この記事を書いてくれたMerkuのKirk Malevに感謝します。 Cyrilは3年以上にわたり、さまざまな量のデータに対する機械学習の実用化に取り組んできました。 同社は、顧客の解約と自然言語処理を予測する分野の問題を解決し、結果の商業化に大きな注意を払っています。 ボローニャ大学およびNSTUを卒業
今日は、機械学習タスクを解決するために実際にAzureクラウドプラットフォームを使用する方法について説明します。機械学習タスクを解決するために、タイタニックの生き残った乗客を予測する一般的なタスクを例として使用します。
私たちは皆、フクロウの有名な写真を覚えているので、この記事ではすべての手順について詳しくコメントしています。 手順がわからない場合は、コメントで質問することができます。
最近のガートナーのレポートによると、ビッグデータと機械学習はすでに生産性の高原に近づいています。 これは、市場がビッグデータ処理技術を適用する方法を十分に理解しており、臓器の3D印刷や火星の植民地化のアイデアよりも、このトピックに人々が慣れていることを意味します。
機械学習にAzureクラウドプラットフォームを使用することに関する記事がHabrahabrで既に公開されています。 彼らは、すべてがどのように機能するか、このプラットフォームをどのように使用できるか、そしてその長所と短所について話します。 このコレクションを2つの実用的な例で補完します。
どちらの例でも、Kaggle Data Scientist競争プラットフォームを使用します。 Kaggleは、企業がデータを投稿し、解決したい問題を特定し、その後、世界中のエンジニアが問題の正確な解決策を競う場所です。 原則として、最高の結果を得るために、勝者は決定を発表すると現金賞金を受け取ります。
同時に、商業競争に加えて、Kaggleはトレーニングに使用される提供されたデータでタスクを解析しました。 彼らにとって、「知識」は賞として直接示されており、これらの競争は終わりません。
Azure MLの紹介は、最も有名なタイタニック:Machine Learning from Disasterに参加して開始します。 データをアップロードし、R言語モデルとAzure ML組み込み関数を使用して分析し、結果を取得してKaggleにアップロードします。
