この記事では、作成方法と作成理由について説明します。

背景
過去数年間、私はSharePointを実行するRepsorカストディアンアプリケーションに取り組んできました。 SharePointに精通している場合、そのモデルには別のサーバーでアプリケーションを実行する必要があることがわかります。 これにより、安定性が向上し、アーキテクチャが簡素化されます。 ただし、毎回データをSharePointサーバーに移動する必要があるため、このモデルはパフォーマンスを低下させます。この場合のネットワーク遅延は好ましくありません。
このため、StackExchange.Redisを.NETクライアントとして使用して、Redisキャッシュをアプリケーションに追加することにしました。 すべてのアプリケーションデータモデルの完全なキャッシュには、セット、順序付きセット、およびハッシュテーブルを使用します。
予想どおり、これによりアプリケーションが大幅に加速しました。 これで、以前のように、ページが2秒ではなく約500ミリ秒で返されました。 しかし、分析により、これらの500ミリ秒のうちでも、Redisとのデータの送受信にかなりの時間が費やされていることがわかりました。 さらに、ページからの要求に応じて毎回受信されるデータの主要部分は変更されませんでした。
キャッシュキャッシング
Redisは非常に高速なキャッシュツールであるだけでなく、キャッシュされたデータを管理するためのツールセットでもあります。 このシステムは十分に開発され、広くサポートされています。 StackExchange.Redisライブラリは無料でオープンソースであり、そのコミュニティは急速に成長しています。 Stack ExchangeはすべてのRedisデータを積極的にキャッシュしますが、Redisデータはインターネット上で最も忙しいサイトの1つです。 しかし、切り札は、Redisサーバー上のすべての利用可能なデータのメモリ内キャッシュを実行するため、通常、Redisにアクセスする必要さえありません。
次の引用では、Stack Exchangeでキャッシュメカニズムがどのように機能するかについてある程度説明しています。
http://meta.stackexchange.com/questions/69164/does-stack-exchange-use-caching-and-if-so-how
「間違いなく、ネットワークを介して最も速く送信できる最適なデータ量は0バイトです。」
別のキャッシュに移動する前にデータをキャッシュすると、いくつかのレベルのキャッシュが作成されます。 Redisにキャッシュする前にデータのメモリ内キャッシュを実行すると、メモリ内キャッシュには最初のL1レベルが割り当てられます。
したがって、Redisがアプリケーションの最も遅い部分である場合、正しい方向に進んでおり、将来この欠点を確実に加速させることができます。
メモリ内キャッシュ
最も単純な状況では、Redisを使用すると、コードは次のようになります。
//Try and retrieve from Redis RedisValue redisValue = _cacheDatabase.StringGet(key); if(redisValue.HasValue) { return redisValue; //It's in Redis - return it } else { string strValue = GetValueFromDataSource(); //Get the value from eg. SharePoint or Database etc _cacheDatabase.StringSet(key, strValue); //Add to Redis return strValue; }
また、インメモリキャッシュ(つまり、L1キャッシュ)を適用する場合、コードはもう少し複雑になります。
//Try and retrieve from memory if (_memoryCache.ContainsKey(key)) { return key; } else { //It isn't in memory. Try and retrieve from Redis RedisValue redisValue = _cacheDatabase.StringGet(key); if (redisValue.HasValue) { //Add to memory cache _memoryCache.Add(key, redisValue); return redisValue; //It's in redis - return it } else { string strValue = GetValueFromDataSource(); //Get the value from eg. SharePoint or Database etc _cacheDatabase.StringSet(key, strValue); //Add to Redis _memoryCache.Add(key, strValue); //Add to memory return strValue; } }
実装はそれほど難しくありませんが、Redisの他のデータモデルに対して同じことをしようとすると、はるかに複雑になります。 さらに、次の問題が発生します。
•Redisでは、StringAppendなどの関数を使用してデータを管理できます。 この場合、メモリ内要素を無効と宣言する必要があります。
