定義1 。 同種のコンテナとは、まったく同じタイプのオブジェクトが格納されているコンテナです。
定義2 。 異種コンテナは、さまざまなタイプのオブジェクトを格納できるコンテナです。
定義3 。 静的コンテナは、その構成がコンパイル段階で完全に決定されるコンテナです。
この場合、 構成は要素の数とそのタイプとして理解されますが、これらの要素自体の値としては理解されません。 実際、コンパイル段階で要素の値さえも決定されるコンテナがありますが、このモデルではそのようなコンテナは考慮されません。
定義4 。 動的コンテナは、実行時に構成が部分的または完全に決定されるコンテナです。
この分類によると、明らかに4種類のコンテナがあります。
静的均質
例を挙げていただけますか?通常の配列は
int[n]
です。
静的不均一
例?このようなコンテナの最も顕著な例はタプルです。 C ++では、クラス
std::tuple<...>
によって実装されstd::tuple<...>
。
動的均質
推測?右、
std::vector<int>
。
動的な異種
このタイプのコンテナについては、この記事で説明します。
内容
動的な異種コンテナー
動的な異種コンテナを作成するには、いくつかの手法があります。 以下に、おそらく最も一般的な3つを示します。
多相クラスへのポインタの配列
選択肢
co病者経験豊富なオペシュニカ。
struct base { virtual ~base() = default; ... }; struct derived: base { ... }; std::vector<std::unique_ptr<base>> v;
結合の配列
Unionは、
union
言語機能、およびboost::variant
(std::variant
はC ++ 17に表示されます)のようなライブラリクラスとして理解できます。
タイプeraseを使用する任意のオブジェクトの配列
例えば、
boost::any
(C ++ 17では、std::any
が表示されます)に何でも入れることができます。
これらの手法にはそれぞれ長所と短所があり、それらを確実に検討します。
そして今、それが記事のタイトル(および本質)の一部であるという事実にもかかわらず、その瞬間まで影に残っていたポイントを強調する時です。
定義5 。 密集したコンテナとは、要素がメモリの連続領域にあり、それらの間にギャップがない(アライメントまで)コンテナです。
int[n]
、 std::vector<int>
、 std::tuple<...>
。
残念ながら、密集したすべてのコンテナが動的に異種であるとは限りません。 そして、それだけが必要です。
ただし、動的な異種コンテナーを取得するための上記の手法の長所と短所に戻ります。
多相クラスへのポインタの配列
利点:
実装の比較的容易さ
継承、ポリモーフィズム、すべてのもの。 これらのこと(残念ながら、または残念ですか?)初心者でも知っています。
新しいエンティティを簡単に導入
新しいオブジェクトを配列に挿入できるようにするために、追加の手順は必要ありません。 基本クラスの新しい子孫を作成するだけです。
また、ポインターの配列に応じてコードを再コンパイルする必要はありません。
短所:
階層依存
ある基本クラスから継承されたオブジェクトのみを配列に追加できます。
コードの冗長性
新しいメンバーごとに、階層に新しいクラスを作成する必要があります。 つまり、コンテナに2種類の数値(整数と浮力)を入れたい場合、基本クラスの「数値」とそれに対応する2つの相続人を取得する必要があります。
緩いパッキング
配列内にはポインタのみが存在し、オブジェクト自体はメモリ全体に分散しています。 これは、一般的な場合、キャッシュの処理に悪影響を及ぼします。
結合の配列
利点:
階層の独立
配列には、ユニオンで指定された任意の型を配置できます。
オブジェクトはメモリの連続した領域にあります。
配列に格納されるのはポインターではなく、オブジェクトそのものです。
短所:
ユニオンに含まれるオブジェクトのセットへの依存
新しいオブジェクトをユニオンに追加する場合、すべてのコードを再コンパイルする必要があります。これは、関連の配列に明確に依存します。
緩いパッキング
はい、オブジェクトは連続したメモリ領域にあります。 しかし、タイトなパッケージを取得したいので、このためにはオブジェクト間にボイドがないことが必要です。 そして、ボイドがあるかもしれません。
事実、ユニオンのサイズは、このユニオンの最大タイプのサイズと同じです。 たとえば、共用体に
sizeof(X) = 32
2つのタイプX
とchar
含まれる場合、それぞれのchar
は32バイトを占有しますが、1つで十分です。
タイプeraseを使用する任意のオブジェクトの配列
利点:
完全な独立
いつでも、どのようなタイプでもそのような配列に入れることができ、この配列に依存するものを再コンパイルする必要はありません。
短所:
緩いパッキング
ポインターの配列の場合のように、そのような配列のオブジェクトはメモリー全体に散らばっています(一般的なケースでは、小さなオブジェクトの最適化を使用できるためそうではありませんが、十分に大きなオブジェクトの場合、これは常に真です)。
動的タプル
そのため、上記のアプローチはいずれもタイトなパッケージングを必要としません。 したがって、動的な異種コンテナを作成するための別のアプローチを開発する必要があります。これは、とりわけ、望ましいタイトなパッケージングを提供します。
これを行うには、まず、より適切に対処するany
ます。 彼との仕事は次のようになります。
int main () { // . auto a = any(1); assert(any_cast<int>(a) == 1); // . any_cast<int>(a) = 42; assert(any_cast<int>(a) == 42); // . a = std::string(u8"!"); assert(any_cast<std::string>(a) == std::string(u8"!")); }
