はじめに
予測可能ですが、私が待ち望んでいた季節の変わり目が今起こっています。 友人の多くは、夏のシーズンの始まりを楽しみにしており、積極的に在庫を更新しています。 購入する必要がある非常に必要なもののリストは、想像できるすべての予算を10年前に超えています(結局、必要なものすべてを配達するために貨物列車のレンタルを提供する必要があります)そして、オンライン掲示板が助けになります。 お金を節約するために、不要になったもののリストを決定し、それらを売りに出し、掘り出し物を見込んで、電話を待ち始めます。 元気? 目の肥えたバイヤーは、「芝刈り機が優れた状態にある」という事実だけでなく、エンジン出力、草の排出方向、シャフトの位置、稼働時間などにも関心があることがわかりました。 園芸用品の専門家ではないのに、どうやってこれを予見できますか? そして、あなたは同様のトピックに関する他の発表を見始めます、そして時が経ち、あなたの国の物流担当者は輸送のためにバージと2つの貨物飛行機をすでに注文しました。 掲示板の見出しの例では、提案の説明から人々が知りたいことを正確に把握し、広告のクリック数の非常に大まかな見積もりを提供するのに役立つ予測モデルの構築を検討します。
ここでは、全体像、全体像を説明しようとしました。詳細は、投稿の最後にあるコードとデータへのリンクに記載されています。 この記事では、次のことを前提としています。
- 遷移の数は、商品の販売時間に反比例します
- 他の都市(首都に関する記事のみ)およびカテゴリの場合、分析は類推によって実行できます。
データセットの説明
python urllibライブラリを使用して、3879件のレコードが1つの人気サイトから取得されました。 トピック-犬、モスクワ市。 広告を選択するとき、私は非営利の申し出だけを良い手に移すように残そうとしたので、品種は特に示されていませんでした。 選択フィールドの説明:
- 説明 -広告テキスト全体
- 識別子 -サイトの広告番号
- num_counts-プレースメントの開始以降の広告への訪問数
- 価格 -動物の購入が提案されている価格。 通常、ボランティアは100rを入れます。 またはまったく価格を示さない
- start_date-広告が配置された日付
- title-広告の名前、最初のページでの表示
最初の5つのエントリ:
研究目的
広告の説明に対する1日あたりの視聴回数の依存を予測するモデルを開発し、このセクションで最も重要な単語を決定する。
データの前処理
num_countsフィールドには、 パブリケーションstart_dateの開始以降のクリック数が含まれています 。 各レコードの公開時間は異なるため、訪問数を公開の瞬間からデータが受信されるまでに経過した日数で割る必要があります。したがって、1日あたりの訪問数の概算を取得し、予測します。 テキストを分析するために、bag of wordsモデルが使用されます。 だから、計画:
- 異なる記号として異なる形式である同じ単語の使用を除外するためのステミング
- 「日付」フィールドには文字列形式の日付が含まれているため、分析の観点から正しい形式に変換する必要があります
- 説明フィールドは記号と見なされるため、テキストは「bag of words」ビューに翻訳して、tf-idfを適用する必要があります。 この場合、ストップワードはテキストから削除されます:前置詞、補助助詞など。
