タスクの簡単な説明は次のとおりです。多数のノードがあり、それらはサーバーに大量のログを送信し、そこで特定の方法で処理および保存する必要があります。 ログの数は、1秒間に約1万〜2万ログで、1秒間に最大100〜150,000の短期的なピークがあります。
次の構成がありました。各Logstash + ElasticSearchに3台のサーバーがあります。 また、単純なjavaを作成して同じサーバーにアップロードしました。これは、TCPを介して単一のアドレスに文字列の形式でログを生成して送信するプログラムです。 中規模サーバー、16コア、32 GBのRAM、ssdなし。
彼らはESを開始するために、indexs.memory.index_buffer_sizeパラメーター(インデックス作成用のバッファーのサイズを設定する)を30%(10%標準に従って)だけ変更し、マニュアルで調べて、logstashの設定ファイルを作成しました。
初期設定
input { tcp { port => "1515" } } output { elasticsearch { cluster => "elasticsearch" embedded => false host => "localhost" index => "performance_test" } }
ジェネレーターを起動して、1秒あたり11,000ログを取得しました。 そして、これはログの処理なしです! それは容認できないほど小さいです。丸太の「爆撃」は言うまでもなく、通常の仕事も生き残れません。 ESのパフォーマンスに関する記事を読み始め、調べ始めたところ、破片とレプリカの数がインデックス作成の速度に大きく影響すると述べました。 ElasticSearchのこのような設定の場合、新しく作成されたインデックスを構成するのはインデックステンプレートです。 言われたよりすぐに、テンプレートを作成しました:
テンプレート
template" : "performance*", "settings" : { "index.number_of_shards" : "9", "index.refresh.interval" : "30s", "index.number_of_replicas" : "0" }, "mappings" : { }, "aliases" : { }
シャードの数を9に変更し、レプリカの数を0に変更して(標準に従って、5つのシャードと1つのレプリカ)、テストを開始しました。 1秒あたり16,000 1.5倍の加速:悪くはないが、それでも十分ではない。 実験を通して、最適な量を見つけました:18シャード、1秒あたり18,000ログ。 それ以上は行きませんでした。 まだ十分ではありません。 動作中にサーバーの負荷スケジュールを確認したところ、プロセッサの負荷は20%であり、負荷はさらに少なく、ioにも依存していません。 したがって、最適化の余地はまだあります! Logstashの設定に行くことにしました。 出力では、workers => 8を設定します。これは、ESにログを送信するために8つの「workers」を使用し、その後、速度が2万\秒に増加したことを示しています。 まだ十分ではありません。
