
みなさんこんにちは!
今日は、ドメイン名生成アルゴリズムを使用して生成されたドメインの認識について説明します。 既存のメソッドを見てみましょう。また、リカレントニューラルネットワークに基づいて独自のメソッドを提供します。 面白い? 猫へようこそ。
ドメイン名生成アルゴリズム(DGA)は、マルウェアがコマンドセンターとの接続を確立できるようにする多数の擬似ランダムドメイン名を生成するために使用するアルゴリズムです。 したがって、マルウェアインフラストラクチャの強力な保護層を提供します。 一見すると、接続を確立するために多数のドメイン名を作成するという概念は複雑に思えませんが、任意の文字列を作成するために使用される方法は、難読化のさまざまなレイヤーの後ろに隠れていることがよくあります。 これは、リバース開発のプロセスを複雑にし、特定のアルゴリズムファミリーの機能のモデルを取得するために行われます。
たとえば、最初のケースの1つは、2008年のConfickerコンピュータワームでした。 今日、このような悪意のあるプログラムが多数あり、それぞれが深刻な脅威をもたらしています。 さらに、アルゴリズムは改善されており、その検出はより困難になっています。
仕事の一般原則
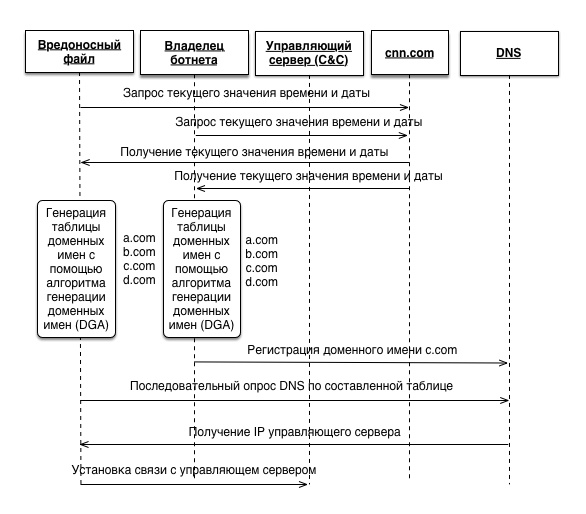
一般に、悪意のあるファイルには、疑似乱数ジェネレーター(PRNG)を初期化するためのシードが必要です。 悪意のあるファイルとボットネットの所有者に知られるパラメータはすべてシードとして機能します。 私たちの場合、これはcnn.comから取得した現在の日時の値です。 