
誰もがBeeline機械学習コンテストについて何度も耳にし、記事( 1、2 )を読んでいます。 これで競争は終わり、最初の場所は私のところに行ったことがわかりました。 そして、以前の参加者とは100分の1パーセントしか離れていませんでしたが、私が何をしたかをお伝えしたいと思います。 実際、信じられないほどのことはありません。
データ準備
彼らは、データ分析がデータの準備と予備的な修正に費やす時間の80%、分析に直接費やすのは20%だけだと言います。 そして、それは「ガベージイン-ガベージアウト」ほどカジュアルではありません。 ソースデータを準備するプロセスは、いくつかの段階に分けることができます。
外れ値の修正
ヒストグラムを注意深く調べた結果、かなりの数の外れ値がデータに侵入していることが明らかになりました。 たとえば、変数Xの観測値の99.9%が区間[0; 1]に集中しており、観測値の0.01%が100秒間捨てられている場合、2つのことを行うのは非常に論理的です。第二に、排出物を合理的なものに置き換えます。
data["x8_strange"] = (data["x8"] < -3.0)*1 data.loc[data["x8"] < -3.0 , "x8"] = -3.0 data["x31_strange"] = (data["x31"] < 0.0)*1.0 data.loc[data["x31"] < 0.0, "x31"] = 0.0 data["x40_zero"] = (data["x40"] == 0.0)*1.0
分布の正規化
一般に、多くの統計的検定は正規性の仮説と結びついているため、正規分布を扱うことは非常に快適です。 それほどではありませんが、これは最新の機械学習方法に関係しますが、データを適切な形式にすることが重要です。 これは、ポイント間の距離で動作するメソッド(ほとんどすべてのクラスタリングアルゴリズム、k近傍の分類器)にとって特に重要です。 データ準備のこの部分では、標準的なアプローチを採用しました。ゼロ付近でより密に分布するすべてを対数化します。 したがって、変数ごとに、より快適な外観を与える変換を選択しました。 さて、その後、セグメント[0; 1]にすべてをスケーリングしました
テキスト変数
一般に、テキスト変数はデータマイニングの倉庫ですが、元のデータにはハッシュのみがあり、変数の名前は匿名化されていました。 したがって、標準ルーチンのみ:すべてのレアハッシュをRareという単語に置き換え(まれ= 0.5%未満の頻度)、すべての欠落データをMissingという単語に置き換え、バイナリ変数として展開します(xgboostを含む多くのメソッドは、カテゴリ変数の方法を知らないため) 。
data = pd.get_dummies(data, columns=["x2", "x3", "x4", "x11", "x15"]) for col in data.columns[data.dtypes == "object"]: data.loc[data[col].isnull(), col] = 'Missing' thr = 0.005 for col in data.columns[data.dtypes == "object"]: d = dict(data[col].value_counts(dropna=False)/len(data)) data[col] = data[col].apply(lambda x: 'Rare' if d[x] <= thr else x) d = dict(data['x0'].value_counts(dropna=False)/len(data)) data = pd.get_dummies(data, columns=data.columns[data.dtypes == "object"])
機能エンジニアリング
これが私たち全員がデータサイエンスを愛している理由です。 ただし、すべてが暗号化されているため、この項目は省略する必要があります。 ほぼ。 グラフをよく調べてみると、x55 + x56 + x57 + x58 + x59 + x60 = 1であることに気付きました。 サブスクライバーがSMS、通話、インターネットなどに費やすお金の割合を考えてみましょう。 そのため、90%以上または5%未満の株式を保有する同志は特に関心があります。 したがって、12個の新しい変数を取得します。
thr_top = 0.9 thr_bottom = 0.05 for col in ["x55", "x56", "x57", "x58", "x59", "x60"]: data["mostly_"+col] = (data[col] >= thr_top)*1 data["no_"+col] = (data[col] <= thr_bottom)*1
NAを削除します
