この夏のプレゼンテーションの準備として、PostgreSQL Cソースコードの一部を調査することにし、非常に単純な選択クエリを実行し、CデバッガーであるLLDBを使用してPostgresがそれをどのように処理するかを見ました。 彼は私が探していたデータをどのように見つけましたか?

この投稿は、PostgreSQLの内部についての私の旅の非公式ジャーナルです。 私が旅した道と、その過程で見たものを説明します。 一連の単純な概念図を使用して、Postgresが私の要求をどのように満たしたかを説明します。 Cを理解している場合、Postgresの内部を突っ込んだ場合にあなたが探すことができるガイドラインとポインタも残しておきます。
PostgreSQLのソースコードは私を喜ばせました。 クリーンで、十分に文書化されており、理解しやすいことがわかりました。 Postgresが内部からどのように機能するかを自分で確認し、毎日使用する楽器の深みへの旅に参加してください。
キャプテンニモを見つける
これは私のプレゼンテーションの前半からのリクエストの例です。 彼がCaptain Nemoを検索している間、Postgresをフォローします。

テキスト列で単一の名前を見つけるのは簡単ですよね? 深海のダイバーがロープにつかまって水面に戻る方法を調べながら、Postgresの内部を調べて、この選択クエリを厳しく保持します。
全体像
PostgresはこのSQL文字列で何をしますか? 彼は私たちの意味をどのように理解していますか? 彼はどのデータを探しているのかをどのようにして知るのでしょうか?
Postgresは、送信する各SQLコマンドを4つのステップで処理します。

最初に、PostgreSQL は SQLクエリを解析し 、それをメモリに保存されている一連のCデータ構造、つまり解析ツリーに変換します 。 その後、Postgresはクエリを分析および書き換え 、一連の複雑なアルゴリズムを使用してクエリを最適化および簡素化します。 その後、彼はデータを検索する計画を作成します。 ポートフォリオが入念に詰められるまで家を出ない強迫性障害の人のように、Postgresは計画を立てるまでリクエストを開始しません。 最後に、Postgres が要求を満たします。 このプレゼンテーションでは、最初の3つのステップに簡単に触れた後、最後の、リクエストの実行に焦点を当てます。
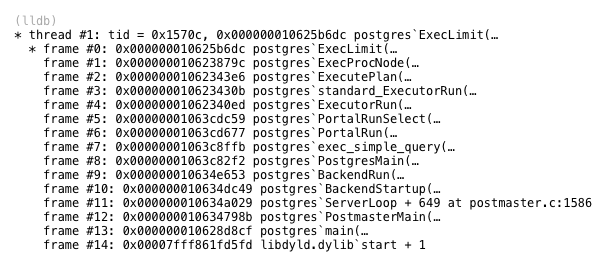
この4段階のプロセスを実行するPostgres内のC関数は、exec_simple_queryと呼ばれます。 Postgresがexec_simple_queryを呼び出すタイミングと方法の詳細を示すLLDBトレースとともに、以下へのリンクを見つけることができます。

