すべての理解の始まりは分類です。ヘイデンホワイト
この記事は何についてですか?
情報アーキテクチャには多くの定義があります。 この記事では、その側面の1つ、つまり、サイトの情報の構造化と分類を検討し、リソースへの訪問者の情報を見つけるプロセスを促進することを目指します。
サイト所有者の間では、訪問者がサイトに費やす時間が長いほど良いという意見があります。 訪問者がサイトに滞在する平均時間を増やす方法に関する記事もあります。 しかし、そうですか? ビジネスにとってさらに重要なこと-ユーザーが必要な情報を探して10分間サイト内をさまよい、何も見つからずに去るということですか? または、組織の連絡先であれ、配管の自動設置の指示であれ、必要な情報を見つけられるように、彼は喜んでサイトに戻り、買い手として会社に来ますか? 2番目を想定します。
この記事では、訪問者の生活を楽にする方法について説明します。
実際、問題は何ですか?
情報技術が科学研究所やコンピューターセンターの境界を越えて、私たちの日常生活の一部になったことにも気付かなかった。 不可欠な部分。 5年後には、地球の領土の85 85%がワイヤレスインターネットでカバーされると考えられています。 そしてこれは、インターネット上の情報の消費者は訓練された専門家ではなく、 普通の人々であることを意味します。 また、リソースの情報アーキテクチャを設計する際には、リソースに投稿された情報の消費者が特定の分野で特別な知識を持っていないという事実に導かれるべきです。
そして、これが問題が発生する場所です。
- あいまいさ
どの言語もあいまいです。 たとえば、「タマネギ」という言葉の意味はいくつ知っていますか? そして、「ダックスフント」という言葉は?
専門用語は言うまでもありません。 準備ができていない人は、「輸送」サービスが商品の輸送をドアからドアへではなく、倉庫から倉庫へのみ隠すことをどのように理解できますか? 「フェンス」という言葉の下では、ピケットフェンスやコンクリートで作られた構造ではなく、ドアから倉庫まで貨物を配送するサービスとまったく同じですか?
「トピック」や「機能」などの抽象的な概念を分類することは特に困難です。
- 異質性
「均一性」とは対照的に、不均一性は、切断されたまたは異なる部分で構成されたオブジェクトまたはオブジェクトのグループのプロパティです。
セモリナは非常に均質であるため、均質です。 しかし、ここでは、現代のリソースに関する情報はむしろ寄せ集めです。 サービス、価格、記事、オンライン購入、写真、ビデオ、連絡先-これは、通常サイトに投稿されるトピックの完全なリストではありません。
そして、この寄せ集めをコンポーネントに分解して、リソースの訪問者が何を、何を探すべきかを理解するのはそれほど簡単ではありません。
- 視点の違い
リソース所有者は、ビジネスがどのように機能するかについて明確な考えを持っています。 会社にはどの部門が存在し、その組織構造は何ですか。 そして、しばしば彼は彼のアイデアに従ってサイト上の情報を整理しようとします。
しかし、訪問者は会社がどのように組織されているかについて何も知りません。 サイトに来て、彼は、たとえば製品の技術的特性を見つけることなど、特定の目標を念頭に置いています。 そして、どのユニットがこれらの特性の編集であるかを、彼はどのようにして見つけることができますか?
理論のビット
情報を分類するためのシステムには、階層型とマルチアスペクトの2つがあります。
- 階層分類システム

図1-階層分類システム
階層分類システムを使用する場合、多くのオブジェクトは、下位のサブセットまたは分類グループに順番に分割されます。 各分類レベルで、オブジェクトのグループのサブセットへの分割は、記号の1つに従って行われます。
階層分類システムの機能は、各分類レベルのオブジェクトをオブジェクトの1つのサブセットのみに割り当てることができることです。 分類機能の事前に確立された選択と、分類手順に従ってそれらを使用する順序により、厳密な分類グループが作成されます。
- 多面分類システム
アスペクトは、1つ以上の属性によって特徴付けられる分類オブジェクトの視点です。 したがって、 多次元分類システムは、いくつかの独立した機能(アスペクト)を使用して、オブジェクトを分類の基礎として特徴付けます。
マルチアスペクトシステムには、 ファセットシステムとディスクリプタシステムの2種類があります。 ファセットは、独立した分類グループを形成するために使用される分類の側面です。 記述子は、オブジェクトの説明を形成し、このオブジェクトをクラス、グループなどに属するようにする特定の概念を定義するキーワードです。
ファセット分類では、ファセットと呼ばれる分類機能テーブルのシステムが開発されています。 オブジェクトを識別するために、ファセットからフィーチャが選択され、特定の順序で関連付けられます。

