
/ 写真:Jason Tester Guerrilla Futures CC
IDC は 、2011年に人類が1.8ゼタバイトの情報を生成したと報告しています。 2012年には、この数値はすでに2.8ゼタバイトでしたが、2020年には40ゼタバイトに増加します。
このデータの大部分は、Google、Facebook、Appleなどのグローバル企業によって生成されています。 データを保存するだけでなく、バックアップ、関連性の監視、処理、最小限のコストでの実行も必要です。 したがって、大規模な組織のIT部門は、これらの問題を解決するために独自のシステムを開発しています。
Ars Technicaの編集者であるSean Gallagher氏によると 、Googleは乳房ストアの規模拡大の問題に対処した最初のWebプレーヤーの1つでした。 同社は、2003年に分散ファイルシステムであるGoogle File System(GFS)を開発することで、この質問に対する答えを見つけました。
Google の研究者Sanjay Ghemawatと上級エンジニアのHoward GobioffとShun-Tak Leungによると、GFSは特定の機能で開発されています。 その目標は、多数の安価なサーバーとハードドライブを、多くのアプリケーションが同時にアクセスできる数百テラバイトのデータの信頼できるストレージに変えることです。
GSFは、Googleのほぼすべてのクラウドサービスの基盤です。 Googleは、数百台のマシンが同時に情報を追加する巨大なファイルにアプリケーションデータを保存します。 さらに、ファイルへの書き込みは、そのファイルで作業が行われている瞬間に行うことができます。
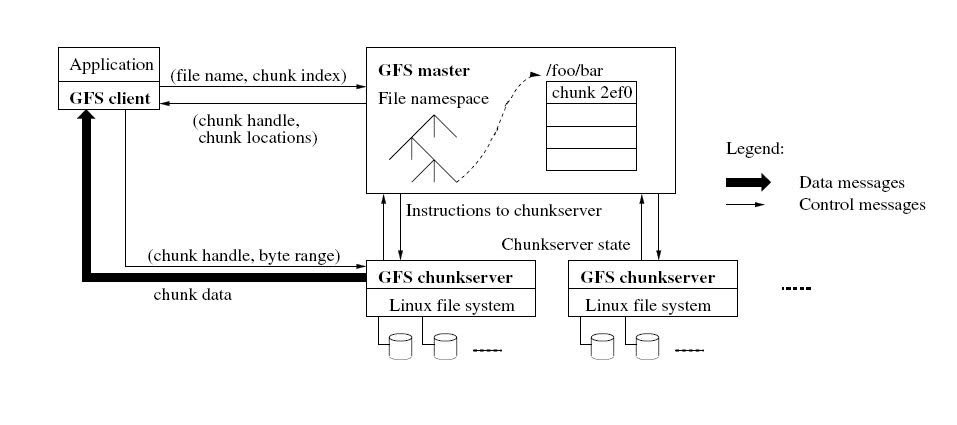
/ Googleファイルシステム
システムには 、データを保存するマスターサーバーとフラグメントサーバー(チャンクサーバー)が含まれています。 通常、GFSクラスターは、1つのメインマスターマシンと複数のフラグメントサーバーで構成されます。 GFSのファイルは、フラグメントサーバーがLinuxファイルとしてローカルハードドライブに保存する、固定されたカスタムサイズの断片に分割されます(ただし、信頼性を高めるために、各フラグメントはさらに他のサーバーに複製されます)。
ウィザードについては、メタデータの操作を担当し、システムのすべてのグローバルアクティビティ(フラグメントの管理、ガベージコレクション、サーバー間でのフラグメントの移動など)を制御します。
このようなシステムの主な問題の1つは、多数の安価な機器に基づいて構築されているため、コンポーネントの頻繁な誤動作です。 障害は、システム要素へのアクセス不能と、破損したデータの存在の両方によって引き起こされる可能性があります。 しかし、Googleはこれに対応していたため、GFSは常にコンポーネントを監視し、いずれかのコンポーネントに障害が発生した場合、システムのパフォーマンスを維持するために必要な措置を講じます。
破損したフラグメントは、チェックサムを計算して決定されます。 各ピースは、32ビットのチェックサムで64 KBのブロックに分割されます。 他のメタデータと同様に、これらの量はメモリに保存され、ユーザーデータとは別に定期的に記録されます。
GFSが存在する間、Googleプラットフォームは新しい要件を開発して適応し、検索エンジンには新しいサービスがあります。 GFSのクラスターサイズは、すべてのデータタイプの効率的なストレージに適さないことが判明しました。 2010年までに、同社の研究者はGFSの長所と短所を研究し、取得した知識を適用して新しいソフトウェアシステムを作成しました。
そこで、Colossus分散ファイルシステム(GFS2)、Spanner(BigTable開発)-データバージョン管理をサポートするスケーラブルな地理分散ストレージ、スケーラブルなクエリ処理システムDremel、Caffeine-GFS2、反復MapReduce、次世代BigTableを使用したGoogle検索サービスインフラストラクチャが誕生しました今日、彼らはより複雑な問題を解決し、より多くの情報を処理し、新しい可能性を開いています。