exec_simple_query
postgresql.orgで表示
解析
Postgresは、送信したSQL文字列をどのように理解しますか? 選択クエリのキーワードとSQL式でどのように意味がありますか? parsingと呼ばれるプロセスを通じて。 Postgresは、SQL文字列を、彼が理解する内部データ構造、つまり解析ツリーに変換します。
PostgresはRubyと同じ解析テクノロジー、つまりBisonと呼ばれるパーサージェネレーターを使用していることがわかります。 Bisonはpostgresビルドプロセス中に動作し、一連の文法規則に基づいてパーサーコードを生成します。 生成されたパーサーコードは、SQLコマンドを送信したときにPostgres内で機能するものです。 生成されたパーサーがSQL文字列で対応するパターンまたは構文を検出し、構文解析ツリーに新しいCメモリ構造を挿入すると、各文法規則が呼び出されます。
今日は、解析アルゴリズムの仕組みの詳細な説明に時間を費やしません。 これらのトピックに興味がある場合は、私の本Ruby Under a Microscopeを読むことをお勧めします。 最初の章では、BisonとRubyで使用されるLALR解析アルゴリズムの例を詳しく見ていきます。 Postgresは、まったく同じ方法でSQLクエリを解析します。
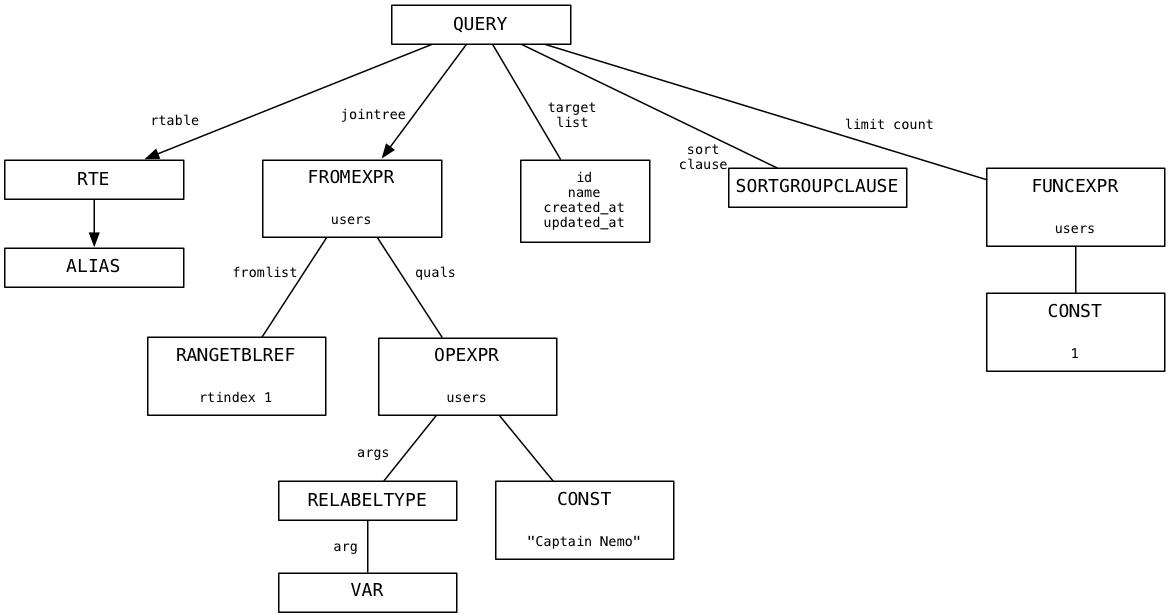
LLDBを使用し、一部のログコードCをアクティブにして、PostgresパーサーがCaptain Nemoの検索クエリ用に次の解析ツリーを作成するのを見ました。

最上部は完全なSQLクエリを表すノードであり、下はSQLクエリ構文のさまざまな部分を表す子ノードまたはブランチです:ターゲットリスト(列のリスト)、条件(テーブルのリスト)、WHERE句、ソート順、レコード数。
PostgresがSQLクエリを解析する方法の詳細を知りたい場合は、pg_parse_queryと呼ばれる別のC関数を使用して、exec_simple_queryからの実行順序に従います。
pg_parse_query
postgresql.orgで表示
ご覧のとおり、Postgresのソースコードには、何が起こっているのかを説明するだけでなく、重要な設計上の決定を示す多くの便利で詳細なコメントがあります。
尾の下の犬のすべての仕事
上記の構文解析ツリーはおそらくおなじみのように思えます。これは、ActiveRecordで以前に観察したのとほぼ同じ抽象構文ツリー(AST)です。 プレゼンテーションの最初の部分を思い出してください。ActiveRecordは、Rubyでこのクエリを実行したときに、Captain Nemoに関する選択クエリを生成しました。

whereおよびfirstのようなメソッドを呼び出すと、ActiveRecordが内部ASTビューを作成することがわかりました。 後で( 2番目の投稿を参照)、gem Arelが訪問者パターンに基づくアルゴリズムを使用してASTをサンプル選択クエリに変換するのを見ました。
考えてみると、PostgresがSQLクエリで最初に行うことは、文字列からASTに戻すことです。 Postgresの解析プロセスは、ActiveRecordが以前に行ったすべてをキャンセルし、gem Arelが行ったすべてのハードワークは無駄になりました! SQL文字列を作成する唯一の理由は、ネットワーク経由でPostgresにアクセスすることです。 しかし、Postgresはリクエストを受信するとすぐに、ASTに戻します。これは、リクエストを送信するためのはるかに便利で便利な方法です。
これを学んだ後、あなたは尋ねるかもしれません:より良い方法はありますか? SQLクエリを作成せずに、必要なデータをPostgresに概念的に説明する他の方法はありますか? 複雑なSQL言語やActiveRecordとArelを使用する余分なオーバーヘッドを学ぶ必要はありませんか? ASTからSQL文字列を作成して、再びASTに戻すためだけに長い時間を費やすのは、非常に時間の無駄です。 代わりにNoSQLソリューションを使用する必要がありますか?
もちろん、Postgresが使用するASTはActiveRecordが使用するASTとは非常に異なります。 ActiveRecordでは、ASTはRubyオブジェクトで構成され、Postgresでは、メモリに格納された一連のC言語構造で構成されます。
分析と書き換え
Postgresは構文解析ツリーを生成すると、異なるノードのセットを使用して別のツリーに変換します。 これはクエリツリーとして知られています 。 C関数exec_simple_queryに戻ると、別のC関数-pg_analyze_and_rewriteが呼び出されていることがわかります。
pg_analyze_and_rewrite
postgresql.orgで表示

