まとめ
銀行の顧客がローンを支払うかどうかを予測します。 このタスクは、ある銀行が主催するオンライントーナメントで提案されました。 その解決策の一例は、 ここにあります 。 私たちの目標は、Microsoft Azureプラットフォームでソリューションを構築することです。
問題の声明
銀行は、ロシアの3大信用調査機関に申請者の信用履歴を要求します。 SAMPLE_CUSTOMERS(CSV)ファイルで銀行の顧客のサンプルが提供されます。 サンプルは、「トレーニング」と「テスト」の部分に分かれています。 「train」サンプルから、不良なターゲット変数の値がわかります-「デフォルト」の存在(クライアントはローンを使用した最初の年の間に90日以上の遅延を想定しています)。
ファイルSAMPLE_ACCOUNTS(CSV)は、関連する顧客に対するすべてのリクエストに対する信用調査機関の応答からのデータを提供します。 局の応答からのデータの形式は、他の銀行からこの局に送信された個人の口座に関する情報です。 データ形式の詳細は、ACCOUNT_DATA_FORMATファイルに記載されています。
「トレーニング」サンプルでは、「デフォルト」の確率を決定するモデルを構築し、「テスト」サンプルから顧客の「デフォルト」の確率を下げる必要があります。
データセットをスタジオにインポートする
ソースデータはCSV形式で表示されますが、スタジオはカンマ区切りのCSVのみでCSVを正しく認識します。 ソースファイルに顧客情報SAMPLE_ACCOUNTS.CSVおよびSAMPLE_CUSTOMERS.CSVを必要な区切り文字(簡潔にするために、SAMPLE_ACCOUNTS.csvはSdvch.csvとして保存されています)とともに保存し、紺andに読み込みます。
一次加工
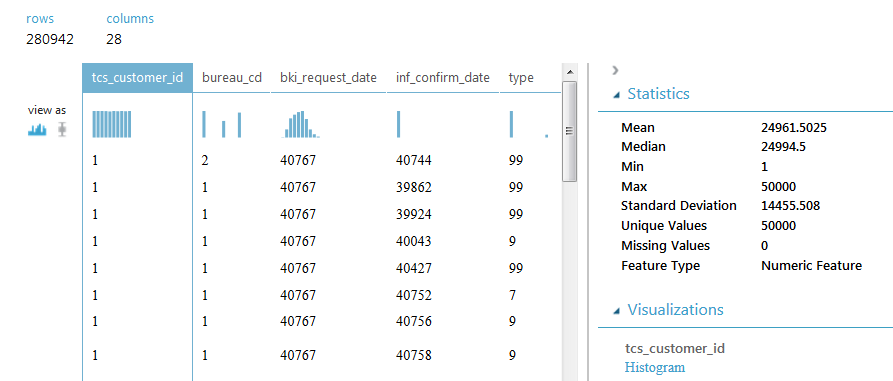
