
TotalCommanderでhtmlビューアーを見ました。 私は自分のOS用にシンプルで非常に小さなテキストブラウザを書くというアイデアを得ました。 最初は、優れたパーサーであるasm-xmlに注目しましたが、非常に大きいです(私の制限は64キロバイトであり、技術的ではなく、単なる原則です)。 以下は、htmlからテキストを取得する非常に簡単な方法です。
独立したコード(OS用)が必要であるため、すぐに予約するので、既製のライブラリはすべてすぐに消えます。 なぜアセンブラー? -OSのすべてがその上に書かれているからです。 しかし、メソッドは任意の言語に移動できます...
したがって、コードのサイズが小さいことが重要であるため、ツリー構築を使用する古典的なパーサーから、階層構造の解析を拒否することにしました。 「額に」行きました。
実際には、プロセスはいくつかの段階で構成されています。
まず、スクリプトタグのコンテンツを削除する必要があります-コードが直接記述されているもののみであり、外部スクリプトが接続されている場所ではありません。 なんで? いくつかの非常に大きなスクリプトが私のパーサーのロジックを壊すことを発見したとき、私はちょうど実験によってそれに到達しました)
次はメインループです。 すべてのタグを段階的に(より正確には、バイトごとに)実行します(タグの開閉を探します)。 つまり 最終的にはタグツリーではなく、dwordヘッダーで満たされた行で構成されるリストになります。
テキストがタグの下にない場合、単純にテキストとして記述します。
一時的な構造は次のようになります(見出しは接線-タグ指定で強調表示されます):
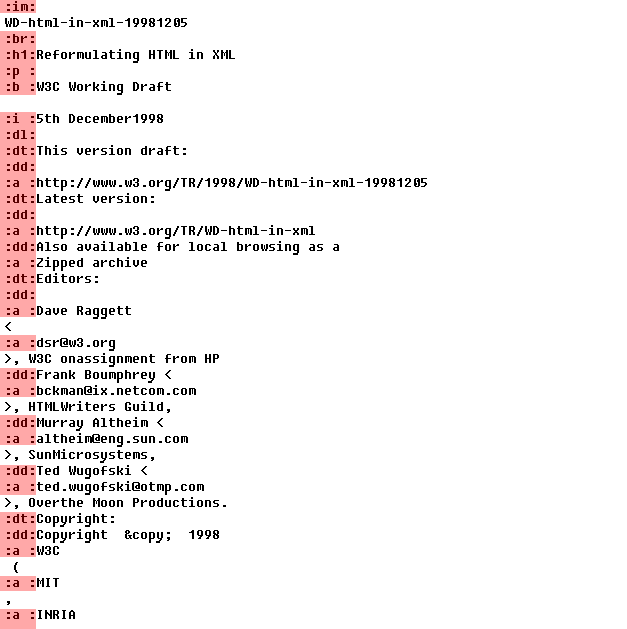
その瞬間について説明します。 各タグに対応するハッシュまたは識別子を与えると、より論理的に見えるでしょう。 ただし、このためには、すべての種類のタグを解析する必要があります。たとえば、<pおよび<p style = ...-個別にチェックする必要があります。 そして、私たちにとっては、各バイトを4バイト比較したファイルへの単なる通路です。
inc esi
cmp byte[esi + 0], '<'
これが開始タグの場合、<p class ...をpに変換します。
もちろん、これは怠slot、govnokodなどですが、高速で短く、効果的です!
それでは、タグの種類に応じて、実際に結果のリストと行を実際に取得し、対応する処理手順の処理を行います。これは、出力バッファーに既に書き込まれています。 (まだ美的な些細な事があります-スペース、ハイフネーションなどの繰り返しを削除します。)
「govnokod」、「learn materiel」などのコメントを楽しみにしています。 したがって、私はすぐに言います:コード(記事の最後、リンク)は「膝の上」で書かれた単なるプロトタイプです。 わずか4kbのプログラム!
参考までに、実際の例(Habrのメインページのソースhtmlで確認しました-下の画面)-すべてが動作します。 唯一のものはファイルサイズの制限です(まだメモリ割り当てを追加していないため、3〜64 KBの初期化されていないバッファを使用しています)。 作業後、プログラムは2つのファイルを提供します-1つはリストが一時的で、もう1つは完成したテキストです。 テキストではハイフネーションが0x0Aであるため、TotalCommanderをテキストモードで見ることに注意してください。
ドキュメント「W3C Reformulating HTML in XML」でテストします。
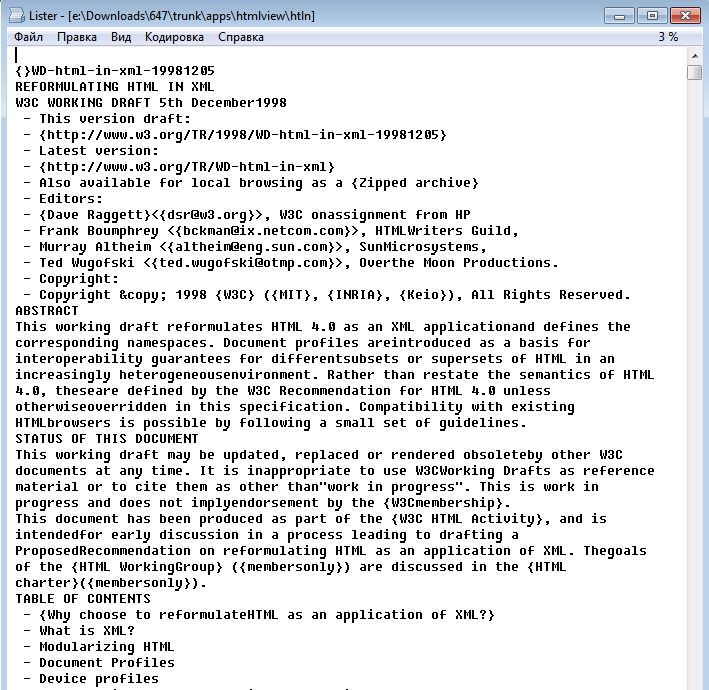
Habrahabrのメインページでテストします。

ソース+ win32binary
そして今、問題は次のとおりです。4K未満になるのは誰か。