
私の名前はTkachev Konstantinです。私は応用ソリューションのアーキテクトとして働いています。
まえがき
Pythonで実装されたscikit-learn(sklearn)機械学習ライブラリの例を使用して、Splunkプラットフォームの既存の機能を拡張する方法についてお話したいと思います。 この例では、決定木アルゴリズムを使用します。 このアルゴリズムは標準のSplunkパッケージには含まれていません。以下では、かなり簡単な手順を実行することで、アプリケーションタスクを実装するために接続できることを示します。
仕事の目的
したがって、最初に作業の目的を決定します。 目的:Splunkの機能を拡張して個々のアプリケーションを解決する方法を特定します。 同時に、重要なこととして、次のものが必要です。
- Splunkをデータソースとして使用する
- また、Splunkインターフェースで計算結果を表示します。
制限事項
Pythonを使用して作業を実装します。 Pythonを支持して選択が行われたのは、 これは標準のSplunkパッケージの一部であり、機械学習で使用される最も一般的なプログラミング言語の1つです。 さらに、このプログラミング言語は大部分のLinuxおよびMacOSディストリビューションに含まれています。
アプリケーションの説明
可能なアプリケーションとして、次のオプションを検討することを提案します。
1.パラメーターによる顧客の分類:
a。 クライアントが最後に小売店を訪問した時間。 このパラメーターをR(Recency)と呼びます。
b。 小売店での顧客の購入頻度。 このパラメーターをF(周波数)と呼びます。
与えられた:
購入頻度F(頻度)には、最後の訪問時間R(最新)の依存関係(分布則)があります。
この流通法に従って、顧客は3つのカテゴリに分類されます:「有望」、「通常」、「無望」。
チャレンジ:
カテゴリが指定されていない顧客の最後の訪問時間R(最新)と購入頻度F(頻度)のデータに基づいて、顧客のカテゴリを決定する必要があります。
2.パラメータに応じた支払いゲートウェイのステータスの分類:時刻(頻度-1時間)、1時間あたりのリクエスト数。
与えられた:
時刻(時間ごとにグループ化)での1時間あたりの支払いゲートウェイの要求数には依存関係(配布法)があります。
この分配法に従い、条件は「穏やか」、「正常」、「重大」となります。
チャレンジ:
ステータスが不明な値については、時刻と1時間あたりのリクエスト数に関する情報に基づいて、支払いゲートウェイのステータスを判断する必要があります。
もちろん、分類問題の実装は他の方法で実行できます。 私たちの目標は、アルゴリズムにSplunk機能をすばやく簡単に追加する方法を示すことです。 特に、決定木法の分類を使用します。
実装
アプローチの説明
Splunkには、SPL(Splunk Processing Language)言語で独自の検索コマンドを開発するために使用されるPythonインタープリターと、Splunk APIと対話するためのPython SDKが含まれています。
実装の主なアイデアの1つは、Splunkの一部であるPythonインタープリターから独自のアルゴリズムの実行を「分離」することです。 これを行うために、2つの個別のPythonモジュールを実装します。
1. Splunk(または、そのPythonインタープリター)によって使用される「ラッパーモジュール」。 このモジュールの機能:
a。 検索チームSplunk SPLの実装。
b。 Splunkおよび独自のアルゴリズムを実装するモジュールとの対話の構成。
2.独自のアルゴリズムの実装が実装されるモジュール。 Pythonのシステムインストールがこのモジュールの実行に使用されます。

