興味深い競合問題を解決する試みのこの説明の最初の部分で 、分析用のデータの準備といくつかの実験について話しました。 問題の条件は、辞書の単語の存在を判断することであり、プログラムの実行時にこの辞書にアクセスできず、プログラムのボリューム(データを含む)が64Kに制限されていることを思い出してください。
前回と同様に、猫の下には多くのSQL、JS、ニューラルネットワーク、ブルームフィルターがあります。
説明した最後の実験は、決定木を構築することで問題を解決する試みであったことを思い出させてください。 テストされた次のテクノロジは、Microsoft Data Miningパッケージに含まれる関係検索アルゴリズムです。 これが彼の仕事の結果です。
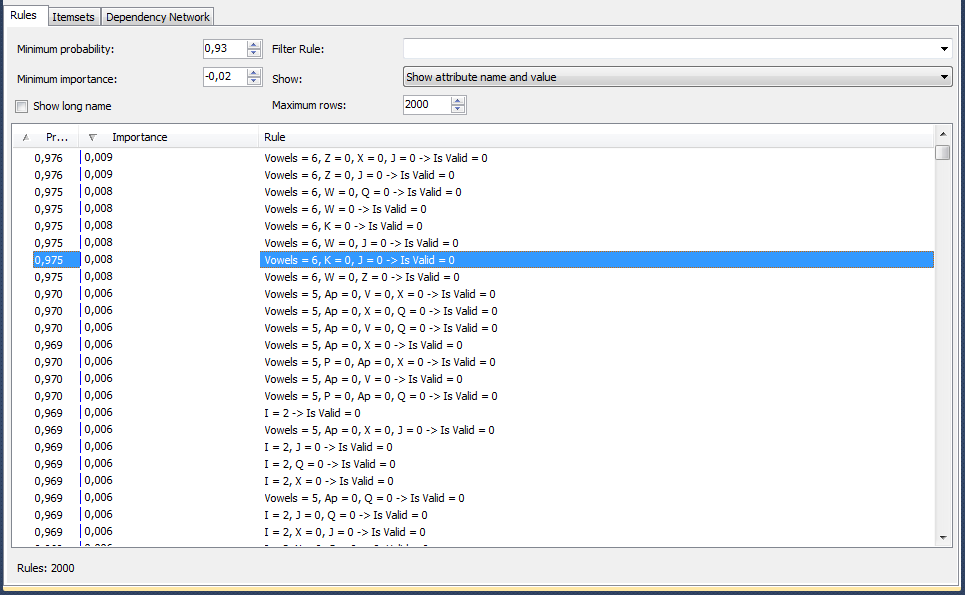
写真は、アルゴリズムが彼の意見では、単語に6つの母音があり、文字「Z」、「X」、「J」が欠落している場合、97.5%の確率で単語が辞書にないことを示していることを示しています すべてのルールをカバーするテストデータの量を確認します-ほとんどのことが判明しました。 結果に満足しています。ルールを守り、DataGripからWebStormに切り替えて、JSコードを記述します。
確認コードは次のようになります。
var wordStat=getWordStat(word); var wrongRules=0; var trueRules=0; function getWordStat (word) { // var result={vowels:0,consonants:0}; for (var i=0;i<word.length;i++) { result[word[i]]=result[word[i]]?(result[word[i]]+1):1; if ('aeiouy'.indexOf(word[i])>-1)result.vowels++; else if (word[i]!="'")result.consonants++; } return result; } for (i=0;i<rules.length;i++) { var passed=0; var rulesCount=0; for (var rule in rules[i]){ rulesCount++; if((wordStat[rule.toLowerCase()]?wordStat[rule.toLowerCase()]:0)==rules[i][rule])passed++; } if (passed==rulesCount&&rulesCount!=0) { return false; } }
データのパッケージ化についてはまだ考えていません。json型のExcelを作成しています
var rules= [ {"Consonants":6,"H":0,"X":0,"J":0}, {"Consonants":6,"H":0,"V":0,"Q":0} ]
もう一つの「真実の瞬間」...そしてもう一つの失望-65%。 話していない97.5%について。
ルールによってどれだけのデータがどのように削除されるかを確認します。多くの偽陰性および偽陽性の応答が返されます。 私は2つの主な「パンク」が何であるかを理解し始めています。 単語の繰り返しと配列の割合を考慮しませんでした。 すなわち:
1)最初に、テスト単語の検証の確率がテストセットの確率と一致することを提案しました。 しかし、テストセット内の単語は繰り返され、これらの単語を間違えた場合、これらの繰り返しにより状況が大幅に低下します。 ところで、アイデアはすぐにすべての繰り返された単語を正しいと見なすように見えます。
2)マイニングアルゴリズムはすべて正しく実行されました。100万の不正な単語ごとに10,000の正しい単語が表示され、99%の確率で満足でした。 私は、間違った大量の正しい言葉と間違った言葉をアルゴリズムに送り込むことで間違っていました。 たとえば、上記のルールを確認してください{"子音":6、 "H":0、 "X":0、 "J":0}:
select isvalid,count(*) from formining10 where Vowels=6 and Z=0 and X=0 and J=0 group by isvalid
| isValid | 数える |
|---|---|
| 0 | 5117424 |
| 1 | 44319 |
実際、差は100倍以上であり、アルゴリズムはそれを正しく認識しました。 しかし、44Kの正しい単語を無視することはできません。 比率をチェックすると、ほぼ等しくなります。 そのため、正しい単語と間違った単語の同じサイズの配列を供給する必要があります。 しかし、結局のところ、600Kの誤った単語はほとんどないでしょう...私は他の10Mのテスト単語を繰り返しますが、繰り返します。 正または負の重複を削除せずに。 私が最初に行うことは、最初の記事で説明したフィルター(存在しないペア/トリプル)を通じて「ゴミ」を削除することです。 私は鉱業に餌をやる...悲しいかな、彼はこの状況で適切なルールを見つけられず、決定木を構築しようとすると、彼は良いものを見つけられなかったと言います。 間違ったペア/トリプルを介してマイニングにデータを供給する前であっても、すべての「明らかな」間違ったオプションをカットすることを思い出させてください。
