
OoOとスタックドマシンのフロントエンドを備えたスーパースカラープロセッサの概念を探る一連の記事の続き。
この記事のトピックは、ビュー内での関数の呼び出しです。
前の記事:
1-直線作品の説明
2-関数呼び出し、レジスターの保存
前の記事で関数呼び出しの外側に注目すると、これらすべてが内部で実行される方法を見失いました。 著者は自分自身をハードウェアの専門家とは考えていませんが、それでも問題を予測しています。
関数から戻った後、プロセッサを以前と同じ状態にしたいと述べました。 そのため、レジスタの状態を維持することに専念していました。 しかし、プロセッサの状態はレジスタだけではありません。 モップの列、コンベアの状態も......
関数呼び出しの時点で次のような状況を想像してください。
- デコーダースタックの一部のモップ
- スタックからデコーダーによって削除されたが、親モップの実行を待機しているモップ
- コンベアモップ
その結果、新しい関数の実行を開始することはできません
- このため、十分なモップがない可能性があります-親関数から残っているモップは、ここから戻るまで解放されません
- デコーダーのモップインデックスのスタックの深さは固定されており、再帰または呼び出しの長いチェーンで簡単にオーバーフローする可能性があります
- パイプラインのモップは、(新しい関数を呼び出した後)レジスタの番号が変更された後に実行されます
すべての引数を計算する呼び出しの前に待機する一般化された命令によって関数呼び出しを宣言したときに、説明された問題を回避するために特定の手段を講じたように見えるかもしれません。
ただし、データに依存しない場合、デコーダーは関数を呼び出した後にコードを処理する時間があるという事実に問題があります。 例:
int i, j, k; … i = foo (i + 1); j += k; bar (i, j);
fooから戻った後、現在のタスクのコンテキストでjが計算および保存(および復元)されたという事実や、j + = kのモップが保存されたという事実に依存することはできません。 彼女に計算する時間がなかったら
関数呼び出しを見ると、デコーダはこの関数から戻るまで動作を停止するとします。 次に、この状況はどうですか:
int i, j, k; … bar (foo (i + 1), j += k);
1つのデコーダーでは十分ではありません。 関数から戻った後、デコードを開始し、さらにコードを再度実行するだけでよいようです。
しかし、結局のところ、基本的に、スーパースカラリティによって引き起こされるこれらの問題は、私たちのアーキテクチャに固有のものではありません。車輪を再発明する必要はないかもしれません。
さて 、IntelのSandy Bridgeを見てみましょう( Tasit Murka、別名Felidに感謝)
ここだけでなく
サンディブリッジ。
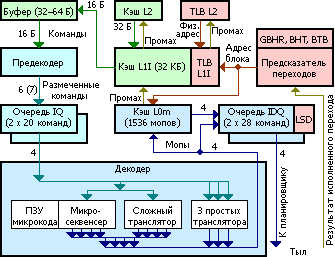
おそらくSandy Bridgeフロントエンド、
- 実行可能コードは、第1レベル(L1I)の命令のキャッシュから(回路の左上隅にある)プリコーダーバッファーに入ります。
- プリコーダーは、長さと複雑さの組み合わせに応じて、サイクルごとに最大7つの命令を処理できます。
- タグ付けされたチームは、チームの2つのキュー(IQ)のいずれかに分類されます-スレッドごとに1つ(ハイパースレッディング)、各20チーム
- デコーダーは交互にキューからコマンドを読み取り、それらをモップに変換します
- コマンドのタイプに応じて、デコーダーは異なるタイプのトランスレーターを使用します
- デコード結果はmopsキャッシュと2つのmopsバッファーに送られます (ハイパースレッディング)
- 32バイトのソースコードのキャッシュされた整列部分(部分)
- キーはその部分へのエントリポイントです。ある部分に別の場所への遷移があった場合、この部分はキャッシュに伝播されます。
- 部分デコードはそのエントリポイントで開始します
- 18個以下のモップが生成された部分のみがキャッシュされます-各6モップの3行
- 命令を2人前の境界線で割ると、最初の1人に関係します
- 部分の6つ以下の遷移を持つことが許可され、それらのうちの1つだけが無条件にできます-そして一度に最後になります。 これは重要です 関数呼び出しは無条件の遷移であり、それ以降に発生するすべては現在のキャッシュユニットに分類されません。つまり、戻ることを試みるまで実行されません。
- 部分が無条件ジャンプで終了しない場合、遷移はアドレスの次のセクションの最初の命令に発生します
