私は、インセプションアーキテクチャの生活について話し続けています。これは、Googleのconvnetアーキテクチャです。
(最初の部分- ここ )
そのため、1年が経過すると、男性はGoogLeNet以降の開発の成功を発表します。
最終的なネットワークがどのように見えるかの恐ろしい画像を次に示します。
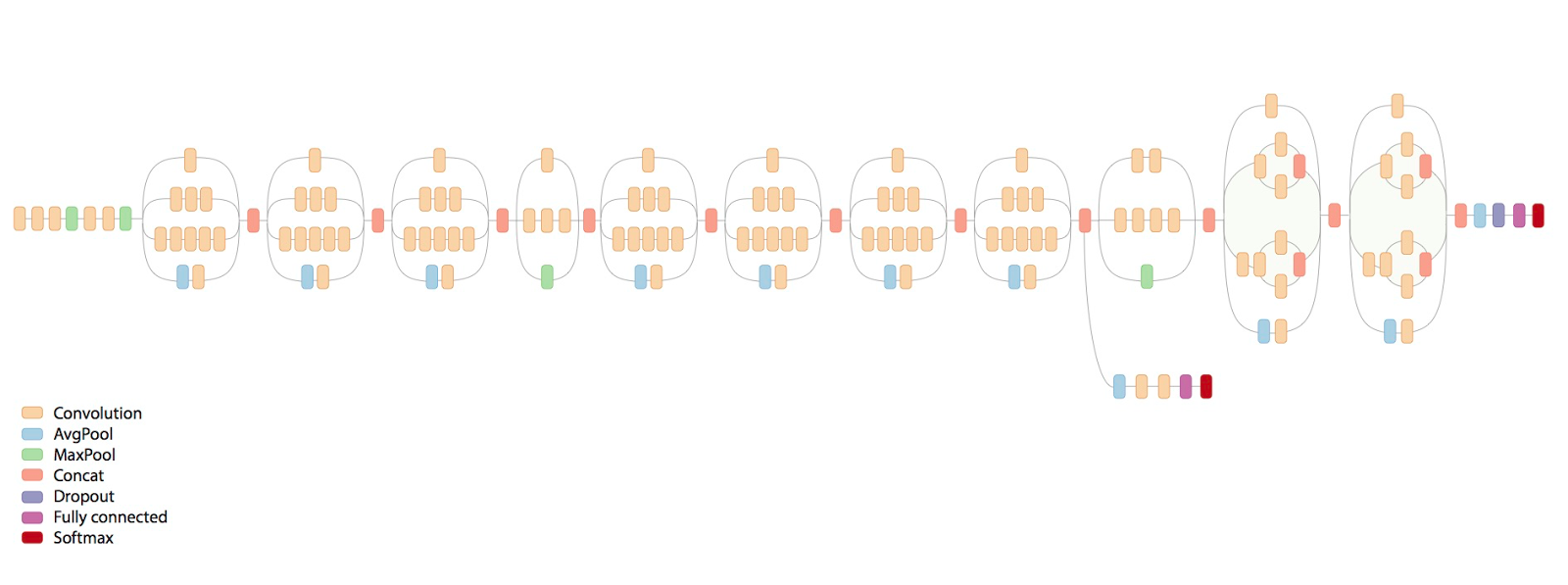
そこでどんな恐怖が起こっているのでしょうか?