- 文書項マトリックスと平均訪問者数の間の回帰を復元する試みが何度か失敗した後、ターゲット変数を間隔(四分位数)に分割し、分類問題(したがってtf-idf)を検討することにしました。 つまり 出力では、モデルはこの広告の平均トラフィックが含まれる間隔を予測します。 四分位数への変換はトレーニングセットでのみ実行されたため、テストセットも変換する関数を記述する必要があります。 サンプル全体を変換することはできません。テストデータが間接的にトレーニングに参加するためです
- 「価格」フィールドは、動物あたりの価格を表します。 高値はサラブレッドの販売の指標ですが、非営利活動に関心があるため、価格が500r未満のレコードのみを残しています。 または指定されていません
- train \ testに分割します。 さらに、列車はグリッド上で交差検証のためのトレーニングとパラメータの選択を行い、テストでは最終品質がチェックされます。 基本的な指標-精度
すべての変換後、出力はドキュメント項マトリックスとターゲット変数mean_countを四分位数に分割します(四分位数を5に選択しました)。
探索的分析
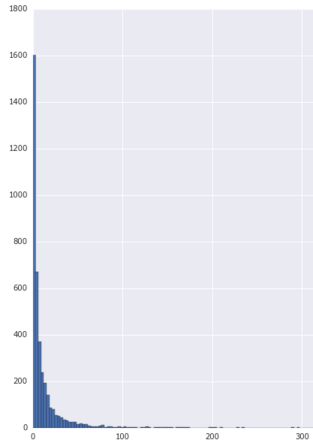
1日あたりの視聴回数にはべき乗則の分布があります。おそらく、このセクションは原則として一般的ではありません。
単語の数とビューの数の散布図を見るのは興味深いです。
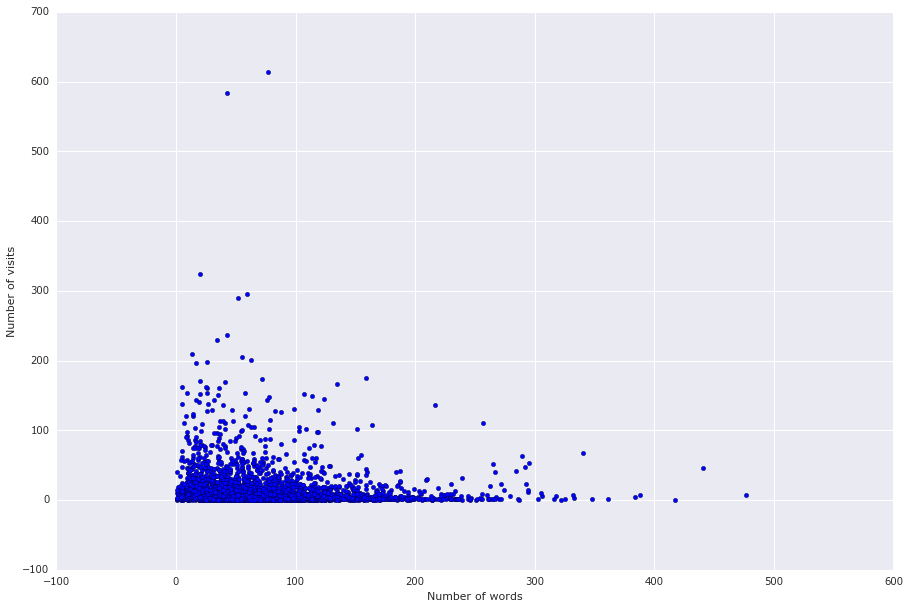
短い広告ほど訪問数が多いことがわかります。 ここでそのような説明をします-長い広告はしばしば、潜在的な所有者とペットとの間のコミュニケーションのモデルを説明します、例えば:
あなたが家の平和を愛しているなら、ロムシュはあなたの足元で静かに横になり、喜んであなたと映画を見ます。そして、あなたは確かにチーズケーキとホットチョコレートのカップと一緒に議論します。 また、寒い夜に非常に快適で暖かくなります。 子供がいて、家が「子供の夢の国」のように見える場合、ロムシュは「バンザイ」の叫び声を上げて走り、子供たちを楽しませます。
すべての人が異なるため、このような発表は、コミュニケーションを異なる方法で提示する人をすぐに除外することができます。 コミュニケーションモデルはボランティアの非常に主観的な見方であり、人が広告に興味を失うのは、犬が彼に合わないからではなく、偏った理由で-彼は間違ったモデルを試してみたからです。 考えられる2番目の理由は、シェルターでの困難な生活の説明です。 人生には砂糖がないことに疑いはありませんが、そのようなテキストを読んだ平均的な人は、深刻なストレスに耐え、無意識のうちにそれをトラウマ的な記憶として忘れようとすることがあります(これは私の主観的な仮説です)。
モデルのベースライン
ターゲット変数は5つの間隔に分割されました(読み取り-クラス):
(13.599、324] 454
[0.0888、1.184] 454
(5.334、13.599)453
(2.436、5.334] 453
(1.184、2.436)453
つまり ターゲット変数が間隔(13.599、324]などから値を取得する454エントリがあります。特定の間隔で常に予測する場合、正解の数は約0.2になり、この値を基本レベルとして選択します。改善されます。
モデル