同じ初期化ベクトルを使用して、悪意のあるファイルとボットネットの所有者は同一のドメイン名テーブルを受け取ります。 その後、ボットネットの所有者が1つのドメインのみを登録するだけで、悪意のあるファイルがDNSサーバーに再帰的にクエリを送信し、管理サーバーのIPアドレスを受信して、さらに接続してコマンドを受信します。
認識
現在、ドメイン名生成アルゴリズムの分析に関連する多くの作品があります。 それらのいくつかは、機械学習法を使用しています。 基本的に、これらは、n-gram、TF-IDFなどの自然言語の処理および分析の環境で見られるよく知られたモデルを使用します。
ただし、トレーニングサンプルの問題が発生します。 サンプルは2つのクラスで構成されます。 最初の合法性は、Alexa Top Millionリストから選ばれました。 2番目-DGAは、リバースエンジニアリングアルゴリズムによってコンパイルされ、インターネット上に存在し、リポジトリ( https://github.com/andrewaeva/DGA )で利用可能な悪意のあるプログラムのコピーから取得された悪意のあるドメイン名を生成します。
始めるために、Clicksecurityの担当者が説明したアプローチを試しました。 彼らは、次のパラメータのリストの使用を提案します:長さ、エントロピー、N-gram選択のあるTF-IDFモデル。 最初のパラメーターは、ドメイン名の長さです。 2番目のパラメーターはエントロピーです。 次に、N-gramモデルを検討しました。 各n-gram(3〜5)はn次元空間のベクトルとして表され、それらの間の距離はこれらのベクトルのスカラー積を使用して計算されました。 Scikit Learnライブラリを使用すると、これは非常に簡単です。
