作業では、よく知られているミドルウェアツール( Wwise 、 Fmod )を使用せず、標準のUnreal Engine 4ツールを使用しません。
一般的な作業計画
すべての作業は、いくつかの主要な段階に分けることができます。
- コンセプト-質問について考える:どのように音を出しますか? どのように実装しますか?
- オーディオシーケンサーのサウンドデザイン-必要なすべてのwavファイルを準備します。
- Unreal Engine 4のサウンドデザイン-wavファイルを導入し、アセットを作成し、アニメーションに添付します。
次に、順番に。
1.コンセプト
ゲームはディーゼルパンクスタイルで行われます。つまり、メカニカルサウンドを使用します。 電子機器やSF要素は使用しないでください。 これはロボットではなく、鎧です。 中は男です。 人間はメカニズムとシステムに囲まれています。
有声装甲はゲームの強力なピースです。 音は明らかにミニチュアまたはキュートであってはなりません。 そのようなキャラクターを見るとき、この男が真面目であることを理解しなければなりません。
キャラクターを詳しく見てみましょう-彼はヘルメットを着用しています、彼は特定のシステムを持つランドセルを持ち、それらに流体があり、鎧自体は非常に可動性であると仮定します-多くの機械部品と構造があります。 これをサウンドの主なカテゴリとして使用します。
- 声。
- サッチェル。
- 金属/機械音。

音声には標準的な人間の呼吸を使用しますが、これを水成分と混合し、処理して「ヘルメット」効果を与えます。 ナップザックには、水性成分と酸性成分も使用します。 メカニック/金属には、金属のガラガラ、サーボドライブ、あらゆる種類の機械的なガサガサを使用します。
Sound Cueと対応するアニメーションへのアタッチメントを使用して、標準のUnreal Engineツールを使用してプロジェクトに導入します。
