
先週Clarifaiで、 わいせつなコンテンツ認識モデル(NSFW、Not Safe for Work)を正式に発表しました。
警告および免責事項。 この記事には、科学的な目的で裸体の画像が含まれています。 18歳未満の人やヌードに腹を立てている人は、これ以上読まないようにしてください。
ヌード写真を自動的に検出することは、20年以上にわたってコンピュータービジョンの中心的な問題であり、その豊かな歴史と明確に定義されたタスクにより、テクノロジーの進化の素晴らしい例となっています。 わいせつ検出問題を使用して、現代の畳み込みネットワークのトレーニングが過去の研究とどのように異なるかを説明します。
1996年に戻って...

この分野の最初の作品の1つは、マーガレットフレック他による「裸の人々を探す」というシンプルでわかりやすいタイトルでした。ネットワーク。 科学記事のパート2では、技術の一般的な説明を提供します。
アルゴリズム:
- 最初に、肌色のピクセルの大きな領域を持つ画像を見つけます。
- 次に、これらの領域で、細長い領域を見つけて、オブジェクトの構造に関する大量の情報を含む特殊なグループ化モジュールを使用して、人間の手足または手足の結合グループにグループ化します。
肌は色空間をフィルタリングすることで検出され、肌の領域は人間の姿を「ほぼ円筒形のパーツのセットとしてモデル化することでグループ化されました。パーツの個々の輪郭とパーツ間の接続はスケルトンジオメトリによって制限されます(セクション2)」。 このようなアルゴリズムを開発する方法は、著者がいくつかの手動のグループ化ルールを示した科学記事で図1を調べると、より理解しやすくなります。
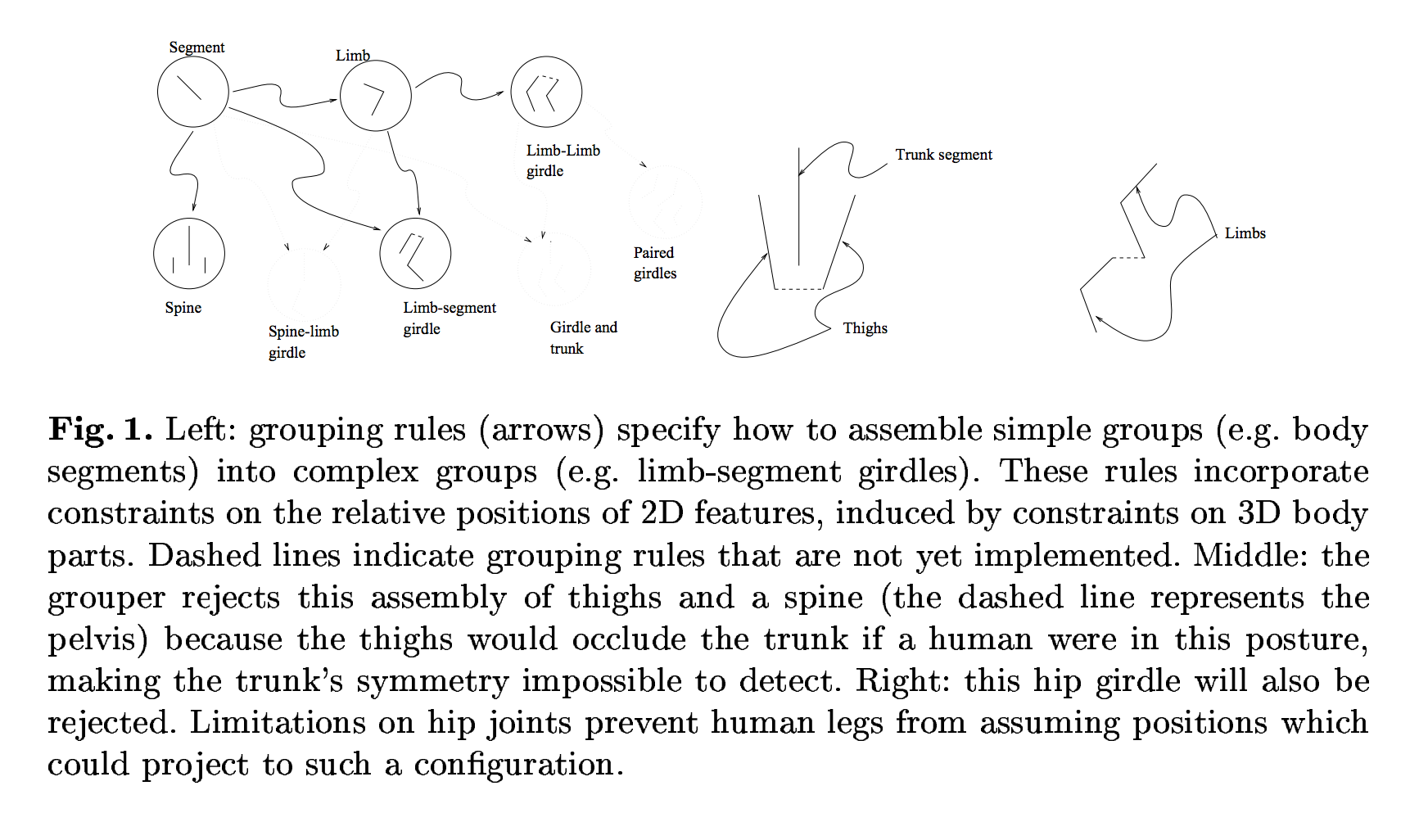
科学記事には、「138枚のヌード画像の制御されていないサンプルの認識精度が60%、リコールが52%」と書かれています。 著者はまた、アルゴリズムが処理した領域を視覚化して、正しく認識された画像と誤検知の例を示しています。