SAMPLE_ACCOUNTSには280,942行と28列が含まれ、各行には1つのローンに関する情報が含まれます。 顧客IDの列には、50,000個の一意の値が含まれています。つまり、各クライアントは複数の行を持つことができます。 一部のローンが繰り返され、一部のフィールドが欠落していることに注意してください。 列の内容は、問題を解決する過程で後ほど開示されます。
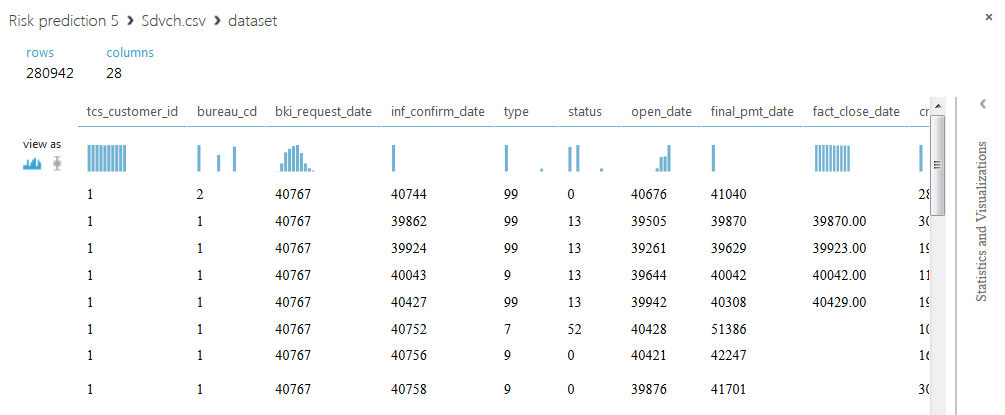
問題を解決するために、各クライアントのすべての情報を1行にまとめます。 これを行うには、データベース上でPythonでスクリプトを実行します。
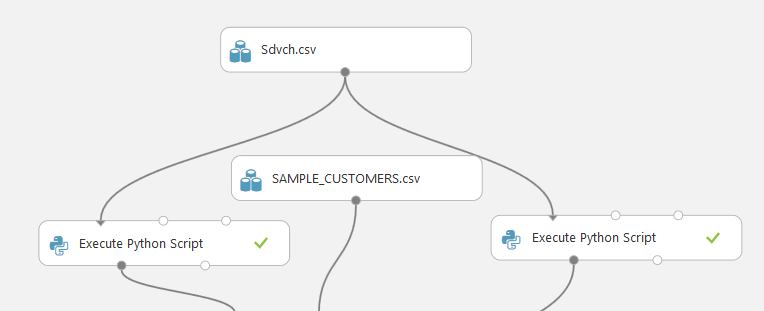
実際、最初のスクリプトは、前述のソリューションのアイデアで構成されています。 簡単に言う。
ステップ1.データセットから重複したローン(行)を捨て、最新の情報を含む行を残します。 これを行うために、キーとして機能する列のセットを定義します。これらは次のとおりです。tcs_customer_id、open_date、final_pmt_date、credit_limit、currency(id、ローン開始日、最終支払いの推定日、クレジット制限、通貨)。 列inf_confirm_date(ローンに関する情報の確認日)により、どの重複が残るかが決まります。
ステップ2.列を処理します:pmt_string_84m(支払いのタイミング)、pmt_freq(支払いの頻度のコード)、タイプ(契約のタイプのコード)、ステータス(契約のステータス)、関係(契約との関係のタイプ)、bureau_cd(請求書の受領元のコード) 。 各クライアントの一意の値の量を計算し、これらの値を新しい列に書き込みます。
ステップ3. fact_close_dateフィールドを変換します。このフィールドには、最後の実際の支払いの日付が含まれ、2つの値のみが含まれます。0-最後の支払いがありません、1-最後の支払いがあります。