どのように機能しますか?
このコードを心に近づけないでください。これは回路図の実装です。 真の実装のためには、 より信頼できるソースに目を向けるべきです 。
#include <cassert> #include <utility> enum struct operation_t { clone, destroy }; using manager_t = void (*) (operation_t, const void *, void *&); // `any` , // . template <typename T> void manage (operation_t todo, const void * source, void *& destination) { switch (todo) { case operation_t::clone: { destination = new T(*static_cast<const T *>(source)); break; } case operation_t::destroy: { assert(source == nullptr); static_cast<T *>(destination)->~T(); break; } } } class any { public: any (): m_data(nullptr), m_manager(nullptr) { } any (const any & that): m_manager(that.m_manager) { m_manager(operation_t::clone, that.m_data, this->m_data); } any & operator = (const any & that) { any(that).swap(*this); return *this; } any (any && that): m_data(that.m_data), m_manager(that.m_manager) { that.m_manager = nullptr; } any & operator = (any && that) { any(std::move(that)).swap(*this); return *this; } ~any () { clear(); } // "" . // "", // . , , // , "" : . template <typename T> any (T object): m_data(new T(std::move(object))), m_manager(&manage<T>) { } template <typename T> any & operator = (T && object) { any(std::forward<T>(object)).swap(*this); return *this; } template <typename T> friend const T & any_cast (const any & a); template <typename T> friend T & any_cast (any & a); void clear () { if (not empty()) { m_manager(operation_t::destroy, nullptr, m_data); m_manager = nullptr; } } void swap (any & that) { std::swap(this->m_data, that.m_data); std::swap(this->m_manager, that.m_manager); } bool empty () const { return m_manager == nullptr; } private: void * m_data; manager_t m_manager; }; // , , . // : // // `any_cast<int>(a) = 4;` // template <typename T> const T & any_cast (const any & a) { return *static_cast<const T *>(a.m_data); } template <typename T> T & any_cast (any & a) { return *static_cast<T *>(a.m_data); }
既に理解したように、 動的タプル (DK)はany
を使用したアイデアの開発になりany
。 すなわち:
-
any
の場合と同様に、タイプ消去技術が適用されます。オブジェクトのタイプは「忘れられ」、各オブジェクトに「マネージャー」が設定され、このオブジェクトの操作方法がわかります。 - オブジェクト自体は、連続したメモリ領域に(整列を考慮して)次々に積み重ねられます。
any
方法と同様に機能しany
。
// . auto t = dynamic_tuple(42, true, 'q'); // . assert(t.size() == 3); // . assert(t.get<int>(0) == 42); ... // . t.push_back(3.14); t.push_back(std::string("qwe")); ... // . t.get<int>(0) = 17;
もっとコードが必要
それでは、 楽しい部分に取り掛かりましょう 。
データ保存
密なパッキングの定義からわかるように、すべてのオブジェクトは単一の連続したメモリに格納されます。 これは、ハンドラーに加えて、各メモリーについて、このメモリーの先頭からインデントを保管する必要があることを意味します。
素晴らしい、これのための特別な構造を取得しましょう:
struct object_info_t { std::size_t offset; manager_t manage; };