•KeyDeleteを使用してキーを削除する場合は、メモリ内キャッシュからも削除する必要があります。
•別のクライアントが値を変更または削除すると、そのクライアントのメモリ内キャッシュで廃止されます。
•キーの有効期限が切れたら、メモリ内キャッシュから削除する必要があります。
StackExchange.Redisライブラリのデータにアクセスしてデータを更新するためのメソッドは、IDatabaseインターフェイスで定義されます。 上記のすべての問題を解決するように、IDatabaseの実装を書き換えることができます。 方法は次のとおりです。
•StringAppend-メモリ内の文字列にデータを追加し、同じ操作をRedisに渡します。 より複雑なデータ操作の場合、メモリ内キーを削除する必要があります。
•KeyDelete、KeyExpireなど-メモリ内のデータを削除します。
•別のクライアントを介した操作-Redisキースペース通知は、データの変更を検出し、それに応じて無効と宣言するように設計されています。
このアプローチの利点は、以前と同じインターフェイスを引き続き使用できることです。 L1キャッシュの実装では、コードを変更する必要はありません。
建築
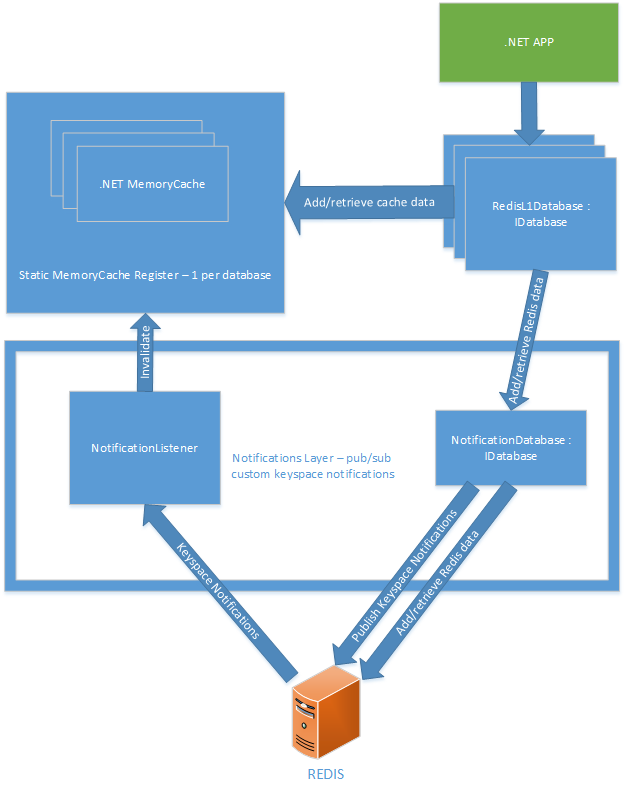
これらの基本要素を備えた次のソリューションを選択しました。
静的レジスタMemoryCache
既製のエンティティをRedis IDatabaseに渡すことで、新しいRedisL1Databaseエンティティを作成でき、このデータベース用に以前に作成したメモリ内キャッシュを引き続き使用します。
通知レベル
• NotificationDatabase-インメモリキャッシュを最新の状態に保つために必要な特別なキースペースイベントを発行します。 Redisの標準キースペース通知は、キャッシュの必要な部分を無効にするのに十分な情報を提供しないため、同じ結果を達成しません。 たとえば、ハッシュキーを削除すると、削除されたハッシュに関する情報を含むHDEL通知を受け取ります。 しかし、それはハッシュのどの要素であったかを示すものではありません。 また、特別なイベントには、ハッシュ要素自体に関する情報も含まれます。
• NotificationListener-特別なキースペースイベントにサブスクライブし、静的キャッシュにアクセスして必要なキーを無効にします。 彼は、expireと呼ばれる組み込みのRedisキースペースイベントにもサブスクライブします。 これにより、期限切れのすべてのRedisキーをメモリからすばやく削除できます。
次に、Redisでさまざまなデータモデルをキャッシュする方法を見ていきます。
ひも
文字列の操作は比較的簡単です。 IDatabase StringSetメソッドは次のようになります。
public bool StringSet(RedisKey key, RedisValue value, TimeSpan? expiry = default(TimeSpan?), When when = When.Always, CommandFlags flags = CommandFlags.None)
•キーと値-名前はそれ自体を表しています。
•有効期限は任意の期間であるため、有効期間のあるメモリ内キャッシュを使用する必要があります。
•いつ-線を作成するための条件を定義できます。線がすでに存在するか存在しない場合にのみ設定します。
•フラグ-Redisクラスターの詳細を指定できます(関係ありません)。
データを保存するには、System.Runtime.Caching.MemoryCacheを使用します。これにより、キーの自動有効期限が切れます。 StringSetメソッドは次のようになります。
public bool StringSet(RedisKey key, RedisValue value, TimeSpan? expiry = default(TimeSpan?), When when = When.Always, CommandFlags flags = CommandFlags.None) { if (when == When.Exists && !_cache.Contains(key)) { //We're only supposed to cache when the key already exists. return; } if (when == When.NotExists && _cache.Contains(key)) { //We're only supposed to cache when the key doesn't already exist. return; } //Remove it from the memorycache before re-adding it (the expiry may have changed) _memCache.Remove(key); CacheItemPolicy policy = new CacheItemPolicy() { AbsoluteExpiration = DateTime.UtcNow.Add(expiry.Value) }; _memCache.Add(key, o, policy); //Forward the request on to set the string in Redis return _redisDb.StringSet(key, value, expiry, when, flags);
