システムの一般的なスキームを思い出してください。
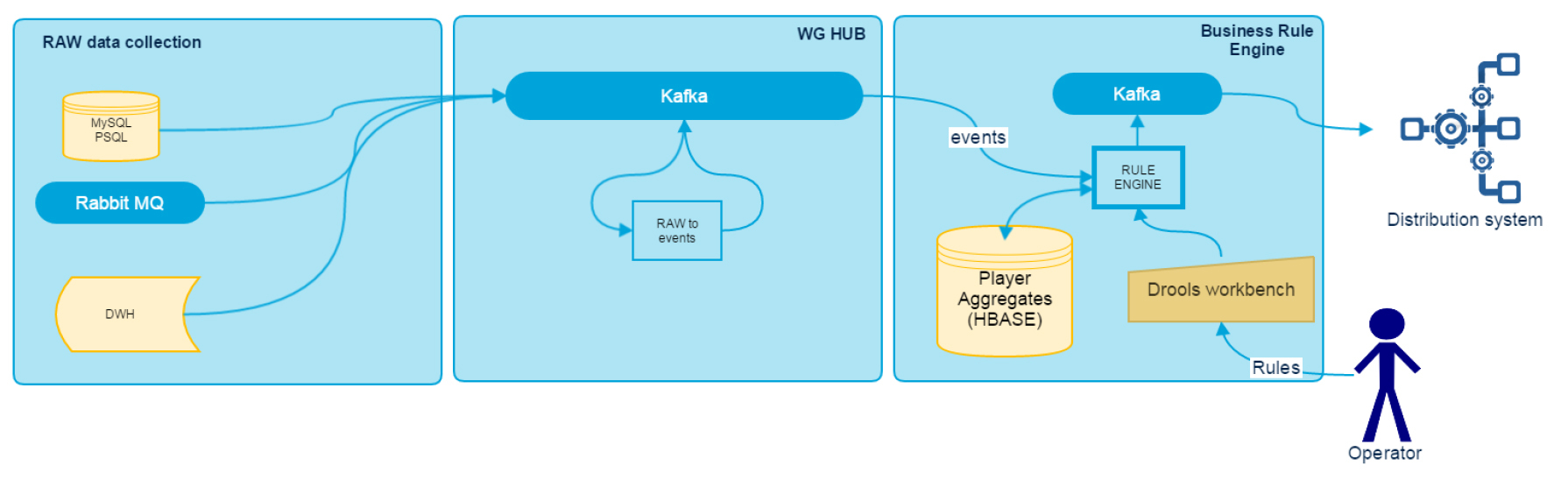
RAW Data Collectionブロックは、最初の記事で説明されており、スタンドアロンアダプターのコレクションです。
次の2つは、並列ストリーミングデータ処理に基づいています。 Spark Streamingはフレームワークとして使用されます。 なぜ彼は正確に? 単一のHadoopディストリビューションであるClouderaを使用することが決定されました。Clouderaには、Spark、HBase、Kafkaが含まれています。 さらに、当時の同社はすでにSparkの専門知識を持っていました。
生データトランスフォーマー
WG Hubサブシステムの入力では、さまざまなデータソースから多くの情報を取得しますが、そのすべてが直接使用できるわけではなく、何らかの変換が必要です。 生データを変換するには、RDT(Raw Data Transformer)モジュールを使用します。これは、データソースを統合するためのすべてのビジネスロジックを収集します。 出力では、すでに標準化されたメッセージを取得します。これは、一連の属性を持つ特定の名前付きイベントです。 これは、シリアル化されたJavaオブジェクトとしてKafkaに書き込まれます。 入力では、RDTはデータソースの数に等しいトピックの数を処理し、出力では、プレーヤーの識別子で分割されたさまざまなイベントのストリームを持つ1つのトピックを取得します。 これにより、その後の処理中に、特定のプレーヤーのデータがパーティションに割り当てられた1つのエグゼキューターによってのみ処理されることが保証されます(Spark Streaming directStreamを使用する場合)。
このモジュールの主な欠点は、入力データの構造が変更された場合にコードを編集して再レイアウトする必要があることです。 現在、モジュールをより柔軟にし、コードを記述する必要なくロジックを変更するために、特定のメタ言語の変換のユースケースに取り組んでいます。
ルールエンジン
このモジュールの主な目的は、データバス内のイベントに応答し、ユーザーが設定したロジックに基づいてプレーヤーに関するいくつかの蓄積された履歴データを最終システムに通知するルールを作成する機会をエンドユーザーに提供することです。 ルールエンジンの基礎は、Droolsに落ち着くまで十分に長く選択されました。 なぜ彼は:
- Javaであるため、統合の問題が少ない
- キットは最も便利ではありませんが、ルールを作成するためのGUIです。
- アプリケーションを再起動せずにルールを更新できるKieScannerコンポーネント
- 追加のサービスをインストールせずにDroolsをライブラリとして使用する機能
- 十分に大きなコミュニティ
プレーヤーの履歴情報のストアとして、HBaseが使用されます。 すべての処理はプレーヤーの識別子によって実行され、HBaseはリージョン間のロードバランシングとデータシャーディングにうまく対処するため、ここのNoSQLストレージは素晴らしいです。 ほとんどすべてのデータがblockCacheに収まる場合、最適な応答が得られます。
概略的に、BREの作業は次のとおりです。

Droolsはルールをコンパイル済みのJARファイルとして配布するため、最初の段階でローカルMavenをインストールし、pom.xmlのdistributionManagementセクションを通じてリポジトリにデプロイするようにWorkbenchでプロジェクトを設定しました。
