いいえ、良い言葉も悪い言葉もないという事実について、私たちは大騒ぎするつもりはありませんが、これらについての評価です。 また、ロシアの虐待の起源と機能については話さず、問題の道徳的な側面についても議論せず、その使用の因果関係も探しません。 ロシア語社会の資料に関するわいせつな語彙の小さな研究を行います。 メディアでは、インターネットソースの大規模なサンプルで一連の測定と計算を行います。
マット の一部
材料として、ロシア語の社会セグメントの2か月のストリームが処理されました。 2014年11月の初めから2015年1月の初めまでBrand-Analyticsによって収集されたメディア(この期間が選択された理由は、記事の最後で明らかになります)。 約450億語が処理されました(ビッグデータタグを挿入)。 処理は、毎日の頻度辞書(ユニグラムとバイグラム)の構築と言語モデルの構築で構成されていました-SRILMツール(テキストマイニングタグを挿入)。
したがって、この期間の単語またはフレーズのダイナミクスを確認することができました。 私たちはさまざまなことをたくさん見ました。 私は何かが好きで、何かは好きではありません。 たとえば、図1は、人称代名詞と前置詞の頻度を示しています。
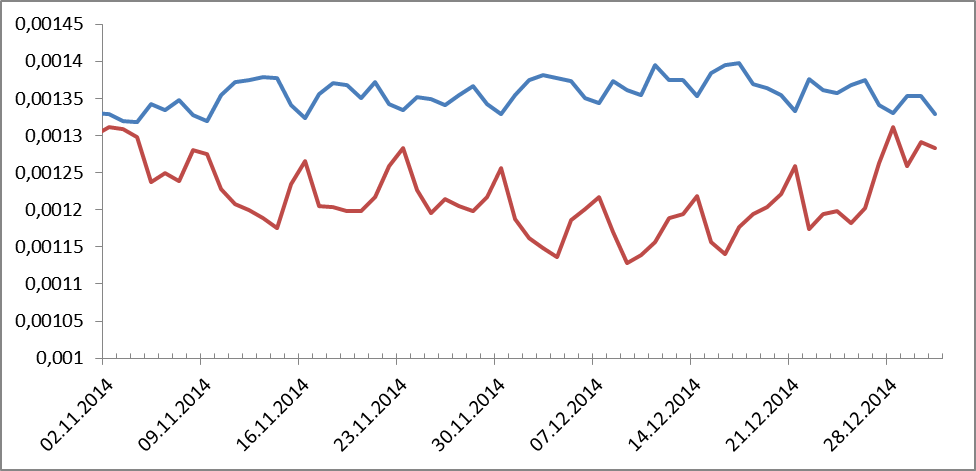
図1.前置詞(青色)および人称代名詞(赤色)の頻度分布のダイナミクス。
彼らは逆位相にありました。 意外とそうですか? そして、ご想像のとおり、ピークは週末です。 彼らはお金について何と言いましたか? 私たちは見ます:
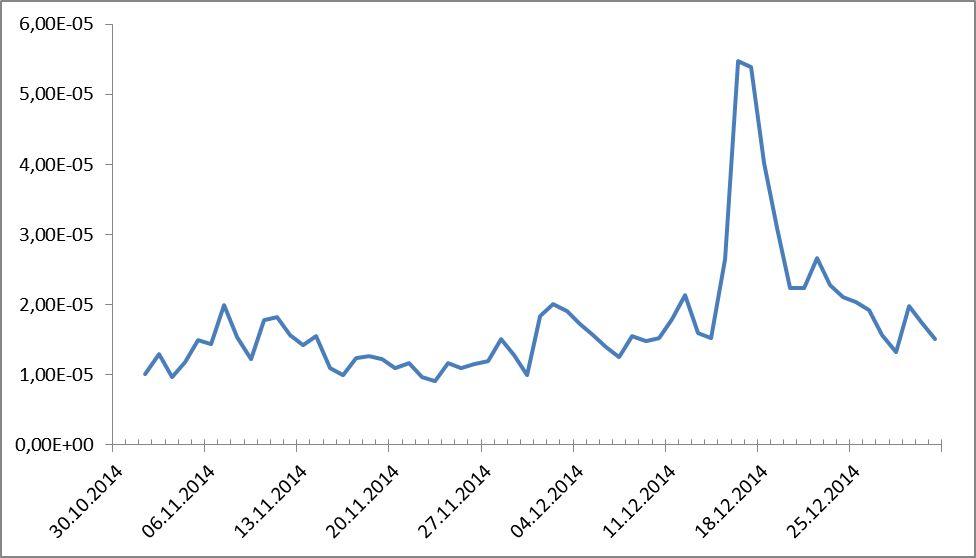
図2.通貨単位の名前の度数分布のダイナミクス。
質問はないようです、誰もが2014年12月18日を覚えています。 しかし、誰かが忘れた場合は、次のことを思い出してください。
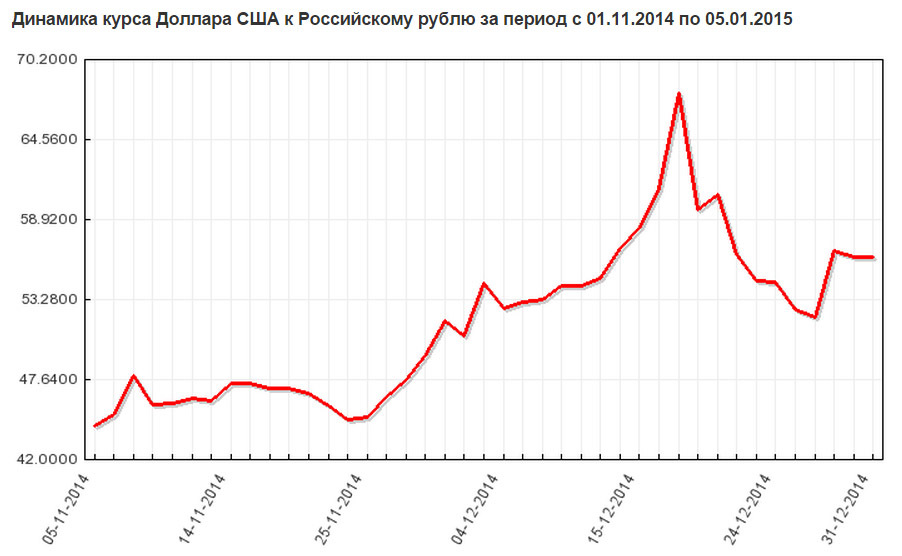