奇妙な方法で、私たちのチームの1人がOOMに関連するLSエラーについて話し合いました;それを解決するには、LSプロセスのメモリ量を制御するLS_HEAP_SIZE環境変数を手動で設定することをお勧めしました(アプリケーションの起動時に-Xmxを入力します)。 Kopfプラグインはヒープの使用を40%(512の200 mb)しか示していませんでしたが、彼らはそれを設定しようとしました。 そしてうまくいきました! 同じ設定で、デフォルトのLS_HEAP_SIZEでLS_HEAP_SIZE = 8GBで2万件、1秒あたり38,000件のログが判明しました。
注意深い読者は、ESクラスターが3つのサーバーで構成され、生成するアプリケーションが1つであるという不一致に気付いている必要があります。 したがって、以前のテストでは、アプリケーションは3つのサーバーのいずれかにログを書き込みました。 完全なテストのために、LS設定を3つすべてのサーバーにコピーし、すべてをLS_HEAP_SIZE = 8gbに設定し、3つの生成アプリケーションを起動し、意性が3倍に増加することを期待しました(38 * 3 = 1秒あたり114千ログ)が、95万であることが判明しました。 忘れないでください:ログの処理はまだありません。
ESおよびLS設定のさらなる研究は状況を改善せず、現在のパフォーマンスは私たちに適合しませんでした。クライアントが1秒あたり32,000ログを1つのサーバーに書き込むことができないためです。 生成アプリケーションとLogstashの間にバッファーを使用することを考え、読み、使用することにしました。 そのため、Redisが動作する可能性がありますが、最初はよりシンプルなものを実装することにしました。
そして、私たちが得たものは次のとおりです。Logstashにログを直接送信する代わりに、Rsyslogを受け入れてファイルに入れます。 テストによると、ログの受信と記録におけるRsyslogのパフォーマンスは1秒あたり約570,000ログに達し、これは私たちのニーズを数回カバーしました。 これらのログは、ファイルからlogstashによって読み取られ、logstashによって処理されてESに送信されます。
その結果、LS構成は次のようになりました。
最終構成
input { file { path => "/root/logs/log.log" start_position => "end" } } output { elasticsearch { cluster => "elasticsearch" embedded => false host => "localhost" index => "performance_testing" workers => "8" } }
3つのサーバーですぐにテストし、66千\秒を受け取りました。 しかし、現在では、任意のサイズのピークに耐えることができます(最も重要なのは、あまり頻繁ではないため、平均ログストリームが66,000ログ/秒を超えないようにするため)。