いくつかの実験の後、分類器としてランダムフォレストを選択しました。 折り畳みの数が5に等しいクロス検証のグリッド検索を通じて、さまざまなパラメーターが構成されました。 Intel i7のトレーニングには約15〜20分かかります。 精度メトリックによる相互検証の平均品質は0.386で、これは定値予測のほぼ2倍です。 以前は精度に関係していなかった遅延サンプル= 0.384以下の表は、分類器が極端な値(間隔[0.0888、1.184]および(13.599、324))と、より悪い隣接値をよりよく区別することを示しています。

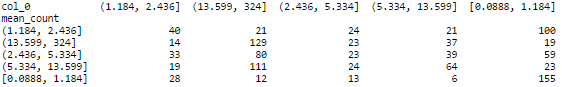
おそらく、テキストに写真を追加することで、モデルの品質を向上させることができます。 写真から特徴を抽出するには、AlexNetなどの畳み込みニューラルネットワークを使用してみます。
言葉の意味
分類で重要な上位50の単語を見てみましょう。

グラフは直感と矛盾していません:人々は、動物の年齢や性別、犬が綱の上を歩くかどうか、家族や独身者に適しているかどうか、他のペットと一緒にいるかどうかに興味があります。 これは、広告に含めるべき最小限の情報であると結論付けることができます。
ソースコード
データセットとipythonラップトップ
おわりに
私たちはすでに、「贈り物としての動物」という見出しに対する見解の数は多くなく、シェルターの方が個人よりも少ないことを見てきました。 おそらくこれは、人々とさまざまな偏見の情報が不十分であることが原因です。 いくつかの事実を説明します。
- 告知は、病棟に可能な限り最良の条件を提供することに関心を持つボランティアによって行われます。 彼らは、何匹の動物を取り付けることができるかについてお金を払われていません。 問題がある場合は、動物を戻すことができます。 そのため、ボランティアには欲求がなく、病気のペットを飼うことはありません。 動物が特別なケアを必要とする場合、そのようなことは常に事前に交渉されており、ボランティアからのあらゆる種類の(合理的な)サポートを頼りにすることができます
- シェルターでは、彼らは疫学的状況を監視します。そうでなければ、ストレスと中程度の品質の飼料の状態では、すべての動物はずっと前に死んでいたでしょう
- シェルターには、飼いならされたが、失われたり、自動車事故や事故の際に飼い主から逃げられたり、単に不必要で不快な動物がたくさんいます。 つまり これらは野生のオオカミではありません
- 少なくとも1週間に1回またはそれ以上広告に表示される各動物について、ボランティアがトレーニングを実施します-綱の上を歩き、チームを教えます。
- これに参加することもできます。
- シェルターにも猫がいます
- シェルターには小型から中型の犬がいます。
いつか自分で動物を飼いたいなら、必ずチェックしてください。突然誰かがあなたの写真からあなたを見ています:
謝辞
この分析は、高等経済学部の「機械学習とデータマイニング」コースの最終プロジェクトの一環として実施されました。先生たちの忍耐と仕事に感謝し、上司にも感謝します。
PSすべての不正確さとタイプミスについては、個人で書いてください!
UPD。 ユーザーandraszsomは、カグル競技の枠組みの中で、シェルターでの生活のさまざまな結果(安楽死、または動物が家族への適応などのために与えられた)の関係を、品種、年齢、およびその他の兆候、 リンクについて分析しました。