このアプローチの長所と短所を以下に示します。
利点:
-SPLコマンドとアルゴリズムを実装するモジュールを個別に実装する「ラッパーモジュール」の実装により、Splunkとアルゴリズムの「強力な」接続性を削減します。
-システムPython内でSplunkからアルゴリズムを個別に開発およびテストできます。
-Splunkを更新しても、アルゴリズムの機能には影響しません。
-Splunkは特定のPythonライブラリでオーバーロードされません。
短所:
-モジュール間の相互作用に必要なコードの冗長性。 パラメーター(引数)としてモジュール間で転送されるデータを使用して、追加の変換を実行する必要があります。
-パラメーター(引数)として使用されるデータの追加変換に関連する一般的なソリューションのパフォーマンスの低下の可能性。
将来、おそらく必要な外部ライブラリをSplunkが使用するPythonインタープリターに接続するでしょう。
実装手順
利用規約
1. Ubuntu OSの実装例が提供されています。
2.標準のSplunkアプリケーションのフレームワーク-「検索とレポート」でタスクを実行します。 私の場合、実行に必要なファイルは「/ opt / splunk / etc / apps / search」というパスにあります。
システムPythonを構成する
「出発点」として、独自のアルゴリズムを実行するPythonシステム環境を構成します。 これを行うために、必要なライブラリをインポートします。 私たちの場合、「決定木」のアルゴリズムを使用していることを思い出させてください。 Ubuntuでは、これはapt-getコマンドで実現できます。 使用した例は次のとおりです。
apt-get install python-numpy python-scipy python-pandas
その結果、「決定木」を使用して分類アルゴリズムを実装するための準備されたシステムPython環境を手に入れました。
Splunkセットアップ
すべてのSplunk設定は、設定ファイルのcommands.confを作成/変更することです。 このファイルでは、Splunkコマンドの名前と、このコマンドを実装するPythonの「ラッパーモジュール」を指定する必要があります。 構成ファイルは、「/ opt / splunk / etc / apps / search / local」フォルダーに配置する必要があります。
Pythonモジュールの開発
ここで、作業と元のデータ形式の要件について簡単に説明します。 モジュールの起動は、コマンド「| dtree」を呼び出すことによってSplunkから開始され、その入力は次の構造に転送される必要があります:X、Y、クラス。 XとYが分布法則である場合(「適用される問題の説明」セクションの例を参照)、Classは分類です。 モデルは「クラス」フィールドの既存の値でトレーニングされ、モデルはクラスフィールドの値が空のレコードの分類を決定します。 Splunkで「| dtree」コマンドを呼び出すと、対応する「スクリプトラッパー」(dtree.py)が起動し、これにより、分類アルゴリズムの実装(dtree_lib.py)でスクリプトが呼び出されます。
「ラッパーモジュール」のコードとアルゴリズムを実装するモジュールは、「付録」に記載されています。
コードには、例外的な状況、エラー処理などを管理するために必要な構造が含まれていないことに注意してください。 例は、アプローチを示すために最低限必要な手順を示しています。
Splunkの再起動
上記の手順が完了したら、Splunkを再起動する必要があります。 その後、作成したチームの使用に進むことができます。
使用する
作成したチームを使用するには、Splunkのデータを準備した後、Splunkの検索行にチームの名前「| dtree」を入力する必要があります。
Splunk検索クエリの結果を入力として使用できます。 その結果、私たちのチームは「入力」にデータ形式を提出する必要があります。これは「Pythonモジュールの開発」セクションに示されています。
事前にcsvファイルに初期データを用意しました。 以下に、表形式および分布グラフの形式で示します。
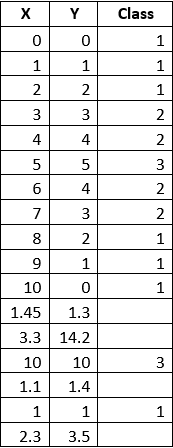
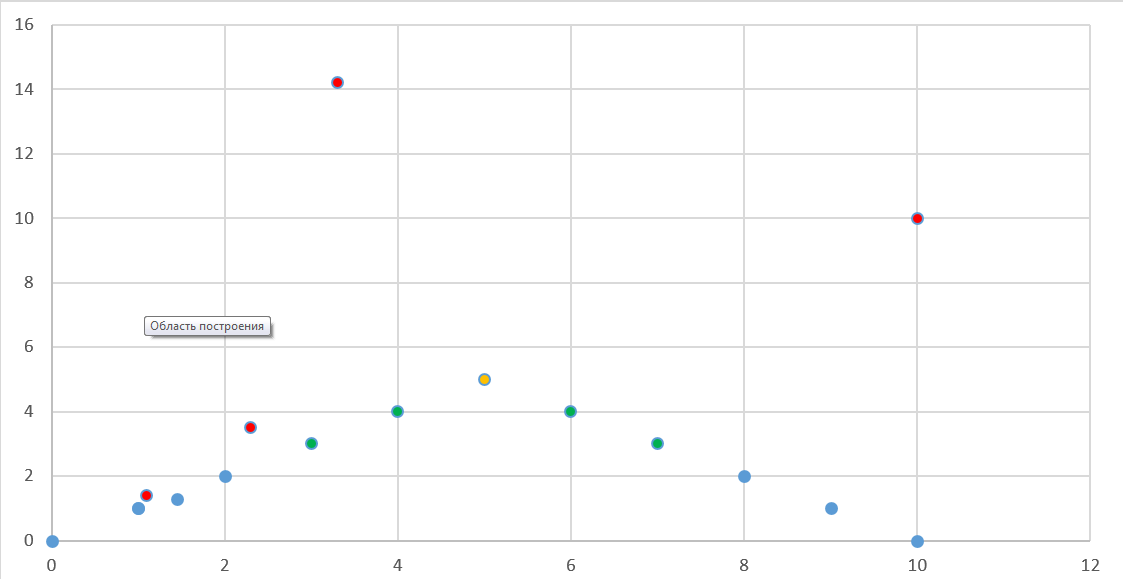
「クラス」フィールドの空の値(グラフ上の赤い点)については、「決定木」法による分類を決定します。
Splunkでデータを表示するには、コマンド| inputlookup dtree.csvを実行する必要があります。 以前は、csvファイルは「/ opt / splunk / etc / apps / search / lookups」フォルダに配置されていました。

以下のSplunkが作成した分布図。

コマンド「| inputlookup dtree.csv | dtree」を実行してアルゴリズムを実行します。 彼女の仕事の結果を以下に示します。 「クラス」フィールドが空だったXおよびYのクラスが定義されています(「予測」フィールドを参照)。

