全体として、これはコーネル大学のウェブサイトに掲載された記事の簡単な翻訳であり、いくつかの挿入図があります。
注釈
 Web 2.0の登場以来、インターネットは人々の生活においてより重要な役割を果たし始めています 。 ユーザー間の相互作用により、ソーシャルネットワーク、フォーラム、ブログ、ウィキペディアサイト、および他のインタラクティブな共同開発のメディアリソースを通じて自由に情報を交換できるようになりました。
Web 2.0の登場以来、インターネットは人々の生活においてより重要な役割を果たし始めています 。 ユーザー間の相互作用により、ソーシャルネットワーク、フォーラム、ブログ、ウィキペディアサイト、および他のインタラクティブな共同開発のメディアリソースを通じて自由に情報を交換できるようになりました。
一方、セカンドウェブのコンセプトのすべての欠陥は明らかです。 コンテンツ指向は、同時にネットワークの最も重要なプラスとマイナスになりました。 完全に成長している情報の信頼性と信頼性の問題は、インタラクティブコミュニティの所有者とユーザーが直面しています。 実際の場合と同様に、ネットワークを介して通信するプロセスでは、一部のユーザーが一般に受け入れられている「ネットワーク」エチケットのルールに違反する状況が発生することがあります。 実際、リソースの通常の雰囲気を維持するために、所有者は相互作用の人為的なルールを導入し、コンプライアンスを監視することを余儀なくされています。
これらの露骨な違反の1つはトローリングです。
「トローリング」とは、他の参加者を暗示的または明示的にいじめたり、屈辱したり、by辱したり、しばしばサイトのルールに違反したり、時には「トロール」自体に対してネットワーク相互作用の倫理に違反したりすることによる怒り、対立のコミュニケーション(「トロール」)への参加者の扇動です。 それは攻撃的、,笑的、虐待的な行動の形で表現されます。 認識の可能性のない、認知度の向上、宣伝、とんでもない、匿名のユーザーに興味を持つ擬人化された参加者の両方によって使用されます。 特定のケースでは、「トローリング」は注意を引くための「犠牲者」の挑発です。
この記事では、コンピューティング攻撃者に対する新しいアプローチを提案します。 この方法は、ディスカッションスレッド内の異なるメッセージ間の信頼機能の競合の程度に基づいています。 アプローチの実行可能性を実証するために、人工データでテストします。
最近、情報を取得する方法は、人件費の加速、促進、および削減に大きくシフトしています。 実際、インターネットのおかげで、トピックに関する研究はマウスボタンを1回クリックするだけになりました。 いくつかの問題では、従来の検索エンジンを使用して満足のいく答えを見つけることは困難ですが。 代わりに、専門家の意見を求めています。
その結果、質疑応答コミュニティ(以下、 Q&AC )などの情報相互作用のツールが広く使用されました。 このようなシステムにより、各ユーザーはコミュニティの発展に貢献できます。 残念ながら、すべてのメッセージが信頼できるわけではありません。一部のユーザーは専門家になりすまし、他のユーザーは役に立たないメッセージを発行します。 したがって、これらのコミュニティのモデレーターの仕事は非常に重要なプロセスになります。 ほとんどの場合、「ジャンク」メッセージの増加は、「トロール」のアクションの結果です。
-Q&AC:簡単な概要
A. Q&ACユーザー
ユーザーはQ&ACの主役です。 従来は、「専門家」、「生徒」、「トロール」に分類できます。
専門家:特定の分野の知識またはスキルを持つユーザー。
学生:情報や経験を取得しようとしているユーザー。
トロル:コミュニティの平和を妨害しようとする人。 彼らの目標は、非生産的な議論をすることです。
B. Q&ACのソースの特定
多くの研究は、すでにコミュニティの情報源を評価しようとしました。
一部のユーザーは、最適なユーザー応答の数に基づいてユーザー評価モデルを提供します。 ここでの最良の答えは、要求元のユーザーまたは投票方法によって決まります。
また、著者は、ユーザーが回答するために選択した質問の選択に焦点を当てています。 専門家は常に、より有能な質問に答えることを好みます。