詳細を説明することなく、分析および書き換えプロセスでは、SQLクエリを最適化および簡素化するために、多数の複雑なアルゴリズムとヒューリスティックを使用します。 ネストされたクエリと多数の内部および外部結合を使用して複雑な選択クエリを実行する場合、最適化の範囲は膨大です。 Postgresは、ネストされたクエリまたは結合の数を減らして、より簡単なクエリを作成できる可能性があります。
単純な選択クエリの場合、pg_analyze_and_rewriteは次のクエリツリーを作成しました。
pg_analyze_and_rewriteの背後にあるアルゴリズムを詳細に理解しているふりはしません。 この例では、クエリツリーは構文解析ツリーに非常に似ていることに気付きました。 これは、選択クエリが非常に単純だったため、Postgresでさらに簡単にできなかったことを意味します。
計画
Posgresが要求を満たす前に行う最後の作業は、計画の作成です。 このプロセスには、Postgresの指示のリストであるノードの3番目のツリーの作成が含まれます。 選択リクエストのプランツリーを次に示します。
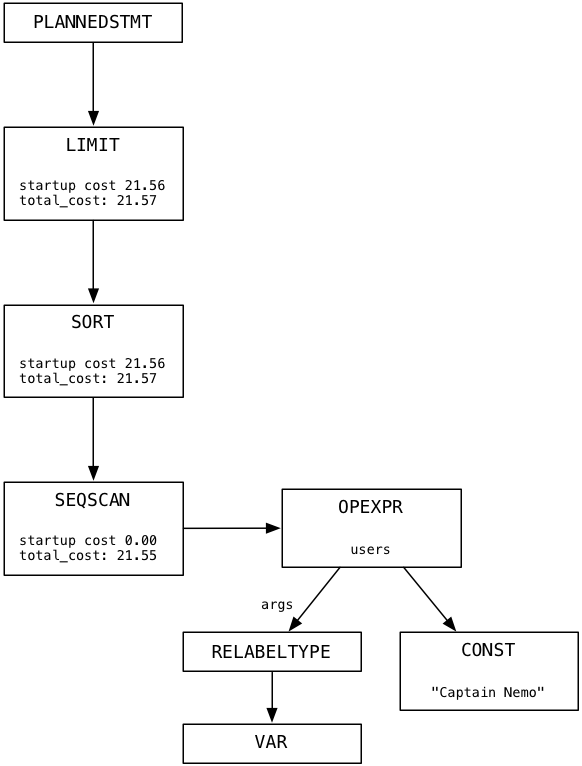
計画ツリーのすべてのノードがマシンまたはワーカーであると想像してください。 計画ツリーは、工場のデータパイプラインまたはコンベヤベルトに似ています。 私の簡単な例では、ツリーにはブランチが1つしかありません。 計画ツリーの各ノードは、基礎となるノードの出力からデータを取得して処理し、結果を上のノードのソースデータとして返します。 次の段落では、彼が計画を実行するときにPostgresをフォローします。
クエリスケジューリングプロセスを開始するC関数は、pg_plan_queriesと呼ばれます。
pg_plan_queries
postgresql.orgで表示

各ノードのstartup_costおよびtotal_cost値に注意してください。 Postgresはこれらの値を使用して、計画を完了するのにかかる時間を推定します。 リクエストの実行計画を確認するためにCデバッガーを使用する必要はありません。 クエリの最初にSQL EXPLAINコマンドを追加するだけです。 このように:

これは、pg_plan_queriesの複雑なスケジューリングアルゴリズムにもかかわらず、Postgresがクエリの1つで内部的に行っていることと、それが遅いまたは非効率である理由を理解するための素晴らしい方法です。
計画ノード実行の制限
この時点で、PostgresはSQL文字列を解析し、それをASTに変換し直しました。 それから彼はそれを最適化し、書き直し、おそらくそれを単純化した。 その後、Postgresは、探しているデータを見つけて返すために従う計画を書きました。 そして最後に、Postgresがあなたの要求を満たす時間です! 彼はどのようにそれをしますか? もちろん、計画に従ってください!
計画ツリーの最上部から始めて、下に移動しましょう。 ルートノードをスキップすると、PostgresがCaptain Nemoのリクエストに使用する最初の従業員はLimitと呼ばれます。 ご想像のとおり、LimitノードはSQL LIMITコマンドを実行し、結果を特定のレコード数に制限します。 また、このプランノードはOFFSETコマンドを実行し、指定された行から開始して一連の結果を含むウィンドウを開始します。

