 バージョン8.2以降、 Intel Performance Primitives(IPP)ライブラリは、関数の内部並列化から外部へ体系的に移行します。 この決定の理由は複数のStreamsのImage ProcessingのためのBorder Supportがある記事IPP Functionsで概説されます。
バージョン8.2以降、 Intel Performance Primitives(IPP)ライブラリは、関数の内部並列化から外部へ体系的に移行します。 この決定の理由は複数のStreamsのImage ProcessingのためのBorder Supportがある記事IPP Functionsで概説されます。
この投稿では、最終応答を持つフィルターを実装する関数-FIRフィルター(有限インパルス応答)を検討します。
FIRフィルター
フィルタは、デジタル信号処理で最も重要な分野の1つです。 そしてもちろん、IPPライブラリには、FIR(有限インパルス応答)フィルターを含むこれらのフィルターのほとんどのクラスの実装があります。 FIRフィルターの詳細な説明は、多数の文献またはWikipediaで見つけることができますが、簡単に言えば、FIRフィルターは、いくつかの以前のサンプルと入力離散信号の現在のサンプルにそれらに対応する係数を単に乗算し、これらの製品を追加して、出力信号の現在のサンプルを受け取ります。 またはもう少し形式的に:FIRフィルターは、長さNサンプルの入力ベクトルXを長さNの出力ベクトルYに変換します。入力ベクトルのKサンプルに対応するK係数Hを乗算し、それらを加算します。 係数Kの数は、フィルターの次数と呼ばれます。

図 1. FIRフィルター
ここに:
tapsLenはフィルター次数、
numItersはベクトルの長さです。
この図はIPPライブラリのドキュメントから取られているため、IPPで受け入れられている用語が使用されます。
視覚的に、FIRフィルターは次のように想像できます。
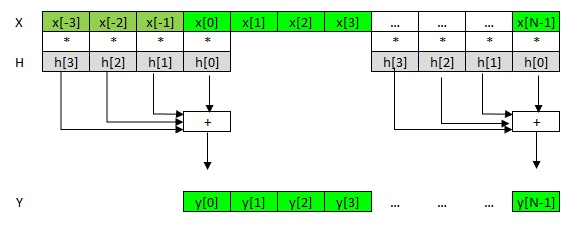
図 2. FIRフィルターの概略図
ご覧のとおり、ここでフィルター次数Kは4であり、4つのフィルター係数hにベクトルxの4つのサンプルを乗算し、合計を出力ベクトルyの1つのサンプルに加算して書き込みます。 フィルタ係数h [3]、h [2]、h [1]、h [0]は、図に一般的に受け入れられている式に従って、xとyに関して逆の順序でメモリ内にあることに注意してください。 1
遅延線
FIRフィルターは通常の畳み込みであるため、長さがNサンプルの出力ベクトルを取得するには、N + K-1個の入力サンプルが必要です(Kはコアの長さ)。 最初のK-1サンプルは「遅延ライン」(遅延ライン)と呼ばれます。 図 2、番号はx [-3]、x [-2]、x [-1]です。 関数に提供されるデータは非常に大きくなる可能性があり、その結果、データは個別に順次処理されるブロックに分割できます。 たとえば、オーディオ信号である場合、オペレーティングシステムによってバッファリングできます。外部デバイスからのデータである場合、通信回線を介して部分的に受信できます。 また、可能性のあるデータの量が事前にわからないため、バッファおよびアプリケーション自体でデータを処理できます。 この場合、作業バッファーには特定の固定長が割り当てられるため、たとえば、一定レベルのキャッシュに収まり、すべてのデータがバッチでこのバッファーを通過します。 このような場合はすべて、遅延線が非常に役立ちます。 データをブロックに分割してもエッジ効果がないように、データを1つの連続したストリームに非常に単純に「接着」するのに役立ちます。
IPP API
IPPライブラリの長年の使用経験から、次の要件を満たすためにFIRフィルタAPIを変更する必要があることが明らかになりました。
- 順次ブロックでベクトルを処理することが可能です。
- 隠されたメモリ割り当てはありません。
- 異なるスレッドでのベクトル処理がサポートされます。