図2-テーブル形式のファセットの説明
記述子分類は、文書などの非構造化データに関する情報の検索に使用されます。 記述子の分類を実装するために、すべての一般的な関係、同義語、同音異義語、および多義性の関係を含むキーワードの辞書(テサリウス)がコンパイルされ、すべてのドキュメントが特定のキーワードのセットによってインデックス付けされます。
理論から実践へ:情報組織化スキーム
階層分類システムに基づく組織スキーム
- アルファベット順の組織
情報は、姓、製品またはサービス、部門、形式のアルファベット順に表示されます。 それは、たとえば薬の名前など、同種の情報の分類によく表れています。

図3-アルファベット順の組織 「 www.rlsnet.ru 」の例
- 年表
発行日までに情報を整理することを想定しています。 公開日が情報の重要な側面である場合に適用されます。 プレスリリース、ニュース、ブログフィード-これらはすべて年代順に簡単に並べ替えられます。

図4-情報の時系列編成の例 chto-chitat.livejournal.com
- 地理的組織
多くの場合、情報の重要な特徴は地理的な場所です。 国、地域、都市、地下鉄駅による連絡先情報の分類により、簡単かつ視覚的にアクセスできます。 サイトの地理を地図の助けを借りて視覚化できます。また、アルファベット順のリストの形式で、アルファベット順と地理的編成を組み合わせています。
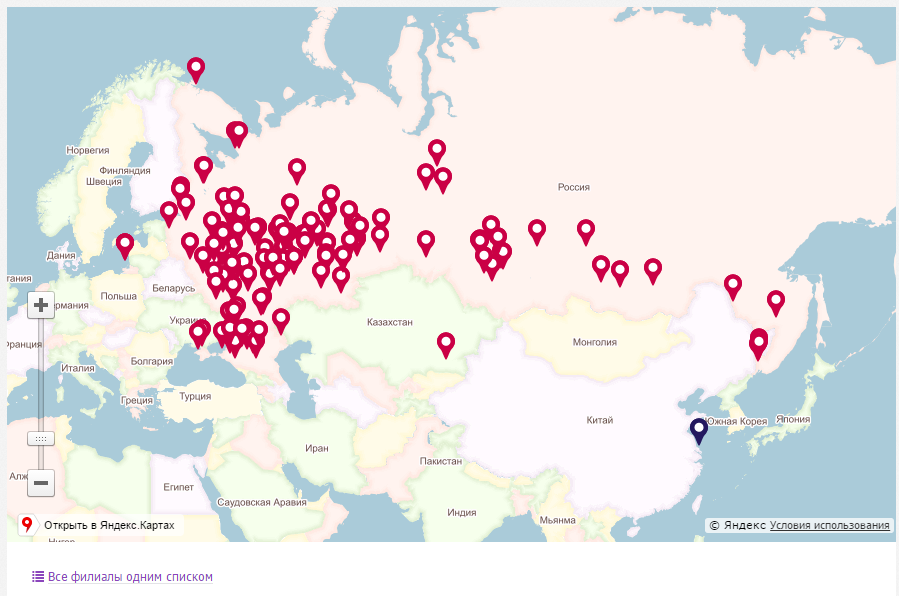
図5-情報の地理的編成の例
- テーマ構成
個々のトピックに属するという原則に従って情報を分離することを前提としています。 この方法の欠点は、その曖昧さです。異なる人が同じオブジェクトを異なるトピックに帰属させることができるためです。 たとえば、C#教科書が必要な学生は、書店のどのセクションで「教科書」または「情報技術」を探しますか?
トピックベースの組織は最も時間のかかる方法の1つですが、視聴者の思考の流れを推測できる場合は、最も効果的です。

図6-情報のテーマ構成の例 www.labirint.ru
- タスク編成
ユーザーにとって最も優先度の高い機能またはタスクを強調表示できる場合は、プロセス、機能、またはタスクの組み合わせによって情報を整理できます。
インターネットでは、タスクの組織はほとんどの場合、銀行および保険組織のWebサイトやオンラインバンキングシステムにあります。

図7-タスク 別の 組織の例 www.sberbank.ru
このスキームの欠点は、異なるユーザーが同じ小さなタスクを異なるグループに割り当てることができることです。たとえば、「ローンを取得する」セクションと「カードを選択する」セクションの両方でクレジットカードを検索できます。
- 視聴者組織
リソースのオーディエンスを少なくとも2つのグループに明確に分割できる場合、これらのグループ向けの情報は完全に異なり、サイトの訪問者が特定のグループに明確に自分自身を関連付けることができると確信できる場合は、オーディエンスごとに組織を適用できます。