「説明的な」方法に戻ります。
マイニングの記事の最初の部分では、辞書に基づいて、行が単語に対応し、列が単語内の文字の番号に対応し、セルの値がアルファベットの文字のシリアル番号(アポストロフィの場合は27)であることに注意してください。 この表から、各長さの「マップ」を作成します。 この手紙やその手紙が会えない場所の長さ。 たとえば、「7'4」は、7文字の単語ではアポストロフィを4番目の文字にできないことを意味し、「15b14」は15文字の単語で「b」が最後に1つしか気付かれていないことを意味します。
各単語長の文字位置でテーブルを作成する
select length=len(word),'''' letter, charindex('''',word) number into #tmpl from words where charindex('''',word)>0 union select length=len(word),'a' letter, charindex('a',word) number from words where charindex('a',word)>0 ... union select length=len(word),'z' letter, charindex('z',word) number from words where charindex('z',word)>0
文字、長さ、位置のデカルト積を行い、既存のものに左結合します
select l.length,a.letter,l.length from allchars a cross join (select 1 number union select 2 union select 3 union select 20 union select 21) n cross join (select 1 length union select 2 union select 3 union select 20 union select 21) l left join #tmpl t on a.letter=t.letter and t.number=n.number and t.length=l.length where t.letter is not null
次に、最初の部分の「切り捨てられた」ハーフメジャーの単語の位置番号を補完して、単語内の2文字と3文字の存在しない組み合わせをチェックします。
ペアとトリプルを選択します。
-- . cright cwrong – . create table stat2(letters char(2),pos int,cright int,cwrong int) create table stat3(letters char(3),pos int,cright int,cwrong int) create table #tmp2(l varchar(2),valid int,invalid int) create table #tmp3(l varchar(3),valid int,invalid int) -- declare @i INT set @i=0 while @i<20 begin set @i=@i+1 truncate table #tmp2 truncate table #tmp3 -- insert into #tmp2 select substring(word,@i,2),0,count(*) from wrongwords where len(word)>@i group by substring(word,@i,2) -- insert into #tmp3 select substring(word,@i,2),count(*),0 from words where len(word)>@i group by substring(word,@i,2) insert into stat2 -- select e.letters2,@i,r.valid,l.invalid from allchars2 e left join #tmp2 l on ll=e.letters2 left join #tmp3 r on rl=e.letters2 end declare @i INT set @i=0 while @i<19 begin set @i=@i+1 truncate table #tmp2 truncate table #tmp3 -- insert into #tmp2 select substring(word,@i,3),0,count(*) from wrongwords where len(word)>@i+1 group by substring(word,@i,3) -- insert into #tmp3 select substring(word,@i,3),count(*),0 from words where len(word)>@i+1 group by substring(word,@i,3) -- insert into stat3 select e.letters3,@i,r.valid,l.invalid from allchars3 e left join #tmp2 l on ll=e.letters3 left join #tmp3 r on rl=e.letters3 print @i end
