データドリブンリアルタイムルールエンジンは、大量のデータをリアルタイムで分析することにより、ユーザーが最後のゲーム体験のコンテキストに基づいて受信した推奨事項を通じて、プレーヤーとのやり取りをパーソナライズできる特別なシステムです。
DDRREを使用すると、プレーヤーはゲームからより多くの楽しみを得ることができ、ユーザーエクスペリエンスが向上します。また、不要な広告やプロモーションメッセージを表示する必要がなくなります。
DDRREアーキテクチャ
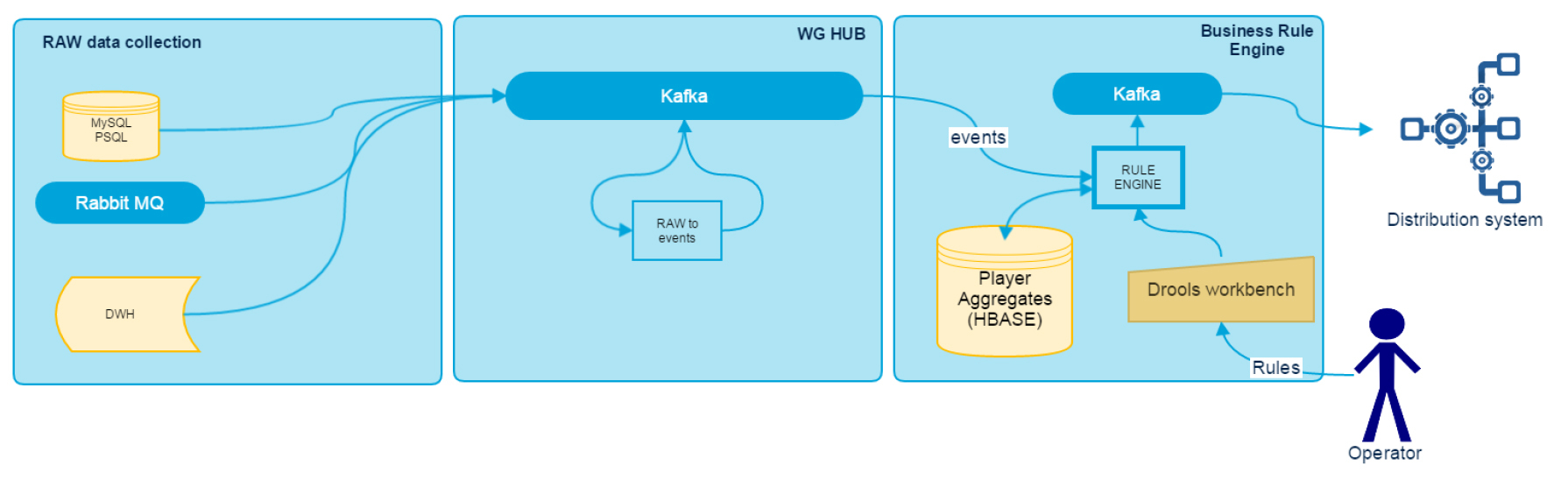
データドリブンリアルタイムルールエンジンは、RAWデータコレクション、WG HUB、ビジネスルールエンジンなどの複数のコンポーネントに分割できます。 それらのアーキテクチャは図で見ることができます。
この記事では、データを収集および分析するためのアダプターについて説明します。また、以下の出版物では、システムの他のコンポーネントを詳細に検討します。
データ収集は、Kafkaを使用する共通バスを使用して実行されます。 すべてのゲームサブシステムは、確立された形式のログをリアルタイムでバスに書き込みます。 技術的な制限によりこれを実行できないサブシステムについては、ログを収集してKafkaにリダイレクトするアダプターを作成しました。 特に、スタックには、MySQL、PSQL、RabbitMQのアダプターと、Hive JDBCインターフェースを介してアーカイブデータをDWHからダウンロードするためのアダプターが含まれています。 これらはそれぞれ、処理速度と遅延に関するメトリックをソースからJMXにエクスポートします。この場合、Grafanaはデータの視覚化に使用され、Zabbixは問題の通知に使用されます。 すべてのアダプターは、Java 8およびScalaのスタンドアロンJavaアプリケーションとして設計されています。
MySQL用アダプター、PSQL
カフカのプロデューサーが書かれているタングステン複製機に基づいています。 レプリケーションを使用します。これは、データソースのデータベースサーバーに追加の負荷をかけることなくデータを取得するための信頼できる方法です。
タングステンの現在のパイプラインは次のとおりです。
replicator.pipelines =スレーブ
replicator.pipeline.slave = d-binlog-to-q、q-to-kafka
replicator.pipeline.slave.stores =並列キュー
replicator.pipeline.slave.services =データソース
replicator.pipeline.slave.syncTHLWithExtractor = false
replicator.stage.d-binlog-to-q = com.continuent.tungsten.replicator.pipeline.SingleThreadStageTask
replicator.stage.d-binlog-to-q.extractor = dbms
replicator.stage.d-binlog-to-q.applier = parallel-q-applier
replicator.stage.d-binlog-to-q.filters = replicate、colnames、schemachange
replicator.stage.d-binlog-to-q.blockCommitRowCount = $ {replicator.global.buffer.size}
replicator.stage.q-to-kafka = com.continuent.tungsten.replicator.pipeline.SingleThreadStageTask
replicator.stage.q-to-kafka.extractor = parallel-q-extractor
replicator.stage.q-to-kafka.applier = asynckafka
replicator.stage.q-to-kafka.taskCount = $ {replicator.global.apply.channels}
replicator.stage.q-to-kafka.blockCommitRowCount = $ {replicator.global.buffer.size}
ここでasynckafkaモジュールは私たちによって書かれています。
Asynckafkaは前のステージからデータを受け取り、Kafkaに書き込みます。 最後に記録されたオフセットは、Kafkaに常に存在するため、zookeeperに保存されます。 あるいは、タングステンはデータをファイルまたはMySQLに保存できますが、これはアダプターを備えたホストが失われた場合にはあまり信頼できません。 このケースでは、クラッシュ中にモジュールがオフセットを読み取り、Kafkaに保存された最後の値からbinlogの処理が続行されます。
カフカで録音
