免責事項:投稿は、かなり編集されたチャットログclosedcircles.comに基づいて書かれたため、プレゼンテーションのスタイルと、明確な質問の可用性
誰もが知っているように、移動の可能性が非常に多く、検索スペースが非常に大きいため、直接検索ではほとんど役に立たないため、Goのコンピューターのパフォーマンスは低下しました。
最良のプログラムは、いわゆるモンテカルロツリー検索 -いわゆるロールアウト、つまりノード内の位置からのゲームの結果の迅速なシミュレーションによるノードの評価によるツリー検索を使用します。
AlphaGoは、このツリー検索を深層学習ベースの評価関数で補完して、検索スペースを最適化します。 この記事は元々Natureに掲載されていました(そしてペイウォールの背後にあります)が、インターネットで見つけることができます。 たとえば、こちら-https://gogameguru.com/i/2016/03/deepmind-mastering-go.pdf
最初に、複合部品について説明し、次にそれらをどのように組み合わせるかについて説明しましょう
ステップ1:人々の動きを予測することを学習するニューラルネットワークのトレーニング-SLポリシーネットワーク
私たちは、オンラインで利用可能なかなり高レベルのプレイヤーのゲームを160K取り、その位置にいる人の次の動きを予測するニューラルネットワークをトレーニングします。
ネットワークアーキテクチャは、最終的にセルごとに非線形性とソフトマックスを備えたたった12レベルの畳み込み層です。 通常、この深さは、前世代の画像を処理するネットワーク(Google Inception-v1、VGG、これらすべて)に匹敵します。
重要な点は、ニューラルネットワークが入り口で与えられることです。
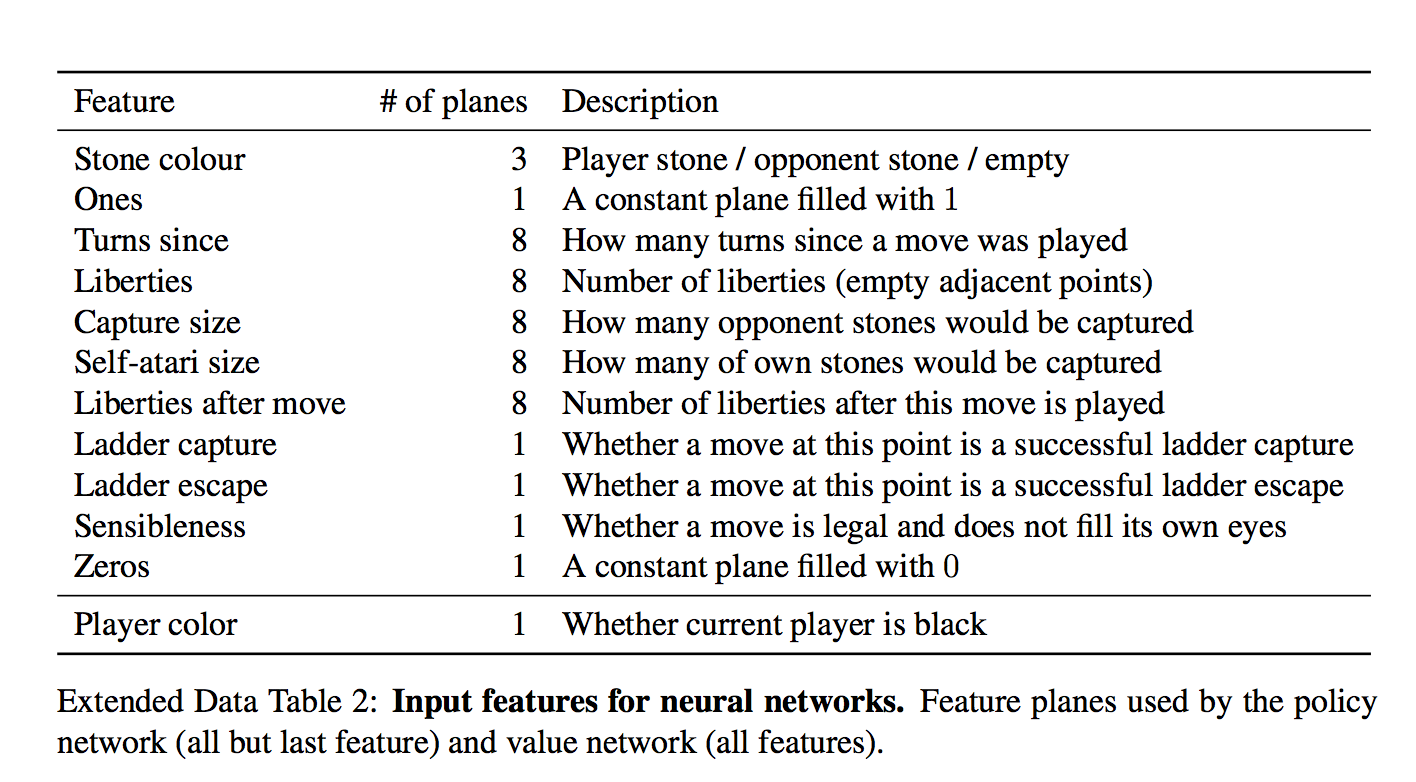
各セルに対して、48個のフィーチャが入力として与えられ、それらはすべてテーブルにあります(各ディメンションはバイナリフィーチャです)
セットは面白いです。 一見すると、セル内に石が存在する場合にのみネットワークを提供する必要があるように思われます。 しかし、そこにイチジク!
「石の自由度の数」や「この動きをとる石の数」など、些細な計算された特徴があります。
「移動が行われたのはどれくらい前か」など、正式には重要ではない機能があります。
「ラダーキャプチャ/ラダーエスケープ」という頻繁に発生する現象の特別な機能でさえ、強制移動の潜在的に長いシーケンスです。
「常に1」および「常に0」とは何ですか?
