
エントリー
ある晴れた日、私はある物語のために図書館に行きました。 司書に物語の名前と著者を言った後、彼はこの著者のコレクションのスタックを受け取りました。 こうした多様性の中から適切なストーリーを見つけるために、すべての作品を検討しなければなりませんでした。 目的の作業を「グーグル」して、数回クリックするだけで必要なものを取得する方がはるかに簡単です。

そして、私は考えました:「なぜライブラリにそのようなものがまだないのですか? とても便利です!」 当然、まともな怠け者のプログラマーのように、私は検索エンジンに直接行き、同様のプロジェクトを探しました。 そして問題にぶつかりました。 見つかったすべてのプロジェクトは、商用(有料)、またはアマチュアで低品質のいずれかでした。
当然のことながら、このような不正は、大学に入学する試験や入学にもかかわらず、緊急に対処する必要がありました。
言語選択
まず、Webパーツなしではできないことが明らかになりました。 ウェブプログラミングに対する個人的な不寛容にもかかわらず、私はGoogleに座ってこの問題を研究し始めました。
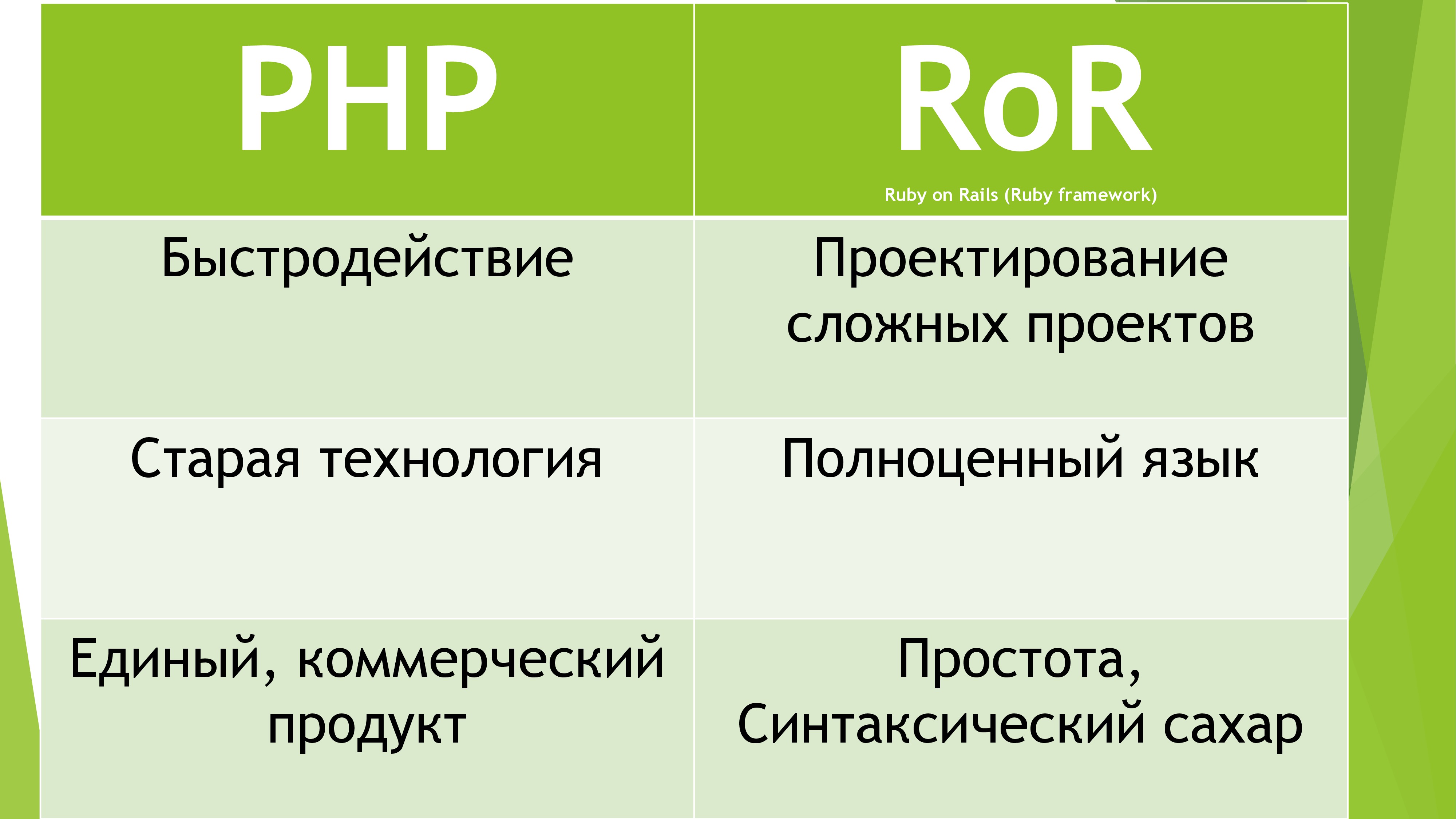
数時間後、私は最終的に必要な言語を選択しました。 より正確には、言語ではなく、FrameWork RubyOnRails。 彼はなぜですか? 本格的なOOP言語を使用しているため、巨大なコミュニティによって積極的に開発され、高速なコアを備えています。 さらに、女の子はRubyが大好きです(プレゼンテーションでは話さない方がいいです)。
