
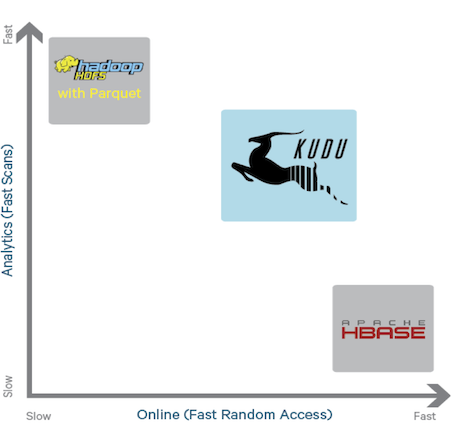
Kuduは、会議「Strata + Hadoop World 2015」でClouderaが発表した新製品の1つでした。 これは、分散HDFSファイルシステムとHbase列データベースの2つの既存のエンジン間のギャップを埋めるように設計された新しいビッグデータストレージエンジンです。
現在のエンジンには欠陥がないわけではありません。 HDFSは、大量のデータをスキャンするのに優れた働きをしますが、検索操作の結果が悪いことを示しています。 Hbaseでは、すべてが正反対です。 さらに、HDFSには追加の制限があります。つまり、すでに記録されているデータの変更は許可されません。 開発者によると、新しいエンジンには既存の両方のシステムの利点があります。
-迅速な応答検索操作
-変更の可能性
-大量のデータをスキャンする際の高いパフォーマンス
Kuduの用途には、時系列分析、ログ分析、感覚データが含まれます。 現在、そのようなことのためにHadoopを使用するシステムは、かなり複雑なアーキテクチャを持っています。 原則として、データは同時に複数のストレージに格納されます(いわゆる「ラムダアーキテクチャ」)。 ストレージ間のデータ同期に関する多くのタスクを解決する必要があります(必然的に、それらが単純に調和して動作するための遅延が避けられません)。 また、各ストレージのデータアクセスセキュリティポリシーを個別に構成する必要があります。 また、「単純なほど信頼性が高い」というルールは取り消されていません。 複数の同時ストレージの代わりにKuduを使用すると、このようなシステムのアーキテクチャを大幅に簡素化できます。
Kuduの機能:
-大量のデータをスキャンする際の高いパフォーマンス
-検索操作の高速応答時間
-CAP定理のCP型の列データベースは、いくつかのレベルのデータ整合性をサポートします
-「更新」のサポート
-レコードレベルのトランザクション
-耐障害性
-カスタマイズ可能なデータ冗長性レベル(ノードの1つに障害が発生した場合のデータの安全性のため)
-C ++、Java、Python用のAPI。 Impala、Map / Reduce、Sparkからのアクセスがサポートされています。
-オープンソース。 Apacheライセンス
アーキテクチャに関するいくつかの情報
Kuduクラスターは、2種類のサービスで構成されています。マスター-メタデータの管理とノード間の調整を担当するサービス。 タブレット-データを保存するために設計された各ノードにインストールされたサービス。 クラスターは、アクティブなマスターを1つだけ持つことができます。 フォールトトレランスのために、さらにいくつかのスタンバイマスターサービスを開始できます。 タブレット-サーバーはデータを論理パーティション(「タブレット」と呼ばれる)に分割します。

ユーザーの観点から、Kuduデータはテーブルに保存されます。 各テーブルについて、構造を決定する必要があります(NoSQLデータベースのかなり一般的ではないアプローチ)。 列とそのタイプに加えて、ユーザーは主キーとパーティションポリシーを定義する必要があります。
Hadoopエコシステムの他のコンポーネントとは異なり、Kuduはデータの保存にHDFSを使用しません。 OSファイルシステムが使用されます(ext4またはXFSを使用することをお勧めします)。 単一ノードで障害が発生した場合のデータの安全性を保証するために、Kuduはサーバー間でデータを複製します。 通常、各タブレットは3台のサーバーに保存されます(ただし、3台のサーバーのうち1台のみが書き込み操作を受け入れ、残りは読み取り専用操作を受け入れます)。 tablet-aのレプリカ間の同期は、raftプロトコルを使用して実装されます。
最初のステップ
ユーザーの観点からKuduを操作してみましょう。 テーブルを作成して、SQLおよびJava APIを使用してアクセスしてみましょう。
テーブルにデータを入力するには、この開いているデータセットを使用します。
https://raw.githubusercontent.com/datacharmer/test_db/master/load_employees.dump
現在、Kuduには独自のクライアントコンソールはありません。 Impalaコンソール(impala-shell)を使用してテーブルを作成します。
まず、HDFSのデータストレージを使用して「従業員」テーブルを作成します。
CREATE TABLE employees ( emp_no INT, birth_date STRING, first_name STRING, last_name STRING, gender STRING, hire_date STRING );
impala-shellクライアントを使用してマシンにデータセットをロードし、データをテーブルにインポートします。
impala-shell -f load_employees.dump
コマンドの実行が完了したら、impala-shellを再度実行し、次のリクエストを実行します。
create TABLE employees_kudu TBLPROPERTIES( 'storage_handler' = 'com.cloudera.kudu.hive.KuduStorageHandler', 'kudu.table_name' = 'employees_kudu', 'kudu.master_addresses' = '127.0.0.1', 'kudu.key_columns' = 'emp_no' ) AS SELECT * FROM employees;
このクエリは、同様のフィールドを持つテーブルを作成しますが、ストレージとしてKuduを使用します。 最後の行で「AS SELECT」を使用して、HDFSからKuduにデータをコピーします。