機能の数を4の倍数に仕上げるだけであるように思えます。
そして、これですべてのネットは人間の動きを予測することを学びます。 57%の精度で予測しますが、これは注意して処理する必要があります。予測の目的である人間の経過はまだあいまいです。
しかし、著者は、精度のわずかな改善でさえ、ゲームの強さに大きく影響することを示しています(異なる力のグリッドを比較)
SLポリシーとは別に、彼らは高速ロールアウトポリシー-単に線形分類器である非常に高速な戦略をトレーニングします。
彼らは入り口で彼女にもっと準備された特徴を与えます。

つまり、あらかじめ用意されたパターンの形で特徴が与えられます
深いネットワークを持つモデルよりもはるかに悪いですが、超高速です。 使用方法はさらに理解されます
ステップ2:強化学習によりポリシーをさらに改善する-RLポリシーネットワーク
私たちは偶然にネットワークの以前のバージョンのプールから敵を選択し(自分に過剰にならないように)、最後までネットワークの予測から最も可能性の高い動きを選択するだけで、再びソートなしでゲームをプレイします。
唯一の報酬は、勝ち負けのゲームの実際の結果です。
報酬がわかったら、ウェイトをシフトする方法を計算します-ゲームに再び負け、結果に応じて+または-の勾配に従って、各ターンで選択した位置の選択に影響するウェイトを移動します。 つまり、この報酬を各動きの勾配の方向として適用します。
(好奇心が強い人のために-もう少し微妙であり、勾配は結果と値ネットワークを介した位置推定値との差で乗算されます)
そして、ここでこのプロセスを繰り返し、繰り返します。この後、RLポリシーは最初のステップのSLポリシーよりもはるかに強力です。
この訓練されたRLポリシーを予測することは、木やバスティングなしで過去のGoゲームのほとんどを既に引き裂いています。
DarkForest Facebookを含めますか?
彼らは彼女と比較しませんでした、それは明らかではありません。
興味深い詳細! 元の記事では、このプロセスは1日間しか継続しなかったと書いています(残りのトレーニングは数週間でした)。
ステップ3:ネットワークをトレーニングしましょう。これは、配置を「一目で」把握することで、勝つチャンスを教えてくれます。 -バリューネットワーク
つまり -1〜1の値を1つだけ予測します。
ポリシーネットワークとまったく同じアーキテクチャ(追加の畳み込み層が1つあるようです)と最後に自然に完全に接続された層があります。
つまり、彼女は同じ機能を持っていますか?