当然、それは「美しい」Ruby言語に基づいていました。 私はジュニアレベルでJavaを知っているので、他のOOP言語を学ぶことは難しくありませんでした。 私は1週間、毎晩2つの講義を見て、その結果、Ruby構文の必要な知識を誇っていました。 そして、私の自信が低下しました...そして、すべてこのフレームワークは非常に巨大で広大であるため、Rubyの知識は私をほんの少し助けました。 MVCテクノロジーと悪のWebプログラマーのその他のアイデアを研究した後、私はプロジェクトを実装し始めました。
ログイン
奇妙なことに、承認が私の道の最初の障害でした。 OAuthテクノロジーを使用することにしました。 その原則は、パスワードの代わりにトークンが使用されることです。 トークンを使用すると、パスワードが盗まれることを心配せずに、各トークンを自分用に構成できます(たとえば、1回の操作のみの権限を持つワンタイムトークンを取得できます)。 サーバー側にパスワードを保存するために、最初はMD5暗号化を使用することにしましたが、インターネットでそれを読んだ後、この方法は時代遅れであると判断しました。 新しいコンピューターでのハッキングにはわずか1分かかります。 そのため、データベース内のパスワード復号化に対してほぼ100%の保護を提供するbCryptを使用することにしました。 そのようなシステムを自分で作ることにしたので、最適化について考えなければなりませんでした。 まず、データベースでバイナリ検索を検索できるように、トークンを文字列から数値に変換する必要がありました。

認可された単純な学校プロジェクトでは複雑になりそうですか? はじめに、私は20時間認証ウィンドウを行いました。 そして、私のプロジェクトは完全にオープンソースであり、ローカルネットワークで実行されているという事実から続けましょう。つまり、トークンをインターセプトするには、モバイルにサーバーを展開するだけで十分です。 