タイプ0:CQRSなし
このタイプでは、CQRSパターンをまったく使用しません。 これは、ドメインモデルがドメインクラスを使用してコマンドとクエリの両方を処理することを意味します。
例としてCustomerクラスを考えてみましょう。
public class Customer { public int Id { get; private set; } public string Name { get; private set; } public IReadOnlyList<Order> Orders { get; private set; } public void AddOrder(Order order) { /* … */ } /* Other methods */ }
nullタイプのCQRSでは、次のようなCustomerRepositoryクラスを使用します。
public class CustomerRepository { public void Save(Customer customer) { /* … */ } public Customer GetById(int id) { /* … */ } public IReadOnlyList<Customer> Search(string name) { /* … */ } }
ここでの検索方法はリクエストです。 データベースからカスタムメーターのデータを取得し、このデータをクライアント(APIまたはAPIを介してアプリケーションにアクセスするUIまたは別のアプリケーション)に返すために使用されます。 このメソッドは、ドメインオブジェクトのリストを返すことに注意してください。
このアプローチの利点は、コードの量に関してオーバーヘッドがないことです。 つまり、コマンドとクエリの両方に使用できる唯一のモデルがあり、コードを複製する必要はありません。
ここでの欠点は、この単一モデルが読み取り操作用に最適化されていないことです。 UIにカスタムメーターのリストを表示する必要がある場合、通常、注文を表示する必要はありません。 代わりに、ほとんどの場合、ID、名前、注文数などの簡単な情報のみを表示する必要があります。
ドメインクラスを使用してデータを転送すると、カスタママーのすべてのサブオブジェクト(Ordersなど)がデータベースからメモリに読み込まれます。 これは、次のような深刻なオーバーヘッドにつながります。 UIに必要なのは注文数だけで、注文自体は必要ありません。
このタイプのCQRSは、パフォーマンス要件がほとんどない(またはまったくない)アプリケーションに適しています。 他のタイプのアプリケーションでは、次のタイプのCQRSを使用する必要があります。
タイプ1:別のクラス階層
このタイプのCQRSでは、クラス構造が分割され、読み取り操作と書き込み操作が提供されます。 これは、データベースからロードされたデータを転送するDTOクラスのセットを作成していることを意味します。
CustomerクラスのDTOは次のようになります。
public class CustomerDto { public int Id { get; set; } public string Name { get; set; } public int OrderCount { get; set; } }
リポジトリのSearchメソッドは、ドメインオブジェクトのリストではなく、DTOリストを返します。
public class CustomerRepository { public void Save(Customer customer) { /* … */ } public Customer GetById(int id) { /* … */ } public IReadOnlyList<CustomerDto> Search(string name) { /* … */ } }
検索では、ORMと通常のADO.NETの両方を使用して、必要なデータを取得できます。 これは、それぞれの場合のパフォーマンス要件によって決定される必要があります。 メソッドのパフォーマンスが十分であれば、ADO.NETにロールバックする必要はありません。
DTOは、1つではなく2つのクラスを作成する必要があるという意味で、いくつかの重複を追加します。1つはドメインオブジェクト形式のコマンド用で、もう1つはDTO形式の要求用です。 同時に、読み取り操作のニーズに明確に当てはまる、明確で明確なデータ構造を作成できます。 表示するときに必要なものだけが含まれています。 そして、コードで意図を明確に表現するほど、より良い結果が得られます。