しかし、これは別の出版物のトピックです。 さて、あなたは女性と発音できないものをどのように見ることができませんか? はい、彼らは私たち、ロシア人、4つの
OK、言った-完了。 彼らはロシアのわいせつな語彙のフィルターを取りました。 そして、すでにモルフォタイプを持つ500以上のユニークな単語があります。 すべての単語形式を生成しました。 8650年頃に何かが判明しました。しかし、すごい単語形成ではありません。
今、実験と写真
わいせつな言語が禁止されないように、プラスは、「女性と一緒に自分を表現しないでください」と言うように、これを行います:条件付きでそれらを結合します(代名詞の照応:語彙、私はそれらを与えません)文字(まあ、あなたはまだこれらの単語を知っていますか、説明する必要がありますか?):
- グループB
- グループX
- グループE
- そしてグループP
さらに2つ追加しましょう。
- グループG (はい、牛肉の根)、それから理由は明らかです。
- グループOは、残りの意味で、 Mu * 、 Pid *などの文字上にあります。
ご注意 非文字のスペリング (文字の置き換え: ダンス )、強調母音の長さ( * lyayaya )、および最も頻繁に起こる間違いを含む、すべての単語形式を考慮しました。 up曲表現は考慮されませんでした。 ありとあらゆる種類の、わさび、性交 -あなた自身のための通常の言葉。
これらの8650個の単語のうち、約1,000個が度数分布全体で見つかったとすぐに言わなければなりません。 まず、頻度辞書がカットオフされました:頻度分布の合計の95%が考慮されました(つまり、テールがカットされました-なぜすべてのゴミをあなたと一緒にドラッグします)、辞書のボリュームの30-50%に減りましたが、元の5%材料)、そして第二に、多くの単語形式は本当にエキゾチックです。
注 (誰かが興味を持っている場合)。 私たちが研究する語彙の頻度は、発行の頻度でランク付けされた2番目の1000の終わりから始まります(ほぼ1200万のトークンのうち)。