override def commit(): Unit = { try { import scala.collection.JavaConversions._ val msgs : java.util.concurrent.ConcurrentLinkedQueue[(String,String,String,Option[Callback])] = new java.util.concurrent.ConcurrentLinkedQueue[(String,String,String,Option[Callback])]() data.foreach(e => { msgs.addAll(ruleProcessor.get.processToMsg(e._1, e._2).map(e => (e._1, e._2, e._3, None))) }) kafkaSender.get.send(msgs.toSeq:_*) } catch { case kpe: KafkaProducerException => { logger.error(kpe.getMessage, kpe) throw new ReplicatorException(kpe); } } lastHeader.map(saveLastHeader(_)) resetEventsToSend() }
オフセットの保存
def saveLastHeader(header: ReplDBMSHeader): Unit = { zkCurator.map { zk => try { val dhd = DbmsHeaderData( header.getSeqno, header.getFragno, header.getLastFrag, header.getSourceId, header.getEpochNumber, header.getEventId, header.getShardId, header.getExtractedTstamp.getTime, header.getAppliedLatency, if (null == header.getUpdateTstamp) { 0 } else { header.getUpdateTstamp.getTime }, if (null == header.getTaskId) { 0 } else { header.getTaskId }) logger.info("{}", writePretty(dhd)) zk.setData().forPath(getZkDirectoryPath(context), writePretty(dhd).getBytes("utf8")) } catch { case t: Throwable => logger.error("error while safe last header to zk", t) } } }
オフセット回復
override def getLastEvent: ReplDBMSHeader = { lastHeader.getOrElse { var result = new ReplDBMSHeaderData(0, 0, false, "", 0, "", "", new Timestamp(System.currentTimeMillis()), 0) zkCurator.map { zk => try { val json = new String(zk.getData().forPath(getZkDirectoryPath(context)), "utf8") logger.info("found previous header {}", json) val headerDto = read[DbmsHeaderData](json) result = new ReplDBMSHeaderData(headerDto.seqno, headerDto.fragno, headerDto.lastFrag, headerDto.sourceId, headerDto.epochNumber, headerDto.eventId, headerDto.shardId, new Timestamp(headerDto.extractedTstamp), headerDto.appliedLatency, new Timestamp(headerDto.updateTstamp), headerDto.taskId) } catch { case t: Throwable => logger.error("error while safe last header to zk", t) } } result } }
RabbitMQ用アダプター
あるキューから別のキューにデータを転送するかなり単純なアダプター。 レコードは1つずつKafkaに転送され、その後RabbitMQで確認が行われます。 サービスは少なくとも1回メッセージを配信することが保証されており、データ処理側で重複排除が行われます。
RabbitMQConsumerCallback callback = new RabbitMQConsumerCallback() { @Override public void apply(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) { // callback- RabbitMQ String routingKey = envelope.getRoutingKey(); Tuple3<String, String, String> routingExpr = routingExprMap.get(routingKey); // topic Kafka routingKey if (routingExpr == null) throw new RuntimeException("No mapping for routing key " + routingKey); String expr = routingExpr._1(), topic = Objects.firstNonNull(routingExpr._2(), kafkaProducerMainTopic), sourceDoc = routingExpr._3(); Object