バリューネットワークはもう1つの機能を提供します-プレーヤーは黒でプレイするかしないかを選択します(ポリシーネットワークは色ではなく「友人または敵」の石を転送します)。 私が理解しているように、これは彼女がコミを考慮することができるようにするためです-彼らは2番目に行くので、白のための余分なポイント
人々のゲームのすべてのポジションでトレーニングすることはできません-多くのポジションが同じ結果でゲームに属しているため、そのようなネットワークは過剰になり始めます-つまり 立場を評価する代わりに、それがどの政党であるかを思い出してください
したがって、合成データでトレーニングされます-SLネットワークを介してN個の動きを行い、次にランダムな合法的な動きを行い、RLネットワークを介して結果を見つけるためにプレイし、N + 2(!)でトレーニングします-生成されたゲームごとに1ポジションのみ。
それで、ここにこれらの訓練されたレンガがあります。 どうやって彼らと遊ぶの?
TL; DR:ポリシーネットワークは検索幅を減らすための可能性のある動きを予測し(ノード内で可能な動きよりも少ない)、バリューネットワークは必要な検索の深さを減らすための位置の利点を予測
注意、写真!
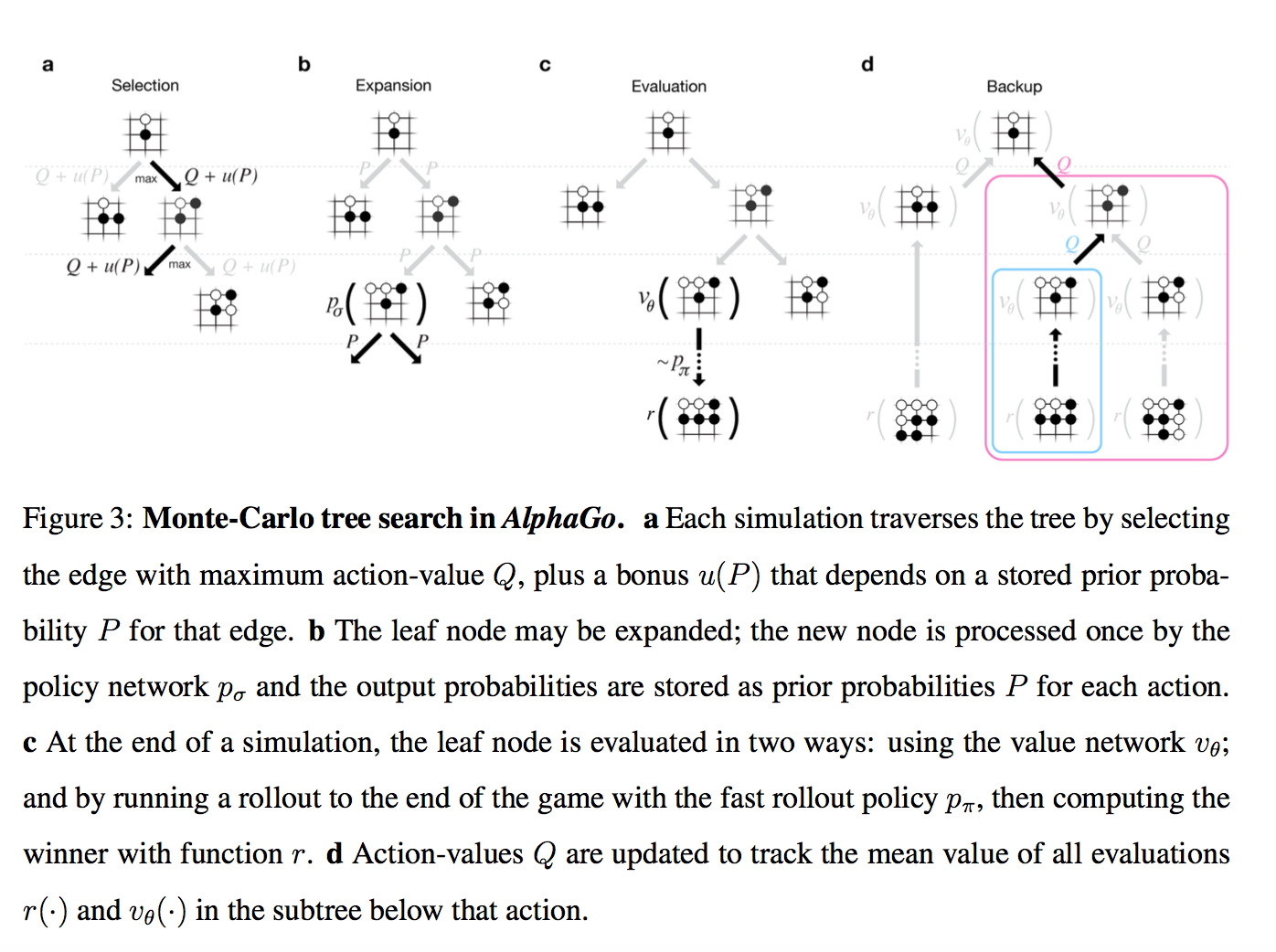
そのため、ルートに現在のツリーがあります。 各ポジションには特定のQ値があり、これはどれだけ勝利につながるかを意味します。
このツリーでは、多数のシミュレーションを同時に実行します。
各シミュレーションは、ツリーを通過して、さらにQ + m(P)がある場所に進みます。 m(P)は、探査を刺激する特別なサプリメントです。 ポリシーネットワークが、この動きがより可能性が高いと考えている場合は大きく、このパスが既に多く移動している場合は小さくなります。
(これは標準的な多腕バンディットテクニックのバリエーションです)
シミュレーションがツリーの葉に到達し、先に進みたい場合、他に何もありません...
次に、新しく作成されたツリーノードが2つの方法で評価されます。
- まず、上記のバリューネットワークを通じて
- 次に、ステップ1の超高速モデルを使用して最後まで再生されます(これはロールアウトと呼ばれます)