結果をExcelにコピーし、正しい単語と間違った単語の数で遊んで、理論的に最も可能性の高いもの(少なくとも5〜10単語が見つかりました)と最も有用なもの(少なくとも1:300の正しい/間違った比率)だけを残します。
ピボットテーブルを作成します。 結果は次のようになります。
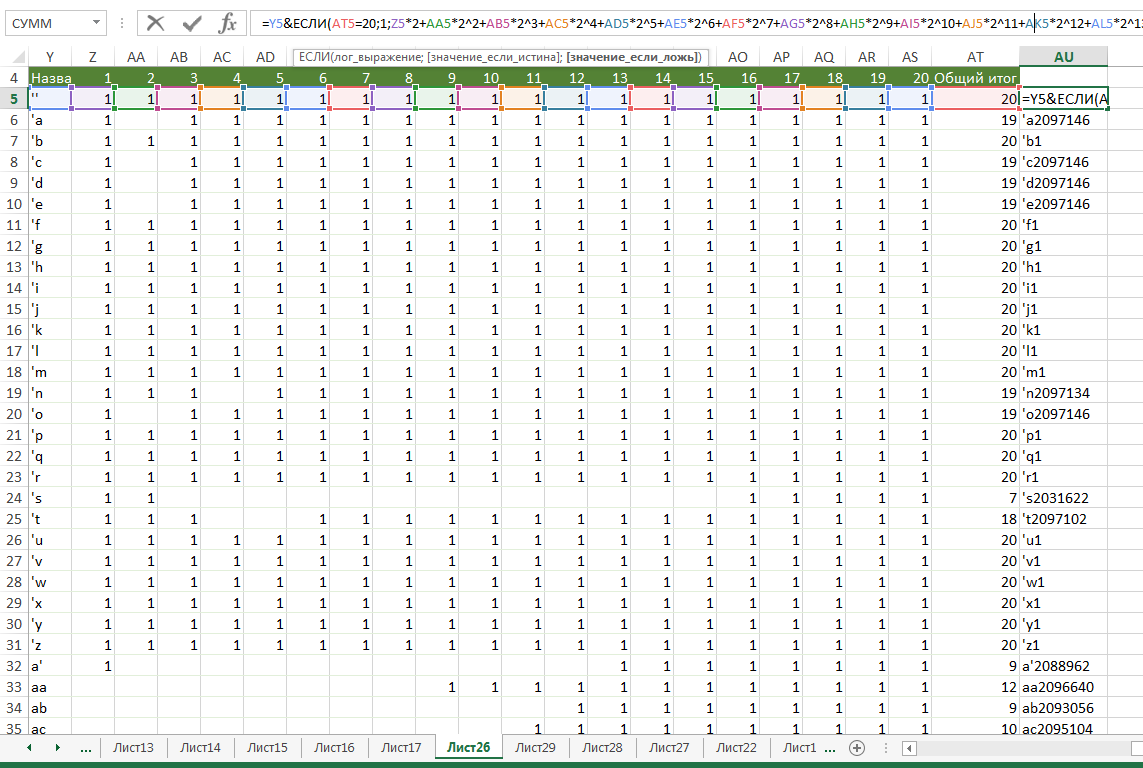
プログラム用のデータを作成します:ペア+ビットマスク(写真の上部にある式を参照)。
ダウンロードコードは前半で説明したものと似ていますが、チェックが変わります。
for (letters in letters2Map) { if (word.indexOf(letters)>=0) { if ((letters2Map[letters] & 1) ==1) { result = return false; } for (var k=0;k<21;k++) { if (((letters2Map[letters] & Math.pow(2,k+1))==Math.pow(2,k+1))&& (letters[0] == word[k-1]) && (letters[1] == word[k])) { return false; } } } }
私はチェック:再び、65%以下。 ジェネレーターのロジックに基づいて、少し「チート」して結果を改善したいという要望があります。
- すべての繰り返しを正しい単語と見なしてください。 間違ったものはあまり頻繁に繰り返されません。 間違ったリーダーの間の繰り返しには、いくつかの奇妙な明白なリーダーがいますが、彼らは単に例外として説明することができます。
- 100ワードのパケットの割合を正しく/間違って追跡し、60/40のスキューの後にそれらを調整します。
しかし、これらのオプションは両方ともa)信頼性が低く、b)「スポーツマンらしくない」ので、後で使用します。
「記述的」な方法で問題を解決することが不可能であることを確認するために、データ量を制限せずに最後のチェックを行いたいです。 これを行うために、私はチェックにすべての「隣接する」ペアと文字のトリプルを追加することにしました。 ペアから始めて、テーブルに入力します。
declare @i INT set @i=0 while @i<17 begin set @i=@i+1 insert into stat2_1 select substring(word,@i,2),substring(word,@i+2,2),@i,count(*),0 from words where len(word)>@i+3 group by substring(word,@i,2),substring(word,@i+2,2) end
結果をテキストで保存し、データを確認します-結果は約67%です。
単語が間違っているとして排除されない場合、結果は肯定的であると見なされることに留意する必要があります。 これは、単語の約半分が明らかに肯定的であるという事実によってのみ67%さえ達成されることを意味します。つまり、間違った単語の3分の1以上をふるいにかけます。 文字の組み合わせによって単語の不正確さを判断するために利用可能なほとんどすべてのオプションを試したため、この方法は追加のフィルターとしてのみ機能し、ニューラルネットワークに戻る必要があるという残念な結論に至りました。 まあ、「numismatograph」や「troid」などの誤った単語を識別するためのルールを作成することはできません。
トレーニングが長すぎるため、セットに誤った単語が存在するオプションがなくなるため、ホップフィールドネットワークを試すことにしました。 既成のシナプス実装を見つけました。 私は小さなセットでテストしています-結果は驚くほど良いです。 5文字のすべての単語の配列を確認します-結果は80%を超えています。 同時に、ライブラリは、ライブラリ自体を接続せずにデータをチェックする関数を作成する方法も知っています。
var run = function (input) { F = { 0: 1, 1: 0, ... 370: -0.7308188776194796, ... 774: 8.232535948940295e-7 }; F[0] = input[0]; ... F[26] += F[0] * F[28]; F[26] += F[1] * F[29]; ... F[53] = (1 / (1 + Math.exp(-F[26]))); F[54] = F[53] * (1 - F[53]); F[55] = F[56]; F[56] = F[57]; ... F[773] = (1 / (1 + Math.exp(-F[746]))); F[774] = F[773] * (1 - F[773]); var output = []; output[0] = F[53]; ... output[24] = F[773]; return output; }
私は単純に(もう一度)喜び、アレイ全体をチェックします。 ネットワークのトレーニングの最後の部分で、単語が5ビットブロックのシーケンスで表されるテーブルを作成したことを思い出してください。各ブロックはアルファベットの文字のシリアル番号のバイナリ表現です。 21 * 5の入力ニューロンのページングされたデータは64Kを大幅に超えるため、長い単語を2つの部分に分割し、それぞれにフィードすることにしました。