図8-視聴者による組織の例 pecom.ru
- 比phor
それらは、よく知られた概念の助けを借りて、ユーザーに新しい何かを説明するために使用されます。 インターネット上でメタファーを使用する主な例は、eコマースショッピングカートです。 物理的なバスケットがないことを理解するように、オンラインストアのバスケットに商品を入れるときの意味を理解しています。
比phorの特徴は、陳腐化の特性です。 今日の子供たちは、「保存」アイコンを3インチフロッピーディスクのイメージとして認識しなくなりました。 彼らにとっては、それはフロッピーのようなもので、保存アイコンの一種です。
Googleのマテリアルデザインは、比phorの現代的な例です。

図9-Googleマテリアルデザイン www.google.com/design/spec/style/icons.html#icons-product-icons
ハイブリッド情報組織化スキーム
厳格な情報組織化スキームには1つの重要な利点があります-それらはユーザーに簡単に認識されます。 ユーザーが分類を理解する最も簡単な方法は、対象者と主題です。 しかし、それにもかかわらず、実際の設計状況では、その異質性による情報が厳格な組織体系に適合することはめったにありません。 実際には、ハイブリッド方式が最もよく使用されます。
ハイブリッドスキームは、さまざまな方法で構築できます。 最上位レベルでは、たとえばテーマなどの1つのスキームを使用し、次のレベルでは、たとえばアルファベット順に別のスキームを使用し、異なるセクションで異なるスキームを使用できます。
2つ以上の厳密なスキームを同じ分類レベルで一緒に使用することもできます。 これにより非常に良い結果が得られますが、同じレベルで3つ以上の回路を使用するとユーザーが混乱する可能性があります。
以下の図は、ハイブリッド情報編成スキームの使用例を示しています。
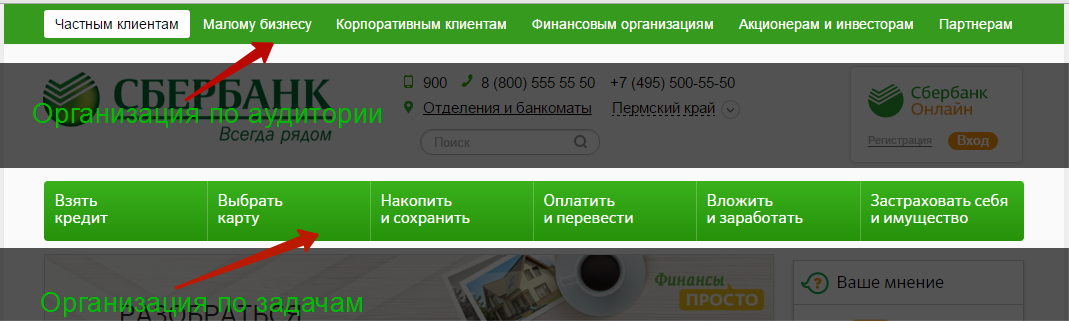