2.オーディオシーケンサーのサウンドデザイン
サウンドデザインには、オーディオ操作用の非常にシンプルで興味深いプラグインが既に付属しているため、 Ableton Liveを使用します。プログラムのデザインは高速オーディオに焦点を合わせています。
ソース素材については、自分で音を録音する予定でした。 しかし、適切な機器のコスト、録音の余地、録音自体の時間、素材の処理を考慮すると、これは私たちにとって次のステップになるという結論に達しました。 現時点では、オーディオライブラリの素材に限定しています。 例外は音声です。 試用後、自分で記録できることが明らかになりました。
2.1。 声
音声録音には、 MK-101のカプセル付きの国産Oktava MK-012マイクを使用しました。 それは安価であり、受け取った素材を深刻に歪めるという事実を考えると、録音品質は私たちにとってそれほど重要ではありません。 記録の結果は次のとおりです。
これは、処理された素材の音です:
処理の本質は、ボコーダーを使用することです。 私たちはその中の声を水ベース(水の泡)と混ぜ、さらに各チャンネルを処理して味わいます。 私の設定の詳細な処理スキームはここにあります:
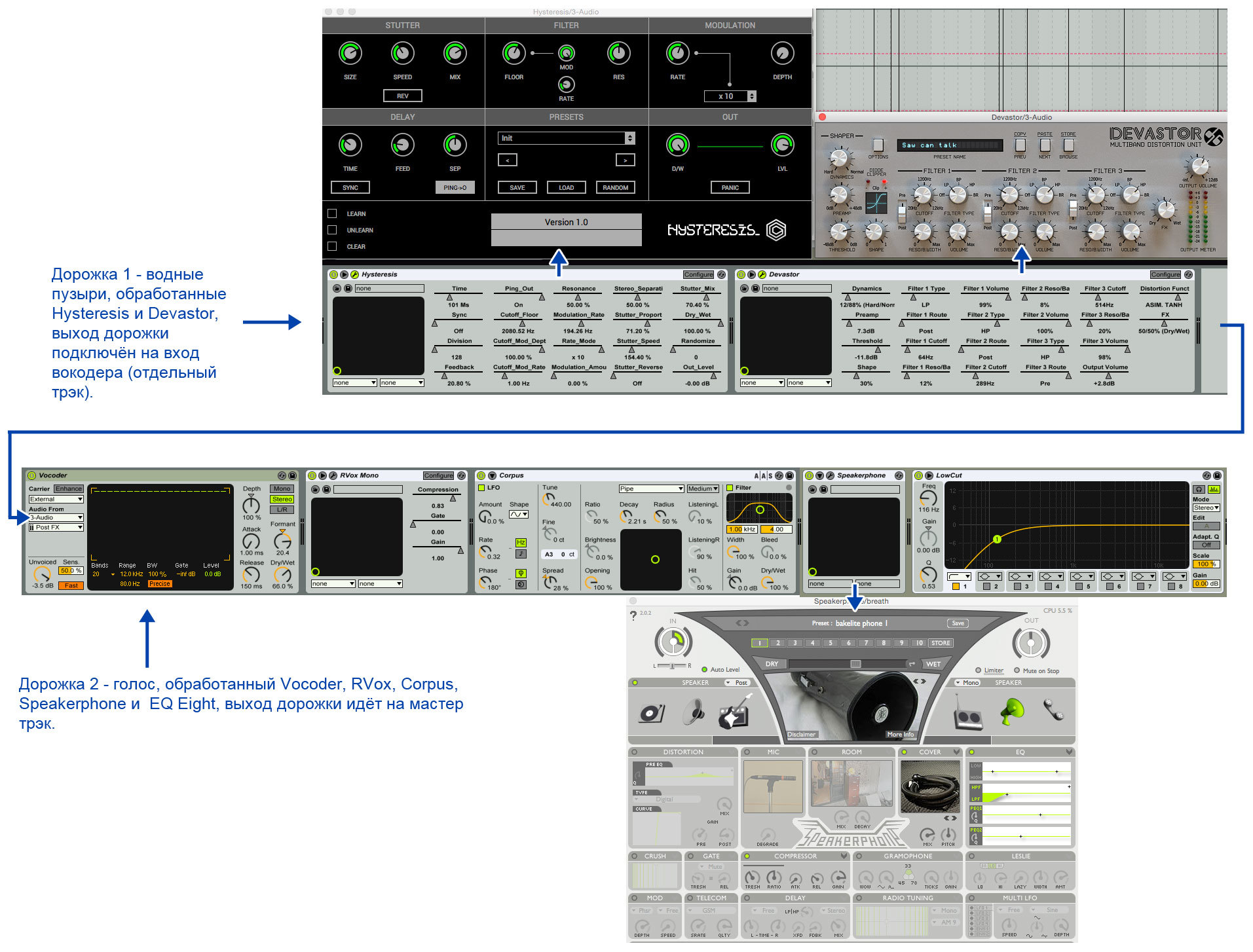
2.2。 サッチェル
ランドセルの場合、次の材料を使用します。
- 空気蒸気(スチーム)。
- 水の泡-音声による前方通信。
- ゴロゴロ音のアナログシンセサイザー-色を追加します。 シンセサイザーでは、ノートla(A-1)のみを使用します。 マイナーのゲームの主な鍵。 もちろん、このコンポーネントはほとんど聞こえず、ほとんどの場合、潜在意識レベルで機能しますが、すべてがここで大丈夫であればより良いでしょう。
- 軽い電気火花。
- シューという酸。
すべてを1つのボイラーに投入して処理し、これらのサウンドを取得します。