- Mopsキャッシュ(L0m)はL1Iと同期され、キャッシュの最後の行は64バイトであるため、行L1Iがプッシュされると、2つの部分に関するすべてがL0mから削除されます
- 好奇心が強い、L1Iは物理アドレスで動作し、L0mは仮想アドレスで動作します
- 投機的実行に関して:
- 遷移予測 (BPU)は、条件付き遷移モップがこの遷移のイベントの発生確率を報告することができます
- なぜなら モップの現在のキューで、デコーダーはすべての潜在的な遷移を既に識別しています。それらを確認できます
- 遷移確率が十分に高い場合、コードの適切な部分をプリロードして投機的に実行するのが理にかなっています
- 遷移が実際に発生した場合、少なくともデータのデコードされた部分を取得します。おそらく、いくつかの命令(データ依存性を持たない)は成功します
- 移行がない場合、まだ実行されていない命令は中止されるべきであり、解決された命令は取り返しのつかない結果を引き起こすべきではありません。 キャプチャされたすべてのリソースが解放されます。
- つまり、特別な投機モードで実行されます。
- メモリへの書き込みを遅らせる必要があります
- メモリからの読み取りは、データが既にデータキャッシュにある場合にのみ実行されます。そうでない場合は、実行がブロックされます(無駄なキャッシュミスとその後のスワップへのアクセスを回避するため)
- 例外を引き起こす可能性のあるすべて(たとえば、0による除算)はそれに応じてマークされ、ブロックされますが、これは前の段落の一般化です。 これで、移行が発生したときに、ブロックされたモップを正直に再起動できます
- そしてもちろん、これらはすべて仮定に過ぎず、Intelだけが実際の状況を知っていることを思い出してください
関数呼び出しはどのように発生しますか?
次の例を見てみましょう。
int i, j, k, l, m, n; ... i = 1 + foo (1 + bar (1 + biz (1 + baz (1 + j) + k) + l) + m) + n;
このコードはすべて1つの32バイトチャンクに収まり、コード生成の順序(オプティマイザーをオフにした場合)はテキストの順序に対応すると想定します。 L0mキャッシュに分類されるセクションのインスタンスに応じてコードをマークしましょう。
int i, j, k, l, m, n; ... 1> i = 1 + 4> foo ( 1> 1 + 3> bar ( 1> 1 + 2> biz ( 1> 1 + 1> baz (1 + j) 2> + k) 3> + l) 4> + m) 5> + n;
このスニペットは、おそらく使用可能な256行のうち5行を占有します。
当然のことながら、コンパイラーは小さな関数のインライン化に苦労しています。
結論
そこで、非常に洗練されたマイクロアーキテクチャの1つで関数がどのように呼び出されるのかを調べましたが、これからどのような利点が得られるのでしょうか。
客観的なポイントを強調します。
- 命令キャッシュが必要です。これがないと、わかりやすいプロセッサーは使用できません。
- キャッシュはきめ細かく、現時点では一般的なサイズは64バイトの文字列です。
- デコード(少なくともx86_64の場合)はかなり高価な操作です。デコードされたコードをモップの文字列の形式でキャッシュするのは理にかなっています
- エントリポイントでのアクセスは素晴らしいアイデアです。レコードを複製せずに実行できますか-実装の問題
- 唯一の必須ソリューション-シンプルで自然なソリューション、多くの問題を排除
これはすべて、スタックフロントエンドを備えたアーキテクチャで機能すると思われるかもしれません。 しかし、ニュアンスがあります。
例で説明しましょう。 アッカーマン関数は次のとおりです。
int a(int m, int n) { if (m == 0) return n + 1; if (n == 0) return a(m - 1, 1); return a(m - 1, a(m, n - 1)); }
単純に見えますが、再帰の驚異を示しています。 次のグラフは、呼び出しa(3、5)のネストの深さのダイナミクスを示しています。xはステップ番号、yは呼び出しの深さです。
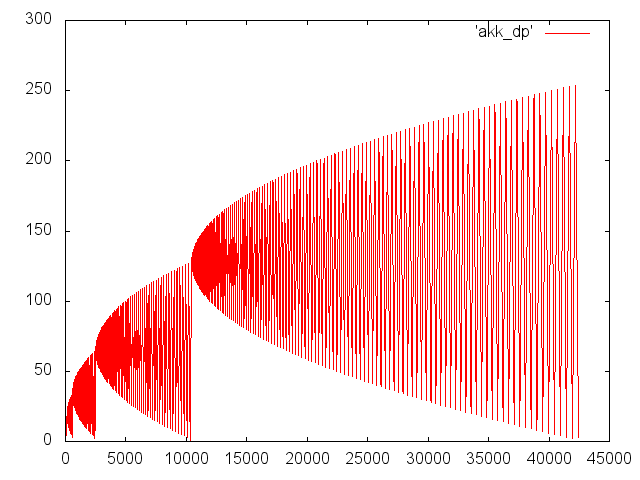
関数呼び出しを任意の数のパラメーターを持つ一般化された命令と見なすことにしたため、m * n!= 0の場合、最初の引数(m-1)はモップのスタックに残り、2番目の引数は計算されます:a(m、n- 1)。 さて、最初の引数に計算する時間があり、その値がレジスタスタックで呼び出されたときに保存される場合。 ただし、最初の引数の式が、2番目の引数の子呼び出しの引数よりも長く評価される場合があります。 そして、私たちにはかなりの量の故障したモップがハングアップします。