免責事項:投稿はclosedcircles.comの編集されたチャットログに基づいて書かれているため、プレゼンテーションスタイルと明確な質問です。
今回、著者は、効率的なネットワークのアーキテクチャを構築するためのいくつかの基本原則を策定しようとしています(実際の記事はhttp://arxiv.org/abs/1512.00567です )。
(Inceptionアーキテクチャの目的は、私たちが大好きな実際のアプリケーションの計算とパラメーターの数で主に効果的であることを思い出します)
彼らは次のように原則を定式化します:
- 多くの信号は、空間(つまり、隣接する「ピクセル」)で互いに近接しており、これを使用してより小さい畳み込みを行うことができます。
同様に、近隣の信号はしばしば相関しているため、情報を失うことなく畳み込みの前に次元を減らすことができます。 - リソースを効率的に使用するには、ネットワークの幅と深さの両方を増やす必要があります。 つまり たとえば、リソースが2倍になった場合、レイヤーを広くし、ネットワークを深くすることが最も効果的です。 さらに深く行うだけでは効果がありません。
- 特に最初の段階で、急激なボトルネック、つまりパラメーターが急激に減少するレールがあるのは悪いことです。
- 「幅の広い」層はより高速に学習します。これは、高レベルでは特に重要です(ただし、局所的に、つまり、次元を小さくすることはかなり可能です)
ネットワークビルディングブリックの以前のバージョンは次のようになりました。
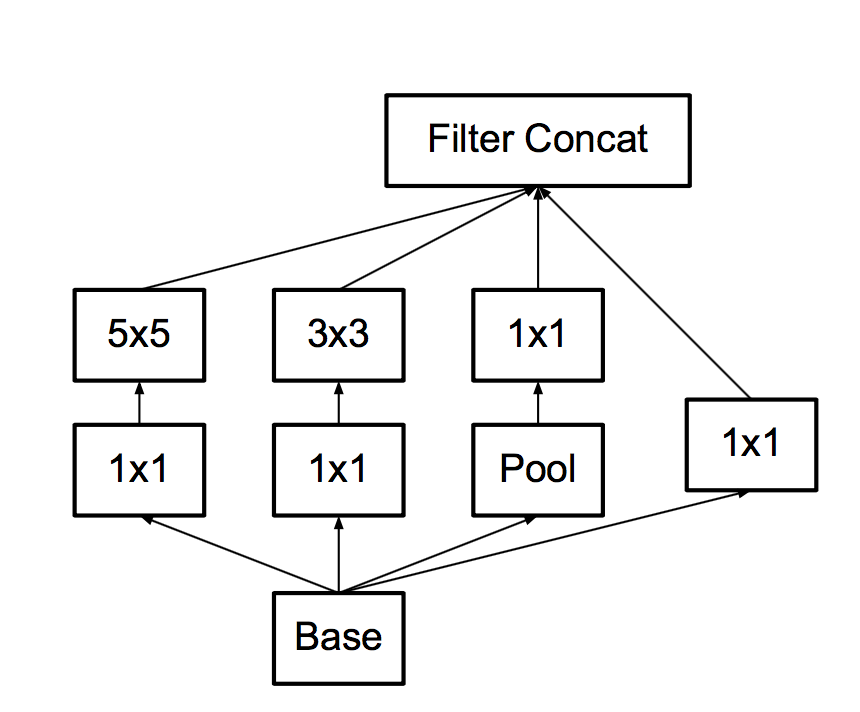
彼らはどのような修正を行いますか
最初に 、大きく太い5x5畳み込みをそれぞれ2つの連続した3x3に置き換えることができることに気付きます。信号は相関しているため、少し失われると言われています。 これらの3x3の非直線性の間で実行する方が、実行しないよりも優れていることが実験的に判明しています。
- 第二に、そのような酒なので、3x3を3x1 + 1x3に置き換えましょう。
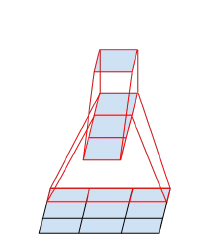