私の意見では、このタイプのCQRSはほとんどのエンタープライズアプリケーションに十分です。 シンプルさとコードのパフォーマンスのバランスがとれています。 また、このアプローチでは、クエリに選択するツールに柔軟性があります。 メソッドのパフォーマンスが重要でない場合、ORMを使用して開発者の時間を節約できます。 それ以外の場合は、ADO.NET(またはDapperのような軽量ORM)を直接使用して、複雑で最適化されたクエリを手動で作成できます。
タイプ2:別のモデル
このタイプのCQRSでは、個別のモデルと一連のAPIを使用して、読み取りおよび書き込み要求を処理します。
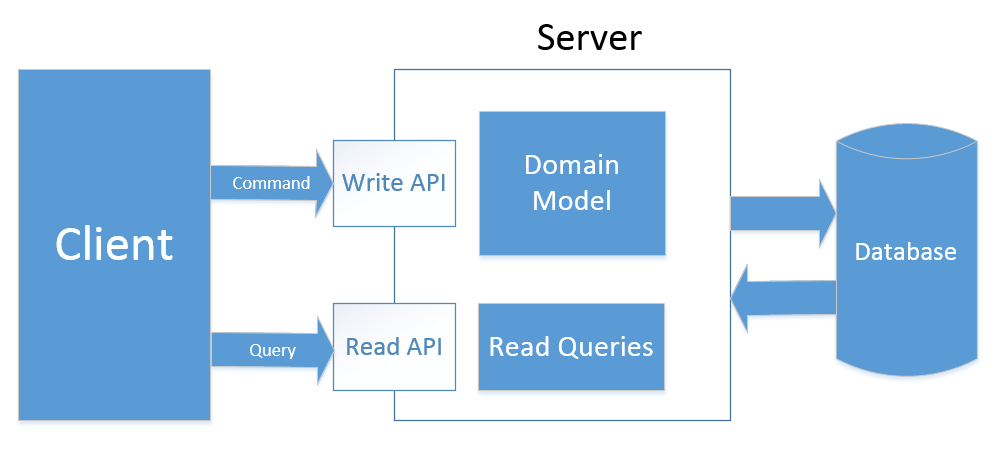
つまり、DTOに加えて、モデルからすべての読み取り操作を抽出します。 リポジトリには、コマンドに関連するメソッドのみが含まれるようになりました。
public class CustomerRepository { public void Save(Customer customer) { /* … */ } public Customer GetById(int id) { /* … */ } }
また、検索ロジックは別のクラスにあります。
public class SearchCustomerQueryHandler { public IReadOnlyList<CustomerDto> Execute(SearchCustomerQuery query) { /* … */ } }
このアプローチは、リクエストを処理するために必要なコードの量の点で以前のものと比較してより多くのオーバーヘッドを追加しますが、これは大量のデータ読み込み負荷がある場合には良いソリューションです。
最適化されたクエリを作成できることに加えて、タイプ2を使用すると、クエリに関連するAPIの一部をキャッシュメカニズムに簡単にラップしたり、ローダーAPIが構成された別のサーバーまたはサーバーのグループにこのAPIを移動することもできます。 このソリューションは、読み取りと書き込みの負荷が大きく異なるアプリケーションに最適です。 読み取り操作を適切にスケーリングできます。
読み取り操作に関してパフォーマンスをさらに向上させる必要がある場合は、タイプ3に移行する必要があります。
タイプ3:別のストレージ
これは、多くの人が「真の」CQRSと考えるタイプです。 読み取り操作をさらに拡張するために、システムのリクエスト用に最適化された別個のストレージを使用できます。 多くの場合、このようなリポジトリは、MongoDBなどのNoSQLデータベース、またはいくつかのインスタンスからのレプリカのセットです。

ここでの同期はバックグラウンドで行われ、時間がかかる場合があります。 このようなリポジトリは、「最終的に一貫性のある」と呼ばれます。
ここでの良い例は、Elastic Searchを使用して顧客データにインデックスを付けることです。 多くの場合、SQL Serverに組み込まれている全文検索を使用したくないのは、 あまりうまくスケーリングしません。 代わりに、カスタム検索用に最適化された非リレーショナルデータストレージを使用できます。
このタイプのCQRSは、読み取り操作の最高のスケーラビリティとともに、最大のオーバーヘッドをもたらします。 読み書きのモデルを論理的に共有するだけでなく、つまり このために個別のクラスとアセンブリを使用しますが、データベース自体も共有します。
おわりに
アプリケーションで使用できるCQRSパターンにはさまざまなグラデーションがあります。 タイプ1がアプリケーションのパフォーマンス要件を満たしている場合、タイプ1に固執し、タイプ2および3に移行しないことに問題はありません。
この点を強調したい:CQRSはバイナリ選択ではありません。 読み取り操作と書き込み操作をまったく分離しない(タイプ0)と完全に分離する(タイプ3)には、さまざまなバリエーションがあります。
分離の程度と、この分離がもたらす複雑さの間でバランスをとるべきです。 多くの場合、いくつかの反復を使用して、それぞれの場合にバランスを個別に検索する必要があります。 「できる」という理由だけでCQRSパターンを適用すべきではありません。
記事の英語版: CQRSの種類