次に、メモリ自体とそのサイズを保存する必要があります。また、オブジェクトが占有する合計量を個別に記憶する必要があります。
取得するもの:
class dynamic_tuple { private: using object_info_container_type = std::vector<object_info_t>; ... std::size_t m_capacity = 0; std::unique_ptr<std::int8_t[]> m_data; object_info_container_type m_objects; std::size_t m_volume = 0; };
ハンドラー
これまでのところ、 manager_t
ハンドラータイプは未定義のままです。
主に2つのオプションがあります。
「メソッド」を含む構造
any
からすでにわかっているany
に、オブジェクトを制御するにはいくつかの操作が必要です。 レクリエーションセンターの場合、これは少なくともコピー、転送、破壊です。 それぞれについて、構造内にフィールドを作成する必要があります。
struct manager_t { using copier_type = void (*) (const void *, void *); using mover_type = void (*) (void *, void *); using destroyer_type = void (*) (void *); copier_type copy; mover_type move; destroyer_type destroy; };
汎用ハンドラーへのポインター
汎用ハンドラーへのポインターは1つのみ保存できます。 この場合、必要な操作の選択を担当する列挙を作成するとともに、オブジェクトで可能なすべてのアクションの単一タイプの署名を作成する必要があります。
enum struct operation_t { copy, move, destroy }; using manager_t = void (*) (operation_t, const void *, void *);
最初のオプションの欠点は、アクションごとに新しいフィールドの導入が必要なことです。 したがって、新しいハンドラーが追加されると、ハンドラーが占有するメモリが肥大化します。
2番目のオプションの欠点は、異なるハンドラーの署名が異なるため、すべてのハンドラーを単一の署名に合わせる必要がありますが、要求された操作によっては、一部の引数が不要なままになる場合があり、場合によってはconst_cast
を呼び出す必要さえあります。
実際、3番目のオプションがあります:ポリモーフィッククラスハンドラー。 しかし、このオプションは最も抑制されているため容赦なく一掃されます。
したがって、オプションの1つの短所は、他のオプションの利点です。
長所と短所を十分に検討し、検討した結果、最初のオプションの短所を上回り、選択はより小さな悪、つまり一般化されたハンドラーに置かれます。
template <typename T> void copy (const void *, void *); // . " ". template <typename T> void move (void * source, void * destination) { new (destination) T(std::move(*static_cast<T *>(source))); } template <typename T> void destroy (void * object) { static_cast<T *>(object)->~T(); } template <typename T> void manage (operation_t todo, const void * source, void * destination) { switch (todo) { case operation_t::copy: { copy<T>(source, destination); break; } case operation_t::move: { move<T>(const_cast<void *>(source), destination); break; } case operation_t::destroy: { assert(source == nullptr); destroy<T>(destination); break; } } }
データアクセス
DCについて言える最も単純なこと。
要求されたデータのタイプはコンパイル段階で知られ、インデックスは実行段階で知られているため、オブジェクトにアクセスするためのインターフェースはそれ自身を示唆しています:
template <typename T> T & get (size_type index) { return *static_cast<T *>(static_cast<void *>(data() + offset_of(index))); } size_type offset_of (size_type index) const { return m_objects[index].offset; }
また、効率を高めるために(記事の最後にあるアクセスパフォーマンスのグラフを参照)、インデントによってオブジェクトへのアクセスを判断できます。
template <typename T> const T & get_by_offset (size_type offset) const { return *static_cast<const T *>(static_cast<const void *>(data() + offset)); }
さて、標準コンテナとの類推によるインジケータ:
size_type size () const { return m_objects.size(); } std::size_t capacity () const { return m_capacity; } bool empty () const { return m_objects.empty(); }