import numpy as np from sklearn.feature_extraction.text import CountVectorizer alexa_vc = CountVectorizer(analyzer='char', ngram_range=(3, 5), min_df=1e-4, max_df=1.0) counts_matrix = alexa_vc.fit_transform(dataframe_dict['alexa']['domain']) alexa_counts = np.log10(counts_matrix.sum(axis=0).getA1()) dict_vc = CountVectorizer(analyzer='char', ngram_range=(3, 5), min_df=1e-5, max_df=1.0) counts_matrix = dict_vc.fit_transform(word_dataframe['word']) dict_counts = np.log10(counts_matrix.sum(axis=0).getA1()) all_domains['alexa_grams'] = alexa_counts * alexa_vc.transform(all_domains['domain']).T all_domains['word_grams'] = dict_counts * dict_vc.transform(all_domains['domain']).T all_domains['diff'] = all_domains['alexa_grams'] - all_domains['word_grams']
その結果、3つのパラメーターが追加されました:Alexa gram-Alexa Top Millionドメインで構成される辞書までのコサイン距離、Word gram-最も一般的な単語とフレーズで構成される特別に構成された辞書までのコサイン距離、およびパラメーターdiff = alexa gram-単語グラム。
各パラメーターについて、視覚的なチャートを作成しました。 見ることを忘れないでください:)
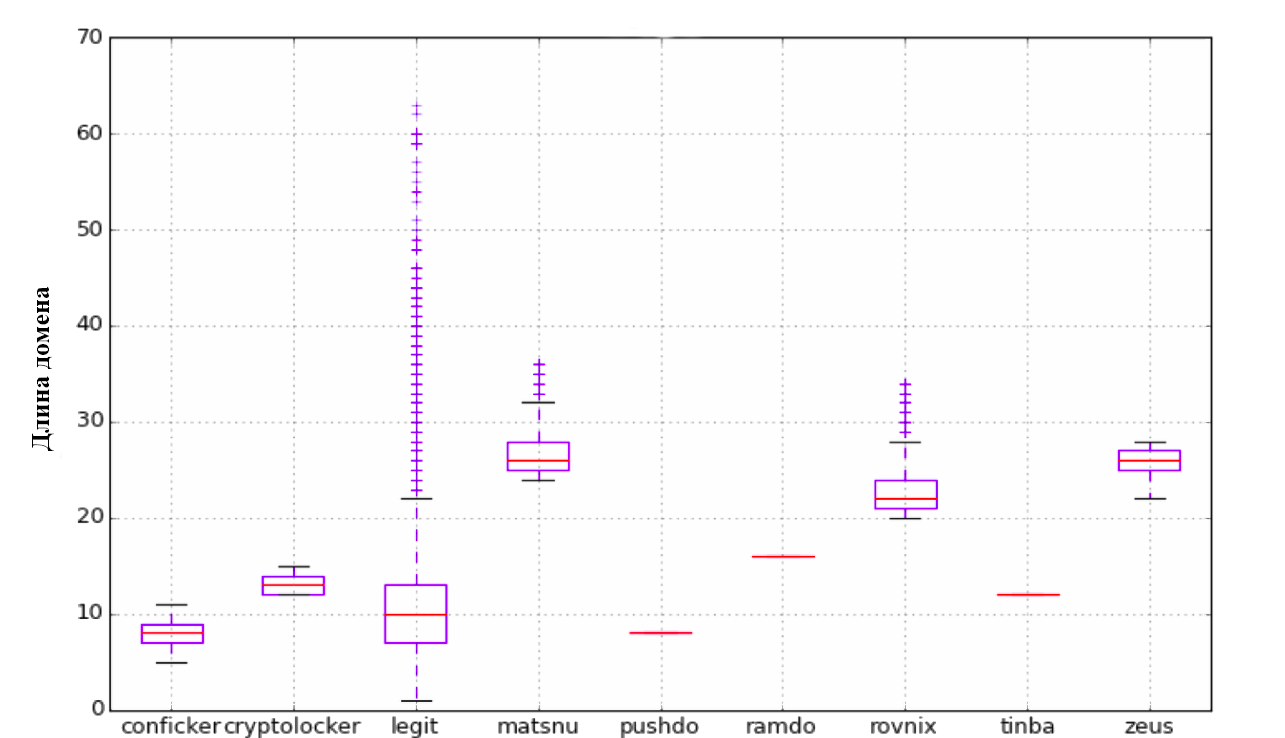
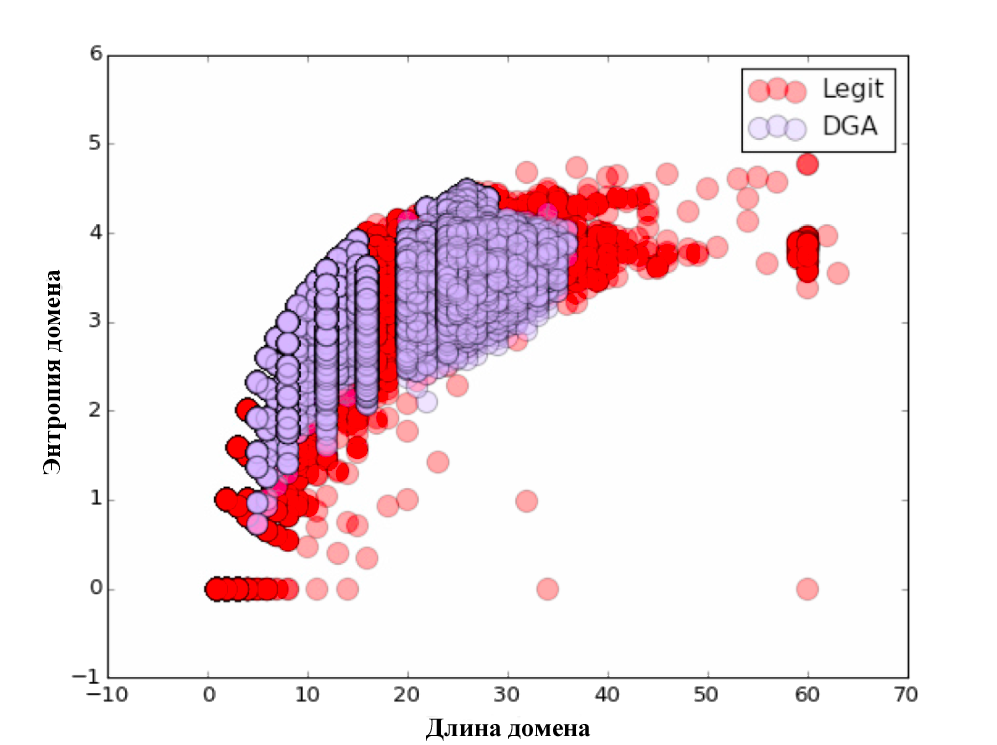

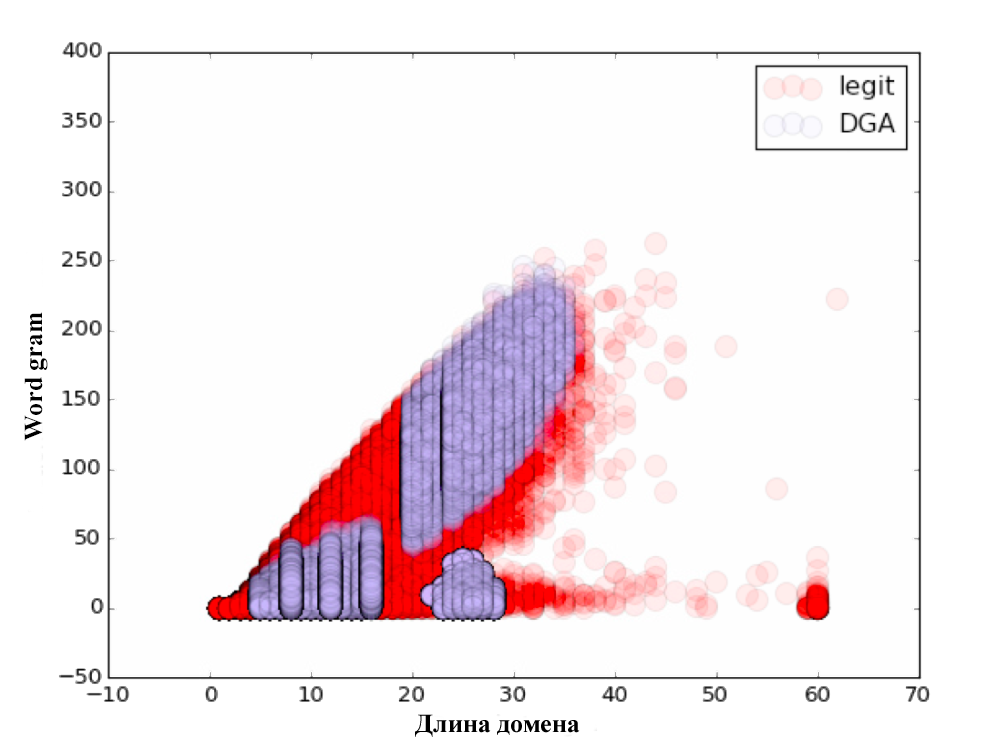
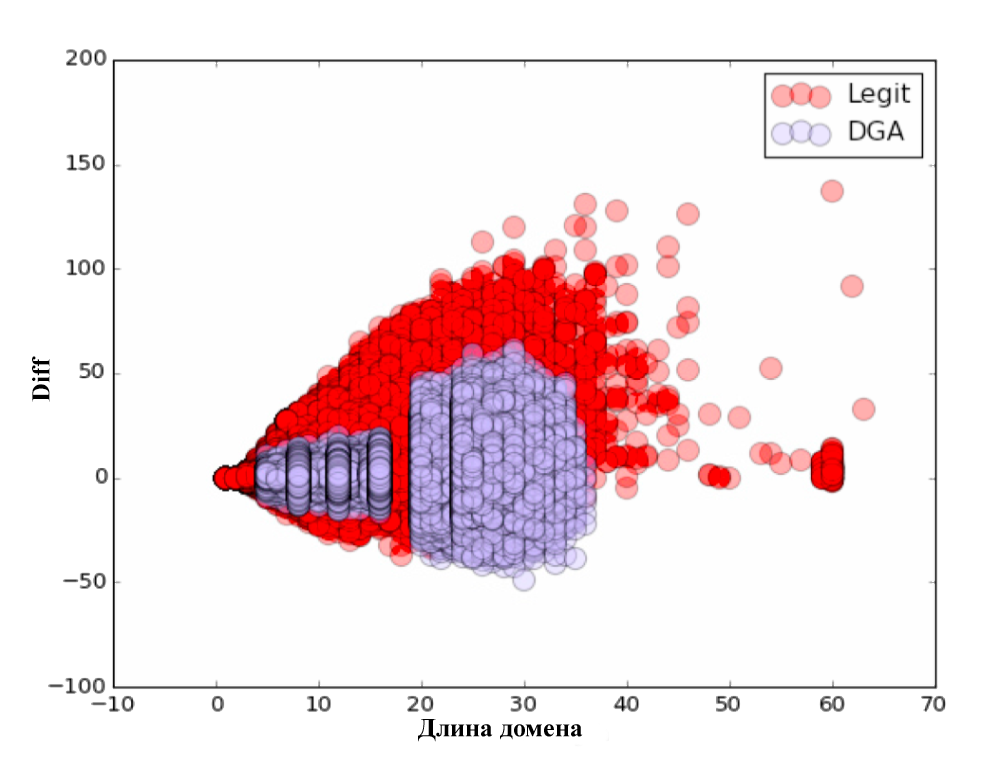
分類自体は、80/20の原則に従って実行されました。 初期データの80%でトレーニングが行われ、残りの20%でアルゴリズムがテストされました。 分類の品質を確認した後、次の結果が得られました。
| アルゴリズム | 分類精度 |
|---|---|
| ロジスティック回帰 | 87% |
| ランダムフォレスト | 95% |
| ナイーブベイズ | 75% |
| 余分な木の森 | 94.6% |
| 投票分類 | 94.7% |
なぜこれまで誰もニューラルネットワークを使用しようとしていないのかと考えました。 試す必要があります!