トレーニングスクリプト:
var synaptic = require('synaptic'); var fs=require('fs'); var Neuron = synaptic.Neuron, Layer = synaptic.Layer, Network = synaptic.Network, Trainer = synaptic.Trainer function hopfield(size) { var input = new synaptic.Layer(size); var output = new synaptic.Layer(size); this.set({ input: input, hidden: [], output: output }); input.project(output, synaptic.Layer.connectionType.ALL_TO_ALL); var trainer = new synaptic.Trainer(this); this.learn = function(patterns) { var set = []; for (var p in patterns) set.push({ input: patterns[p], output: patterns[p] }); return trainer.train(set, { iterations: 50000, error: .000000005, rate: 1, log:1 }); } this.feed = function(pattern) { var output = this.activate(pattern); var pattern = [], error = []; for (var i in output) { error[i] = output[i] > .5 ? 1 - output[i] : output[i]; pattern[i] = output[i] > .5 ? 1 : 0; } return { pattern: pattern, error: error .reduce(function(a, b) { return a + b; }) }; } } hopfield.prototype = new synaptic.Network(); hopfield.prototype.constructor = hopfield; var myPerceptron=new hopfield(11*5+2); var array = fs.readFileSync('formining.csv').toString().split("\n"); var trainingSet=[]; for(i in array) { if (!(i%10000)) console.log(i); var testdata=array[i].split(","); var newtestdata1=[] var newtestdata2=[] var length = parseInt(testdata[0]?1:0); // testdata.splice(0, 1); // , newtestdata1.push(0); for(var j=0;j<11*5;j++){ newtestdata1.push(parseInt(testdata[j]?1:0)?1:0); } if(length>11) { // , newtestdata1.push(1); // "1" , newtestdata2.push(1); for(var j=11*5;j<22*5;j++){ newtestdata2.push(parseInt(testdata[j]?1:0)?1:0); } // "0" , newtestdata2.push(0); } else { // "0" , newtestdata1.push(0); } trainingSet.push(newtestdata1); if(length>11){ trainingSet.push(newtestdata2); } } myPerceptron.learn(trainingSet);
結果を取得するためのサイクルは同じで、trainingSet.pushの代わりにmyPerceptron.activate(newtestdataX)による予測と、結果を保存した単語を含む行の最後の要素とのビットごとの比較があります(もちろん、データファイルも異なります)間違った言葉を追加する)。
確認します。
大災害。
単一の正解ではありません。 より正確には、すべての質問に対して肯定的な答えが得られます。 5文字のセットに戻ります。 正常に動作します。 単語の2番目の部分を削除します-まだ正常に機能しません。 実験を通して、奇妙な機能に出くわします。5つのキャラクターの配列は、混ぜ合わせるまでスムーズに機能します。 つまり、このアルゴリズムは、星の配置が成功したことだけが十分に訓練されています。 他の状況では、設定に関係なく大量のデータで、この特定のアルゴリズムは、ほとんどすべてのデータセットに対して肯定的な答えを与えるような方法で因子を選択します。