個別に言う必要があるのは、コンテナの容積を報告する特別なインジケータだけです。
ボリュームとは、レクリエーションセンターにあるオブジェクトが占有するメモリの総量を意味します。
std::size_t volume () const { return m_volume; }
ライフタイムおよび例外セキュリティ
最も重要なタスクは、オブジェクトの寿命を監視し、例外の安全性を確保することです。
オブジェクトは、配置new
を使用して「手動で」構築されるため、デストラクタへの明示的な呼び出しによって、もちろん「手動で」破棄されます。
これにより、再割り当て中にオブジェクトをコピーおよび転送する際に特定の問題が発生します。 したがって、コピーと転送のために比較的複雑な構造を実装する必要があります。
template <typename ForwardIterator> void move (ForwardIterator first, ForwardIterator last, std::int8_t * source, std::int8_t * destination) { for (auto current = first; current != last; ++current) { try { // . current->manage(operation_t::move, source + current->offset, destination + current->offset); } catch (...) { // , , . destroy(first, current, destination); throw; } } destroy(first, last, source); } template <typename ForwardIterator> void copy (ForwardIterator first, ForwardIterator last, const std::int8_t * source, std::int8_t * destination) { for (auto current = first; current != last; ++current) { try { // . current->manage(operation_t::copy, source + current->offset, destination + current->offset); } catch (...) { // - , , . destroy(first, current, destination); throw; } } }
その他の問題
最大の問題の1つはコピーでした。 そして、私はそれを理解しましたが、疑念はまだ定期的に発生します。
説明します。
コピーできないオブジェクト(たとえばstd::unique_ptr
)をstd::vector
ます。 これは転勤を通じて行うことができます。 しかし、ベクターをコピーしようとすると、コンパイラーはその内部要素がコピーできないため、誓います。
DCの場合、すべてが多少異なります。
- アイテムをレクリエーションセンターに置くときに、コピーハンドラーを作成する必要があります。 オブジェクトがコピーされない場合、ハンドラーを作成できません(コンパイルエラー)。 さらに、DCを一般的にコピーするかどうかはまだ不明です。
- レクリエーションセンターの実際のコピーの時点では、タイプの消去によるタイプのコピー可能性に関する情報は利用できなくなりました。
現在、次のソリューションが選択されています。
- オブジェクトがコピーされると、通常のコピーハンドラーが作成されます。
- オブジェクトがコピーされない場合、特別なハンドラーが作成され、コピーしようとすると例外がスローされます。
template <typename T> auto copy (const void * source, void * destination) -> std::enable_if_t < std::is_copy_constructible<T>::value > { new (destination) T(*static_cast<const T *>(source)); } template <typename T> auto copy (const void *, void *) -> std::enable_if_t < not std::is_copy_constructible<T>::value > { auto type_name = boost::typeindex::ctti_type_index::type_id<T>().pretty_name(); throw std::runtime_error(u8" " + type_name + u8" "); }
2つのDCが等しいかどうかを比較すると、さらに複雑な問題が発生します。 同じように行うこともできますが、比較できないものを比較しようとする場合のコンパイラエラーの場合に加えて、コンパイラがエラーを生成せず、警告を生成する場合もあります(たとえば、浮動小数点数の等値演算子を呼び出す場合)。 ここでは、一方で、ユーザーは自分のアクションを認識し、意図的に比較を行うことができるため、例外をスローすることはできません。 一方、安全でない操作についてユーザーに何らかの形で通知したいと思います。
この問題は未解決です。
パフォーマンス測定
主な目標は、要素への最適なアクセス時間を得るために密集したコンテナを作成することであったため、レクリエーションセンターでのパフォーマンス測定では、メモリから「散乱」したオブジェクトへのポインタの配列に対するアクセス速度を比較しました。
2つの散布パターンが使用されました。
スパースネス
N
測定された配列のサイズ、S
散乱指数とします。
次に、サイズN * S
のポインターの配列N * S
生成され、番号N * i
、i = 0, 1, 2, ...
