 モバイルデバイスのカメラを使用して見開きの本を撮影する場合、次の欠陥のいくつかが必然的に発生します(おそらく一度にすべて)。
モバイルデバイスのカメラを使用して見開きの本を撮影する場合、次の欠陥のいくつかが必然的に発生します(おそらく一度にすべて)。
•デジタルノイズ、
•影とハイライト、
•焦点ぼけとグリース、
•スキュー、
•遠近感の歪み、
•曲がった線、
•フレーム内の余分なオブジェクト。
そのような写真を後続のOCRで処理することは、Photoshopのスキルが高い人にとってもかなり時間がかかります。 プログラムを使用してこれを自動的に行いたい場合はどうなりますか? すぐに、アルゴリズムのすべての段階の詳細な説明によって出版物が膨大になりすぎるので、サブ問題の1つを解決する方法-そのような写真のルートラインを見つける方法-のみをお伝えします。 写真の影とまぶしさを除去する方法についてはすでに説明しました。 デジタルノイズの除去について多くの記事が書かれています。 また、遠近法と曲線の自動修正については、次回お話しします。
一見、タスクは難しくありません:勾配演算子(たとえば、Sobel)のいずれかを使用して画像内のすべての輪郭を選択し、ハフ変換を使用して最も強力で最長のものを探します。


右側の画像で最も明るいピクセルを見つけ、その座標から線の方程式を取得する必要があります。 それだけですか? 5-10メガピクセルの画像でこれらすべてを処理しないように、画像を最初に縮小できると誰かが決めるかもしれません。 しかし、何かが簡単に機能するとは限らないことがわかります。 考えられる状況を考慮してください。
ルートには影がありません:

ページには、暗い境界線のある写真があります。

または単に大きな暗い写真:

表:

セパレータ付きの複数列テキスト:

このような状況では、上記の些細なアルゴリズムはしばしば誤解されます。 少し改善して、上記の例を考慮してみましょう。
ルートの弱い影を強調する前処理
画像をグレースケール(グレー)に変換し、UnsharpMaskフィルターに以下のパラメーターを適用します:radius = 41、strength = 300。

テキスト行の向きをすばやく検出
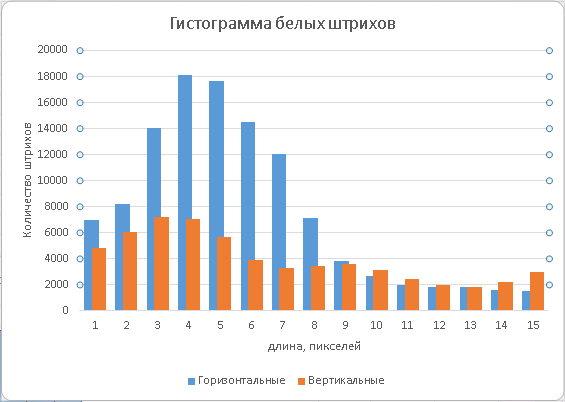
画像を切り取る方向を決定するために、テキストの行の方向を探します。 これは、白いRLEストロークの長さのヒストグラムを使用して、2値化された画像で実行できます。 行間の間隔は、通常、複数行のテキストの文字間の間隔を超えることが知られています(そうでない場合、読みにくくなります)。 ストロークの長さのヒストグラムは、テキストを含む画像の領域にわたって収集する必要があります。 テキストブロックの最も単純な分類子を使用するか、フィールドと背景が収集された統計を「あいまいにしない」ように、画像の端から10〜15%だけ後退します。 あるしきい値Lを超えない長さを持つ水平の白いストロークの面積の合計をS hとして、垂直のストロークの面積の合計をS vとして示します。 次に、しきい値Lを変更して、最大比(S h 、S v )/最小値(S h 、S v )を監視できます。2を超えるとすぐに、文字間隔が見つかったと確信できます。 そして同時に、彼らは線の方向を決定しました:max(S h 、S v )= S hの場合 -それは水平、そうでなければ-垂直。 オリエンテーションを決定する際にあまりにも多くのギャップを作らないようにすると同時に、ミスを頻繁にしないために、比率を2にしました。 この値を変更すると、精度/リコールグラフのさまざまなポイントを取得できます。 同じヒストグラムから追加の機能を使用できます。 方向を明確に単純な方法で決定できない場合、両方向(水平および垂直)でルート(シャドウ)の強力な仮説の検索を開始し、テキストの行の方向をルートの方向に垂直であると評価します。
強い仮説(影)
写真のルート領域に影が写っているとします。 この行を検索する画像を準備します。
a)画像を所定のサイズ、たとえば長辺に沿って最大800ピクセルに縮小します。
b)モルフォロジー演算TopHatを使用して大きな影を取り除きます。元の画像から開口部を減算します。 侵食の蓄積(r = 5)、信号= 1により、黒、白の背景= 0を意味します。
c)垂直侵食(r = 3)を使用してライン(短い垂直黒ストローク)を削除します。
d)前の2つの結果の差として線の画像を受け取った場合、それをペナルティとして使用し、現在の結果に追加します。
a)