Splunk標準機械学習機能
さらに、機械学習の分野でSplunkの利用可能な機能に注目したいと思います。 Splunkには、予測分析と機械学習の機能を実行するための豊富なコマンドライブラリが含まれています。
>相関関係;
>クラスタリング(kはクラスターを意味します);
>連想ルール。
>分類と予測(ベイジアン分類、線形およびロジスティック回帰、SVM);
>異常を検索します。
>主成分分析(PCA)。
以下の表で引用したコマンドの一部。
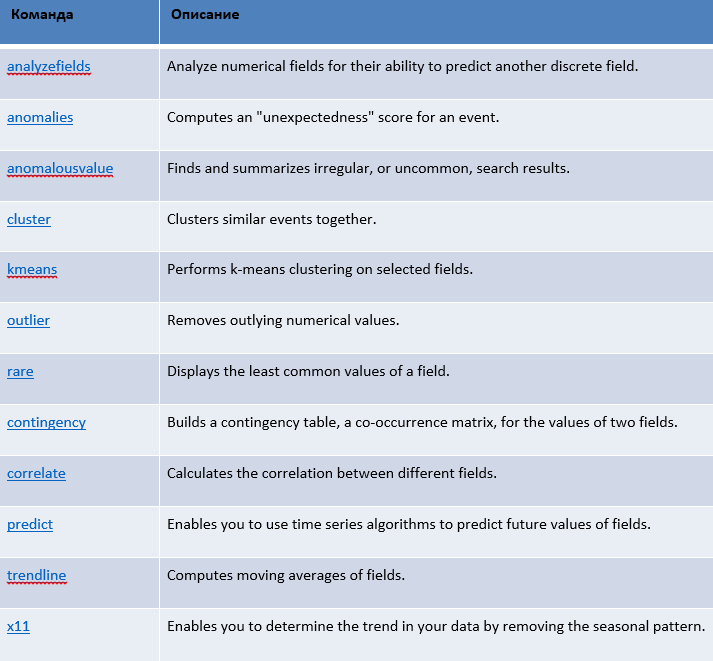
また、ML ToolkitとShowcaseというアプリケーションも利用できます。これは、便利なインターフェイスで、ユーザーが機械学習機能を実行できる機能を提供し、既製のサンプルセットを含んでいます。

おわりに
ご清聴ありがとうございました。 この記事がお役に立てば幸いです。 この出版物のビデオへのリンクはwww.youtube.com/watch?v=uVPaLWbXW1E&feature=youtu.beです。
アプリ
commands.conf
commands.confファイルの内容を以下に示します。
[dtree]
タイプ= python
ファイル名= dtree.py
生成= false
ストリーミング= false
retainsevents = false
ソースコード
モジュールラッパー(dtree.py)
import os import sys import subprocess import splunk.Intersplunk #---Get data from Splunk--- results,unused1,unused2 = splunk.Intersplunk.getOrganizedResults() #---Prepare data--- str_X="" str_Y="" str_Class="" predict_X="" predict_Y="" cnt=0 delim="" for result in results: if result["Class"]=="": predict_X=predict_X+","+result["X"] predict_Y=predict_Y+","+result["Y"] else: if cnt>=1: delim="," str_X=str_X+delim+result["X"] str_Y=str_Y+delim+result["Y"] str_Class=str_Class+delim+result["Class"] cnt=cnt+1 #---Call python module with required functionality _NEW_PYTHON_PATH = '/usr/bin/python' os.environ['PYTHONPATH'] = '/opt/splunk/lib/python2.7' _SPLUNK_PYTHON_PATH = os.environ['PYTHONPATH'] os.environ['PYTHONPATH'] = _NEW_PYTHON_PATH my_process = os.path.join(os.getcwd(), '/home/konstantin/Documents/dtree_lib.py') p = subprocess.Popen([os.environ['PYTHONPATH'], my_process, _SPLUNK_PYTHON_PATH,str_X,str_Y,str_Class,predict_X,predict_Y], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) output = p.communicate()[0] #---Print results--- #splunk.Intersplunk.outputResults(results) print output
「決定木」アルゴリズム(dtree_lib.py)を実装したモジュール
import sys from sklearn import tree #---Get data--- X=sys.argv[2] Y=sys.argv[3] Class=sys.argv[4] predict_X=sys.argv[5] predict_Y=sys.argv[6] #---Prepare data--- X=X.split(",") Y=Y.split(",") Class=Class.split(",") predict_X=predict_X.split(",") predict_Y=predict_Y.split(",") predict=list(zip(predict_X,predict_Y)) new_X=list(zip(X,Y)) new_Y=Class #---Call Machine Learning function--- clf = tree.DecisionTreeClassifier() clf = clf.fit(new_X, new_Y) result=clf.predict(predict[1:]) #---Print results--- print '{},{},{}'.format("Predicted","X","Y") for line,(x,y) in zip(result,predict[1:]): print '{},{},{}'.format(line, x, y)