ステップ4.すべての与信限度をルーブルに譲渡します。 簡単にするために、2013年のコースを取ります。
手順5. bki_request_date、inf_confirm_date、pmt_string_start、interest_rate、open_date、final_pmt_date、inf_confirm_date_maxの列を破棄しながら、データ0のギャップを埋め、クライアントによる最終的なグループ化(合計)を実行します。 これらはローンの日付と支払利息です。
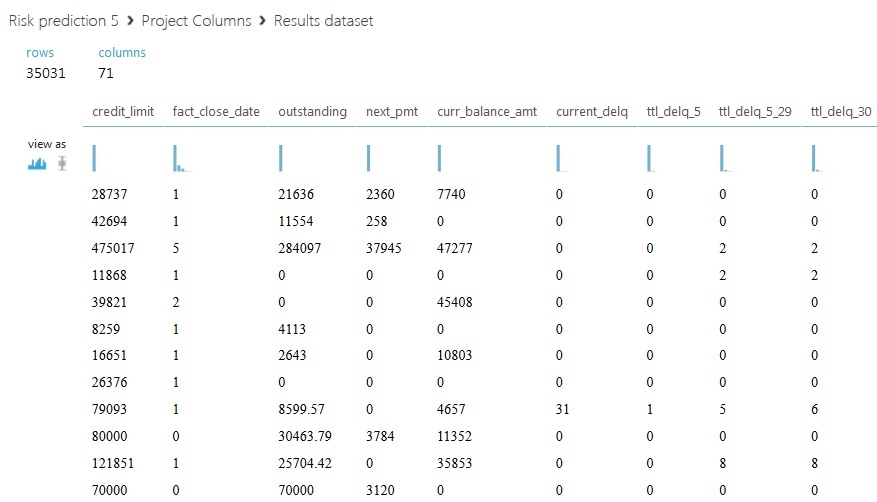
結果のデータセットは次のとおりです。
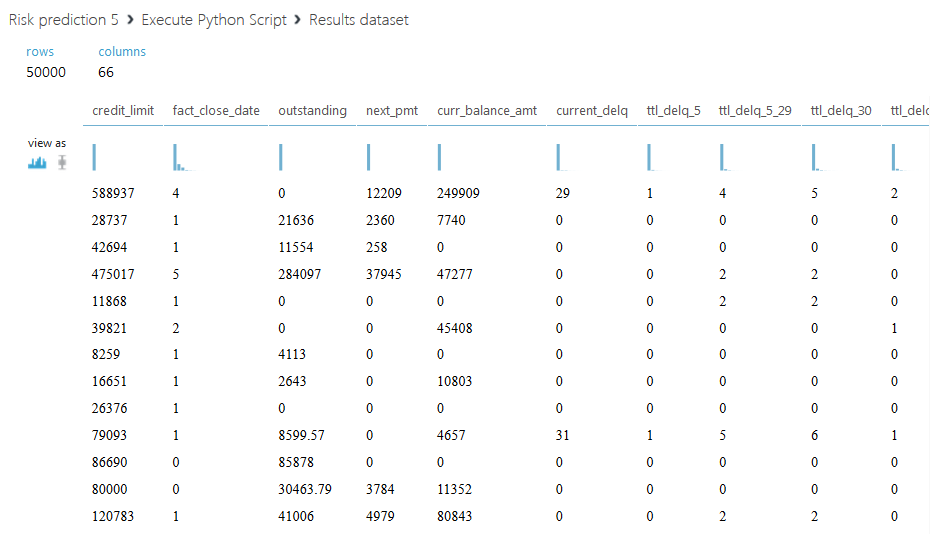
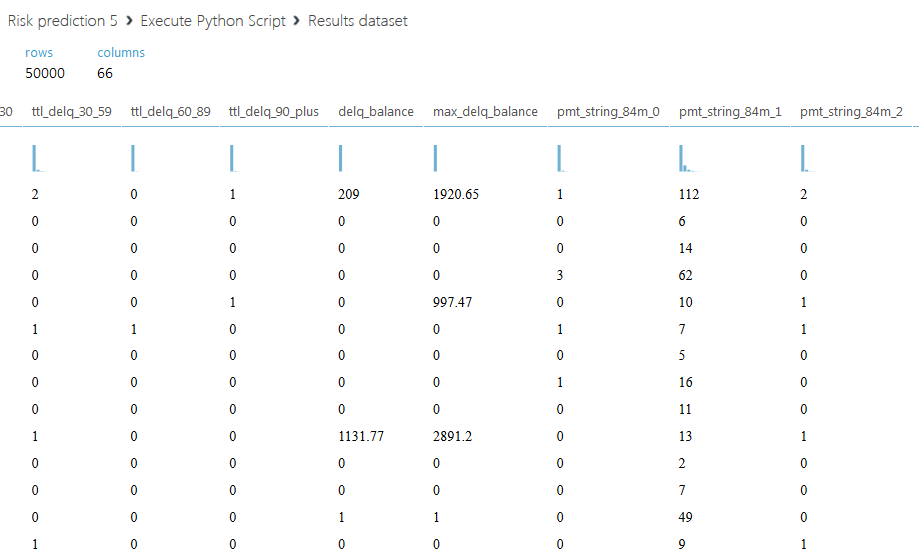
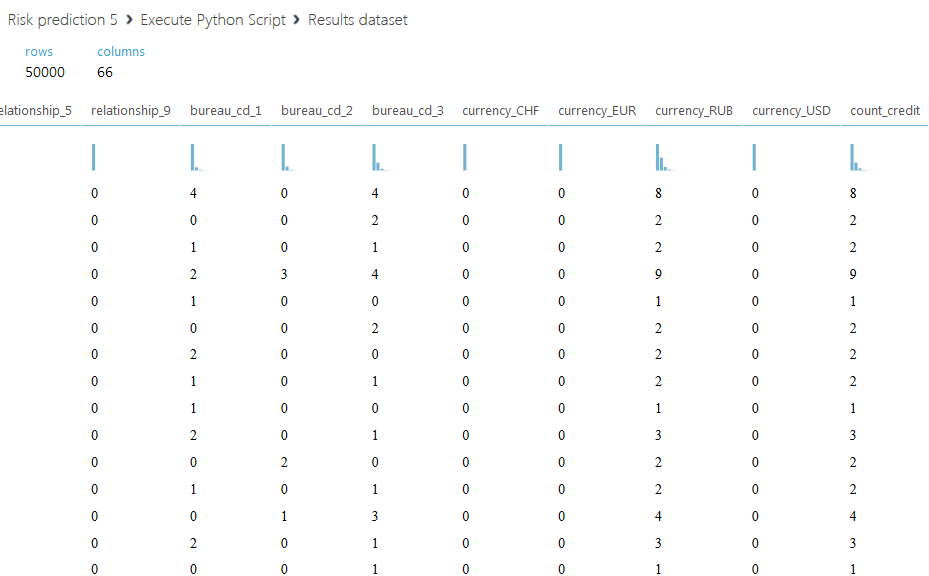
2番目のスクリプトについて説明します。 各クライアントのすべてのクレジット限度を合計するだけでなく、金額全体を2つの部分に分割することを提案します。ステータス値が00のアクティブなクレジット限度と、他のすべてのステータスのクローズされた限度です。 また、アクティブな制限の合計と閉じた比率の別の列を導入します-閉じた制限の量がゼロの場合、フィールドに文字Aを入力します。2番目のスクリプトのコードを以下に示します。
def azureml_main(dataframe1): from pandas import read_csv, DataFrame,Series import numpy SampleAccounts=dataframe1 SampleAccounts.final_pmt_date[SampleAccounts.final_pmt_date.isnull()] = SampleAccounts.fact_close_date[SampleAccounts.final_pmt_date.isnull()].astype(float) SampleAccounts.final_pmt_date.fillna(0, inplace=True) # sumtbl = SampleAccounts.pivot_table(['inf_confirm_date'], ['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], aggfunc='max') #sumtbl - SampleAccounts = SampleAccounts.merge(sumtbl, 'left', left_on=['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency'], right_index=True, suffixes=('', '_max')) # SampleAccounts=SampleAccounts.drop_duplicates(['tcs_customer_id','open_date','final_pmt_date','credit_limit','currency']).reset_index() df1=SampleAccounts.drop('index',axis=1) curs = DataFrame([33.13,44.99,36.49,1], index=['USD','EUR','GHF','RUB'], columns=['crs']) df2 = df1.merge(curs, 'left', left_on='currency', right_index=True) df2.credit_limit = df2.credit_limit * df2.crs # df2=df2.drop(['crs'], axis=1) # df3 = df2[['tcs_customer_id','credit_limit','status']] df3['act_lim']=df3.credit_limit[df3.status==0] df3.act_lim.fillna(0, inplace=True) df4=df3.copy() df4['credit_limit'] = numpy.where(df3['status']==0, 0, df3.credit_limit) df5=df4.groupby('tcs_customer_id').sum() df5.rename(columns={'credit_limit':'closed_limit'}, inplace=True) df6=df5.drop('status',axis=1) df6['otn_lim']=numpy.where(df6.closed_limit==0, 'A', df6.act_lim/df6.closed_limit) return df6
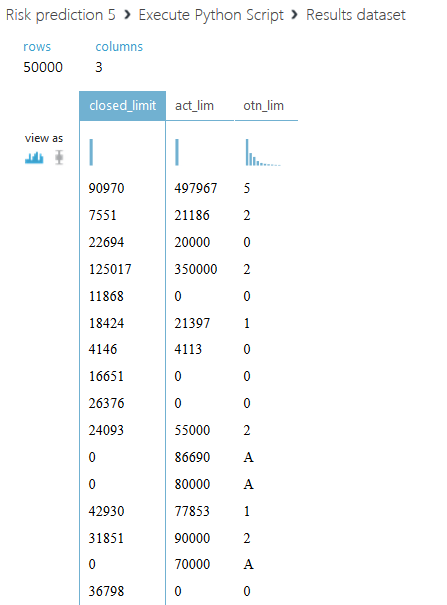
Azure Processing
2つのAdd Columnsブロックを使用して、スクリプトによる処理の結果として取得されたデータベースをSAMPLE_CUSTOMERSファイルに接続します。


次に、「Split Data」ブロックを使用してサンプルを2つの部分に分割します。 正規表現モードを選択し、列「sample_type」に条件を設定します。値「train」の行が必要です。
「Project Columns」ブロックを使用して、処理する残りの列を選択します。 2つのデータセットを比較します:左側は受信したすべての列(sample_typeを除き、すべての場所で同じ「トレイン」です)、変更なし、つまりアクティブな閉じた制限列とそれらの関係(およびsample_type)を除く右側。
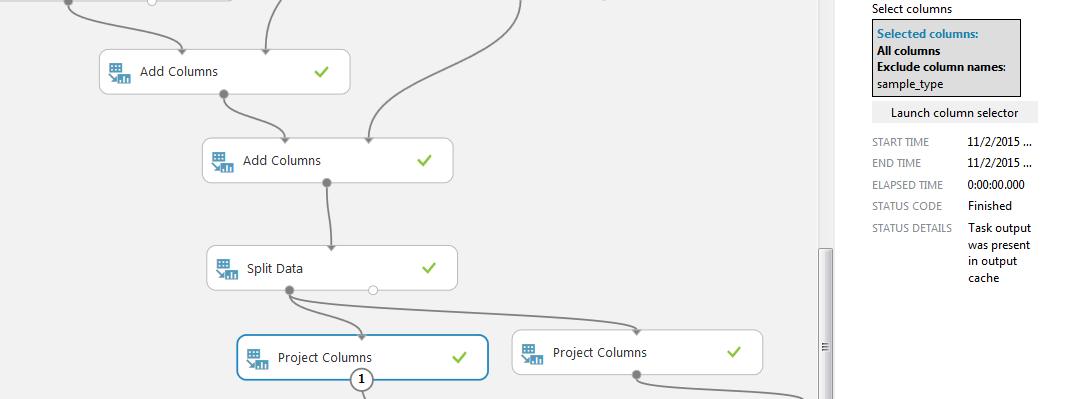
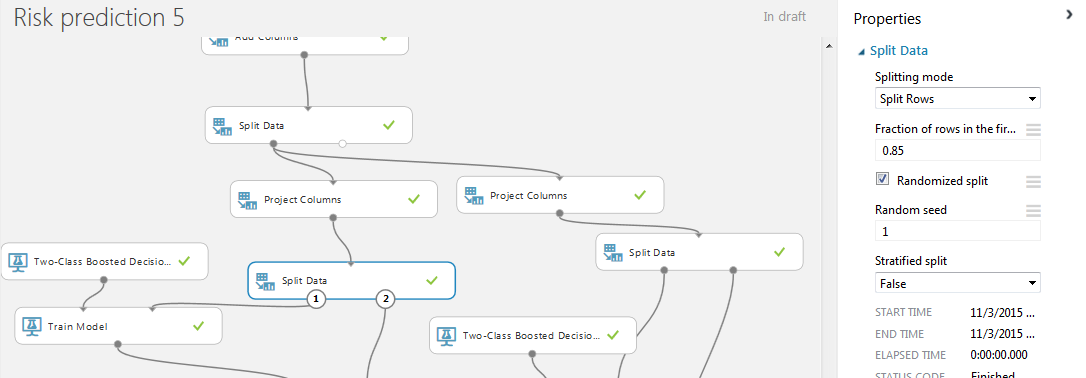