b)

c)

d)

最後の画像にクイックハフ変換を適用し、反転した画像でグローバルな最大値を探します。

ルートラインの垂直および水平オフセットからの角度の統計分布を考慮することができます。 原則として、99.9%の場合、角度は絶対値で20〜25度を超えず、ルートラインの中央の座標はw / 3〜2w / 3(wは画像の幅)です。 さらに、角度と座標の極端な値は、平均よりもはるかに低い可能性があります。 この分布は、ハフ空間内のポイントの値で考慮することができ、角度と座標(0、w / 2)で最も可能性の高い位置から逸脱するとペナルティを課します。
見つかったグローバル最大値が強い仮説を検出するためのしきい値を超える場合、シャドウにルートラインが見つかったと見なします。 この場合、最大値の座標を直線の方程式に変換します。 大量の写真サンプルで実験的に選択したしきい値は、エラーと欠落の数を最小限に抑えます。
弱い仮説(クリアランス)
選択したしきい値では、約10%のケースで、強力な仮説を解決できません。 私たちが知っているように、シャドウはルート領域にない場合があります。 これは、枕地が大きく開いている場合、または撮影時にフラッシュが使用された場合に発生する可能性があります。 中心ルーメンの領域でルートラインを見つけてみましょう。
縮小グレースケール画像(a)(Sobel演算子)で勾配係数(b)を計算します。
a)

b)

別の例をここで特別に選択します。 強い影が存在すると、このアルゴリズムに干渉します。
二値化された画像c)では、モルフォロジー膨張演算を使用してテキストをブロックに接着します(サイズが800ピクセルの画像の場合、d = r = 6)。 結果のテキスト領域のマスクを勾配モジュールの画像に適用します(e、信号は4倍に増幅されました)。
c)

d)

e)

次に、テキスト領域のマスク(d)をガウスぼかし(f)(r = 8)で滑らかにし、それに非テキスト領域(g)の強化されたグラデーションを追加します。
f)

g)

これで、ルートラインに弱い勾配さえ含まれている場合、ルーメン領域の信号に追加の寄与を与える画像が得られました。 勾配がない場合、つまり 画像に目に見える線がない場合、ガウスぼかしのため、両側のテキストからかなり離れた線を選択します。 狭いルートでは、ほぼ中央を通過します。
線を検索するために、再びハフ変換を適用し、角度とオフセットの統計的分布を考慮して、グローバルな最大値を探します。

最大座標はルートライン方程式に変換されます。 できた!
本の見開き1800枚以上の写真を自由に使用できるように提示された単純なアルゴリズムは、エラーの1.5%未満です。
もちろん、それを改善する多くの機会があります:画像内の追加の特徴を強調表示し、2つの仮説を順番に計算するのではなく、一度に複数の仮説を計算し、それらの相対的な位置を評価し、画像内のオブジェクト(ライン、セパレーター)を選択して分析することができます...再トレーニングの可能性を回避するために、トレーニング(およびテスト!)サンプルをもう一度拡張する必要があります。 これはすべて、アルゴリズムの品質に対する無限の闘争です。
背骨線を見つける問題を解決するために、言うのを忘れていましたが、なぜそれが必要なのでしょうか? 写真でこの行を探す必要があるのはなぜですか? 非常に簡単:背骨線はスキューを排除します。 この線が垂直になるように画像を回転し、線拡張アルゴリズムの後続の適用のために画像を2ページに分割し、遠近歪みを特定するのに役立ちます(ただし、遠近のより多くの消失点を見つける必要があります)。 一般に、この問題を解決せずに、後続のOCR用にそのような写真を準備することはほとんど不可能です。 これらのアルゴリズムは、すでにABBYY FineScannerモバイルアプリケーションの一部であるBookScanテクノロジーで使用されています。