- インプレースモードは許容されました。つまり、入力ベクトルは同時に出力です。
これらすべての要件を同時に満たすために、「入力」および「出力」遅延線の概念が導入され、その後、APIは次のようになり始めました。
FIR Filter API
// Name: ippsFIRSRGetSize, ippsFIRSRInit_32f, ippsFIRSRInit_64f // ippsFIRSR_32f, ippsFIRSR_64f // Purpose: Get sizes of the FIR spec structure and temporary buffer // initialize FIR spec structure - set taps and delay line // perform FIR filtering // Parameters: // pTaps - pointer to the filter coefficients // tapsLen - number of coefficients // tapsType - type of coefficients (ipp32f or ipp64f) // pSpecSize - pointer to the size of FIR spec // pBufSize - pointer to the size of temporal buffer // algType - mask for the algorithm type definition (direct, fft, auto) // pDlySrc - pointer to the input delay line values, can be NULL // pDlyDst - pointer to the output delay line values, can be NULL // pSpec - pointer to the constant internal structure // pSrc - pointer to the source vector. // pDst - pointer to the destination vector // numIters - length of the destination vector // pBuf - pointer to the work buffer // Return: // status - status value returned, its value are // ippStsNullPtrErr - one of the specified pointer is NULL // ippStsFIRLenErr - tapsLen <= 0 // ippStsContextMatchErr - wrong state identifier // ippStsNoErr - OK // ippStsSizeErr - numIters is not positive // ippStsAlgTypeErr - unsupported algorithm type // ippStsMismatch - not effective algorithm. */ IppStatus ippsFIRSRGetSize (int tapsLen, IppDataType tapsType , int* pSpecSize, int* pBufSize ) IppStatus ippsFIRSRInit_32f( const Ipp32f* pTaps, int tapsLen, IppAlgType algType, IppsFIRSpec_32f* pSpec ) IppStatus ippsFIRSR_32f (const Ipp32f* pSrc, Ipp32f* pDst, int numIters, IppsFIRSpec_32f* pSpec, const Ipp32f* pDlySrc, Ipp32f* pDlyDst, Ipp8u* pBuf)