一部の著者は、ユーザーの認知および行動の基準に基づいて複雑な構造を提案し、信頼性だけでなく情報プロバイダーの経験も評価しています。
B. Q&ACの不確実性
人から提供された情報を扱うとき、いくつかのレベルの不確実性に直面しています。 Q&ACには3つのレベルの不確実性があります。 1つ目は不確実性の抽出と統合、2つ目は不確実性の情報源、3つ目は情報の本質です。 私たちの場合、ソースの推定とこれに関連する不確実性の一部により興味があります。 実際、ネットワーク上で他のユーザー(つまり、情報源)に出会うと、それらについての先験的な知識はほとんどありません。
-数学的な装置
不正確な(間隔)専門家の評価、測定、または観測をモデリングおよび処理するための数学的ツールの1つは、 信頼関数の理論です 。
信頼関数の理論またはDempster-Shaferの理論は、「信頼関数」と呼ばれる数学的オブジェクトを使用します。 通常、彼らの主な目標は、特定の対象の何かに対する信頼度をモデル化することです。 同時に、文献には、さまざまな応用問題で使用できる「信頼機能」の解釈が多数あります。
この記事で提案されているアプローチでは、2つの結合された信頼関数の競合を決定する量の導入と併せて、この理論を使用しています。
メソッドの説明に進みましょう。
重要な仮定の1つは、「トロール」がディスカッションの一般的なブランチにのみ統合されることを示唆しています。 メソッドの詳細な説明を3つのステップに分けます。
1.カスタム投稿
研究者は、攻撃、欺ception、ルール違反、成功という「トロール」の基本的な特徴を提供します。 また、道徳的基準の無視、明らかなサディスティックおよび精神障害の傾向などの行動特性を示します。 この作業の文脈において、研究者は「トロール」と他のユーザーの違いをメッセージから手動で区別しました。 これに基づいて、メッセージには関連性、オフトピック、ナンセンス、または悪用があります。 メッセージを特徴付けるフレームワークを定義します。
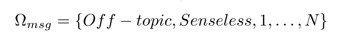
[1]
メッセージの性質は、公開された質問またはトピックに関連して決定されます。 この段階では、メソッドが各メッセージの性質を一意に決定すると想定しています。
2.ユーザーの競合
無関係なメッセージを検出しても、ユーザーが「トロール」コホートに属しているかどうかの質問に対する明確な回答はまだ得られていません。 ユーザーは、poddevkiに傷をつけて応答するだけです。 さらに、議論の主題は徐々に変わるかもしれません。 実際、「トロール」を他のユーザーと区別するために、このユーザーが他のユーザーとどれだけ競合するかを定量的に評価する必要があります。 提案されたアプローチには、各ユーザーのメッセージ間の競合の大きさの測定も含まれます。
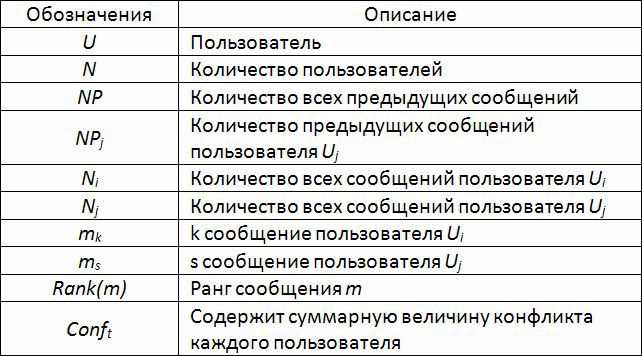
-Conf msg / U :ユーザーU iの k 番目のメッセージと、他のユーザーU jによって書き込まれたメッセージとの間の競合の尺度。
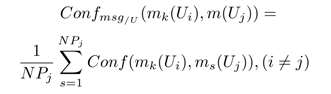
[2]
-Conf msg :ユーザーU iの k 番目のメッセージと、加重平均に基づいて他のすべてのユーザーUによって書き込まれたすべてのメッセージとの間の競合の尺度。 この値は、特に「トロール」とエキスパートの間の競合のレベルを決定するために、各ユーザーによって書き込まれたメッセージの数を考慮します。
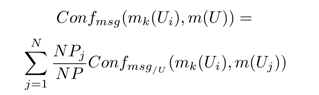
[3]
- ユーザーの構成 :ユーザー競合の一般的な尺度U i
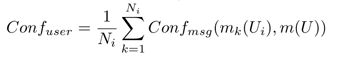
[4]
ユーザーが「トロール」との絶え間ない議論に着手すると、ユーザーの全体的な対立の規模が大きくなる可能性があります。 この場合、ユーザーは被害者となり、モデレーターは多くのスレッドでユーザーの動作を制御する必要があります。
3.ユーザーのクラスタリング
最後のステップは、競合の測定に従ってユーザーを2つのグループに分類することです。 著者は、 K-meansアルゴリズムを使用してユーザーをグループに分類することを規定しています。