私の設定の詳細な処理スキームはここにあります:
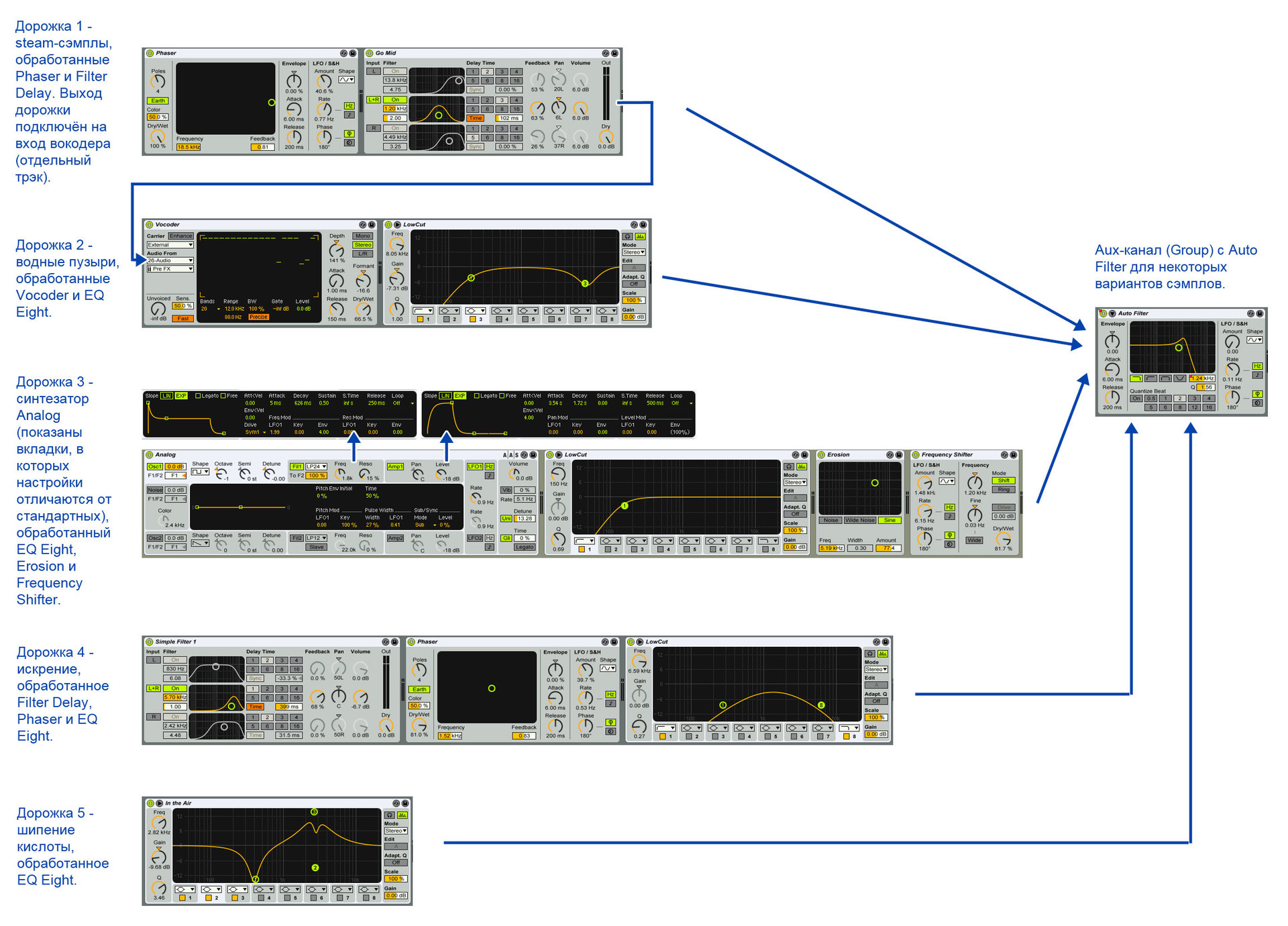
2.3。 力学/金属
デザイン全体の主要部分-鉄の鎧を扱っていることを明確にします。 ここには特別なトリックはありません。すべては、最小限の効果(イコライザー)で標準レイヤー(レイヤー)で行われます。 そのような作業の例として、キャラクターの死を見ることができます。 まず、打撃(抽象的な「何か」に襲われる)が聞こえます。次に、落下する鎧のガラガラと落下が聞こえます。 シーケンサーでは次のようになります(元のサンプルのレイヤーが表示されます)。

音は次のとおりです。
すべてのwavファイルがレンダリングされた後、それらをサウンドエディターに駆動し( Adobe Auditionを使用)、それらを編集して終了します(最後に無音部分を切り取り、可能性のあるアーティファクトを削除します)。 すべてのファイルは44.1kHz、16ビット、モノラルです。 アンリアルエンジン4でダウンロードできるサウンドファイルのパックを入手します。
2. Unreal Engineのサウンドデザイン
ここでのタスクは、Unreal Engineツールを使用して、シーケンサーで行われた作業を再現することです。 準備したwavファイルをインポートし、イベントに対応する名前でSound Cueアセットを作成します。 このホワイトペーパーでは、鎧、サッチェル、声の音を3つの個別のサウンドキューアセットに分割しました。 これは、オーディオファイルに名前を付けるためのシステムでは、すべてのステップと音声が別々に存在するためです。 すべてを1つのアセットにマージすることは論理的ではありませんが、この場合、装甲を発声すると便利です。 既存のシステムに固執します。
サウンドキューを作成する場合、メインインストゥルメントは次のサウンドコンポーネント(サウンドノード)です。