このAPIは、IPPで使用される標準スキームに従います。 まず、 ippsFIRSRGetSize関数を使用して、関数コンテキストと作業バッファーのメモリサイズが要求されます。 次に、 ippsFIRSRInit関数が呼び出され 、そこにフィルター係数が提供されます。 この関数は、pSpec構造体の内部データテーブルを初期化し、 ippsFIRSR処理関数の操作を加速します。 この構造体の内容は、関数の動作中に変化せず、その名前Specに反映されます。したがって、複数のスレッドで同時に使用して、メモリをより効率的に使用できます。 pBufパラメーターは、関数の作業用および変更可能なバッファーであるため、各作業バッファーはスレッドごとに割り当てる必要があります。
サフィックスSRはシングルレートを意味し、MR(マルチレート)フィルターの均一性のために使用されます。MRフィルターの説明は完全に別の記事にすることができます。 numItersパラメーターもMRフィルターから取得されます。この場合、単にベクトルの長さを意味します。
パラメータpSrcは、処理されたブロックx [0]の先頭を指します。
次に、pDlySrcパラメーターとpDlyDstパラメーターの意味を見てみましょう。
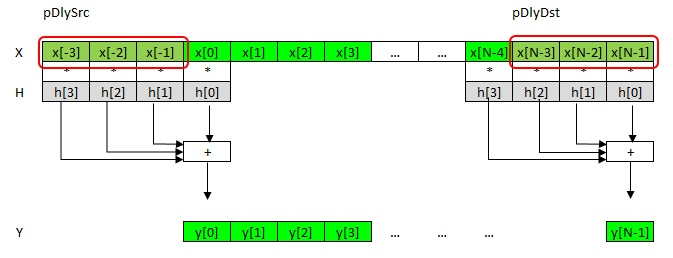
図 3.「入力」および「出力」遅延線
前述のように、x [-3]、x [-2]、x [-1]の必要性は、畳み込み式に由来します。 これらの要素は「入力遅延線」pDlySrcと呼ばれます。 サンプルx [N-3]、x [N-2]、x [N-1]は処理されたベクトルの「テール」です。つまり、 最後のK-1アイテム。 それらは、pDlyDst「出力遅延線」と呼ばれます。 次のブロックでは、それぞれ入力行などになります。
入力遅延ラインpDlySrcは、x [0]の左にあるk-1個のサンプル、他のバッファー、またはNULLを指すことができます。 NULLの場合、入力遅延線のすべての要素が0であると想定されます。これは、データがまだない初期ブロックに便利です。
pDlyDstアドレスは、ブロックの「テール」を記録します。 最後のサンプルのk-1。 値がNULLの場合、何も書き込まれません。
このような2つの遅延線のメカニズムにより、インプレースモードの場合でも、ベクトルの並列処理が可能になります。 ベクトルが上書きされるとき。 これを行うには、最初にブロックの「テール」を個別のバッファーにコピーし、各ストリームへの入力行として送信するだけで十分です。 この記事で使用されているコードの例は、最後に1つのリストで示されています。
ローパスIPP FIRフィルターの使用例。
たとえば、信号の低周波成分のみを残すためにIPP FIRフィルターを使用する方法を検討してください。
元のフィルターされていない信号を生成するには、特別なIPP関数Jaehneを使用します。
pDst [n] = magn * sin((0.5πn2)/ len)、0≤n <len
この機能は、多くのIPP機能がテストされている主力製品です。 生成された信号を最も単純な.csvファイルに書き込み、Excelで画像を描画します。 元の信号は次のようになります。
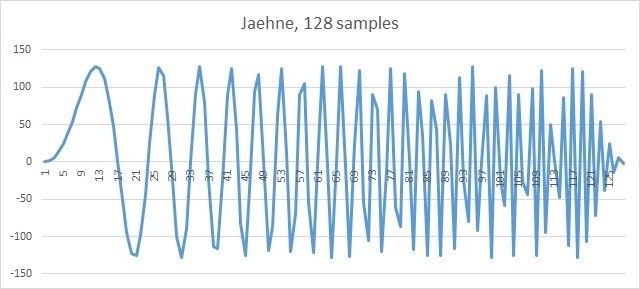
図 4. 128 Jaehne信号サンプル
たとえば、次数31のフィルターを考えます。係数を生成するには、IPP関数ippsFIRGenLowpass_64fが使用されます。 この関数は係数をdoubleでのみ計算するため、floatに変換されます。 付録のfirgenlowpass()関数コードを参照してください。 この関数を呼び出した後、バッファーサイズ、初期化、およびメイン関数ippsFIRSRの呼び出しが計算され、そのパフォーマンスが測定されます。
ローパスフィルターを適用した後、信号に低周波成分が残りました。 位相がシフトしていることに注意してください。ただし、これはすでにFIRフィルター自体のプロパティに従っており、IPPライブラリには適用されません。