data = rabbitMQConsumerSerializer.deserialize(body); // , RabbitMQMessageEnvelope msgEnvelope = new RabbitMQMessageEnvelope(envelope, properties, data, sourceDoc); // byte[] key = getValueByExpression(data, expr).getBytes(); byte[] msg = kafkaProducerSerializer.serialize(msgEnvelope); kafkaProducer.addMsg(topic, key, msg, envelope.getDeliveryTag()); // Kafka try { checkForSendBatch(); } catch (IOException e) { this.errBack(e); } } @Override public void errBack(Exception e) { logger.error("{}", e.fillInStackTrace()); close(); }
DWH用アダプター
履歴データを処理する必要がある場合、DWHを使用します。 ストレージはHadoopテクノロジー上に構築されているため、HiveまたはImpalaを使用してデータを取得します。 読み込みインターフェイスをより汎用的にするために、JDBCを使用して実装しました。 DWHを使用する際の主な問題は、その中のデータが正規化されていることです。ドキュメント全体を収集するには、いくつかのテーブルを組み合わせる必要があります。
入り口にあるもの:
•必要なテーブルのデータは日付ごとに分割されます
•データをダウンロードする期間がわかっている
•ドキュメントグループ化キーは、各テーブルで既知です。
テーブルをグループ化するには:
•Spark SQLデータフレームを使用する
•与えられた範囲の日付でサイクルを統合する
•キーを1つのドキュメントにグループ化して複数のDataFrameを結合し、Sparkを使用してKafkaに書き込みます。
プロパティファイルを使用してデータソースを構成する例。
hdfs_kafka.dataframe.df1.uri="jdbc:hive2://[HiveUri]:10000/test;user=hdfs" // jbdc uri hdfs_kafka.dataframe.df1.sql=select * from test.log_arenas_p1_v1 where dt='%s' hdfs_kafka.dataframe.df1.keyField=arena_id // SQL- '%s' hdfs_kafka.dataframe.df1.outKeyField=arena_id // , . hdfs_kafka.dataframe.df1.tableName=test.log_arenas_p1_v hdfs_kafka.dataframe.df2.uri="jdbc:hive2://[HiveUri]:10000/test;user=hdfs" hdfs_kafka.dataframe.df2.sql=select * from test.log_arenas_members where dt='%s' hdfs_kafka.dataframe.df2.keyField=arena_id hdfs_kafka.dataframe.df2.outKeyField=arena_id // , Kafka hdfs_kafka.dataframe.df2.tableName=test.log_arenas_members_p1_v // ,
この例では、2つのDataFrameを構築しています。
アプリケーションは、指定された日付間の日数を計算し、構成ファイルからサイクルを実行します。
hdfs_kafka.from = 2015-06-25
hdfs_kafka.to = 2015-06-26
val dates = Utils.getRange(configuration.dateFormat, configuration.from, configuration.to) // , sql dates.map( date => { // val dataFrames = configuration.dataframes.map( dfconf => { val df = executeJdbc(sqlContext, Utils.makeQuery(dfconf.sql, date), dfconf.uri) (dfconf, df) }) val keysExtracted = dataFrames.map( e => { // DataFrame dataFrameProcessor.extractKey(e._2.rdd, e._1.keyField, e._1.tableName) }) // RDD[Key, Row] keyBy keyField val grouped = keysExtracted.reduce(_.union(_)).map( e => (e._1, Seq(e._2))) // dataFrame grouped.reduceByKey(_ ++ _) // Row dataFrameProcessor.applySeq(grouped) }) //
収集された情報の処理がどのように実行されるか、およびDDRREの他のコンポーネントについては、次の投稿でお知らせします。 説明されている技術について質問がある場合は、コメントでそれらを確認してください。