もう一度、私は怒っています。 コンテストの終了まであと1日しかありませんでしたが、検索を続行することにしました。 ブルームフィルターに出くわした 。 意図的に大きなサイズ(10,000,000)を配置しました。 確認します。 95% やった! 100万に削減-結果は81%に悪化します。 単語をハッシュに置き換えることにしました:
function bitwise(str){ var hash = 0; if (str.length == 0) return hash; for (var i = 0; i < str.length; i++) { var ch = str.charCodeAt(i); hash = ((hash<<5)-hash) + ch; hash = hash & hash; // Convert to 32bit integer } return hash; } function binaryTransfer(integer, binary) { binary = binary || 62; var stack = []; var num; var result = ''; var sign = integer < 0 ? '-' : ''; function table (num) { var t = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'; return t[num]; } integer = Math.abs(integer); while (integer >= binary) { num = integer % binary; integer = Math.floor(integer / binary); stack.push(table(num)); } if (integer > 0) { stack.push(table(integer)); } for (var i = stack.length - 1; i >= 0; i--) { result += stack[i]; } return sign + result; } function unique (text) { var id = binaryTransfer(bitwise(text), 61); return id.replace('-', 'Z'); }
結果は88%でした。 データをアップロードします-たくさん。 減らす方法を考えます。 フィルターサイズを500,000に縮小します-結果は80%に悪化します。 単語数を減らす必要があると思います。
論理的な最初のステップは、「 's」から100K以上の重複する単語を削除することです。 しかし、もっと実質的なことをしたいと思います。 辞書を減らすためにテストされたすべてのオプションをリストするわけではありません。最後のオプションに焦点を当てます。
主なアイデアは、他の単語に既に含まれているがプレフィックスとエンディングを持つ単語を辞書から削除し、吸収する単語に正しい単語がこれと同じかどうかを言うビットマスクを追加することですが、最初/最後の1/2/3/4文字なし。 その後、検証時に単語を取得し、すべての可能なプレフィックスとエンディングで試してみます。
たとえば(「s」のバリアント)、「sucralfate's4」という単語は「sucralfate」という単語がまだ存在することを意味し、「suckstone16」という単語は「stone」という単語もあり、「suctorian's12」という意味です「suctorian」と「suctoria」の両方も正しいでしょう。
そのようなディレクトリを作成する方法を理解するために-それは少し残っています。 結果はアルゴリズムです:
プレフィックスとエンディングを持つテーブルを作成する
select word,p=substring(word,len(word),1),w=substring(word,1,len(word)-1) into #a1 from words where len(word)>2 select word,p=substring(word,1,1),w=substring(word,2,len(word)-1) into #b1 from words where len(word)>2 select word,p=substring(word,len(word)-1,2),w=substring(word,1,len(word)-2) into #a2 from words where len(word)>3 select word,p=substring(word,len(word)-2,3),w=substring(word,1,len(word)-3) into #a3 from words where len(word)>4 select word,p=substring(word,len(word)-3,4),w=substring(word,1,len(word)-4) into #a4 from words where len(word)>5 select word,p=substring(word,1,2),w=substring(word,3,len(word)-2) into #b2 from words where len(word)>3 select word,p=substring(word,1,3),w=substring(word,4,len(word)-3) into #b3 from words where len(word)>3 select word,p=substring(word,1,4),w=substring(word,5,len(word)-4) into #b4 from words where len(word)>4
