私たちのブログでは、株式市場の状況を分析し、起こりうる崩壊と価格の変化の予測を作成するために使用されるさまざまなツールを証券取引所で取引するためのソフトウェアについて繰り返し書きました( この資料には、考慮されるすべてのアルゴリズムとツールが含まれています)。 最も一般的な分析ツールの1つは、Hadoop、NoSQLなどのさまざまなビッグデータテクノロジーです。
今日は、研究者がビッグデータを使用して株式市場の動きの予測を作成した2つの実験を見ていきます。
投資家分析によるボラティリティの予測
インドのコインバトール市の技術研究所の研究者は、株式市場の動きの予測を作成するためのこれらのデータの使用に関する世論の調子を決定するためのビッグデータ分析メカニズムの使用に関する論文を発表しました。
特に、投資家やトレーダーが取引所や金融機関のウェブサイトに残したメッセージやレビューが分析されました。
分析のプロセスでは、データを収集し、このステートメントがポジティブかネガティブかを示すマーカーを選択する必要がありました。 この場合、自然言語の特性を考慮する必要があります。ミスを避けるためには、自然言語の特性を考慮する必要があります。たとえば、「悪くない」というフレーズは肯定的な特性です。
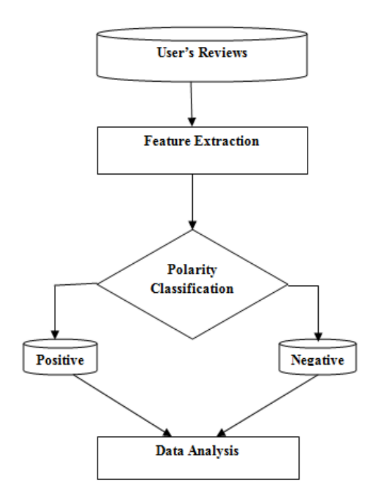
このような分類は、ドキュメント、文、またはフレーズのレベルで、さまざまな方法で実行できます。 このために、機械学習のさまざまなメカニズムを適用することもできます。たとえば、 「教師」と教師なしで学習するためのアルゴリズムは、互いに反対です。
後者の場合、語彙分析は、声明の一般的な調性を決定するためによく使用されます-システムは、意見を表す単語(形容詞など)を検索します。
教師とのトレーニングの場合、入力データと目的の分析結果を含むトレーニングサンプルが使用されます。 これらのデータを比較するには、 単純ベイズ分類器またはサポートベクトルアルゴリズムを使用できます。
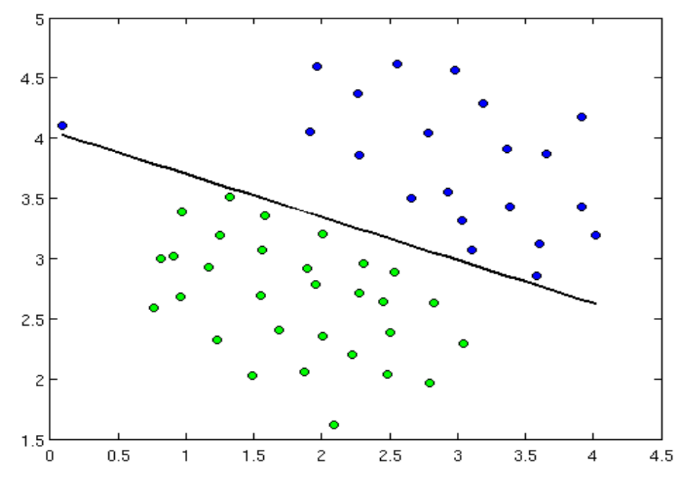
サポートベクトルアルゴリズムによる線形分類器
投資家の声明の調子に関するデータも履歴データと比較されて、金融のボラティリティが決定されます。この後、この価値が将来どのようなものになるかについて予測を立てることができます。 ここで、ボラティリティは、一定期間にわたる金融資産の価値の変化として理解されます。
時系列の分析には、 自己回帰条件付き不均一分散 (ARCH)のモデルが使用されます-それらは、金融市場のボラティリティをクラスタリングするプロセスを分析するように設計されています。 これは、高ボラティリティの期間が低ボラティリティの期間に置き換えられるという事実に表れています。 同時に、平均ボラティリティは比較的安定したままです。これにより、将来のボラティリティを予測できます。
