
ファウンテンコードの注目すべき特性は、パケット損失のレベルに関する知識に依存することなく、また受信者が送信者に連絡して欠落データを回復する必要なく、インターネットなどを介して信頼性の低い通信チャネルでデータを送信できることです。 このような機会が多くの状況で非常に役立つことは容易にわかります。 たとえば、オンデマンドのビデオ伝送システムのように、ブロードキャスト通信チャネルで情報を送信します。 ファイルのフラグメントが多数のピアに分散されている場合、Bittorrentプロトコルおよびその他の類似のプロトコルの動作は、タスクの同じカテゴリに属します。
基本原則
噴水コードは非常に複雑なように思えるかもしれません。 しかし、これはまったく真実ではありません。 このアルゴリズムにはさまざまな実装がありますが、最も単純なものから始めることをお勧めします。 これはいわゆるLabi変換コードです。要するに、通常はLuby Transform CodeからLTコードと呼ばれます 。 このファウンテンコードのバリアントを使用する場合、ブロックは次のようにエンコードします。
- 1〜kの範囲から乱数dを選択します。 範囲は、ファイル内のブロック数に対応しています。 以下で、dを選択する最善の方法について説明します。
- d個のファイルブロックをランダムに選択して結合します。 この例では、XOR操作が適しています。
- 前の手順で取得したブロックは、作成元のブロックに関する情報とともに送信されます。
ご覧のとおり、複雑なことは何もありません。 ただし、このスキームの多くは、いわゆるコードシンボルの次数の分布、結合する必要のあるブロック数の選択方法に依存することに注意してください。 この問題に戻ります。 説明から、エンコードされたブロックの一部は、ソースデータの1つのブロックのみを使用して実際に作成され、ほとんどのブロックのコーディングには複数のソースブロックが含まれることがわかります。
以下に、一見したところ明らかではない別のコーディング機能を示します。 これは、出力ブロックを取得するために結合しているブロックを受信者に知らせる限り、このリストを明示的に送信する必要がないという事実にあります。 送信者と受信者が特定の疑似乱数ジェネレーターに同意した場合、ランダムに選択した数値でジェネレーターを初期化し、それを使用して次数分布とソースブロックのセットを選択できます。 初期番号は、エンコードされたブロックとともに送信されるだけで、受信者は同じ手順を使用して、エンコード時に送信者が使用したソースブロックのリストを復元できます。
デコード手順はもう少し複雑ですが、非常に簡単です。
- エンコードされたブロックの作成に使用されたソースブロックのリストを復元します。
- このリストの各ソースブロックについて、既にデコードされている場合は、エンコードされたブロックでXOR操作を実行し、ソースブロックのリストから削除します。
- リストに少なくとも2つのソースブロックが残っている場合は、エンコードされたブロックを一時記憶領域に追加します。
- リストにソースブロックが1つだけ残っている場合、これは次のソースブロックが正常にデコードされたことを意味します! デコードされたファイルに追加して一時記憶リストを調べ、見つかったブロックを含むソースブロックに対してこの手順を繰り返す必要があります。
0x48 0x65 0x6C 0x6C 0x6F、ワールド!
すべてをよりよく理解するために、デコードの例を検討してください。 それぞれが1バイト長の5つのエンコードされたブロックを取得するとします。 また、各ソースブロックがどのソースブロックから構築されているかに関する情報も受信されました。 これらのデータは、グラフの形式で表示できます。
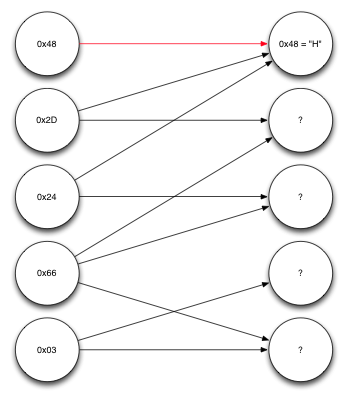
受信データを表すグラフ
左側のノードは、受信したエンコード済みブロックです。 右側のノードはソースブロックです。 最初に受信したブロックの最初の0x48は、最初の1つのソースブロックのみが参加して形成されました。 したがって、このブロックが何であるかはすでにわかっています。 最初のソースブロックを指す矢印に沿って反対方向に移動すると、2番目と3番目のエンコードブロックが最初のソースブロックのみに依存していることがわかります。 また、最初のソースブロックは既にわかっているため、受信したブロックと最初のソースブロックでXOR演算を実行し、さらにいくつかのブロックをデコードできます。
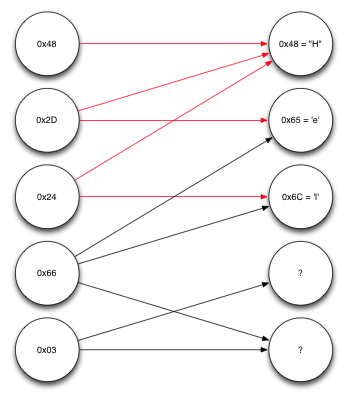
継続的なメッセージのデコード
同じ手順をもう一度繰り返しますが、2番目と3番目のソースブロックに依存する4番目のブロックをデコードするのに十分なことがわかりました。 それらに対してXOR演算を実行すると、次の図に示すように、5番目、つまりソースブロックリストの最後のブロックを見つけることができます。

デコードされた5番目のソースブロック
そして最後に、残りのソースブロックの最後をデコードできます。これにより、最終的に、送信者が受信者に送信したいメッセージを提供します。

完全にデコードされたメッセージ