ここではすべてが非常に単純です。すべての分布が合理的な形式になった後、NA-shkamiを中間または中央値に安全に置き換えることができます(現在はほぼ一致しています)。 一般に、変数の60%以上がNAである行をトレーニングセットから削除しようとしましたが、これで終わりではありませんでした。
リグレッサーとしての回帰
次のステップはもはや平凡ではありません。 クラスの分布から、年齢グループを順序付ける、つまり0 <1 ... <6、またはその逆にすることを提案しました。 もしそうなら、あなたは分類することはできませんが、回帰を構築します。 うまく動作しませんが、その結果はトレーニングのために他のアルゴリズムに転送できます。 したがって、フーバー損失関数を使用して通常の線形回帰を開始し、確率的勾配降下法によって最適化します。
from sklearn.linear_model import SGDRegressor sgd = SGDRegressor(loss='huber', n_iter=100) sgd.fit(train, target) test = np.hstack((test, sgd.predict(test)[None].T)) train = np.hstack((train, sgd.predict(train)[None].T))
クラスタリング
私が試した2番目の興味深い考え:k-means法を使用したデータのクラスタリング。 データが実際の構造を持っている場合(およびサブスクライバーのデータ内にある必要があります)、k-meansはそれを感じます。 最初にk = 7を取り、次に3と15を追加しました(2倍と半分)。 これらの各アルゴリズムの予測は、各サンプルのクラスター番号です。 これらの番号は順序付けられていないため、番号を付けたままにすることはできません。2値化する必要があります。 合計+ 25の新しい変数。
from sklearn.cluster import KMeans k15 = KMeans(n_clusters=15, precompute_distances = True, n_jobs=-1) k15.fit(train) k7 = KMeans(n_clusters=7, precompute_distances = True, n_jobs=-1) k7.fit(train) k3 = KMeans(n_clusters=3, precompute_distances = True, n_jobs=-1) k3.fit(train) test = np.hstack((test, k15.predict(test)[None].T, k7.predict(test)[None].T, k3.predict(test)[None].T)) train = np.hstack((train, k15.predict(train)[None].T, k7.predict(train)[None].T, k3.predict(train)[None].T))
トレーニング
データの準備が完了すると、どの機械学習方法を選択するのかという疑問が生じました。 原則として、この質問に対する答えは長い間知られています。
実際、xgboost以外に、k-neighborsメソッドを試しました。 高次元空間では効果がないと考えられているにもかかわらず、私は通常のユークリッド空間ではなく距離を数えることで(変数が等しい場合)、重要度を調整することで75%(人にとっては小さな一歩、k隣人にとっては大きな一歩)を達成することができましたプレゼンテーションに示される変数。
しかし、これらはすべておもちゃであり、本当に良い結果が得られたのは、ニューラルネットワークではなく、ロジスティック回帰やk近傍ではなく、期待されていたxgboostです。 後に、ビーラインの防衛施設に来て、私は彼らがこのライブラリを使用してより良い結果を達成したことを知りました。 分類タスクについては、すでに「ゴールドスタンダード」のようなものです。
「疑わしい場合-xgboostを使用」
オーウェン・チャン 、Kaggleのトップ2。
実際の起動を開始して優れた結果を得る前に、与えられたすべての列と、ハッシュを拡張してK-meansクラスタリングを実行して作成した列がどれほど重要かを確認することにしました。 これを行うために、ライトブースト(多くのツリーではなく)を行い、重要度で並べ替えられた列を作成しました(xgboostによる)。
gbm = xgb.XGBClassifier(silent=False, nthread=4, max_depth=10, n_estimators=800, subsample=0.5, learning_rate=0.03, seed=1337) gbm.fit(train, target) bst = gbm.booster() imps = bst.get_fscore()