そのため、独自のサーバー検証システムを思いつきました。 各トークンで、サーバーは2つの値を発行します。 データベース内のIDおよび一意の小さな識別子。 クライアントがサーバーの有効性を確認するたびに、サーバーにIDを送信し、サーバーは識別子を返します。 その後、クライアントはサーバーにトークンを送信します。 両側からの承認が判明します。
検索アルゴリズム
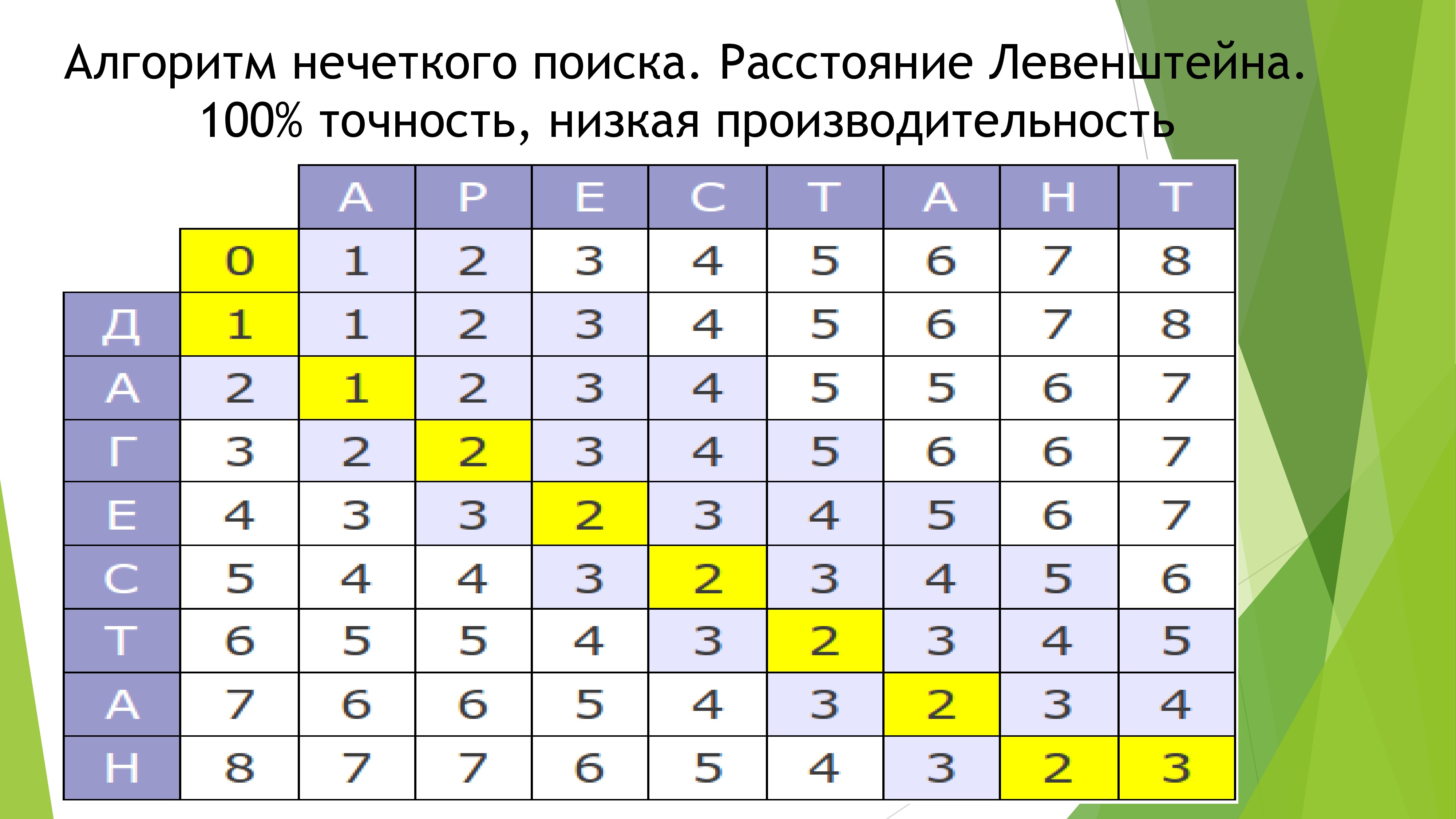
そのようなすべてのプロジェクトで、弱点は検索です。 私はこのような欠陥が私のプロジェクトに存在することを望まないでしょう。 すべての主要な検索エンジンがインターネット接続を必要とするという事実により、既製のソリューションの使用は完全に排除されます。 したがって、私はこの問題に真剣に取り組みました。 アルゴリズムに関する本を読んだ後、Damerau-Levenshtein距離アルゴリズムを使用して文字列を比較する方がよいと判断しました。これは、プロジェクトにとって最も重要な生産性の低下に対して最大の精度を持っているからです。 しかし、文全体の比較には問題がありました。 最初は、比較テーブルをグラフツリーに分解する同様のアルゴリズムを使用しました。 長い間、私はこれに苦しんでいましたが、最終的には間違った結果になりました。 したがって、すべてが破壊され、文の比較に別のアルゴリズムが挿入されました。 彼の原則は狂気に単純です。 単語のエラーが3つ未満の場合は、正しいものと考えて、最終インデックスに1ポイントを追加します。 2つの正しい単語が連続する場合は、さらに1ポイントを追加します。 などなど。
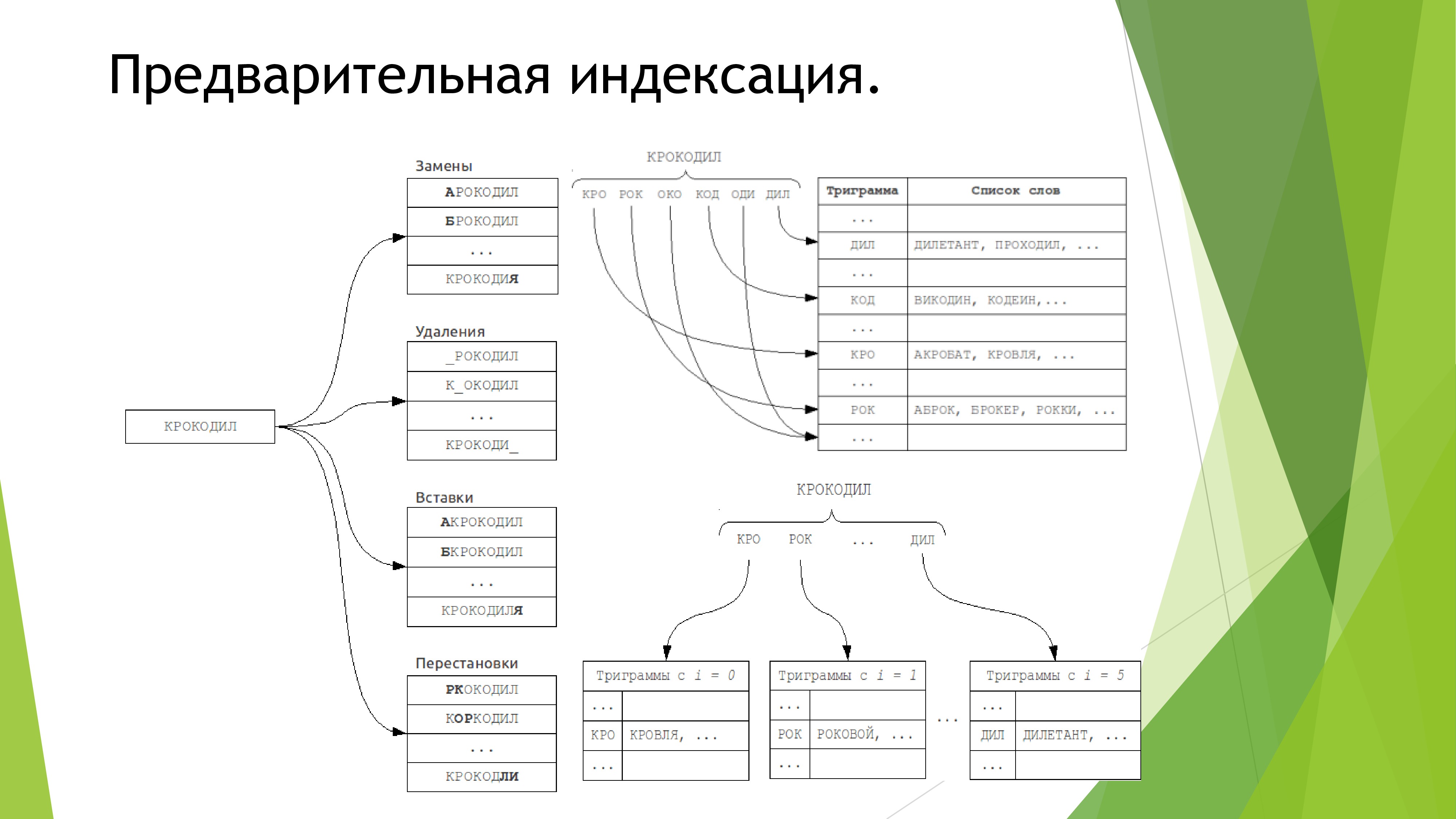