親呼び出しモップは、子呼び出しが完了するまで待機します。 SandyBrigeでは、通話の深さは数万台に簡単に達することができます。たとえば、モップはそれほど多くありません。
問題の本質は、呼び出しを一般化された命令として認識し、それによってプログラムを一般化された表現として認識したことです。 また、再帰によるこの式のツリーは、任意の高さにすることができます。 一方、式スタックは制限されています。 また、スタック要素はモップのインデックスであり、その数も限られています。
しかし、私たちはそれほど簡単にgivingめることに慣れていないので、プランBが出てきます。
プランb
スーパースカラーレジスタプロセッサにはこのような問題はありません。 モップ間の接続の識別は、後で行われます-レジスタの名前を変更する段階で。
私たちの国では、これらの接続はモップのインデックスのスタックに保存されます。
たぶん、スタックの状態を保存しますか? モップのインデックスを維持するだけでは不十分であることがわかりました。モップ自体にも注意が必要です。 割り当てられているかどうかにかかわらず、スタック全体でモップの保存を整理するのは自然なことのように思えますが、質問は完全に別です。
そしてここで、レジスタを保存しようとしたときに遭遇したのと同じ問題に直面しています。 つまり、単一の(すべての機能の)モップの識別で:
- モップの使用順序は通話履歴に依存します
- 関数内では、動的に定義されます
- FILL操作の後、すでに占有されているモップと競合しないという保証はありません。
これらの問題を解決する方法は同じです:
- リングバッファモップ
- 各関数には、独自の番号のモップがあります。たとえば、0 ...
- FILLおよびSPILLは関数全体に対して作成され、必要に応じて、レジスタスタックとモップのスタックを1つのメモリ領域にバインドできます。
- FILLおよびSPILLは、完了を待つモップに対してのみ作成されるため、シリアル化されたモップのマスク(または列挙)もスタックに配置されます。
- モップのインデックスのスタック、保存する必要があります
一見したところ、メモリを介してデコードされたモップを駆動する必要性は途方もないように見えます。 しかし、 カテコールアミンが燃え尽きると、災害の規模がそれほど大きくないことが明らかになります。
- 最新のプロセッサでは、パラメータ(少なくともそれらの一部)はレジスタを介して送信されますが、再帰呼び出しでは、スタックを除いて、パラメータを保存する場所がありません。
- 'a(m-1、a(m、n-1))'のような式は、a(m、n-1)に等しい一時変数を(明示的または間接的に)導入することにより、コンパイラーが分割できます。 これにより、保存する必要があるモップの数が減ります。
- 関数呼び出しである無条件遷移の時点までにすべての失敗した条件分岐は、すでに投げました
- 次のチャレンジのすべてのモップは、SandyBridgeと同様の手法を使用して、破棄するか、単にロードしないこともできます。
- しかし、そのままにしておくことができます。関数から戻ると、ボーナスを受け取り、実行の準備ができているか、すでに部分的に実行されています(データに依存しない)
- 最も「経済的な」バージョンでは、1つのシリアル化されたコールモップのみがスタックに追加されます。これは、たとえば、フレームバッファアドレスを送信する場合と大差ありません。
- (de)mopsのシリアル化は、コストのかかる操作のようには見えません。さらに、関数からの現在の戻りをブロックすることなく、事前にバックグラウンドで実行できます。
- ロードとともにモップをスタックに保存することは、l0mキャッシュの代替となるはずです。
- 直列化されたモップのサイズは大きすぎません。SandyBridgeの場合、初期モップサイズは最大147ビット、圧縮形式で見積もられます-85ビット(およびすべてのストライプのx87、SSE、AVXがあります)
- プロセッサの技術的機能が外部からアクセス可能になり、技術的な秘密が侵害される可能性があるという事実は、著者を怖がらせません。 最後に、プロセッサにこのデータをワンタイムパッドでxorさせます。
次は何ですか
これまでのところ、スタックされたすべてのマシンの弱点、つまり過剰なメモリアクセスに注意を払っていません。
したがって、 次の記事でそれらに対処します。