だから、私たちはチャートを構築して見ています。 最初のグラフは、グループごとに見つかった単語の絶対数です。
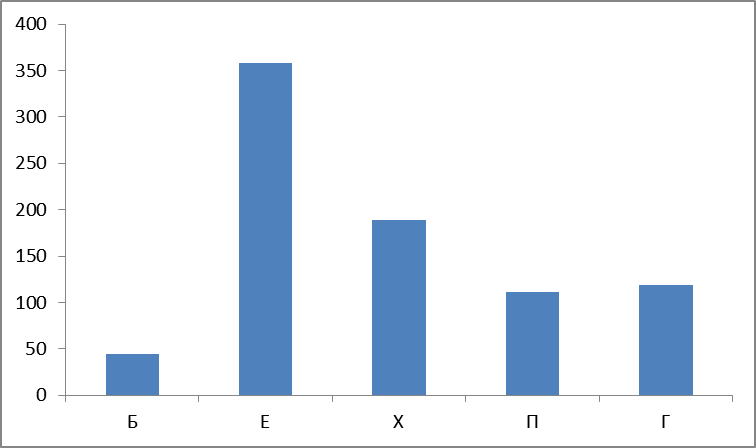
図4.グループごとに見つかった単語の絶対数。
そして、周波数の用語では(より正確には、逆周波数または正規化された周波数で動作します)? そして、ここに2つのチャートがあります:
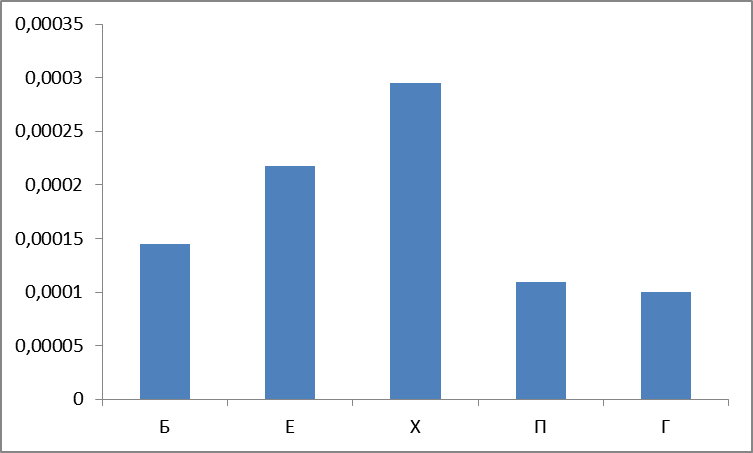
図5.グループによって検出された単語の正規化された頻度の合計。
そして今、平均:絶対数に正規化された周波数の合計:

図6.グループによって検出された単語の正規化された頻度の平均。
最初の驚きは次のとおりです。最も頻度の高いグループP 、 X 、 E (「 非常に頻度の高い」性的な「トライアド 」)が信じられますが、グループBは大きくマージンを持っています。
そして、なぜグループDを常に後ろにドラッグするのですか? しかし、理由:すべてのグラフで、絶対値と相対値の合計P + X + B + EがグループGよりも確実に大きいことは明らかです。 つまり、予想どおり、私たちの仲間は、ドイツ人、チェコ人、および他のスウェーデン人が彼らのシャイシュ文化を持っているにもかかわらず、性的タイプに属する
他に何が見えますか? そして、分散を計算しましょうか?
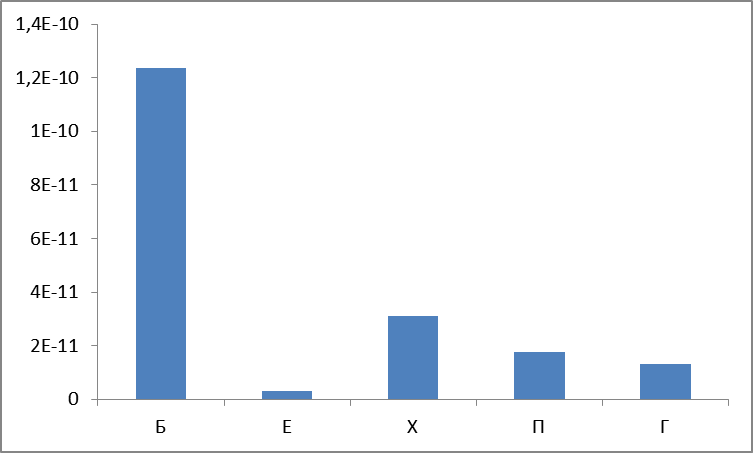
図7.グループごとの分散。
一般に、最も頻度の高いグループの分散が最大であることは驚くべきことではありません(悪名高いZipfの法則の結果)。 グループEは、分布が最も均一で、極端な地域に集中していないため、最も安定していることが判明しました。
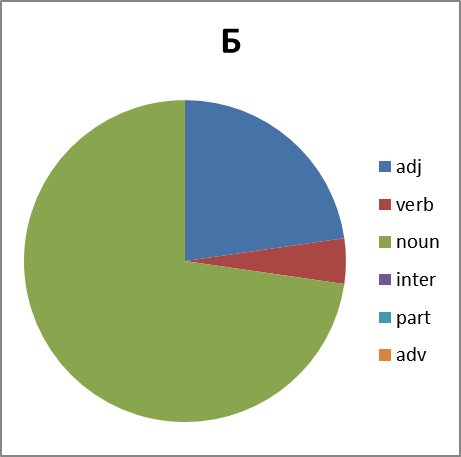
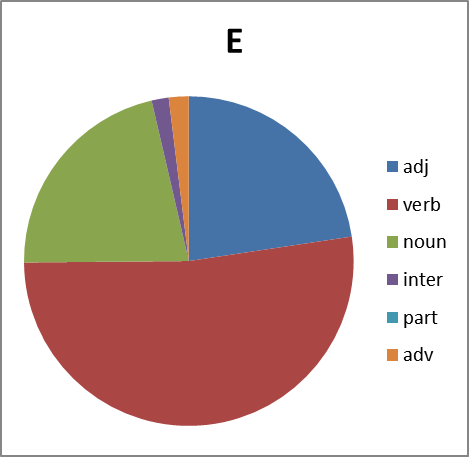