制限ノードが初めて呼び出されたとき、Postgresは制限値とオフセット値を計算します。これらの値は動的な計算の結果に結び付けられるためです。 この例では、オフセットは0で、制限は1です。
次に、Limit planノードは、オフセット値に達するまでサブプラン(この場合はSort)を繰り返し呼び出します。

この例では、オフセットはゼロであるため、このループは最初のデータ値をロードし、反復を停止します。 その後、Postgresは、サブプランから呼び出し元または上位のプランにロードされた最後のデータ値を返します。 私たちにとって、これはサブプランからの最初の値になります。
最後に、PostgresがLimitノードを呼び出し続けると、サブプランからデータ値を1つずつ送信します。
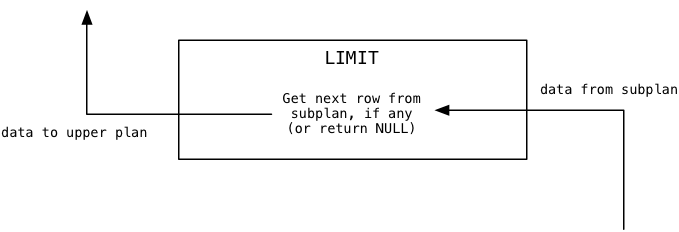
この例では制限は1であるため、LimitはすぐにNULLを返し、上位のプランに対して利用可能なデータがないことを示します。
Postgresは、nodeLimit.cというファイルのコードを使用して制限ノードを実行します
実行制限
postgresql.orgで表示
Postgresのソースコードがタプル (値のセット、各列から1つ)やサブプランなどの単語を使用していることがわかります。 この例では、サブプランはソートノードであり、プランの制限の下にあります。
ソートプランノードの実行
制限フィルターのデータ値はどこから来ますか? プランツリーの[制限]の下にある[並べ替え]ノードから。 ソートは、そのサブプランからデータ値をロードし、それらを呼び出し制限ノードに返します。 次に、Limitノードが最初に呼び出して最初のデータ値を取得するときにSortが行うことを示します。

ご覧のとおり、ソート機能は制限とはまったく異なります。 何かを返す前に、利用可能なすべてのデータをサブプランからバッファにすぐにロードします。 次に、 Quicksortアルゴリズムを使用してバッファーを並べ替え、最後に並べ替えられた最初の値を返します。
2回目以降の呼び出しでは、Sortはソートされたバッファから追加の値を返すだけで、サブプランを再度呼び出す必要はなくなりました。

ソートプランノードは、ExecSortと呼ばれるC関数によって実行されます。
エグゼクソート
postgresql.orgで表示
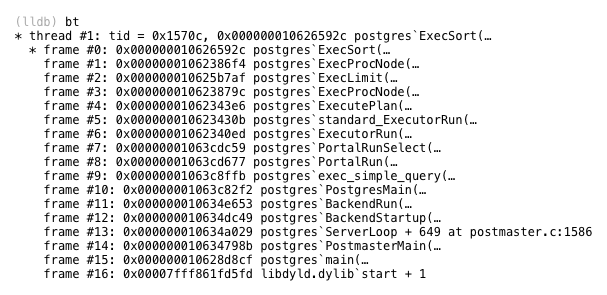
SeqScan計画ノードの実行
ExecSortはどこから値を取得しますか? そのサブランから-プランツリーの一番下にあるSeqScanノード。 SeqScanは順次スキャンの略で、テーブル内のすべての値を表示し、指定されたフィルターに一致する値を返すことを意味します。 スキャンがフィルターでどのように機能するかを理解するために、架空の名前が入力されたユーザーテーブルを想像して、Captain Nemoを探してみましょう。

Postgresは、テーブル内の最初のレコード(Postgresソースコードでは関係と呼ばれます)から始まり、プランツリーからブール式を開始します。 簡単に言えば、Postgresは「このキャプテンニモですか?」という質問をします。ローリアン・グッドウィンはキャプテンニモではないため、Postgresは次の投稿に進みます。