これらの2つの推定の結果は特定の重み(リリースでは当然0.5)と混合され、結果のスコアはシミュレーションが通過したツリーのすべてのノードに書き込まれ、各ノードのQはこのノードを通過するすべてのスコアの平均として更新されます。
(かなり複雑ですが、無視することができます)
つまり 各シミュレーションは、ツリーを介して最も有望な領域に到達し(探索を考慮に入れて)、新しい位置を見つけ、評価し、それにつながったすべての動きに沿って結果を書き込みます。 そして、各ノードのQは、そのノードを通過したすべてのシミュレーションの平均として計算されます。
実際には、それだけです。 最良の動きは、最も頻繁に実行されるノードです(このQスコアよりもわずかに安定していることがわかります)。 すべての動きのQスコアが<-0.8の場合、AlphaGoは降伏します。 勝つ確率は10%未満です。
興味深い詳細! ページャーでは、移動Pの初期確率について、RLポリシーではなく、より弱いSLポリシーを使用しました。
経験的には、少し良くなったことが判明しました(リー・セドルとの試合は不可能だったかもしれませんが、ファン・フイとはそのようにプレーしました)。 強化学習は価値ネットワークを訓練するためだけに必要でした
最後に、Fan Huiで遊んだ(そして記事で説明した)AlphaGoのバージョンが、Lee Sedolで遊んだバージョンとどのように異なっていたかについて、次のことが言えます。
- クラスターが大きくなる可能性があります。 この記事の最大クラスターバージョンは280 GPUですが、Fan Huiは176 GPUのバージョンでプレイしました。
- 彼女は移動により多くの時間を費やし始めたようです(記事ではすべての推定値は移動ごとに2秒で与えられています)+特定のMLが時間管理のトピックに追加されました
- 試合前にネットをトレーニングする時間がありました。 私の個人的な疑いは、基本的に強化学習の時間があることです。 元の記事の1日は、なんとなく面白くさえありません。
おそらくそれだけです。 5:0を待っています!
ボーナス : オープンソース実装の試み。 もちろん、まだ、のこぎりで挽きます。