いいね さらに調べます。 興味深いことに、品詞の分布は何ですか。 ここでの質問は簡単ではありません。 文脈から外れているため、わいせつな語彙のスピーチの一部を明確に識別することは常に可能ではありません。 多くの場合、名詞は間投詞、副詞、または助詞としても使用されます(たとえば、グループXの否定)。 したがって、エラーを含む円グラフを作成します。 ただし:
 |  |
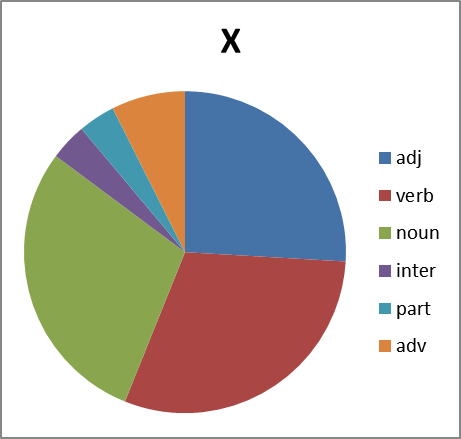 | 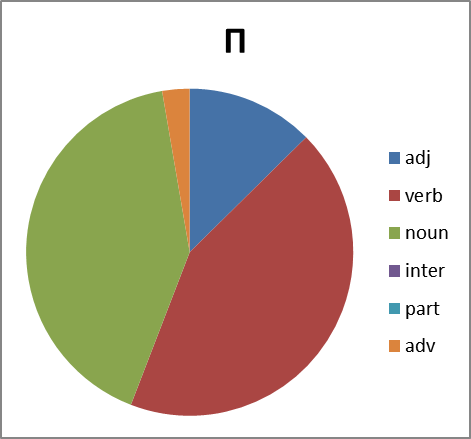 |
図8.品詞における各グループの単語の分布。 略語:adj-形容詞、動詞-動詞、名詞-名詞、inter-間投詞、part-助詞、副詞
これらすべてを見て、どのような結論を導き出すことができますか? グループBは、グループX 、 EおよびPからの変動性が大幅に遅れています。 そして、私たちに未知の理由で、それはほとんど動詞を形成しません。 しかし、グループXはただ眩しいだけです。 しかし、この現象の分析はこの分野の専門家に任せます...
さて、今最も興味深いのは、指定された期間、つまり、調査対象オブジェクトの使用のダイナミクスは何ですか? 2014年末の危機の中で、恒久的なものになりましたか? そして、ここでさらに興味深いものになります。
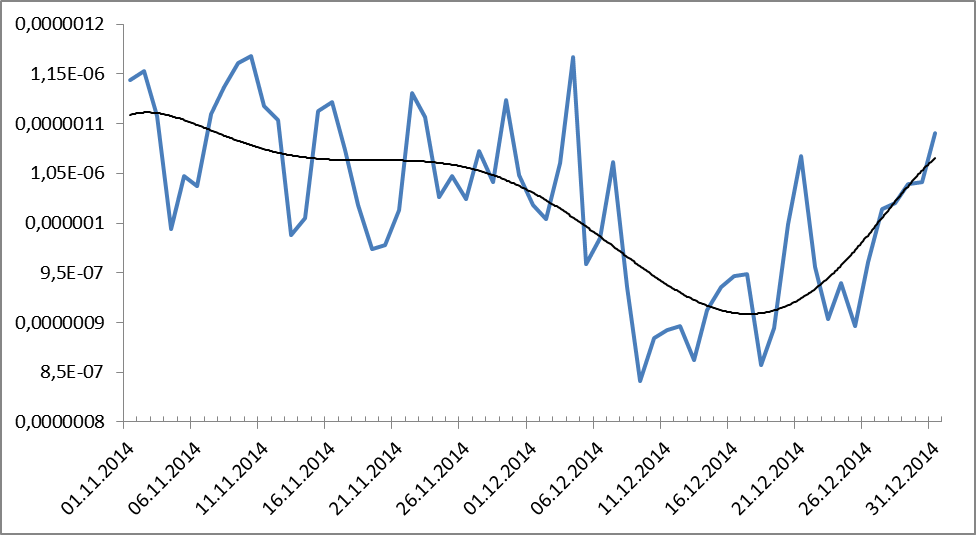
図9. 2014年11月11日から2014年12月31日までの期間のわいせつな語彙の頻度分布のダイナミクス。 黒はトレンドライン(多項式、9度)を示します。
これは何ですか? 危機の間に、わいせつな語彙の使用は落ちますか? はい、判明しました。
中間的な結論を出します。
- わいせつな語彙には強い単語形成があります(一部のトークンには複数の形態型がある場合があります)。 これは、その使用がテキストのエントロピー、その複雑さを増加させるべきであることを示唆しています。