いいえ、キャンディスはキャプテンニモでもありません。 Postgresは続きます:
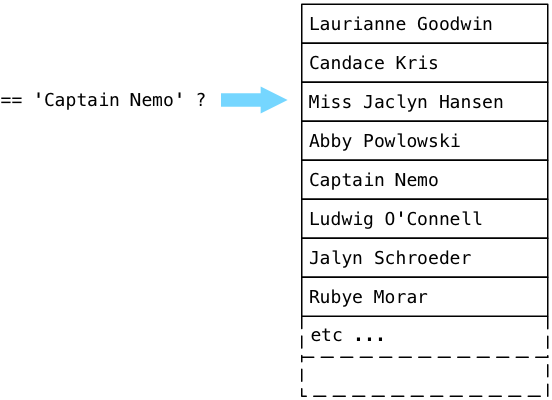
...そしてついにキャプテンニモを見つけました!
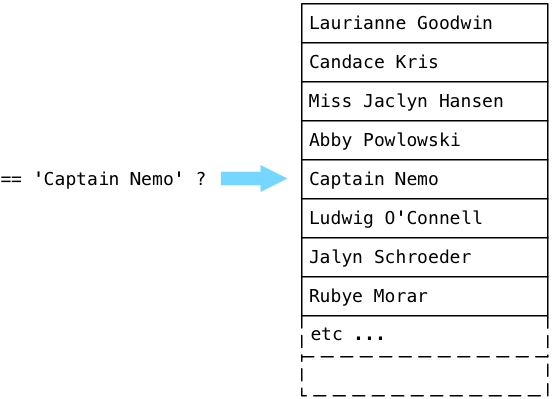
Postgresは、ExecSeqScanと呼ばれるC関数を使用してSeqScanノードを実行します。
ExecSeqScan
postgresql.orgで表示
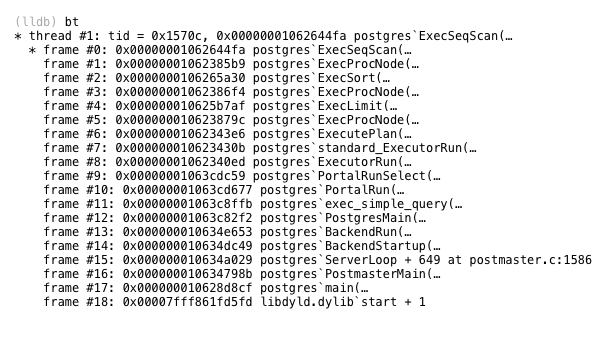
私たちは何を間違っていますか?
これで終わりです! Postgresの内部全体で単純な選択クエリを実行し、それがどのように解析、書き換え、計画、および最終的に実行されるかを確認しました。 何千行ものCコードを実行した後、Postgresは探しているデータを見つけました! これで、Captain Nemoの行をRailsアプリケーションに戻すだけで、ActiveRecordがRubyオブジェクトを作成できるようになります。 最後に、アプリケーションの表面に戻ることができます。
しかし、Postgresは止まりません! データを返すだけでなく、ユーザーテーブルのスキャンを続けますが、Captain Nemoが既に見つかっています。

何が起こっているの? 必要なデータを既に見つけているにもかかわらず、Postgresが検索に時間を費やすのはなぜですか?
答えは、プランツリーの[並べ替え]ノードにあります。 すべてのユーザーを並べ替えるために、ExecSortは最初にすべての値をバッファーにロードし、値がなくなるまでサブプランを繰り返し呼び出します。 つまり、 ExecSeqScanは 、適切なユーザーをすべて収集するまで、テーブルの最後までスキャンを続けます。 テーブルに数千または数百万のレコードが含まれている場合(FacebookまたはTwitterで作業していると想像してください)、ExecSeqScanはすべてのユーザーレコードについてサイクルを繰り返し、それぞれについて比較を実行する必要があります。 明らかに、これは遅くて非効率的であり、新しいユーザーエントリがテーブルに追加されるにつれて、ますます遅くなります。
Captain Nemoに関するレコードが1つしかない場合、ExecSortはこの適切なレコードのみを「ソート」し、ExecLimitはそのレコードをオフセット/制限フィルターに渡しますが、ExecSeqScanがすべての名前を通過した後にのみです。
次回
この問題を解決するには? ユーザーテーブルでSQLクエリを実行するためにますます時間が必要な場合はどうなりますか? 答えは簡単です。インデックスを作成します。
このシリーズの次と最後の投稿では、Postgresでインデックスを作成し、ExecSeqScanの使用を避ける方法を学びます。 しかし、最も重要なことは、Postgresでインデックスがどのように見えるかを示します。それがどのように機能し、なぜこのようなクエリを高速化するかです。