結果の一般的な表
select word, substring(word,len(word),1) s1, substring(word,1,len(word)-1) sw1, substring(word,len(word)-1,2) s2, substring(word,1,len(word)-2) sw2, substring(word,len(word)-2,3) s3, substring(word,1,len(word)-3) sw3, IIF(len(word)>4,substring(word,len(word)-3,4),'') s4, IIF(len(word)>4,substring(word,1,len(word)-4),'') sw4, substring(word,1,1) p1,substring(word,2,len(word)-1) pw1, substring(word,1,2) p2,substring(word,3,len(word)-2) pw2, substring(word,1,3) p3,substring(word,4,len(word)-3) pw3, IIF(len(word)>4,substring(word,1,4),'') p4,IIF(len(word)>4,substring(word,5,len(word)-4),'') pw4, se1=null,se2=null,se3=null,se4=null,pe1=null,pe2=null,pe3=null,pe4=null,excluded=0 into #tmpwords from words where len(word)>2
永遠に待たない指標
create index a1 on #tmpwords(word) create index p0 on #tmpwords(s1) create index p1 on #tmpwords(sw1) create index p2 on #tmpwords(s2) create index p3 on #tmpwords(sw2) create index p4 on #tmpwords(s3) create index p5 on #tmpwords(sw3) create index p6 on #tmpwords(s4) create index p7 on #tmpwords(sw4) create index p20 on #tmpwords(p1) create index p30 on #tmpwords(pw1) create index p21 on #tmpwords(p2) create index p31 on #tmpwords(pw2) create index p41 on #tmpwords(p3) create index p51 on #tmpwords(pw3) create index p61 on #tmpwords(p4) create index p71 on #tmpwords(pw4)
各接頭辞と各長さの末尾の単語数をカウントして保存します。
select p into #a11 from #a1 a join words w on w.word=aw and len(w.word)>2 group by p having count(*)>1 select p into #a21 from #a2 a join words w on w.word=aw and len(w.word)>2 group by p having count(*)>1 select p into #a31 from #a3 a join words w on w.word=aw and len(w.word)>2 group by p having count(*)>1 select p into #a41 from #a4 a join words w on w.word=aw and len(w.word)>2 group by p having count(*)>1 select p into #b11 from #b1 a join words w on w.word=aw and len(w.word)>2 group by p having count(*)>1 select p into #b21 from #b2 a join words w on w.word=aw and len(w.word)>2 group by p having count(*)>1 select p into #b31 from #b3 a join words w on w.word=aw and len(w.word)>2 group by p having count(*)>1 select p into #b41 from #b4 a join words w on w.word=aw and len(w.word)>2 group by p having count(*)>1
テーブル内の単語吸収体に結果をマークします