ニューラルネットワーク
問題を解決するために、リカレントニューラルネットワークを使用しました。 リカレントニューラルネットワークは、主にサイクルの存在によって区別されます。 これらを使用すると、ニューラルネットワークの前のステップで取得した情報を保存して使用できます。 この場合の各ドメインは、固定ディクショナリからの文字のシーケンスと見なされ、リカレントニューラルネットワークの入力に供給されます。 このようなニューラルネットワークのトレーニングは、対応するクラスの正しい選択の確率を最大化するような方法でエラーの逆伝播の方法によって実行されます。
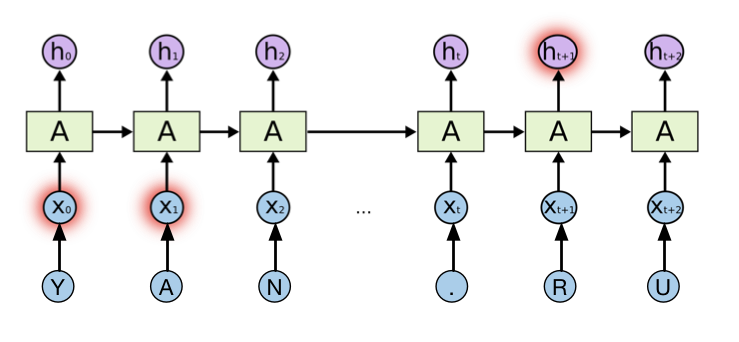
再帰的ニューラルネットワークとYandex.ru
このようなニューラルネットワークアーキテクチャは、特定の時間に以前にデータ分析のために送信された情報を分析できます。 ただし、実際には、過去の情報と現在の情報とのギャップが十分に大きい場合、この接続は失われ、そのようなネットワークは処理できません。 この問題の解決策は、1997年にHochreiter&Schmidhuberの科学者によって発見されました。 彼らの研究で、彼らはリカレントニューラルネットワークの新しいモデル、すなわちロングショートサームメモリを提案しました。 現在、このモデルは、音声認識、自然言語処理など、さまざまなクラスの問題を解決するために広く使用されています。LSTMは、メモリブロックと呼ばれる多数の永続的に接続されたサブネットで構成されます。 ニューラルネットワークの単一層の代わりに、このモデルは特別な方法で相互作用する4つの層を使用します。 このモデルでは、LSTMモデルのバリアント、つまりGated Recurrent Unit(GRU)を使用します。 LSTMとGRUの詳細については、すばらしい記事( http://colah.github.io/posts/2015-08-Understanding-LSTMs/ )を参照してください 。これから先に進みます。
モデルを実装するには、Pythonとみんなのお気に入りのライブラリTheano( https://pypi.python.org/pypi/Theano )とLasagne( https://pypi.python.org/pypi/Lasagne/0.1 )を使用します。
データをメモリにロードし(はい、怠け者です)、前処理します。
import numpy as np import pandas as pd import theano import theano.tensor as T import lasagne dataset = pd.read_csv('/home/andrw/dataset_all_2class.csv', sep = ',') dataset.head() chars = dataset['domain'].tolist() chars = ''.join(chars) chars = list(set(chars)) print chars # ['-', '.', '1', '0', '3', '2', '5', '4', '7', '6', '9', '8', '_', 'a', 'c', 'b', 'e', 'd', 'g', 'f', 'i', 'h', 'k', 'j', 'm', 'l', 'o', 'n', 'q', 'p', 's', 'r', 'u', 't', 'w', 'v', 'y', 'x', 'z'] classes = dataset['class'].tolist() classes = list(set(classes)) print classes #['dga', 'legit']
ここで、ドメインをシーケンスにエンコードし、配列X、y、マスクMを形成します。なぜマスクが必要なのですか? 簡単です、カール! さまざまな長さのドメイン。
char_to_ix = { ch:i for i,ch in enumerate(chars) } ix_to_char = { i:ch for i,ch in enumerate(chars) } class_to_y = { cl:i for i,cl in enumerate(classes) } NUM_VOCAB = len(chars) NUM_CLASS = len(classes) NUM_CHARS = 75 N = len(dataset.index) X = np.zeros((N, NUM_CHARS)).astype('int32') M = np.zeros((N, NUM_CHARS)).astype('float32') Y = np.zeros(N).astype('int32') for i, r in dataset.iterrows(): inputs = [char_to_ix[ch] for ch in r['domain']] length = len(inputs) X[i,:length] = np.array(inputs) M[i,:length] = np.ones(length) Y[i] = class_to_y[r['class']]
トレーニングとテストのサンプルを作成します。
rand_indx = np.random.randint(N, size=N) X = X[rand_indx,:] M = M[rand_indx,:] Y = Y[rand_indx] Ntrain = int(N * 0.75) Ntest = N - Ntrain Xtrain = X[:Ntrain,:] Mtrain = M[:Ntrain,:] Ytrain = Y[:Ntrain] Xtest = X[Ntrain:,:] Mtest = M[Ntrain:,:] Ytest = Y[Ntrain:]