次に、プロジェクトに「Split Data」モジュールの別のペアを追加します。 今回は、与えられたフィールド「ランダムシード」を使用して、文字列を2つの部分に擬似ランダム分割します。 これは、サンプルを2つの部分に分離するために左右のベースで同じように発生するために必要です。 トレーニングとテストの割合は85%と15%です。 これは、このケースでは、50,000のクライアントを持つデータベースが既に2つのサンプルのトレーニングとテストに分割されているためです。 理論的には、電車のベースを100%学習して結果をテストする必要がありますが、電車でトレーニングとテストを行うため、比率は通常の75/25または80/20よりも有利に選択されました。
モデルをトレーニングするために、標準値を持つ2クラスの増加した決定木(2クラスのブースティング)を使用します。 モジュール「Train Model」および「Score Model」も追加します。 「Train Model」では、不良を予測する列を示します。
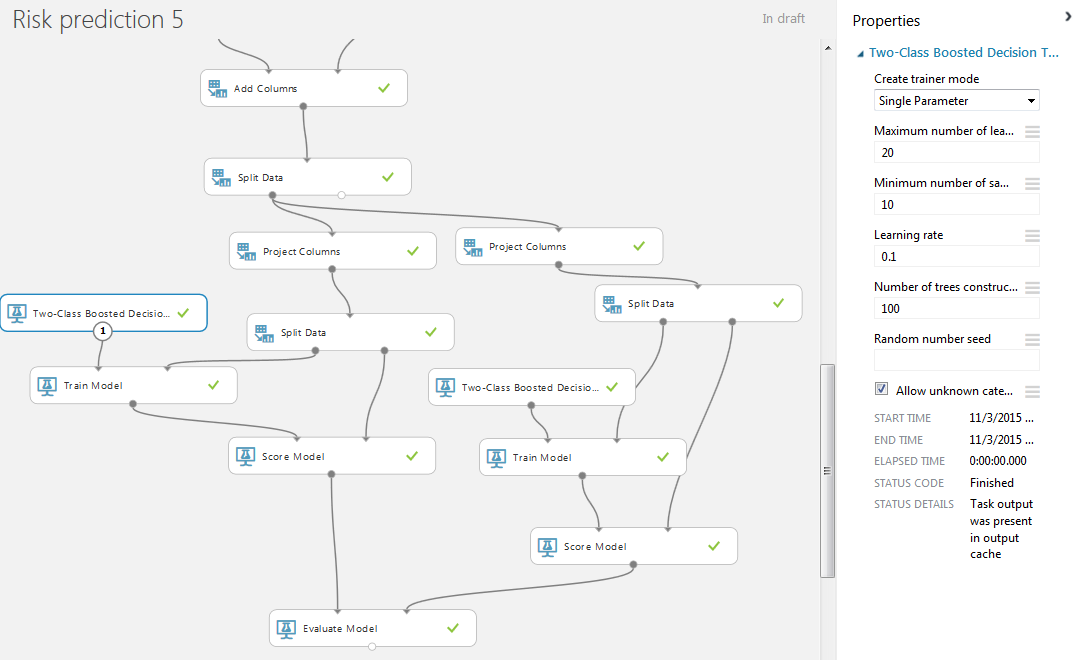
左のブロック「スコアモデル」の視覚化。

「Score Model」モジュールの出力を「Evaluate Model」ブロックの入力に接続することにより、2つの方法の結果を比較できます。 この場合、2つの異なるデータセットに対する1つの分類方法の結果です。
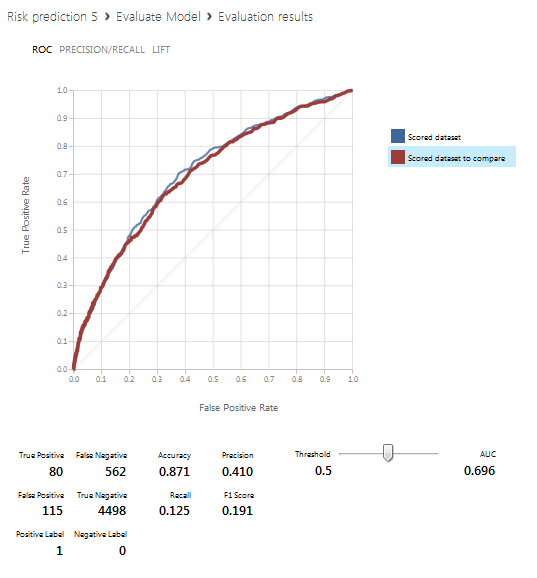
次のスクリーンショットは、Evaluate Modelブロックの視覚化、つまり予測結果を示しています。 青い線は左側のデータベース(すべての列を受け取った)に対応し、赤い線は右側の行(アクティブな、閉じた制限とその比率を持つ列を除く)に対応します。

おわりに
トーナメントが開催する座席の分布を考えると、
- AUC 0.7057
- AUC 0.7017
- AUC 0.7012
- AUC 0.6997