ここで、畳み込みを行うと安価になり、3x1 + 1x3ではなく、すぐにnx1 + 1xnを行う理由がわかります。
そして、グリッドの開始時ではないが、すでに7時になっています。 これらすべてのアップグレードにより、メインブリックは次のようになります。
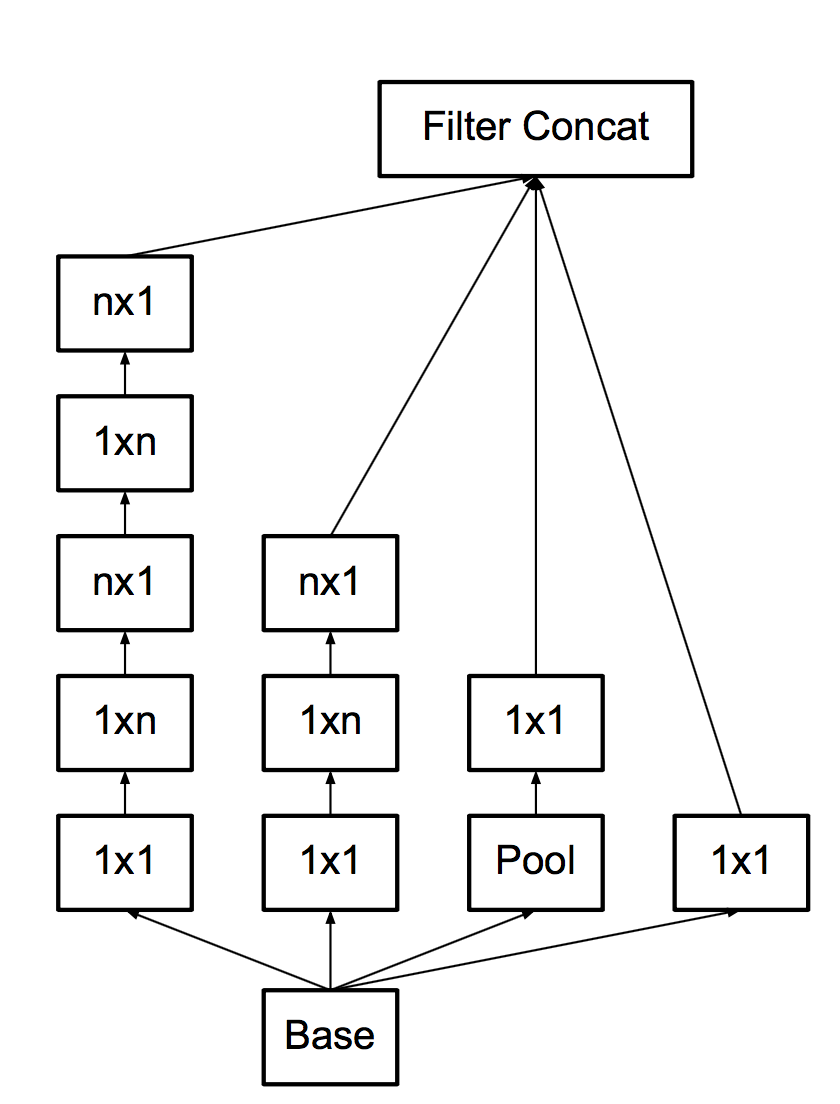
- 第三に 、「ボトネコフを作成しない」契約に続いて、彼らはプーリングについて考えます。
プーリングのなんと問題なのか...次に、プールでイメージを半分に減らし、プール後のフィーチャの数を2倍にします。
プールを作成してから、より低い解像度で畳み込みを行うか、最初に畳み込みをしてからプールを作成できます。
写真のオプションは次のとおりです。

問題は、最初のオプションはアクティベーションの数を大幅に削減することであり、2番目はフル解像度で畳み込みを行う必要があるため、計算の観点からは効率が悪いことです。
したがって、ハイブリッドスキームを提供します。機能プールを半分に、畳み込みを半分にしましょう。
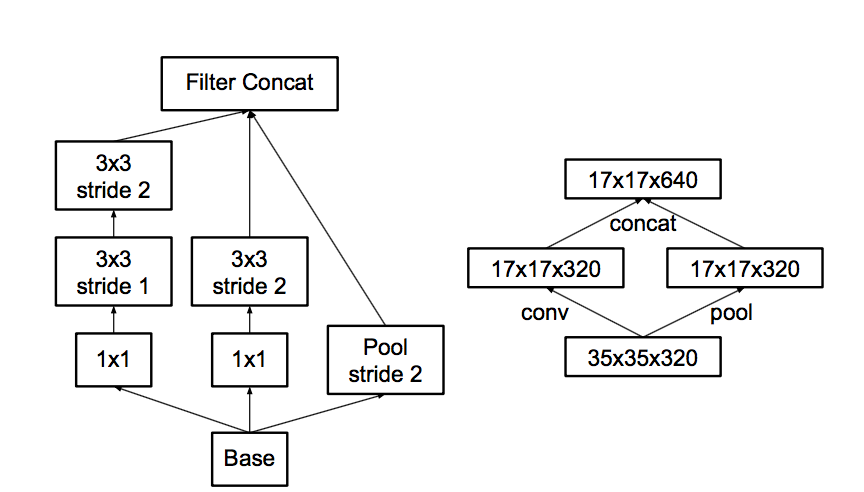
また、プールの後、機能の数は通常2倍になるため、ボトネクは発生しません。 プールは、機能の数を減らすことなく前のプールを圧縮します。一部の畳み込みは最大解像度で駆動されますが、機能は少なくなります。 ネットワークは共有を学習しますが、これには完全な解像度が必要であり、プールには十分です。
- 最後に 、彼らは最後のレールのためにレンガを少し修正し、より深くはありませんが幅を広げます。 桟橋の学習を改善するには、ネットワークの最後でこれが最も重要です。
そして今、ネットワークはいくつかの初期の畳み込みであり、これらはプールによって散在するレンガです。 合計ネットワーク11インセプションレイヤー。
したがって、最初の図の恐怖。
また、側面の追加分類子はトレーニングを大幅に加速するのではなく、正規化子として機能するため、むしろ役立ちます。バッチ正規化を接続すると、ネットワークの予測が向上します。
他に何...
追加の正則化のための別のトリック、いわゆるラベルスムージングを提供します。