検索は非常に厳密に定義されているため、文の構文上の意味を使用しても意味がありません。 したがって、今後は音声検索を追加し、システムの自己学習の改善とすべてのデータの集中化に向けて引き続き作業する予定です。

検索の品質を向上させる別の方法は、自習です。 実際には、各リクエストはデータベースに記録され、必要に応じて、ポピュラーな本にポイントを発行することができます。 Goshユーザーがサイエンスフィクションを愛しているとします。 サイエンスフィクションに関する書籍の数が他のジャンルをはるかに超えていることから、これを理解しました。 したがって、その後、検索結果が返されると、検索システムはフィッシュブックの追加ポイントをGoshユーザーに追加します。 さらに、統計調査のこのような大きな層は有用です。
当然のことながら、このアルゴリズムは後でさまざまな最適化を取得しましたが、それ以降はさらに最適化されました。 このようなリソース集約的なアルゴリズムをC ++で実装し、Riceプラグインを使用してRubyからブリッジを作成することにしました。 ここに、私がRubyOnRailsを選択し、それを後悔しなかった別の良い例があります。
画像認識
画像内のテキストを認識するメカニズムのみが、ライブラリの迅速なデジタル化の問題の解決に役立ちます。 画像をPCウェブカメラに読み込むのはかなり愚かであるため、スマートフォン用のモバイルアプリケーションを開発することにしました。 基本的なアプリケーションの作成には約1週間かかりました。 スマートフォンは、アプリケーション設計にマルチスレッドとかなり厳しい基準を積極的に使用しています。
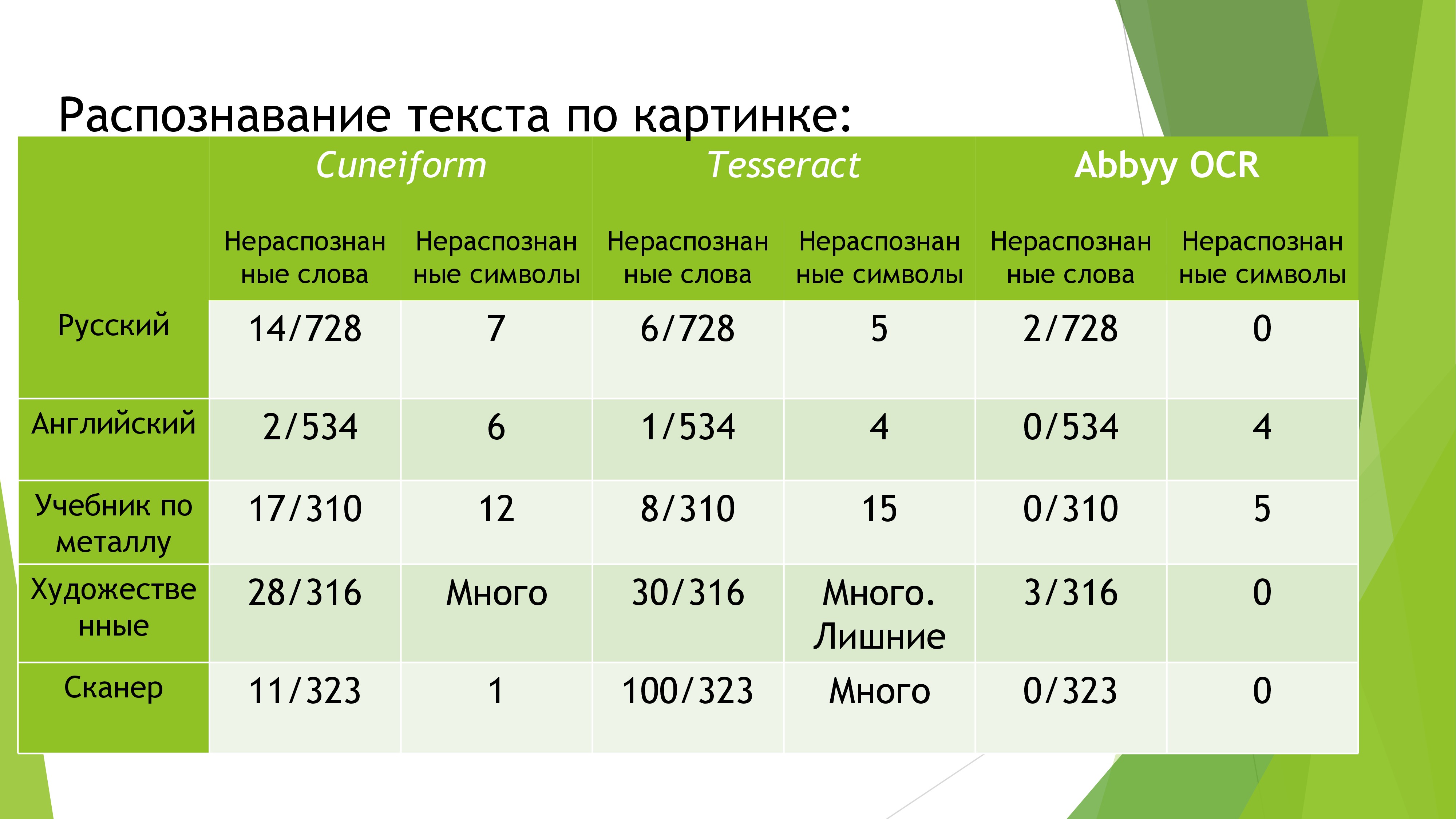