- モジュレータ-音の各反復をピッチと音量で変調します。
- ランダム-提供されるすべてからランダムに1つのサンプルを選択します。
重装甲の資産ステップは次のようになります。
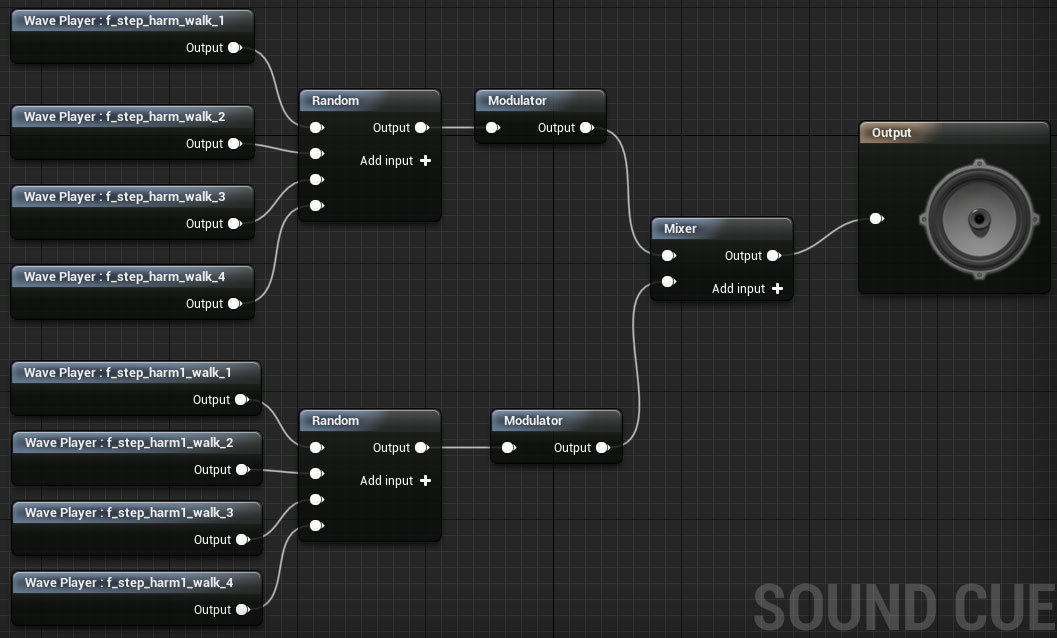
ここでは、Random(4つのサンプルから選択)とModulator(選択したサンプルをランダムに変調)の両方が表示されます。 また、ステップの2つの分離されたパックが表示されます。ファイル名の1つは単に「harm」であり、2番目は「harm1」です。 これは、2つの異なる重装甲がゲーム内にあると想定されていたために、わずかに異なる声で発音されたために発生しました。 技術的な理由から、これまでのところ、演技する声は1つだけですが、行われた分離は維持されています(おそらく、この瞬間は将来実現するでしょう)。 「Harm」はステップの一般的な低周波部分であり、「harm1」は高周波部分です。 2番目のアーマーの場合、ファイル「harm1」は「harm2」に変更されます(視覚的には、2番目のアーマーは「チェーンメールタイプ」に近いため、ここでは考慮されます)。
次に、取得したステップセットを対応するアニメーションに添付します。 たとえば、実行中のアニメーションにアタッチすると、次のようになります。
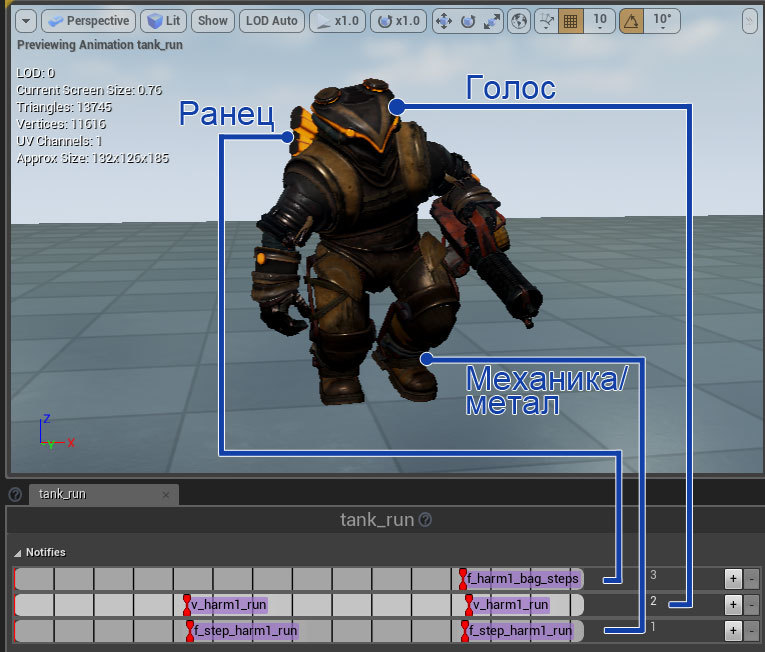
結論として、結果のすべての資産を確認することをもう一度提案します。
ビデオで:
- 画面の右側の部分は、アニメーションアセットと、オーディオアセットが添付されたタイムラインです。
- 画面の左側は、このアニメーションで使用されるオープンサウンドアセットです。
画面の左側で接続が点灯することで、特定の時間にどのwavファイルが再生されたかを追跡できます。
この記事がアンリアルエンジンを使用するすべての人に役立つことを願っています。 ご清聴ありがとうございました!