これで、図に示すように、ネットワークのアーキテクチャを説明する準備がすべて整いました。 分類のために、最後の隠れ層の状態をSoftmax層に転送します。この出力は、クラスの1つ(悪意のあるまたは正当な)に属するドメインの確率として解釈できます。

BATCH_SIZE = 100 NUM_UNITS_ENC = 128 x_sym = T.imatrix() y_sym = T.ivector() xmask_sym = T.matrix() Tdata = np.random.randint(0,10,size=(BATCH_SIZE, NUM_CHARS)).astype('int32') Tmask = np.ones((BATCH_SIZE, NUM_CHARS)).astype('float32') l_in = lasagne.layers.InputLayer((None, None)) l_emb = lasagne.layers.EmbeddingLayer(l_in, NUM_VOCAB, NUM_VOCAB, name='Embedding') l_mask_enc = lasagne.layers.InputLayer((None, None)) l_enc = lasagne.layers.GRULayer(l_emb, num_units=NUM_UNITS_ENC, name='GRUEncoder', mask_input=l_mask_enc) l_last_hid = lasagne.layers.SliceLayer(l_enc, indices=-1, axis=1, name='LastState') l_softmax = lasagne.layers.DenseLayer(l_last_hid, num_units=NUM_CLASS, nonlinearity=lasagne.nonlinearities.softmax, name='SoftmaxOutput') output_train = lasagne.layers.get_output(l_softmax, inputs={l_in: x_sym, l_mask_enc: xmask_sym}, deterministic=False) total_cost = T.nnet.categorical_crossentropy(output_train, y_sym.flatten()) mean_cost = T.mean(total_cost) #accuracy function argmax = T.argmax(output_train, axis=-1) eq = T.eq(argmax,y_sym) acc = T.mean(eq) all_parameters = lasagne.layers.get_all_params([l_softmax], trainable=True) all_grads = T.grad(mean_cost, all_parameters) all_grads_clip = [T.clip(g,-1,1) for g in all_grads] all_grads_norm = lasagne.updates.total_norm_constraint(all_grads_clip, 1) updates = lasagne.updates.adam(all_grads_norm, all_parameters, learning_rate=0.005) train_func_a = theano.function([x_sym, y_sym, xmask_sym], mean_cost, updates=updates) test_func_a = theano.function([x_sym, y_sym, xmask_sym], acc
サンプルを100個のドメイン名のバッチに分割して、モデルをトレーニングします。 その結果、次のグラフが得られます。
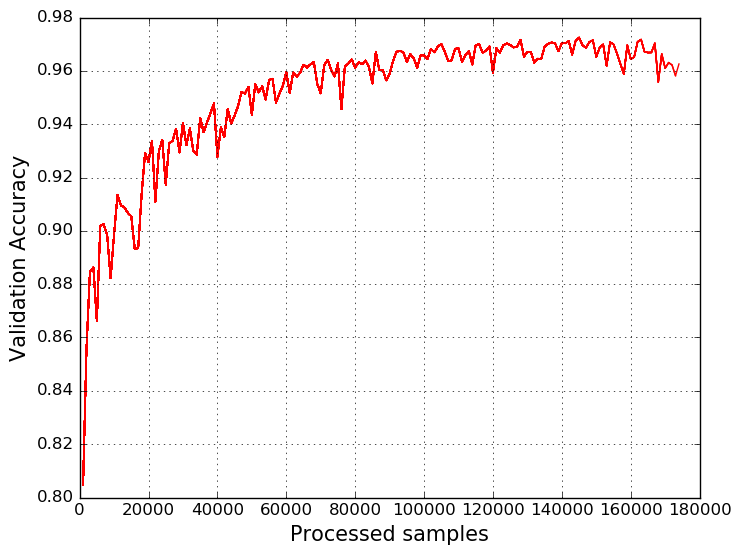
結論として、結果のモデルはランダムフォレストアルゴリズムに決して劣らず、それを上回っているとさえ言えます。 さらに、たとえば、ドメイン名に逆パスを追加するか、アテンションLSTMをモデルに含めることにより、モデルをさらに改善できます。 さて、情報セキュリティの機械学習のトピックについては、すべてが始まったばかりです:)
参照資料
- https://github.com/ClickSecurity/data_hacking/blob/master/dga_detection/DGA_Domain_Detection.ipynb
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://github.com/andrewaeva/DGA/
- http://openbooks.ifmo.ru/en/collections_article/997/raspoznavanie_i_klassifikaciya_vredonosnyh_domennyh_imen.html
- http://openbooks.ifmo.ru/en/collections_article/4053/analiz_algoritmov_generacii_vredonosnyh_domennyh_imen_i_metody_ih_raspoznavaniya_s_ispolzovaniem_rekurrentnyh_neyronnyh_setey.htm
Abakumov Andrey、デジタルセキュリティ