ルールを手動で作成する場合の主な問題は、モデルの複雑さが研究者の忍耐と想像力によって制限されることです。 次のパートでは、同じタスクを実行するようにトレーニングされた畳み込みニューラルネットワークが、同じデータのはるかに複雑な表現をどのように示すかを見ていきます。
今2014年に...
入力データの表示方法を記述するための正式なルールを作成する代わりに、ディープラーニングの研究者は、AIシステムがデータからこれらの表現を直接習得できるネットワークアーキテクチャとデータセットを考え出します。 しかし、研究者が与えられた入力データにネットワークがどのように応答すべきかを正確に示していないという事実のために、新しい問題が発生します:ニューラルネットワークが何に応答するかを正確に理解する方法?

畳み込みニューラルネットワークの動作を理解するには、さまざまなレベルで属性のアクティビティを解釈する必要があります。 この記事の残りの部分では、NSFWモデルの初期バージョンを検討し、入力のトップレベルからピクセルスペースのレベルまでのアクティビティを強調します。 これにより、どの特定の入力パターンが機能マップで特定のアクティビティを引き起こしたかを確認できます(つまり、実際に画像が「NSFW」としてマークされている理由)。
スクリーニングに対する感受性
下の図は、NSFWモデルのステップ3で64x64スライドウィンドウを元の画像のトリミングされたバージョンまたは不明瞭なバージョンに適用した後のLenaSöderbergの写真を示しています。

左側にヒートマップを作成するために、各ウィンドウを畳み込みニューラルネットワークに送信し、各ピクセルの「NSFW」スコアを平均しました。 皮膚で満たされたフラグメントでニューラルネットワークが見つかると、それを「NSFW」と評価する傾向があり、レナの体に大きな赤い領域が出現します。 右側にヒートマップを作成するために、元の画像の一部を体系的に隠し、-1を「NSFW」(つまり「SFW」)としてマークしました。 ほとんどのNSFWリージョンが閉じられると、「SFW」レーティングが増加し、ヒートマップでより高い値が表示されます。 わかりやすくするために、上部の2つの実験のそれぞれについて畳み込みニューラルネットワークに与えた画像の例を次に示します。