その後、既存のソリューションの詳細な分析を行った後、OCRテクノロジーに基づいた最高の無料のオープンソース製品としてTessaractを選びました。 さらに、Googleによって積極的にサポートされています。 彼と一緒に遊んでみたが、そのような結果は良くないだろうと気づいた。 正確に認識するには、かなり長い時間画像の前処理を行わなければなりません。 さらに、このプロジェクトのソースで、いくつかの重大なアルゴリズムエラーを発見しましたが、その修正は長時間続く可能性があります。 したがって、私の声に悲しみを持って、アビーから一時的な免許を求めに行きました。 2週間の毎日の電話の後、私はそれを受け取りました。 ドキュメンテーションとJavaラッパーが非常によく書かれていて、そのような製品で作業できたことを嬉しく思いました。 ただし、認識メカニズムは100%の精度にはほど遠いです。 そのため、自動修正を行う必要がありました。 数時間にわたって、人気のあるサイトlabirint.ruから書籍のデータベース全体をダウンロードするボットを作成しました。 同様のデータベースと前述の検索アルゴリズムを使用して、書籍の認識精度が大幅に向上しました。
ISBN

本を読むことの明らかな使いやすさにもかかわらず、私はISBNを通してオートコンプリートフィールドを使用することにしました。 ISBNブックデータベース全体をダウンロードするのは愚かなので、Google Book Apiを使用してISBNを検索することにしました。 また、オフラインのユーザーは200,000以上のロシア語の書籍で迷路データベースにアクセスできます。 さらに、本のバーコードスキャナーを(同じAbbyy APIで)実装するのは簡単で、本を追加するのは楽しいことです。
超高速ライブラリデジタル化アルゴリズム