Sparkアプリケーションが起動すると、各エグゼキューターは個別のDrools KieScannerプロセスを起動し、Mavenのルールでアーティファクトを定期的にチェックします。 アーティファクトをチェックするためのバージョンはLATESTにインストールされます。これにより、新しいルールが表示された場合に現在の実行中のコードにロードできます。
新しいイベントがKafkaに到着すると、BREは処理用のパケットを受信し、HBaseから各プレーヤーの履歴データのブロックを減算します。 さらに、イベントはプレイヤーのデータとともにDrools StatelessKieSessionに送信され、そこで現在ロードされているルールへの準拠がチェックされます。 その結果、トリガーされたルールのリストがKafkaに記録されます。 ゲームクライアントでユーザーへのヒントや提案が形成されるのは、その基礎に基づいています。
DDRRE:最適化および改善
HBaseに保存するための履歴データのシリアル化。 実装の最初の段階では、Jackson JSONを使用しました。その結果、同じPOJOが2つの場所で使用されました(ルールを作成するときのワークベンチとJackson)。 これにより、ストレージ形式の最適化が大幅に制限され、複雑なジャクソン注釈を使用することになりました。 次に、オブジェクトのビジネス記述をストレージオブジェクトから分離することにしました。 後者として、protobufスキームによって生成されたクラスが使用されます。 その結果、ワークベンチで使用されるPOJOは、人間が読める構造、明確な名前を持ち、protobufオブジェクトの一種の「プロキシ」です。
HBaseのクエリ最適化。 サービスのテスト操作中に、ゲームの詳細のために、同じアカウントからのいくつかのイベントが処理パックに頻繁に分類されることに気付きました。 HBaseへのアクセスは最もリソースを消費する操作であるため、バンドルごとにアカウントを識別子で事前にグループ化し、グループごとに1回履歴データを読み取ることにしました。 この最適化により、HBaseへのリクエストを3〜5倍減らすことができました。
データの局所性の最適化。 クラスターでは、マシンはKafka、HBase、およびSparkを同時に組み合わせます。 処理はKafkaの読み取りから始まるため、読み取り可能なパーティションのリーダーに従ってローカリティが実行されます。 ただし、処理プロセス全体を考慮すると、HBaseから読み取られるデータの量が着信イベントからのデータの量を大幅に超えることが明らかになります。 したがって、このデータをネットワーク経由で送信すると、より多くのリソースが消費されます。 プロセスを最適化するために、Kafkaからデータを読み取った後、HBaseリージョンごとにデータを再グループ化し、それに局所性を公開するシャッフルを追加しました。 その結果、個々のSparkタスクが以前のようにすべてではなく1つの特定のHBase領域のみを参照するため、ネットワークトラフィックが大幅に削減され、パフォーマンスが向上しました。
Sparkが使用するリソースの最適化。 処理時間の戦いでは、spark.locality.waitも削減しました。これは、処理されるパーティションが多くなり、エグゼキューターが少なくなるため、ローカリティ待機が処理時間よりもはるかに長くなるためです。
現在のバージョンでは、モジュールはタスクに対応していますが、最適化の余地はまだ多くあります。
DDRREを拡張する計画には、Rule as a Serviceの作成が含まれます。これは、ゲーム内イベントではなく、APIを介した外部サービスからの要求に応じてルールをトリガーできる特別なシステムです。 これにより、「このプレーヤーにはどの評価がありますか?」、「どのセグメントに属していますか?」、「どの製品が最適ですか?」などのクエリに答えることができます。