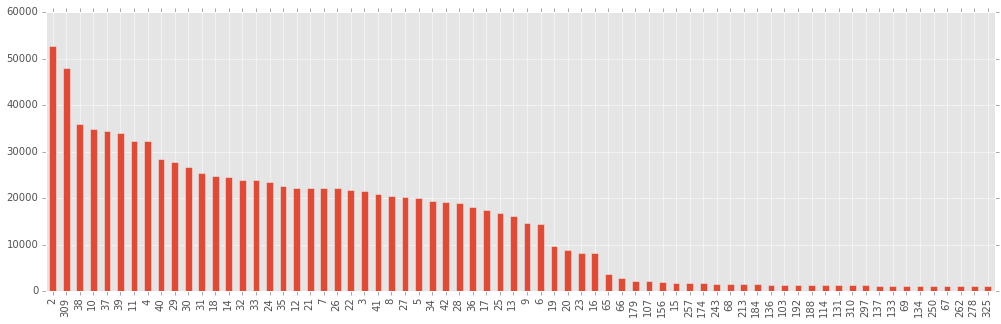
私の意見では、重要性が「重要でない」と評価された列(および335から最も重要な70の変数についてのみ図が作成されている列)には、実際に有用な相関よりも多くのノイズが含まれており、それらから学習することはあなたに有害です(つまり、 再トレーニング )。
また、最初の最も重要な変数はx8であり、2番目は私が追加したSGD回帰の結果であることに注意することも興味深いです。 このコンテストに参加しようとした人は、クラスをうまく分離できるのであれば、変数x8はどのようなものか疑問に思われるでしょう。 ビーラインでの防衛では、抵抗できず、それが何であるかを尋ねませんでした。 AGEでした! 彼らが私に説明したように、関税の購入で示された年齢と世論調査で得られた年齢は必ずしも一致しないので、参加者は年齢を含む年齢グループを決定しました。

短い実験により、120カラムを残すことは70を残す、または170を残すよりも優れていることに気付きました(最初のケースでは、明らかに有用なものが捨てられ、2番目では、データが役に立たないもので汚染されています)。
今、私はそれを手放さなければなりませんでした。 最も注目に値する2つのxgboost.XGBClassifierパラメーターは、eta(別名学習率)とn_estimators(ツリーの数)です。 残りのパラメーターは結果を実際に変更しませんでした(したがって、max_depth = 8、サブサンプル= 0.5を設定し、残りはデフォルトのパラメーターです)。
イータとn_estimatorsの最適値の間には自然な相関関係があります。イータ(学習速度)が低いほど、最大精度を達成するためにより多くのツリーが必要になります。 そして、ここで実際に最適な状態に遭遇します。その後、追加のツリーを追加しても再トレーニングのみが発生し、テストサンプルの精度が悪化します。 たとえば、eta = 0.02の場合、約800本の木が最適です。
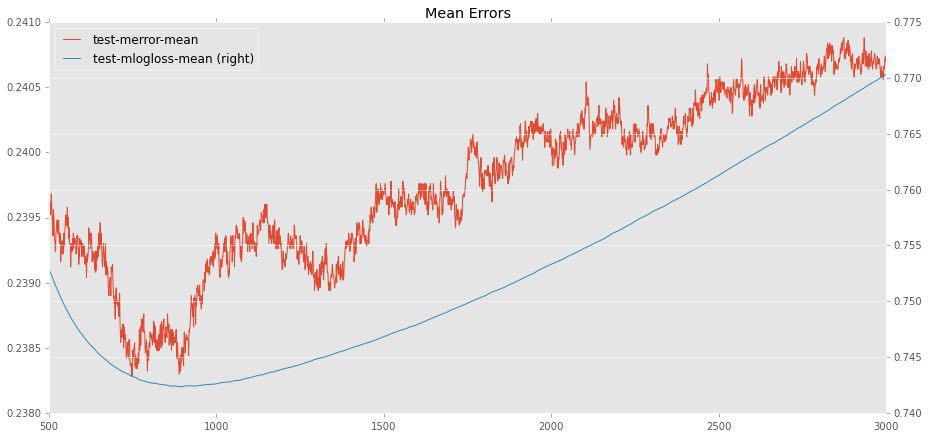
最初にイータ平均(0.01-0.03)を使用してみましたが、ランダムな状態(シード)に応じて顕著な広がりが見られました(たとえば、0.02のスコアは76.7から77.1に変化します)。イータ。 大きいイータは原則として適切ではないことが明らかになりました(どのようにして良いモデルが種子に依存するのでしょうか?)。
次に、コンピューターで余裕のあるイータを選択しました(数日間は使いたくないでしょう)。 これはeta = 0.006です。 次に、最適なツリー数を見つける必要がありました。 上記と同じ方法で、η= 0.006の場合、3400本のツリーが適していることがわかりました。 念のため、2つの異なるシードを試しました(変動が大きいかどうかを理解することが重要でした)。
for seed in [202, 203]: gbm = xgb.XGBClassifier(silent=False, nthread=10, max_depth=8, n_estimators=3400, subsample=0.5, learning_rate=0.006, seed=seed) gbm.fit(trainclean, target) p = gbm.predict(testclean) filename = ("subs/sol3400x{1}x0006.csv".format(seed)) pd.DataFrame({'ID' : test_id, 'y': p}).to_csv(filename, index=False)
通常のコアi7の各アンサンブルは、1時間半と見なされました。 競争が1か月半行われるのは許容できる時間です。 パブリックリーダーボードの変動はわずかでした(シード= 202の場合77.23%、シード= 203の77.17%)。 それらのベストを送信しましたが、プライベートリーダーボードでは他のリーダーボードも悪くなかった可能性が非常に高くなります。 ただし、わかりません。
競争自体について少し説明します。 Kaggleに精通している人に最初に目を引くのは、ちょっと変わった投稿ルールです。 Kaggleでは、サンビシュナの数は制限されています(競技によって異なりますが、通常は1日あたり5つ以下)。ここでは、参加者が無制限であるため、一部の参加者は600回も結果を送信できます。 さらに、最終提出物は1つを選択する必要があり、Kaggleは通常、任意の2つを選択することが許可されており、プライベートリーダーボードのアカウントがそれらのベストと見なされます。
もう1つの珍しいことは、匿名化された列です。 一方で、これは機能設計の機会を実質的に奪います。 一方、これは部分的に理解できます。本名の列はモバイル通信に精通している人々に強力な利点を与え、コンテストの目標は明らかにそれではありませんでした。