StringGetは、Redisへのアクセスを試みる前に、メモリ内キャッシュを読み取ることができます。
public RedisValue StringGet(RedisKey key, CommandFlags flags = CommandFlags.None) { var cachedItem = _memCache.Get<redisvalue>(key); if (cachedItem.HasValue) { return cachedItem; } else { var redisResult = _redisDb.StringGet(key, flags); //Cache this key for next time _memCache.Add(key, redisResult); return redisResult; } } </redisvalue>
Redisは、文字列の多くの操作をサポートしています。 いずれの場合も、それらの使用は、メモリ内の値の更新または無効の宣言と関連付けられています。 一般に、2番目のオプションの方がうまく機能します。そうしないと、多くのRedis操作が不必要に複雑になるリスクがあります。
•StringAppendは非常に簡単な操作です。 データが存在し、非アクティブと宣言されていない場合、データはメモリ内の行に追加されます。
•StringBitCount、StringBitOperation、StringBitPosition-操作はRedisで実行され、メモリ内操作は不要です。
•StringIncrement、StringDecrement、StringSetBit、StringSetRange-メモリ内の文字列は、操作がRedisにリダイレクトされるまで無効と宣言されます。
•StringLength-メモリ内キャッシュにある場合、文字列の長さを返します。 そうでない場合、操作はRedisから取得します。
多くの
多くの場合、処理が少し難しくなります。 SetAddメソッドは次のように実行されます。
1.このキーでHashSetのMemoryCacheを確認します
•存在しない場合は作成します。
2.各Redis値をセットに追加します。
セットの値の追加と削除は非常に簡単です。 SetMoveメソッドは、SetRemoveに続いてSetAddです。
他のほとんどのセットクエリはキャッシュできます。 例:
• SetMembers-セットのすべての要素を返し、結果がメモリに保存されるようにします。
• SetContains、SetLength -Redisにアクセスする前にメモリ内セットを確認します。
• SetPop -Redisのセットからデータ項目をポップし、セットのメモリ内にその項目があれば削除します。
• SetRandomMember -Redisからランダムセット要素を受け取り、メモリ内キャッシュを実行して戻ります。
• SetCombine、SetCombineAndStore-メモリ内は不要です。
• SetMove-インメモリセットからデータ項目を削除し、別のインメモリセットに追加して、Redisにリダイレクトします。
ハッシュテーブル
ハッシュテーブルは、メモリ内での実装が単なる辞書<string、RedisValue>であり、原則として文字列に非常に似ているため、比較的単純です。
基本操作:
1.ハッシュテーブルがメモリ内で使用できない場合、辞書<string、RedisValue>を作成して保存する必要があります。
2.可能であれば、メモリ内ディクショナリで操作を実行します。
3.必要に応じて、リクエストをRedisにリダイレクトします。
•結果をキャッシュします。
ハッシュテーブルでは次の操作を使用できます。
•HashSet-キーに保存された辞書に値を保存し、リクエストをRedisにリダイレクトします。
•HashValues、HashKeys、HashLength-インメモリアプリケーションはありません。
•HashDecrement、HashIncrement、HashDelete-辞書から値を削除し、Redisにリダイレクトします。
•HashExists-値がメモリ内キャッシュにある場合、trueを返します。 それ以外の場合は、リクエストをRedisにリダイレクトします。
•HashGet-インメモリキャッシュからデータを要求します。 それ以外の場合は、リクエストをRedisにリダイレクトします。
•HashScan-Redisから結果を取得し、インメモリキャッシュに追加します。
注文セット
順序付きセットは、間違いなく、メモリ内キャッシュの作成に関して最も複雑なデータモデルです。 この場合、インメモリキャッシングプロセスには、いわゆる「ばらばらの順序セット」の使用が含まれます。 つまり、ローカルキャッシュがRedisの順序付きセットの小さなフラグメントを検出するたびに、このフラグメントは「ばらばらの」順序付きセットに追加されます。 将来、順序付きセットのサブセクションが要求された場合、最初に、ばらばらの順序付きセットがチェックされます。 必要なセクションが完全に含まれている場合、欠落しているコンポーネントがないことを完全に確信して返すことができます。
順序付けされたメモリ内セットは、値ではなく、特別なスコアパラメーターで並べ替えられます。 理論的には、ばらばらの順序セットの実装を拡張して、値でソートできるようにすることは可能ですが、現時点ではまだ実装されていません。
操作では、次のように素集合を使用します。