update w set se1=1 from #tmpwords w join #a11 a on ap=w.s1 join #tmpwords t on t.word=w.sw1 update w set se2=1 from #tmpwords w join #a21 a on ap=w.s2 join #tmpwords t on t.word=w.sw2 update w set se3=1 from #tmpwords w join #a31 a on ap=w.s3 join #tmpwords t on t.word=w.sw3 update w set se4=1 from #tmpwords w join #a41 a on ap=w.s4 join #tmpwords t on t.word=w.sw4 update w set pe1=1 from #tmpwords w join #b11 a on ap=w.p1 join #tmpwords t on t.word=w.pw1 update w set pe2=1 from #tmpwords w join #b21 a on ap=w.p2 join #tmpwords t on t.word=w.pw2 update w set pe3=1 from #tmpwords w join #b31 a on ap=w.p3 join #tmpwords t on t.word=w.pw3 update w set pe4=1 from #tmpwords w join #b41 a on ap=w.p4 join #tmpwords t on t.word=w.pw4
最も一般的なオプションを選択するために、結合された結果を作成します
select s1 p,count(*) cnt into #suffixes from #tmpwords where se1 is not NULL group by s1 union all select s2,count(*) from #tmpwords where se2 is not NULL group by s2 union all select s3,count(*) from #tmpwords where se3 is not NULL group by s3 union all select s4,count(*) from #tmpwords where se4 is not NULL group by s4 select p1,count(*) cnt into #prefixes from #tmpwords where pe1 is not NULL group by p1 union all select p2,count(*) from #tmpwords where pe2 is not NULL group by p2 union all select p3,count(*) from #tmpwords where pe3 is not NULL group by p3 union all select p4,count(*) from #tmpwords where pe4 is not NULL group by p4
100以上の単語で表示されるものだけを残します。
select *,'s' type ,IIF(cnt>100,0,1) excluded into #result from #suffixes union all select *,'p' type, IIF(cnt>100,0,1) excluded from #prefixes
ゼロ統計
update #tmpwords set se1=null,se2=null,se3=null,se4=null,pe1=null,pe2=null,pe3=null,pe4=null
「余分な」コンソールとエンディングを削除します
delete a from #a11 a join #result r on rp=ap and r.type='s' and excluded=1 delete a from #a21 a join #result r on rp=ap and r.type='s' and excluded=1 delete a from #a31 a join #result r on rp=ap and r.type='s' and excluded=1 delete a from #a41 a join #result r on rp=ap and r.type='s' and excluded=1 delete a from #b11 a join #result r on rp=ap and r.type='p' and excluded=1 delete a from #b21 a join #result r on rp=ap and r.type='p' and excluded=1 delete a from #b31 a join #result r on rp=ap and r.type='p' and excluded=1 delete a from #b41 a join #result r on rp=ap and r.type='p' and excluded=1
残りの最も頻繁に発生した統計を更新します。