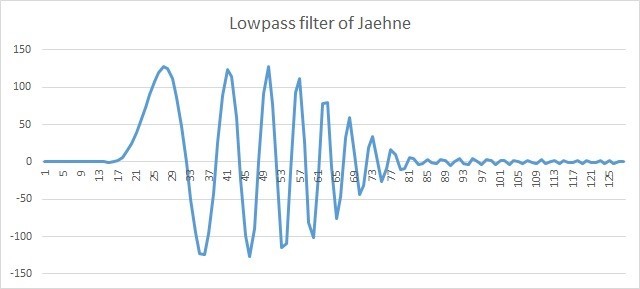
図 5.128ローパスフィルター後のJaehne信号サンプル
これらの図では、FIRフィルターは128サンプルを処理します。入力遅延ラインの30サンプルは0に設定され、pDlySrc = NULLを示します。 出力行pDlyDst = NULLも必要ありません。
マルチスレッドのパフォーマンス
IPPライブラリーの名前にはパフォーマンスという言葉があり、これは最前線にあります。 したがって、AVX2をサポートするプロセッサでのippFIRSR関数のパフォーマンスを測定します。 その後、OpenMPを使用して次のマルチスレッドコードを実装し、測定し、測定結果を1つのグラフにまとめます。
FIRフィルターAPIは、図に示すように、ベクトルを複数のストリームに分割することが単純かつ論理的であるように設計されました。

図 6.スレッド間で元のベクトルを分割する
ストリーム間でベクトルを分割する次の方法が暗示されています。fir_omp関数を参照してください。
Fir_ompコード
void fir_omp(Ipp32f* src, Ipp32f* dst, int len, int order, IppsFIRSpec_32f* pSpec, Ipp32f* pDlySrc, Ipp32f* pDlyDst, Ipp8u* pBuffer) { int tlen, ttail; tlen = len / NTHREADS; ttail = len % NTHREADS; #pragma omp parallel num_threads(NTHREADS) { int id = omp_get_thread_num(); Ipp32f* s = src + id*tlen; Ipp32f* d = dst + id*tlen; int len = tlen + ((id == NTHREADS-1) ? ttail : 0); Ipp8u* b = pBuffer + id*bufSize; if (id == 0) ippsFIRSR_32f(s, d, len, pSpec, pDlySrc, NULL, b); else if (id == NTHREADS - 1) ippsFIRSR_32f(s, d, len, pSpec, s - (order - 1), pDlyDst, b); else ippsFIRSR_32f(s, d, len, pSpec, s - (order - 1), NULL, b); } }
このコードの機能を検討してください。 そのため、フィルターの処理が必要な信号x [0]、...、x [N-1]の次の部分と、入力および出力遅延ラインへのポインター、つまり前の部分とバッファーのテールを受け取りました。現在の部分の「尾」を配置します。 フィルタリングプロセスを高速化し、この部分の処理をスレッド数に対応するT = NTHREADSブロックに分割します。 これを行うには、入力行と出力行を正しく指定し、各ストリームに作業バッファーを割り当てるだけです。
0番目のストリームの場合、 ippsFIRSRが呼び出されたときの入力遅延ラインは前の部分と同じ「テール」であり、他のすべての場合、order-1要素によってシフトされたブロックへのポインターが入力ラインとして提供されます。 そして、最後のストリームのみが部分の「テール」を書き込みます。
上記のアプローチは、結果のベクトルが元のベクトルとは異なるアドレスに書き込まれることを意味します。データが上書きされる場合、遅延線は事前に別のバッファにコピーする必要があります。
このグラフは、AVX2Intel®Core(TM)i7-4770K 3.50Ghz命令をサポートするプロセッサー上の4次31フィルタースレッドのシングルスレッドバージョンとマルチスレッドバージョンのパフォーマンスを示しています。 FIRフィルターの場合、cpMACユニットが使用されます。 操作ごとのメジャー数乗算+加算