k-meansアルゴリズムは、特定のデータセットをユーザー定義のクラスター数kに分割する単純な繰り返しクラスタリングアルゴリズムです。 このアルゴリズムは、実装と実行が簡単で、比較的高速で、適応が容易で、実際には一般的です。 これは歴史的に最も重要なデータマイニングアルゴリズムの1つです。
私たちの場合、クラスターの数: k = 2 。
アルゴリズムの結果として、すべてのユーザーが2つのクラスターに分割されます。 「トロール」は、競合の度合いが最も高いグループと、競合の度合いが最も低い立派なユーザーに分類されます。
-例
次の例を考えてみましょう。
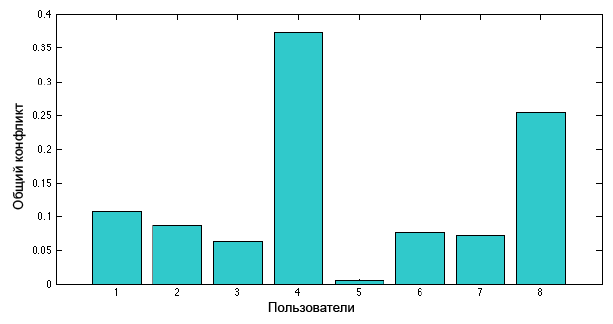
8人のユーザーが書いた31件の投稿を含むディスカッションスレッドの1つを取り上げます。 式[4]で表される各ユーザーの競合の一般的な尺度を次の図に示します。
ユーザーU 1は、ユーザーU 4からのメッセージに応じて、関連する3つのメッセージと物議をかもす2つのメッセージを送信しました。
ユーザーU 2は、ユーザーU 4からのメッセージに応答して、7つの関連メッセージと2つの物議を醸すメッセージを送信しました。
ユーザーU 3は、4つの関連メッセージと1つのオフトピックメッセージをユーザーU 8に送信しました。
ユーザーU 4は2つの物議をかもす投稿を投稿しました。
ユーザーU 5は、関連するメッセージを1つ投稿しました。
ユーザーU 6は、関連する3つの投稿を投稿しました。
ユーザーU 7は、 2つの関連する投稿を投稿しました。
ユーザーU 8は3つの投稿を投稿しました。最初の2つのトピック、1つは物議をかもします。
ユーザー競合U 4の一般的な測定値は、 U 8に比べて大きくなります。これは、2番目のユーザーが他のユーザーからの多数の関連メッセージの後にメッセージを投稿したためです。 したがって、この状況はより高い対立の尺度を示しました。
ユーザーを2つのグループに分割するk-meansアルゴリズムを適用します。

ユーザーU 1 ; U 2 ; U 3 ; いくつかの投稿にもかかわらず、関連する投稿も投稿したため、「トロール」として分類されません。
-結論
ネットワーク上の「トローリング」は、ユーザーによる情報の受信を複雑にする、否定的な、そして何らかの形で破壊的な現象としても明確に定義されています。 現代のオンラインコミュニティの多くは、自主規制のための評価システムを持っていますが、それらのどれもが節度なくしてはできません。 それ自体がコミュニティの所有者のコスト増加につながります。 小さなリソースは主に独自に管理され、大きなリソースは専門家のサポートを余儀なくされます。
この記事では、ユーザーが公開したメッセージの性質によってユーザーの質を判断するための新しい統合アプローチを提案します。 現時点では、著者は1つのディスカッションスレッド(スレッド)の悪意のないユーザーを検索するための方法論を開発しましたが、コミュニティ全体でその作業を拡大する予定です。
トピックを書くとき、記事を役立つだけでなく読みやすくするために、重量のある装置の説明の一部を見逃さざるを得ませんでした。 リンクはまだキャンセルされていないので、トピックに興味がある人はこの単純化を個人的に補うことができます。
残念ながら、1つの記事の枠組みでは、このトピックは非常に広範囲であり、詳細な精緻化により少なくとも候補者が引き出されるため、広大さを把握することは不可能です。 この方法を任意のコミュニティのカルマ式に固定できる場合、ウールのコメントの退屈な義務を取り除く見込みがあります。UFO
していない:
このペーパーでは、「トロール」と他のユーザーの違いを手動で強調しましたが、実際の使用では、このオプションは適切ではありません。 少なくともコメントの見積もりによると、プロセスを自動化できることは明らかです。 Habrの例にアルゴリズムを実装する試みは、主にUFOが非常に小さなコメントを上書きしているという事実により失敗しました。
この方向での作業は継続されます。
Habréでのクラスタリングに関する追加情報: 「クラスタリング:k-meansおよびc-meansアルゴリズム」 。