update w set se1=1 from #tmpwords w join #a11 a on ap=w.s1 join #tmpwords t on t.word=w.sw1 update w set se2=1 from #tmpwords w join #a21 a on ap=w.s2 join #tmpwords t on t.word=w.sw2 update w set se3=1 from #tmpwords w join #a31 a on ap=w.s3 join #tmpwords t on t.word=w.sw3 update w set se4=1 from #tmpwords w join #a41 a on ap=w.s4 join #tmpwords t on t.word=w.sw4 update w set pe1=1 from #tmpwords w join #b11 a on ap=w.p1 join #tmpwords t on t.word=w.pw1 update w set pe2=1 from #tmpwords w join #b21 a on ap=w.p2 join #tmpwords t on t.word=w.pw2 update w set pe3=1 from #tmpwords w join #b31 a on ap=w.p3 join #tmpwords t on t.word=w.pw3 update w set pe4=1 from #tmpwords w join #b41 a on ap=w.p4 join #tmpwords t on t.word=w.pw4
「吸収された」言葉に印を付ける
update t set excluded=1 from #tmpwords w join #a11 a on ap=w.s1 join #tmpwords t on t.word=w.sw1 update t set excluded=1 from #tmpwords w join #a11 a on ap=w.s1 join #tmpwords t on t.word=w.sw1 update t set excluded=1 from #tmpwords w join #a21 a on ap=w.s2 join #tmpwords t on t.word=w.sw2 update t set excluded=1 from #tmpwords w join #a31 a on ap=w.s3 join #tmpwords t on t.word=w.sw3 update t set excluded=1 from #tmpwords w join #a41 a on ap=w.s4 join #tmpwords t on t.word=w.sw4 update t set excluded=1 from #tmpwords w join #b21 a on ap=w.p2 join #tmpwords t on t.word=w.pw2 update t set excluded=1 from #tmpwords w join #b31 a on ap=w.p3 join #tmpwords t on t.word=w.pw3 update t set excluded=1 from #tmpwords w join #b41 a on ap=w.p4 join #tmpwords t on t.word=w.pw4
利益:-)
select excluded,count(*) cnt from #tmpwords group by excluded
| 除外された | cnt |
|---|---|
| 0 | 397596 |
| 1 | 232505 |
ディレクトリは232505ロスレスエントリに圧縮されました。
次に、チェックを行う必要があります。 考えられるすべてのプレフィックスとエンディングを反復処理する必要があるため、非常に複雑になり、速度が低下しました。
// result=bloom.test(unique(word)) if(result){ return true; } // for(var i=0;i<255;i++) { // - result=bloom.test(unique(word+i)) if(result){ return true; } // for (var part in parts ){ //1-,2- var testword=(parts[part]==2?part:"")+word+(parts[part]==1?part:""); // , 4 bitmask=Math.pow(2,(parts[part]-1)*4+part.length); // if(i&bitmask==bitmask){ result=bloom.test(unique(testword+i)) if (result){ return true } } }
私はそれを始めています。 結果は悪化しました。 しかし、彼は改善しなければなりませんでした! 時間がありません。webstormのデバッガーは非常にバグが多く、まだ理解する時間がありません。 何を送信するのかは意味がありませんが、面白かったです。 私もあなたを願っています。 「休暇」は終了しました。 あなたのラムに あなたのプロジェクトに 。 ご清聴ありがとうございました。