cpMAC =(関数実行時間)/(ベクトル長*フィルター次数)
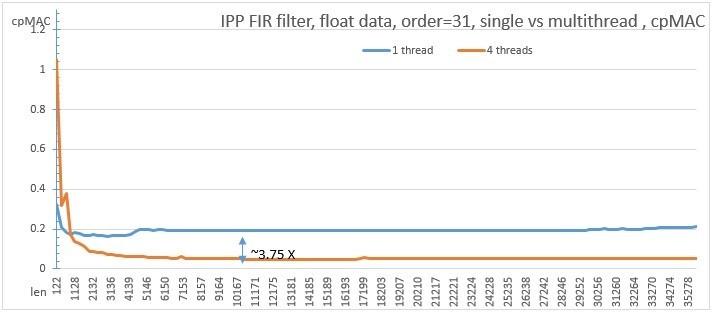
図 7. FIRフィルターのシングルスレッドバージョンとマルチスレッドバージョンのパフォーマンスの比較
関数のスケーリングは非常によく、マルチスレッドバージョンは、4スレッドに非常によく対応するシングルスレッドバージョンよりも十分に長いベクトルで約3.7倍高速に動作することがわかります。 新しいAPIを使用して、シングルスレッドバージョンとマルチスレッドバージョンを切り替えるための基準は、特定のマシンに対して実験的に選択できます。以前のマシンとは異なり、基準はコードに組み込まれ、関数は内部から並列でした。
直接実装とFFT実装の比較
デジタル信号処理では、畳み込みとフーリエ変換の相互マッチングが広く使用されています。
直接実装に加えて、IPP FIRフィルターにはFFTを介した実装もあり、結果のcpMACは、特定のCPUおよび直接アルゴリズムで理論的に可能な値を超えることがあります。
ここで、使用するアルゴリズムのタイプを示すために、algTypeパラメーターの値の1つ-ippAlgDirect ippAlgFFT、ippAlgAutoを使用する必要があります。 最後のパラメーターは、使用されるCPUの固定基準に従って関数がアルゴリズムを選択することを意味し、常に最適とは限りません。
直接アルゴリズムとFFT実装を使用して、1024および128サンプルのベクトル長の異なる次数のフィルターの同じCPUでのパフォーマンスを考慮してください。
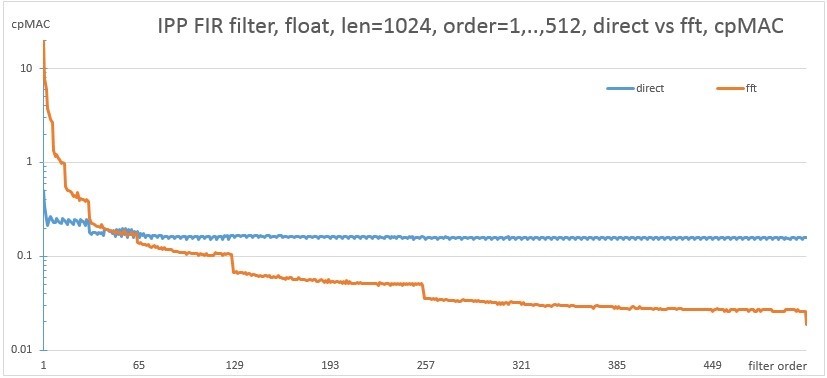
図 8. 1024サンプルの長さでの直接実装とfft実装のパフォーマンスの比較
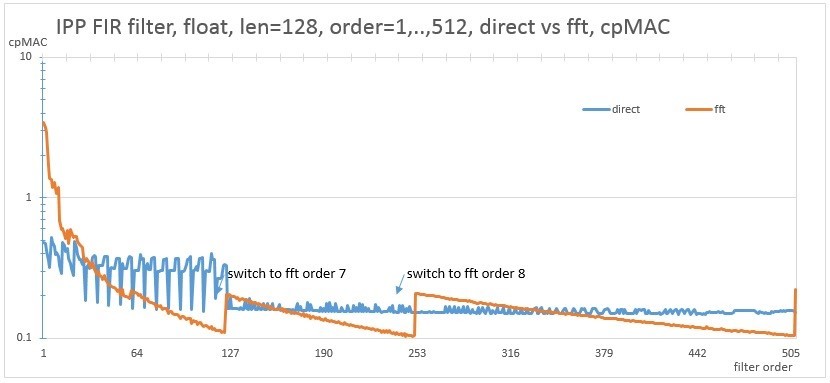
図 9. 128サンプルの長さでの直接実装とfft実装のパフォーマンスの比較
FFTの実装は、ステップによって特徴付けられます。 これは、いくつかの近い次数のフィルターでは、同じ次数のFFTが使用され、FFTの次の次数への遷移がオンになると、パフォーマンスが変化するためです。 最大のパフォーマンスを実現するには、グラフの下にあるアルゴリズムを使用する必要があります。 提案されたAPIを使用すると、両方のバージョンのアルゴリズムを実行して特定のマシンで測定し、最適なものを選択する例を実装できます。 写真は次のようになります。 この図では、X軸に沿ったフィルター次数とY軸に沿ったベクトルの長さの1024x1024のサイズの2次元空間が描かれています。 緑色は、fftアルゴリズムが直接バージョンよりも高速であることを意味します。 図の下部にある特徴的な直線は図に対応しています。 9、次の順序に切り替えた後、fftオプションの動作がしばらく遅くなります。
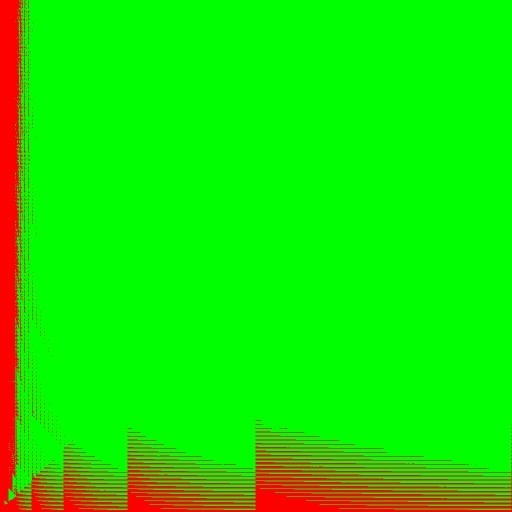
図 10. 1024 x 1024のフィルター空間Xベクトル長次元でのIPP FIRフィルターフロート実装の直接パフォーマンスとfftパフォーマンスの比較
この図は非常に複雑であり、任意のプラットフォームでIPP内に補間することはそれほど容易ではないことがわかります。 さらに、このパターンは特定のマシンによって異なる場合があります。 直接コードとfftコードの選択に加えて、ストリーム数の形式で別の次元を追加できます。これにより、多層的な画像が得られます。 この場合も、提案されたAPIにより、このプラットフォームオプションに最適なオプションを選択できます。
おわりに
IPP 9.0で導入されたFIRフィルターAPIを使用すると、直接アルゴリズムとfftアルゴリズムから最適なオプションを選択し、選択した各オプションを並列化することで、アプリケーションでさらに効率的に使用できます。 さらに、IPPライブラリは完全に無料で、このリンクからダウンロードできますIntel Performance Primitives(IPP)。