要素のみが残るように間引きされます。
混乱
N
測定された配列のサイズ、S
散乱指数とします。
次に、サイズN * S
配列N * S
生成され、ランダムに混合されます。その後、最初のN
要素が選択され、残りは捨てられます。
また、アクセス時間の基準点としてstd::vector
が使用されました。

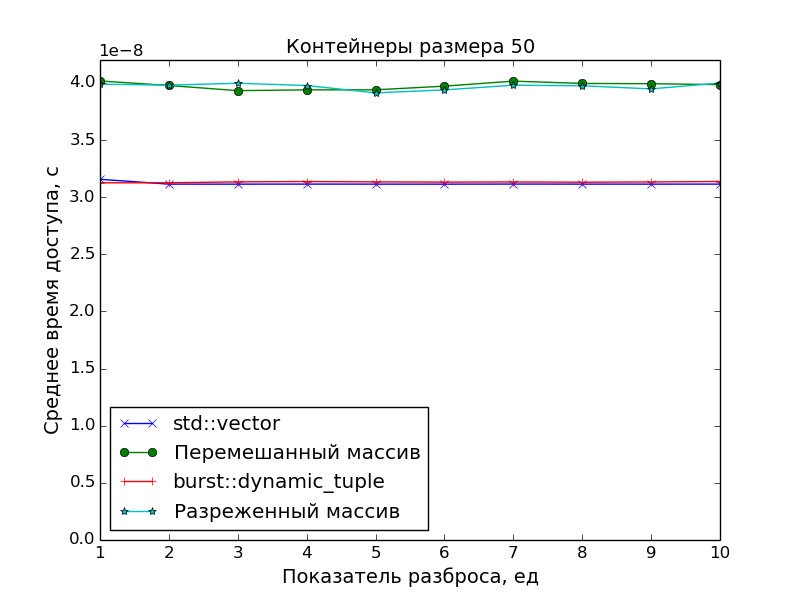
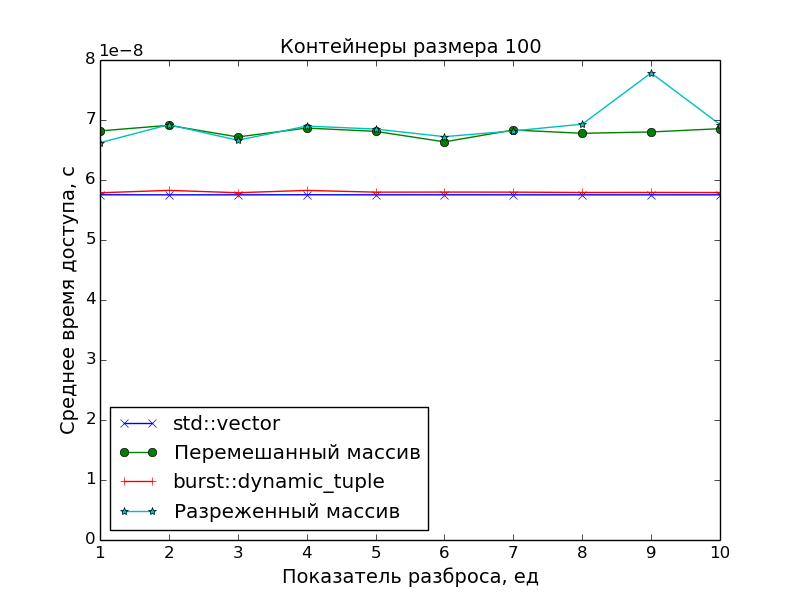
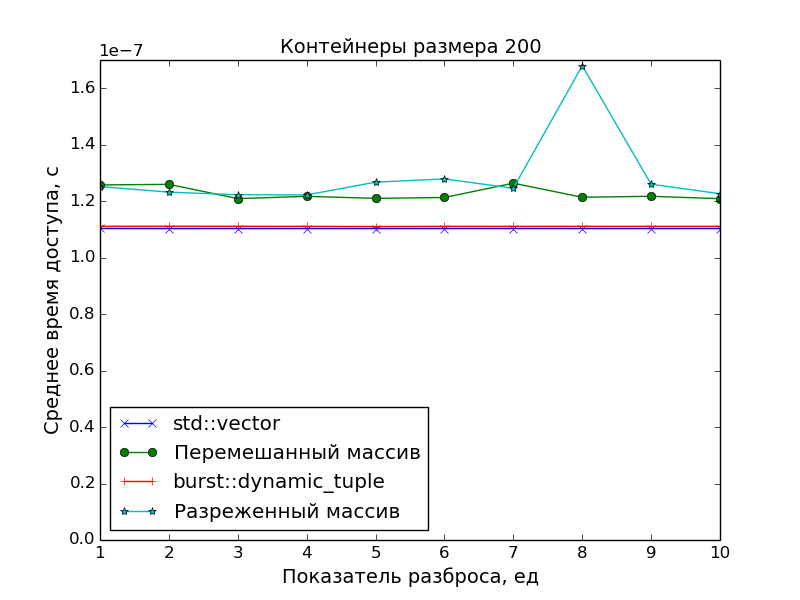