確かに、これは人為的な例です。 ここでは、元のメッセージのデコードに必要なブロックのみが受信されるという仮定から進みます。 さらに、ブロックには余分なものはなく、ブロック自体は非常に便利な順序で配置されています。 しかし、これは噴水のコードの動作の原則のデモンストレーションにすぎません。 この例のおかげで、より大きなブロックとより長いファイルで同じ手順がどのように機能するかを理解できるはずです。
完全な配布について
前に、エンコードされた各ブロックを構成するソースブロックの数を選択する方法、またはコードシンボルの次数の分布は非常に重要であると言われていました。 そして、実際にはそうです。 理想的には、アルゴリズムは少数のエンコードされたブロックを生成する必要があり、その作成には1つのソースブロックのみが使用されます。 これは、受信者がメッセージのデコードを開始できるようにするために必要です。 ただし、ほとんどのエンコードされたブロックは、少数の他のブロックに依存する必要があります。 それは、ディストリビューションの正しい選択にかかっています。 私たちの目的に最適な同様の分布が存在します。 これは理想ソリトン分布と呼ばれます。
残念ながら、実際にはこの分布はそれほど理想的ではありません。 事実は、ランダムな変動により、ソースの一部のブロックが使用されないという事実、またはデコーダーが既知のブロックで終了するとデコードが停止するという事実につながります。 ロバストソリトン分布と呼ばれるこの分布のバリアントの1つでは、非常に少数のソースブロックからより多くのブロックを生成し、すべてまたはほとんどすべてのソースブロックの組み合わせであるブロックを生成することにより、アルゴリズムのパフォーマンスを改善できます。 これは、いくつかの最後のブロックのデコードを容易にするために行われます。
ここでは、要するに、ファウンテンコード、特にLTコードの仕組みです。 LTコードは、既知の噴水コードの中で最も効果が低いと言わなければなりませんが、理解するのが最も簡単です。
ピアツーピアネットワークと信頼の問題
この会話を終了する前に、別の考えを示します。 ファウンテンコードはBittorrentのようなシステムに理想的であり、SIDがほぼ無制限のブロック数を生成および配布できるようにし、シードがほとんどない場合の「最後のブロック」問題をほぼ排除し、ランダムに選択された2つのピアがほぼ常に有用な情報を持つようにします相互に交換できます。 ただし、重要な問題が1つあります。 実際には、ピアから受信したデータを検証することは非常に困難です。
ピアツーピアプロトコルはSHA1などの安全なハッシュ関数を使用しますが、配布の作成者である信頼できる側はすべてのピアに有効なハッシュのリストを提供します。 各データは、このデータを使用して、ダウンロードされたファイルの断片を確認できます。 ただし、噴水コードを使用する場合、このような作業スキームは複雑です。 たとえば、エンコードされたフラグメントのSHA1ハッシュを計算する方法はなく、その形成に関与した個々のフラグメントのハッシュを知っていることすらありません。 また、他のピアが単純に私たちを欺くことができるため、このハッシュを計算するために他のピアを信頼することはできません。 ファイル全体を収集するまで待つことができます。次に、無効なフラグメントのリストを使用して、正しくないエンコードされたフラグメントを見つけることができますが、これは困難で信頼性がありません。 さらに、このアプローチでは、エラーはファイルの最終ビルドでのみ見つけることができます。つまり、時間がかかりすぎる可能性があります。 可能な代替案の1つは、配布作成者が公開鍵を公開し、生成された各ブロックに署名することです。 したがって、エンコードされたブロックを確認できますが、深刻なマイナスがあります。 事実は、ディストリビューションの作成者のみが正しいブロックを生成できるということです。つまり、ファウンテンコードを使用する利点のほとんどをすぐに失うことになります。 ここで私たちは行き詰まっているようです。 ただし、たとえば、準同型ハッシュと呼ばれる非常に独創的なスキームなどの代替手段があります。 完璧ではありませんが。
おわりに
噴水コードの基本について話しました。 このアルゴリズムの多様性は、その利点が欠点を明白に上回る分野で実用的であることがわかりました。 このトピックに興味があり、さらに深く掘り下げたい場合は、噴水コードに関するこの資料をお読みください。 さらに、LTコードを少し複雑にして、効率を大幅に改善するRaptorコードをよく理解しておくと便利です。 それらの使用のおかげで、送信されるデータの量とアルゴリズムの計算の複雑さを減らすことができます。
ああ、仕事に来てくれませんか? :)wunderfund.ioは、 高頻度アルゴリズム取引を扱う若い財団です。 高頻度取引は、世界中の最高のプログラマーと数学者による継続的な競争です。 私たちに参加することで、あなたはこの魅力的な戦いの一部になります。
熱心な研究者やプログラマー向けに、興味深く複雑なデータ分析と低遅延の開発タスクを提供しています。 柔軟なスケジュールと官僚主義がないため、意思決定が迅速に行われ、実施されます。
チームに参加: wunderfund.io