棚を撮影して、すべての本を電子カタログに追加するといいと思いました。 これは、無料のOpenCVライブラリと組み込みのKenny境界検出器を使用してのみ簡単に実現できます。 さらに、本の主要な行のより深刻な分析のために独自のアルゴリズムを作成し、各脊椎をAbbyy APIに送信して必要なテキストを取得し、迷路データベースを介して処理し、撮影された画像上でUIとの対話の要素を表示する必要があります。 (残念ながら、私はこの機能を頭の中で終わらせることができませんでした。時間がありません)
おわりに

プロジェクトの低コストと広範な技術基盤により、普通の市立学校の生徒でさえも、高度で便利な技術を利用できます。 製品が完全にオープンであり、インターネットにアクセスしなくても正常に動作することに注意してください。 さらに、プロジェクトのリソース消費により、 Raspberry PIでも20ドルのコストでサーバーを実行できます。
これは私の人生で何の助けにもならなかったという事実にもかかわらず、本格的なウェブサイトとアプリケーションの開発において貴重な経験を積むことができ、非常に興味深いものでした。 さて、いくつかのスクリーンショット:

情報源
- サイトwww.stackoverflow.comの英語を話す聴衆に感謝します
- ファジー検索に関する一連の優れた記事についてhabrahabr.ru ntzに感謝します。
- このプロジェクトでは、 www.wikipedia.orgの資料も使用しました
- 同級生のエフゲニア・レンドラソワに、美しく活気のあるロゴをありがとう
- 私の努力をサポートしてくれた先生に感謝します
- テキスト認識にOCRを提供してくれたABBYYに感謝します。 彼がいなければ、このプロジェクトを実現できなかった