/ photo Atomic Taco CC
ただし、Googleだけが大量のデータと「戦っている」わけではありません。 Uber は、データストレージとレプリケーションへの異常なアプローチを発見しました 。 データセンター間でデータベースを常に同期する代わりに、自動車サービスの専門家は、ドライバーの電話から外部分散システムを編成することを決定しました。
同社は、このソリューションの主な目標はフォールトトレランスを向上させることだと指摘しています。 このアプローチは、データセンターの障害からデータを確実に保護します。 従来の複製戦略を使用した場合、ネットワーク管理システムの性質により、旅行情報の保存を保証することは困難でした。
データセンターの障害に対する通常の解決策は、アクティブなデータセンターからバックアップにデータを転送することですが、データセンターが3つ以上ある場合、インフラストラクチャの複雑さが急激に増加し、データセンター間のレプリケーションに遅延が発生し、高い接続速度が必要になります。
Uberの場合、データセンターでエラーが発生した場合、旅行情報は常にドライバーのモバイルデバイスに保存されます。 スマートフォンには最新のデータがあるため、そこから実際の情報がデータセンターに送られ、その逆はありません。
ドライバーの携帯電話は4秒ごとにデータを送信します。 「このため、Uberは毎秒数百万の書き込み操作を処理するタスクに直面していました」とUberシステムアーキテクチャのチーフアーキテクトであるMatt Ranneyがプラットフォームスケーリングに関するプレゼンテーションで述べました。
全体のプロセスは次のとおりです。 ドライバーは、たとえば、乗客を迎えるときにステータスを更新し、リクエストをディスパッチサービスに送信します。 後者は旅行モデルを更新し、複製サービスに通知します。 レプリケーションが完了すると、ディスパッチャはデータストアを更新し、モバイルクライアントに操作が正常に完了したことを通知します。
同時に、レプリケーションサービスは情報をエンコードし、ドライバーとの双方向通信チャネルをサポートするメッセージングサービスに転送します。 このチャネルは元のクエリチャネルとはまったく接続されていないため、データ回復プロセスはビジネスプロセスに影響しません。 次に、メッセージングサービスはバックアップを電話に送信します。
「Uberデジタルプラットフォームは、膨大な量のデータを集約します」とConvergent Technology AdvisorsのTyler James Johnson氏は述べています。 -マップ、ルート、顧客の嗜好情報、通信は、Uberリポジトリのコンテンツのほんの一部です。 同社はデジタル技術の開発に多くの投資をしています。 データはすべての基盤です。」
このデータは、将来会社にとって役立つため、保持することが重要です。 自動操縦車の出現はすぐ近くです。 ガートナーは、世界の5台に1台の車が2020年までにワイヤレス接続を確立し、2番目に2億5千万台の接続された車両になると予測しています。
これまでのところ、Googleはこの市場のリーダーであり続けていますが、テクノロジーの巨人であるテスラ、フォードと並行して、Appleは同様のシステムに取り組んでいます。 Uberはそれほど遅れていません。 同社には、ピッツバーグのカーネギーメロン大学と連携して機能する先進技術開発センターがあります。 提供するサービスの品質を改善し、コストを削減するのに役立つスマートカーやその他の技術を開発します。
「作成および消費されるデジタルコンテンツの量が増えると、より洗練された新しい情報システムを作成することが必要になります」 とガートナーのリサーチディレクター、ジェームスハインズは述べています。 「同時に、これらのテクノロジーを自動圏に適用すると、新しいビジネスモデルが出現し、都市環境での自動車の所有権へのアプローチが可能になります。」
PS仮想インフラストラクチャ1cloudを提供するためのサービスに取り組んでいる私たち自身の経験だけでなく、Habréのブログで知識の関連分野についても話しています。 更新、友人を購読することを忘れないでください!