これに落ち着いたので、ログの処理を追加しました。 処理は純粋にシンボリックであり、Grokフィルターと5つのif条件を介してログを解析するだけです。
Grokフィルター
filter { grok{ match => {"message" => "%{MONTH:month} %{NUMBER:date} %{TIME:time} %{URIHOST:sender} %{WORD:grokanchor} %{NUMBER:mstatus} %{WORD:salt}"} remove_field => ["grokanchor"] } if [mstatus]{ if [mstatus] > "90"{ mutate { add_tag => ["morethanninety"] } } else if [mstatus] > "80"{ mutate { add_tag => ["morethaneighty"] } } else if [mstatus] > "70"{ mutate { add_tag => ["morethanseventy"] } } else if [mstatus] > "60"{ mutate { add_tag => ["morethansixty"] } } else if [mstatus] > "50"{ ate { add_tag => ["morethanfifty"] } } } }
すぐに3台のサーバーでテストし、46,206ログ/秒の数値を受け取りました。これは、アプリケーションの通常の動作、およびファイルからのデータの処理(ピーク後のバッファー)にはすでに十分です。
ただし、BUTが1つあります。開発者の1人は、ESのパフォーマンスが時間とともに低下する可能性があると考えていました。 確認することにしました-停止することなくシステムを9時間動作するように設定しました。 結果は心強いものではありませんでした。最初の数時間はすべてが順調でしたが、その後パフォーマンスが大幅に低下し始めました。
1時間あたりのログ数 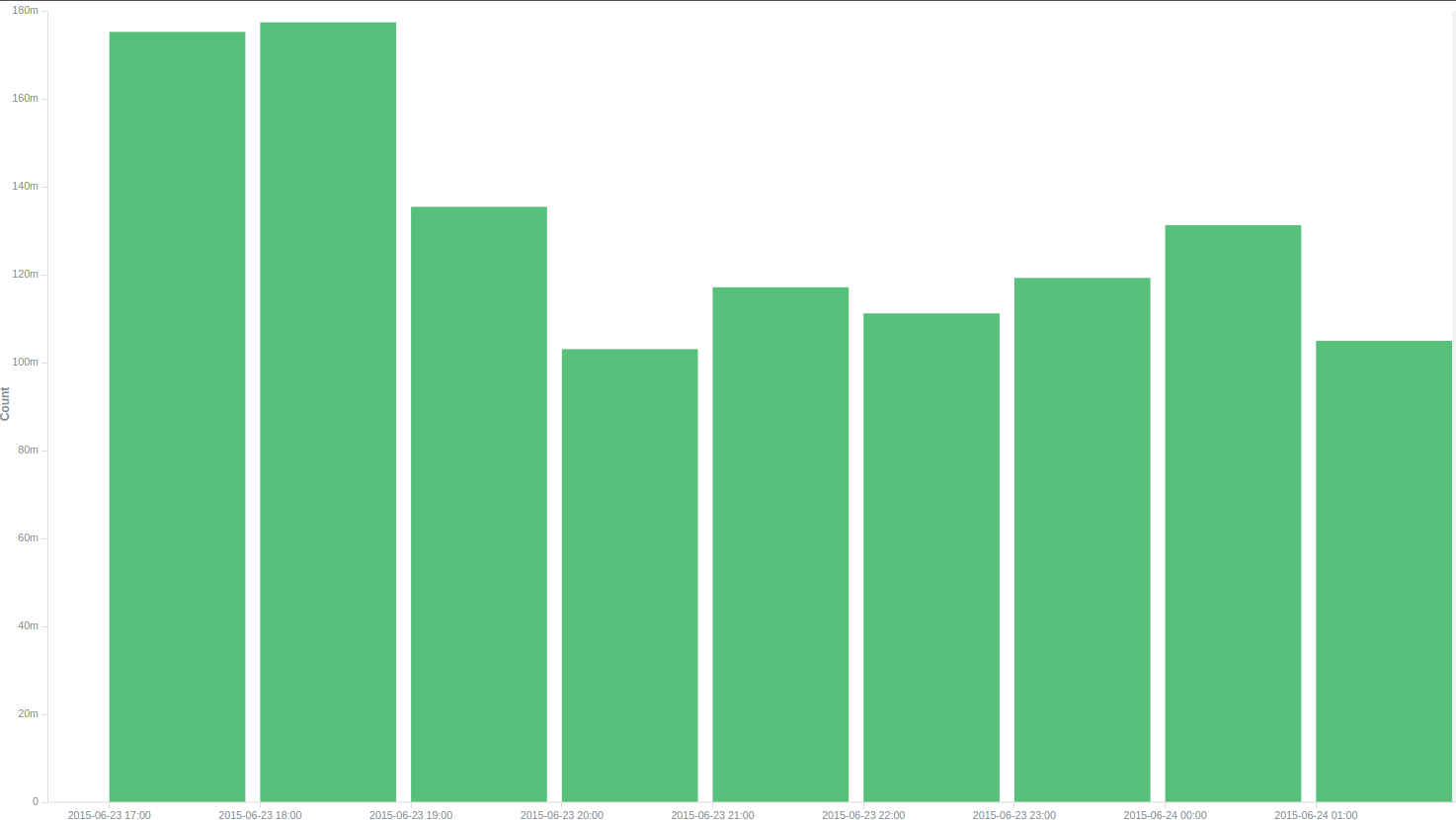
5時間後、私たちは再び世代を開始し、すでにおなじみの4万6千人を受け取りました。 9時間で1 203 453 573のログを生成しました。これは、1秒あたり37143のログに関して取得されます。 システムの通常の動作ははるかに小さいボリューム用に設計されるため、これに非常に満足していると判断しました。 ESのこの動作は、30秒ごとにインデックスを「再構築」する必要があるという事実によるものであることが示唆されました(設定により表示)、その量はこの量の情報でテラバイトになる傾向があるため、彼は長いです。 サーバーログを間接的に調べたところ、推測が裏付けられました。サーバーはiowaitに置かれ、ディスクからの大量の読み取りが行われました。
サーバー負荷 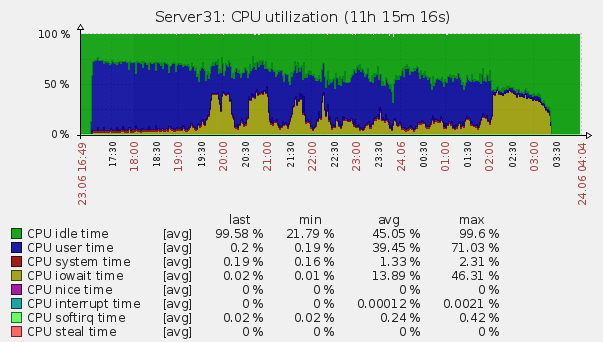
これが何に関連していて、どのように解決するかを誰かがもっと詳しく知っているなら、あなたのコメントを待っています。