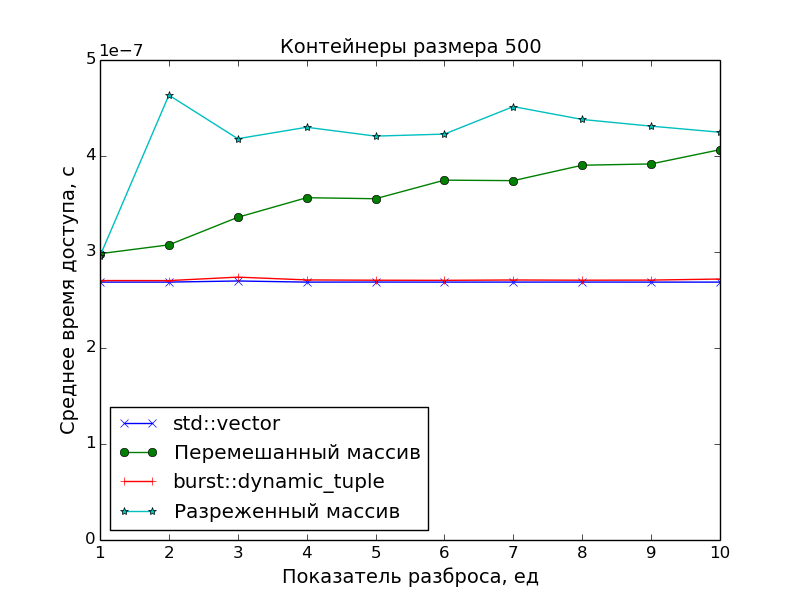
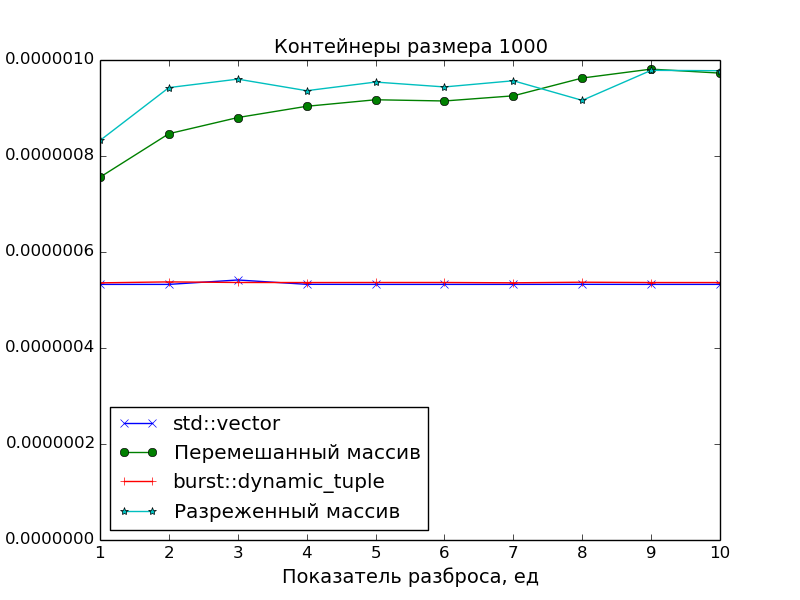
グラフから明らかなことが確認できます。
- DCの要素へのアクセス速度は、
std::vector
クラスの要素へのアクセス速度と同じです(1つのポインターの追加と1つの逆参照)。 - ポインターの配列の要素へのアクセスが遅くなります。 これは、データがキャッシュに収まらなくなった場合に、スプレッドインデックスが
S > 1
大きなアレイで特に顕著です。
すべてのソースコードはgithubで入手できます。