図10-ハイブリッド情報組織化スキームの例
ファセットインターネットナビゲーションの使用
例によるファセット分類を検討してください。 多くの特性による分類の典型的な例は、ワインの分類です。 国、色、種類、ブドウ園、価格など、ワインを分類する多くの兆候があります。 これらはファセットです。
各ファセット内で、値を強調表示できます。 たとえば、色は白、ピンク、赤で、タイプはドライ、セミドライ、セミスイート、スイートです。
したがって、ファセットは多くの可能な値を形成します。 セットの共通部分は、オブジェクトの明確な識別を提供します。
ファセットナビゲーションは、訪問者がさまざまな方法で情報を検索できるという前提に基づいています。 たとえば、ある訪問者にワインを選択する場合、種類が重要であり、別の訪問者には優先原産国が重要です。
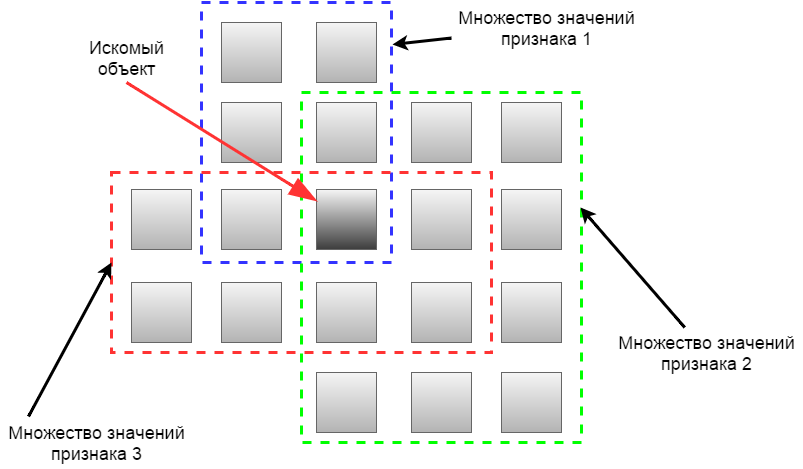
図11-ファセット分類
ファセットナビゲーションの利点は次のとおりです。
- 空の検索結果はありません。 すべての属性の値のセットは既存のオブジェクトによって決定されるため、少なくとも1つの属性の値を示すと、少なくとも1つのオブジェクトになります。
- 値が示されています。 特性の値ごとに、この特性値を持つオブジェクトの数を指定できます。
- 多くの検索パス。 ユーザーは、さまざまな特性の値を任意の順序で選択できます。
- 値の選択はキャンセルできます。 各機能には多くの意味があるため、ユーザーはいつでも値の新しい組み合わせを作成できます。
現在、ファセットナビゲーションは、家電製品のオンラインストアで最も効果的に使用されています。
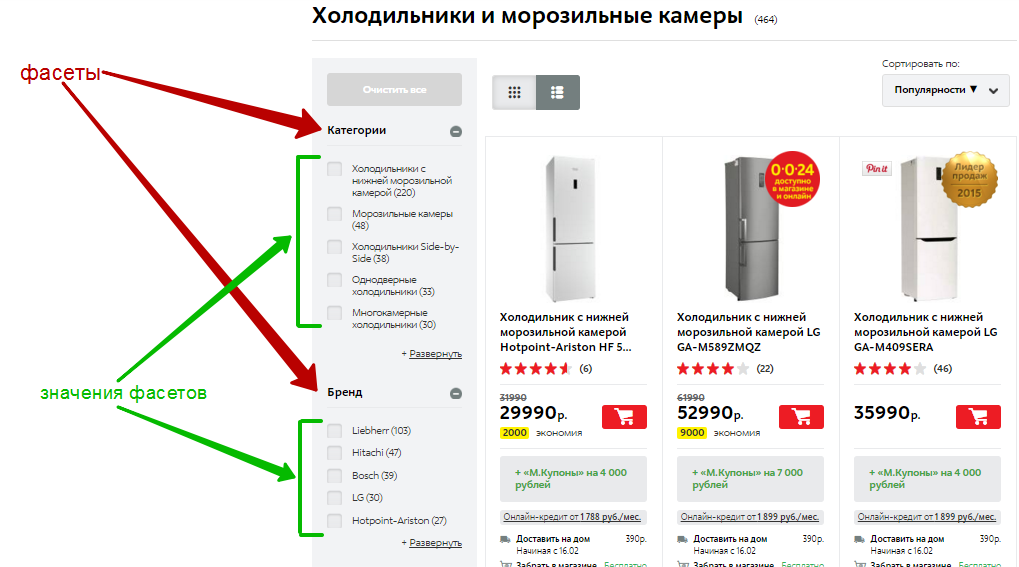
図12-ファセットナビゲーションの例 www.mvideo.ru
情報記述子の構成
前述のように、記述子の分類はキーワードの使用に基づいています。 インターネットでは、記述子はタグクラウドとして実装されます。 各タグのエントリ数は、数値と、このタグまたはそのタグを記述するために使用されるフォントのサイズの両方で示すことができます。

図13-記述子ナビゲーションの例 www.livejournal.com
結論の代わりに
ターゲットオーディエンスグループを識別することにより、Webリソースで情報アーキテクチャの構築を開始することをお勧めします。 ビジネスで同等のグループを少なくとも2つ特定できる場合は、ターゲットグループによる分類から始めて、アーキテクチャを構築する可能性を検討する必要があります。
オーディエンスをグループに分割することが不可能な場合、原則として、ナビゲーションの最上位レベルで、情報はテーマまたは機能ごとに分割されます。
アルファベット順や地理的などの厳格な情報組織化スキームは、主にリソースセクションのネストのより深いレベルで使用されます。
eコマース環境では、カタログの各セクションに個別に実装されるファセットナビゲーションが最良の結果です。