します。 エントリの残りの単語は大文字です。 両方のテーブルを画面形式で表示します。 列見出しをクリックして、グリッド内のレコードを並べ替えることができます。 あるテーブルのアクティブなレコードのインデックス検索機能を使用して、別のテーブルの同じレコードにすばやくジャンプします。 データを分析し、データをさらに処理するためにMS Excel形式のレポートを生成し、テンプレートフォームのレコードを処理するレポートを提供します。 レポートには、作業列のコメントが追加されます。 必要に応じて、上記のADOTableDebugテーブルのアルゴリズムに従って情報システムデータベースにコメントを追加します。MSExcel形式のレポートのレコードに対応する行が見つかります。 ステージングテーブルADOTableReserveとADOTableDebugのIDは同じです。 ADOTableDebugテーブルのコメントを使用してADOTableReserveテーブルを更新します。 レコードの元の形式に戻り、コメントを情報システムデータベースにインポートするためのMS Excel形式のレポートを生成します。 作業列にコメントが追加されたMS Excel形式のレポートに情報システムの行の識別子が含まれている場合、レコードは元の形式に縮小されません。 次に、コメントを情報システムデータベースにインポートするために、単語のテンプレートスペルを含むレポートを送信します。

単一のデータベース内のすべてのレコードを置き換え、クライアントサーバーモードで同時に更新することで合意に達することができる場合、最も興味深い部分が始まります-レコードの標準化を可能にするパターン()関数によって使用されるユーザーディレクトリの集合的な改良。