impala-shellを離れることなく、作成したテーブルに対していくつかのSQLクエリを起動します。
[vm.local:21000] > select gender, count(gender) as amount from employees_kudu group by gender; +--------+--------+ | gender | amount | +--------+--------+ | M | 179973 | | F | 120051 | +--------+--------+
両方のストレージ(KuduおよびHDFS)に同時に要求を行うことができます。
[vm.local:21000] > select employees_kudu.* from employees_kudu inner join employees on employees.emp_no=employees_kudu.emp_no limit 2; +--------+------------+------------+-----------+--------+------------+ | emp_no | birth_date | first_name | last_name | gender | hire_date | +--------+------------+------------+-----------+--------+------------+ | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | +--------+------------+------------+-----------+--------+------------+
次に、Java APIを使用して、最初のクエリ(男性と女性の従業員をカウント)の結果を再現してみましょう。 コードは次のとおりです。
import org.kududb.ColumnSchema; import org.kududb.Schema; import org.kududb.Type; import org.kududb.client.*; import java.util.ArrayList; import java.util.List; public class KuduApiTest { public static void main(String[] args) { String tableName = "employees_kudu"; Integer male = 0; Integer female = 0; KuduClient client = new KuduClient.KuduClientBuilder("localhost").build(); try { KuduTable table = client.openTable(tableName); List<String> projectColumns = new ArrayList<>(1); projectColumns.add("gender"); KuduScanner scanner = client.newScannerBuilder(table) .setProjectedColumnNames(projectColumns) .build(); while (scanner.hasMoreRows()) { RowResultIterator results = scanner.nextRows(); while (results.hasNext()) { RowResult result = results.next(); if (result.getString(0).equals("M")) { male += 1; } if (result.getString(0).equals("F")) { female += 1; } } } System.out.println("Male: " + male); System.out.println("Female: " + female); } catch (Exception e) { e.printStackTrace(); } finally { try { client.shutdown(); } catch (Exception e) { e.printStackTrace(); } } } }
コンパイルして実行すると、次の結果が得られます。
java -jar kudu-api-test-1.0.jar [New I/O worker #1] INFO org.kududb.client.AsyncKuduClient - Discovered tablet Kudu Master for table Kudu Master with partition ["", "") [New I/O worker #1] INFO org.kududb.client.AsyncKuduClient - Discovered tablet f98e05a4bbbe49528f38b5a46ef3a7a4 for table employees_kudu with partition ["", "") Male: 179973 Female: 120051
ご覧のとおり、結果はSQLクエリが発行したものと一致します。
結論
格納されたデータ全体の分析操作と高速応答時間の検索操作の両方を実行する必要があるビッグデータシステムの場合、Kuduはデータストレージエンジンとして自然な候補のようです。 多くのAPIのおかげで、Hadoopエコシステムにうまく統合されています。 結論として、Kuduは現在活発に開発中であり、本番環境で使用する準備ができていないことを述べておく必要があります。