これらの実験の顕著な特徴の1つは、分類子が絶対的な「ブラックボックス」であっても実行できることです。 APIを介してこれらの結果を再現するコードは次のとおりです。
# NSFW occlusion experiment from StringIO import StringIO import matplotlib.pyplot as plt import numpy as np from PIL import Image, ImageDraw import requests import scipy.sparse as sp from clarifai.client import ClarifaiApi CLARIFAI_APP_ID = '...' CLARIFAI_APP_SECRET = '...' clarifai = ClarifaiApi(app_id=CLARIFAI_APP_ID, app_secret=CLARIFAI_APP_SECRET, base_url='https://api.clarifai.com') def batch_request(imgs, bboxes): """use the API to tag a batch of occulded images""" assert len(bboxes) < 128 #convert to image bytes stringios = [] for img in imgs: stringio = StringIO() img.save(stringio, format='JPEG') stringios.append(stringio) #call api and parse response output = [] response = clarifai.tag_images(stringios, model='nsfw-v1.0') for result,bbox in zip(response['results'], bboxes): nsfw_idx = result['result']['tag']['classes'].index("sfw") nsfw_score = result['result']['tag']['probs'][nsfw_idx] output.append((nsfw_score, bbox)) return output def build_bboxes(img, boxsize=72, stride=25): """Generate all the bboxes used in the experiment""" width = boxsize height = boxsize bboxes = [] for top in range(0, img.size[1], stride): for left in range(0, img.size[0], stride): bboxes.append((left, top, left+width, top+height)) return bboxes def draw_occulsions(img, bboxes): """Overlay bboxes on the test image""" images = [] for bbox in bboxes: img2 = img.copy() draw = ImageDraw.Draw(img2) draw.rectangle(bbox, fill=True) images.append(img2) return images def alpha_composite(img, heatmap): """Blend a PIL image and a numpy array corresponding to a heatmap in a nice way""" if img.mode == 'RBG': img.putalpha(100) cmap = plt.get_cmap('jet') rgba_img = cmap(heatmap) rgba_img[:,:,:][:] = 0.7 #alpha overlay rgba_img = Image.fromarray(np.uint8(cmap(heatmap)*255)) return Image.blend(img, rgba_img, 0.8) def get_nsfw_occlude_mask(img, boxsize=64, stride=25): """generate bboxes and occluded images, call the API, blend the results together""" bboxes = build_bboxes(img, boxsize=boxsize, stride=stride) print 'api calls needed:{}'.format(len(bboxes)) scored_bboxes = [] batch_size = 125 for i in range(0, len(bboxes), batch_size): bbox_batch = bboxes[i:i + batch_size] occluded_images = draw_occulsions(img, bbox_batch) results = batch_request(occluded_images, bbox_batch) scored_bboxes.extend(results) heatmap = np.zeros(img.size) sparse_masks = [] for idx, (nsfw_score, bbox) in enumerate(scored_bboxes): mask = np.zeros(img.size) mask[bbox[0]:bbox[2], bbox[1]:bbox[3]] = nsfw_score Asp = sp.csr_matrix(mask) sparse_masks.append(Asp) heatmap = heatmap + (mask - heatmap)/(idx+1) return alpha_composite(img, 80*np.transpose(heatmap)), np.stack(sparse_masks) #Download full Lena image r = requests.get('https://clarifai-img.s3.amazonaws.com/blog/len_full.jpeg') stringio = StringIO(r.content) img = Image.open(stringio, 'r') img.putalpha(1000) #set boxsize and stride (warning! a low stride will lead to thousands of API calls) boxsize= 64 stride= 48 blended, masks = get_nsfw_occlude_mask(img, boxsize=boxsize, stride=stride) #viz blended.show()
このような実験では分類器の結果を簡単に見ることができますが、欠点があります。生成された視覚化はしばしば非常にあいまいです。 これにより、ニューラルネットワークが実際に何をしているのかを真に理解し、トレーニング中に何がうまくいかないかを理解することが難しくなります。
展開ニューラルネットワーク(デコンボリューショナルネットワーク)
特定のデータセットでネットワークをトレーニングした後、画像とクラスを取得し、ニューラルネットワークに「特定のクラスにより適合するようにこの画像を変更するにはどうすればよいですか?」 これには、Sailer and Fergusの2014年の科学記事のセクション2で説明されているように、展開可能なニューラルネットワークを使用します。
開発中のニューラルネットワークは、同じコンポーネント(フィルタリング、プーリング)を使用する畳み込みニューラルネットワークとして表すことができますが、逆も同様です。そのため、サインのピクセルを表示する代わりに、反対のことを行います。 畳み込みニューラルネットワークの特定の活性化を調べるために、このレイヤーの他のすべての活性化をゼロに設定し、発達中のニューラルネットワークのアタッチされたレイヤーへの入力パラメーターとして属性カードをスキップします。 その後、1)アンスプールを正常に実行します。 2)修正および3)選択したアクティベーションを生成した下位層のアクティビティを復元するためのフィルタリング。 その後、元のピクセルレイヤーに到達するまで手順を繰り返します。
[...]
手順は、(通常の勾配とは対照的に)1つの強い活性化の逆伝播に似ています。たとえば、計算どこで
強力なアクティベーションを備えた機能マップの要素であり、
-ソース画像。
レナの写真に必要な変化を示し、ポルノのように見えるようにするタスクを与えられた発達ニューラルネットワークから得られた結果を以下に示します(注:ここで使用される発達ニューラルネットワークは正方形の画像でのみ機能するため、レナの写真を正方形に追加しました)。

バーバラはレナのよりまともなバージョンです。 ニューラルネットワークを信じている場合は、唇に赤を追加することで修正できます。

ジェームズ・ボンドの映画「ドクター・ノウ」のハニ・ライダー役のウルスラ・アンドレスとの次のフレームは、2003年の 「映画史における最もセクシーな瞬間」の投票で1位になりました 。
上記の実験の顕著な結果は、赤い唇とへそがNSFWの指標であることをニューラルネットワークが理解できたことです。 おそらく、これは、SFWトレーニングデータセットに十分な赤い唇とへその画像を含めなかったことを意味します。 精度/完全性およびROC曲線(以下に示す、テストイメージのセット:428,271)を調べることによってのみモデルを評価した場合、テストサンプルには同じ欠点があるため、この事実を見つけることはできません。 これは、ルールベースの分類子と最新のAI研究の根本的な違いを示しています。 特性を手動で処理する代わりに、特性が改善するまでデータセットを再描画します。

最後に、信頼性をテストするために、取得した属性が明らかにNSFWに属するオブジェクトに実際に対応することを確認するために、ハードコアポルノのスキャンニューラルネットワークを開始しました。

ここでは、畳み込みニューラルネットワークが、オブジェクト「陰茎」、「肛門」、「膣」、「乳首」、および「butt部」を正しく取得していることがわかります。 さらに、検出された兆候は、研究者が手動で説明できるよりもはるかに詳細で複雑です。これは、わいせつ写真を認識するために畳み込みニューラルネットワークを使用して達成した大きな成功を説明しています。