アプリケーション。 IPP FIRフィルターのパフォーマンスを測定するサンプルコード
サンプルコード
#include <stdio.h> #include <math.h> #include <omp.h> #include "ippcore.h" #include "ipps.h" #include "bmp.h" void save_csv(Ipp32f* pSrc, int len, char* fName) { FILE *fp; int i; if((fp=fopen(fName, "w"))==NULL) { printf("Cannot open %s\n", fName); return; } for (i = 0; i < len; i++){ fprintf(fp, "%.3f\n", pSrc[i]); } fclose(fp); } Ipp32f* pSrc; Ipp32f* pDft; Ipp32f* pDst; Ipp32f* pTaps; Ipp64f rFreq = 0.2; int bufSize; int NTHREADS = 1; IppAlgType algType = ippAlgDirect; void firgenlowpass(int order) { IppStatus status; Ipp8u* pBuffer; Ipp64f* pTaps_64f; int size; int i; status = ippsFIRGenGetBufferSize(order, &size); pBuffer = ippsMalloc_8u(size); pTaps_64f = ippsMalloc_64f(order); ippsFIRGenLowpass_64f(rFreq, pTaps_64f, order, ippWinBartlett, ippTrue, pBuffer); for (i = 0; i < order;i++) { pTaps[i] = pTaps_64f[i]; } ippsFree(pTaps_64f); } void fir_omp(Ipp32f* src, Ipp32f* dst, int len, int order, IppsFIRSpec_32f* pSpec, Ipp32f* pDlySrc, Ipp32f* pDlyDst, Ipp8u* pBuffer) { int tlen, ttail; tlen = len / NTHREADS; ttail = len % NTHREADS; #pragma omp parallel num_threads(NTHREADS) { int id = omp_get_thread_num(); Ipp32f* s = src + id*tlen; Ipp32f* d = dst + id*tlen; int len = tlen + ((id == NTHREADS-1) ? ttail : 0); Ipp8u* b = pBuffer + id*bufSize; if (id == 0) ippsFIRSR_32f(s, d, len, pSpec, pDlySrc, NULL, b); else if (id == NTHREADS - 1) ippsFIRSR_32f(s, d, len, pSpec, s - (order - 1), pDlyDst, b); else ippsFIRSR_32f(s, d, len, pSpec, s - (order - 1), NULL, b); } } void perf(int len, int order, float* cpMAC) { IppStatus status; IppsFIRSpec_32f* pSpec; Ipp8u* pBuffer; int specSize; Ipp32f* pDlySrc = NULL;/*initialize delay line with "0"*/ Ipp32f* pDlyDst = NULL;/*don't write output delay line*/ __int64 beg=0, end=0; int i, loop = 10000; /*allocate memory for input and output vectors*/ pSrc = ippsMalloc_32f(len); pDst = ippsMalloc_32f(len); pTaps = ippsMalloc_32f(order); /*create special vector Jaehne*/ ippsVectorJaehne_32f(pSrc, len, 128); /*get lowpass filter coeffs*/ firgenlowpass(order); /*get necessary buffer sizes for pSpec and for pBuffer*/ status = ippsFIRSRGetSize(order, ipp32f, &specSize, &bufSize); /*allocate memory for pSpec*/ pSpec = (IppsFIRSpec_32f*)ippsMalloc_8u(specSize); /*for N threads bufSize should be multiplied by N*/ /*allocate bufSize*NTHREADS bytes*/ pBuffer = ippsMalloc_8u(bufSize*NTHREADS); /*initalize pSpec*/ status = ippsFIRSRInit_32f(pTaps, order, algType, pSpec); /*apply FIR filter*/ /*start measurement for sinle threaded*/ if (NTHREADS == 1){ ippsFIRSR_32f(pSrc, pDst, len, pSpec, pDlySrc, pDlyDst, pBuffer); beg = __rdtsc(); for (int i = 0; i < loop; i++) { ippsFIRSR_32f(pSrc, pDst, len, pSpec, pDlySrc, pDlyDst, pBuffer); } end = __rdtsc(); } else { fir_omp(pSrc, pDst, len, order, pSpec, pDlySrc, pDlyDst, pBuffer); beg = __rdtsc(); for (int i = 0; i < loop; i++) { fir_omp(pSrc, pDst, len, order, pSpec, pDlySrc, pDlyDst, pBuffer); } end = __rdtsc(); } *cpMAC = ((double)(end - beg) / ((double)loop * (double)len * (double)order)); printf("%5d, %5d, %3.3f\n", len, order, *cpMAC); ippsFree(pSrc); ippsFree(pDst); ippsFree(pTaps); ippsFree(pSpec); ippsFree(pBuffer); } int main() { int len = 32768; int order; float cpMAC; NTHREADS = 1; algType = ippAlgDirect; //algType = ippAlgFFT; len = 128; printf("\nthreads: %d\n", NTHREADS); printf("len, order, cpMAC\n\n"); for (order = 1; order <= 512; order++){ perf(len, order, &cpMAC); } return 0; }