- 危機の時期には、感情が高まり、感情的な言葉の使用が増えるはずですが、反対の見方があります。
多分どこか間違い? 確認方法 そして、テキストの複雑さ、その複雑さのダイナミクスを見てみましょう。 もちろん、そのようなボリュームで作業するのは難しいですが、何をすべきか。 彼らは受け取ったとみなした:

図10. 2014年1月1日から2014年12月31日までの期間の当惑の分布のダイナミクス。 黒はトレンドライン(多項式、9度)を示します。
ご注意 困惑の非常に重要なことは、ボリュームが大きいために強い平滑化を使用し、周波数制限を課したという事実から生じます。 ユニグラムとバイグラムで数えられます。
繰り返しますが、 驚きです。しかし、複雑さも低下します。 結局のところ、私たちは何か正しいことを考えました。感情は複雑さに関連しています。 しかし、彼らは、危機の間、感情は「オフスケール」でなければならないという「半々」の仮定に誤解されていました-まったく逆です。
たぶん、これは危機の出版物の数の変化によるものでしょうか? 次に、単語の使用数の別のグラフを示します。
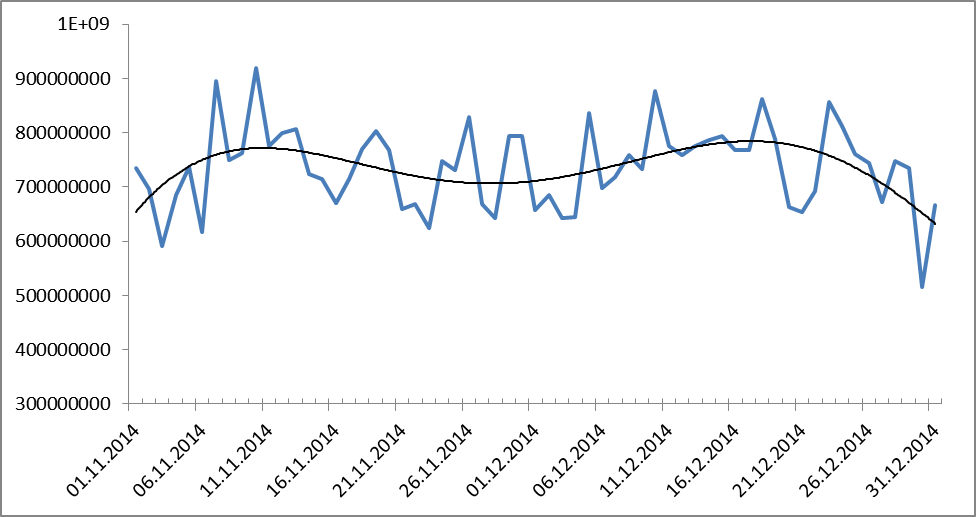
図10. 2014年11月11日から2014年12月31日までの期間の単語使用のダイナミクス。 黒はトレンドライン(多項式、9度)を示します。
おそらく、相関関係を計算することです(困惑とわいせつな語彙):
-相関係数は〜0.51で、これはどれほどああではないようです。
しかし、すべては相対的です。前置詞との複雑さの相関は〜-0.04であり、個人代名詞は-0.06です。
結論
何を持っていくのかさえ分かりません。 深刻な分析(たった1つの危機)に十分なデータがありません。他の何かを測定することは別の記事です。 これかもしれません:自分で結論を出す-使用するかしないか。 おそらくこれは経済危機に何らかの形で影響を与えるでしょう...
読んでくれてありがとう!