簡単に言うと、これは次のとおりです。通常、特定のサンプルのターゲットラベルは、クラスが正しい場合は1、クラスが正しくない場合は0です。
これは、ネットワークがすでにクラスの正確性に非常に自信がある場合、勾配がプッシュされてこの信頼性が増加および増加することを意味します。
彼らは、他のクラスがゼロではなく、いくつかの小さな値を持つように、1回限りのターゲットと、データセットに従ってクラスを比例的に愚かに分布する分布とを混合することを提案しています。 これにより、別の百分位数のchtoli、つまり多くの勝ちが可能になります。
合計
そして、これらすべての機械はInception-v1の2.5倍のコンピューティングリソースを消費し、大幅に優れた結果を達成します。
これらはメインアーキテクチャInception-v2を呼び出し、追加の分類子がBNで機能するバージョンはInception-v3です。
このInception-v3は、Imagenetでトップ5の分類エラー4.2%に達し、4つのモデルのアンサンブルは3.58%です。
そしてこれにより、Googleの男性は2015年にImagenetを獲得しようとしていました。
しかし、ResNetsが発生し、Microsoft Research Asiaのパートナーが結果でKaiming Heを獲得しました... 3.57%!!!
(オブジェクトのローカライズでは、結果が根本的に優れていることに注意してください)
ただし、ResNetsについては別の機会に話します。
興味深い平均ホモサピエンスは、これらの写真にどのようなエラーが表示されます。
広く議論された唯一の実験は、アンドレイ「私たち全員」カルパシーによって行われました。
http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/
彼はデータセットのある部分でテストを行った結果、5.1%でした。
これもtop5ですが、人がtop5を選択するのは難しいかもしれません。
ところで、あなたは自分自身をチェックすることができます-http://cs.stanford.edu/people/karpathy/ilsvrc/
そしてそれは本当に複雑です。 彼らは、地中海のフィンチと占いのいくつかの亜種を紹介します。