同時に、ARCHモデルは、条件付き分散が時系列の過去の値の2乗のみに依存することを前提としています。 このモデルは、条件付き分散がそれ自体の過去の値にも依存することが示唆されたときに一般化されました。その結果、GARCH(Generalized ARCH)モデルが登場しました。
作業スキーム
研究者は、株式市場の状況を予測分析するために、サポートベクターアルゴリズムをGARCHモデルに適用するシステムを開発しました。 次のように機能します。
- 初めに、アナリストのレビュー、投資家とトレーダーのレビュー、および入札プロセス中のテキスト形式のオープンチャットのログが、人気のある金融サイトからダウンロードされます。さらに、取引所で株式が取引されている企業のサイトからのニュースがシステムにダウンロードされます。
- サポートベクトルアルゴリズムを使用して、ステートメントのトーンが決定されます(このアルゴリズムにより、ベイジアン分類器の場合よりも正確な分類を作成できることが実験により示されています)。
- また、同じ期間にわたって、分析された株価指数の値の履歴データが読み込まれます。この情報は、GARCHモデルを使用してボラティリティを計算するために使用されます。
- 得られたデータに基づいて、個々の銘柄のボラティリティトレンドの予測が生成されます(小規模企業の銘柄については、大規模な銘柄よりもモデルの方がうまく機能します)。
Twitterデータに基づいて有望な銘柄を選択するシステム
ロンドンのインペリアルカレッジの研究者は、ソーシャルネットワーク上の出版物を分析し、これらのデータと株式市場のトレンドとの相関関係を特定して有望な株式のポートフォリオを形成するツールの作成に関するストーリーを発表しました。
スタンフォード大学の研究を含むさまざまな研究は、Dow Jones IndexとTwitterユーザーの感情との相関関係を示しています。
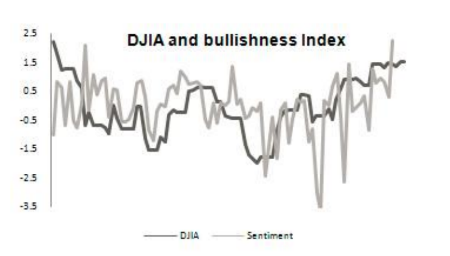
この情報の分析により、将来の価格変動に関する予測を立てることができます。 英国の研究者は、S&P 500インデックスの企業に関連するツイートをダウンロードし、Hadoopジョブを起動して、各発言および株式セット(ポートフォリオ)の総調性スコアを作成し、正の調性評価が高いポートフォリオをランク付けするアプリケーションを作成しましたその他。
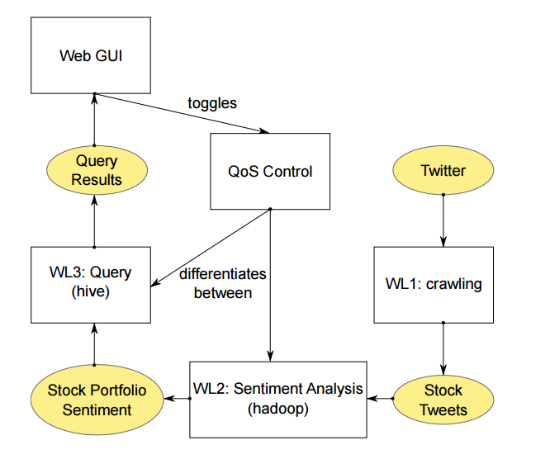
アプリケーションアーキテクチャ
デモシステムは、Hadoop 1.1.2クラスターおよびIBM GPFS 3.6で実行されます。 各ノードには、8つのIntel Xeon 2.5 GHz CPUチップ、8 GBのメモリ、250 GBのストレージ、OS-RedHat Linuxが搭載されています。
アプリケーションの作成者によると、投資家はそれを使用して、現時点で最も有望な株を選択できます-このツールは、株価を正確に予測するようには設計されていませんが、いずれかの方向への動きを期待できるものを選択するのに役立ちます