• SortedSetAdd-値はインメモリセットに個別に追加されます。つまり、スコアの点で関連しているかどうかはわかりません。
• SortedSetRemove-値はメモリとRedisの両方から削除されます。
• SortedSetRemoveRangeByRank-すべてのメモリ内セットは無効と宣言されます。
• SortedSetCombineAndStore、SortedSetLength、SortedSetLengthByValue、SortedSetRangeByRank、SortedSetRangeByValue、SortedSetRank-リクエストはRedisに直接送信されます。
• SortedSetRangeByRankWithScores、SortedSetScan-データはRedisから要求され、個別にキャッシュされます。
• SortedSetRangeByScoreWithScoresは、スコアが順番に返されるため、最もキャッシュされる関数です。 キャッシュがチェックされ、リクエストを処理できる場合はキャッシュが返されます。 それ以外の場合、リクエストはRedisに送信され、その後、スコアはデータの連続セットとしてメモリにキャッシュされます。
• SortedSetRangeByScore-可能な場合、データはキャッシュから取得されます。 それ以外の場合、スコアはRedisから取得され、スコアが返されないためキャッシュされません。
• SortedSetIncrement、SortedSetDecrement-メモリ内データが更新され、リクエストがRedisにリダイレクトされます。
• SortedSetScore —可能であれば、値はメモリから取得されます。 それ以外の場合、リクエストはRedisに送信されます。
順序付きセットの操作の複雑さは、2つの理由によるものです。1つは、順序付きセットの既存のサブセットのメモリ内実装の構築(つまり、不連続セットの構築)の特徴的な複雑さです。 そして第二に、実行を必要とするRedisで利用可能な操作の数を考慮して。 スコアを含むクエリの対象を絞ったキャッシュを実装できるため、ある程度、複雑さが軽減されます。 何らかの方法で、すべてのコンポーネントの深刻な単体テストが必要です。
一覧
リストはRAMにキャッシュするのはそれほど簡単ではありません。 理由は、それらの操作は、原則として、リストの先頭または末尾のいずれかで作業することを伴うからです。 そして、これは一見すると思えるほど簡単ではありません。なぜなら、メモリ内リストの先頭と末尾にRedisのリストと同じデータがあることを確認する機会が100%あるわけではないからです。 一部では、この問題はキースペース通知を使用して解決できますが、これまでのところ実現されていません。
他の顧客からの更新
ここまでは、Redisデータベースクライアントが1つしかないという考慮事項から進めました。 実際、多くの顧客が存在する可能性があります。 このような状況では、1つのクライアントがメモリ内キャッシュにデータを保持し、他のクライアントがそれを更新するため、最初のクライアントのデータが無効になります。 この問題を解決する唯一の方法があります-すべてのクライアント間の通信を構成することです。 幸いなことに、Redisはパブリッシャー-サブスクライバーメッセージングエンジンを提供します。 このテンプレートには2種類の通知があります。
キースペース通知
これらの通知は、キーが変更されると自動的にRedisに公開されます。
特別に公開された通知
通知レベルで公開され、クライアントのキャッシュメカニズムの一部として実装されます。 彼らの目標は、キャッシュの個々の小さな部分を無効にするために必要な追加情報でキースペース通知を強化することです。
複数のクライアントで作業することは、キャッシュの問題の主な原因です。
リスクと問題
紛失通知
Redisは、キースペース通知の配信を保証しません。 したがって、通知が失われ、無効なデータがキャッシュに残ります。 これは最も基本的なリスクの1つですが、幸いなことに、このような状況はほとんど発生しません。 ただし、複数のクライアントで作業する場合は、この危険を考慮する必要があります。
解決策:配信が保証されている顧客間で信頼できるメッセージングメカニズムを使用します。 残念ながら、これはまだではないので、代替ソリューションを参照してください。
別の解決策:メモリ内キャッシュを短時間(たとえば1時間)だけ実行します。 この場合、1時間以内にアクセスするすべてのデータの読み込みが速くなります。 通知が失われた場合、この省略はすぐに埋められます。 データベースでDisposeメソッドを呼び出し、再度インスタンス化してフラッシュします。
1つ使用-誰もが使用
1つのクライアントがこのキャッシングレベル(L1)を使用する場合、他のすべてのクライアントはそれを使用して、データが変更された場合に相互に通知する必要があります。
メモリ内データに制限はありません
現時点では、キャッシュできるものはすべてキャッシュに送信されます。 このような状況では、メモリがすぐになくなる可能性があります。 私の場合、これは問題ではありませんが、念頭に置いてください。
おわりに
彼らは、プログラミングには10の複雑な問題しかないと言います。キャッシュの無効化、ネーミング、バイナリシステムです。このプロジェクトは多くの状況で役立つと確信しています。 ライブラリのソースコードはGitHubで入手できます 。 プロジェクトに従って、それに参加してください!