単純なものから複雑なものに移行します。まず、Rコードを使用してデータ分析の結果を取得し、次にプラットフォーム自体に組み込まれた分析ツールを使用します。 Rの決定は、カットの下の記事の最後で与えられ、特に公式のKaggleトレーニング資料に基づいているため、初心者は、希望するなら、まったく同じ結果をゼロから得る方法を知ることができます。
この記事の主な目的は、クラウドソリューションの機能を使用して分類の問題を解決することです。 Rコードの構文や内容がわからない場合は、 Trevor Stevens ブログで R言語のタイタニック問題の例を使用してデータ分析問題を解決するための簡単な紹介を読むか、 datacampでインタラクティブな1時間コースを受講できます。 モデル自体についてのご質問はコメントで歓迎します。
クラウドを使い始める
Azureを使用するには、Microsoftアカウントが必要です。 登録には5分かかります。また、Azureにまだ登録していない場合は、延長登録ボーナスを提供するスタートアップサポートプログラムであるMicrosoft BizSparkに注意する必要があります。 このプログラムの条件を満たさない場合、登録時に200ドルの試用版が割り当てられ、Azureクラウドのリソースに使用できます。 Azure MLをテストし、記事を繰り返すのに十分な数があります。
アカウントをお持ちの場合は、 Azure ML セクションにアクセスできます。
左側のAzureサービスのリストで「Machine Learning」を選択すると、ワークスペース(「実験」と呼ばれるモデルとプロジェクトファイルがある)を作成するように求められます。 すぐにデータストレージアカウントを接続するか、新しいアカウントを作成する必要があります。 データ処理またはアップロード結果の中間結果を保存するために必要です。

ワークスペースを作成したら、その中にプロジェクトを作成できます。 これを行うには、「作成」ボタンをクリックする必要があります。
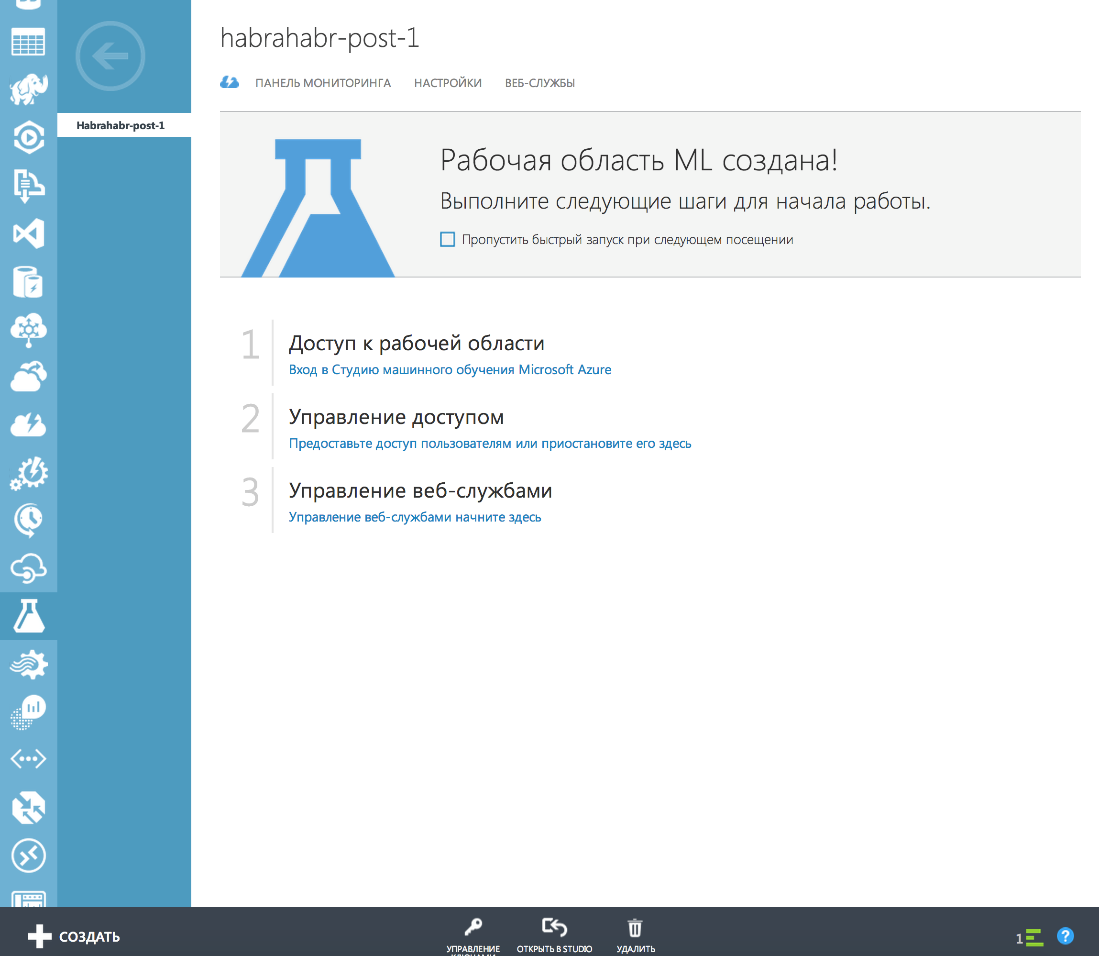
そして、ここで新しいプラットフォームやフレームワークの例を習得することに慣れている人は、素晴らしい贈り物を受け取ります。サービスの仕組みをすぐに理解できる既製のプロジェクトの例です。 問題が発生した場合、ほとんどの質問に対する回答は、便利なオンラインドキュメントに記載されています 。 Azureでの作業のプラクティスによれば、必要な情報はすべてそこにあります。
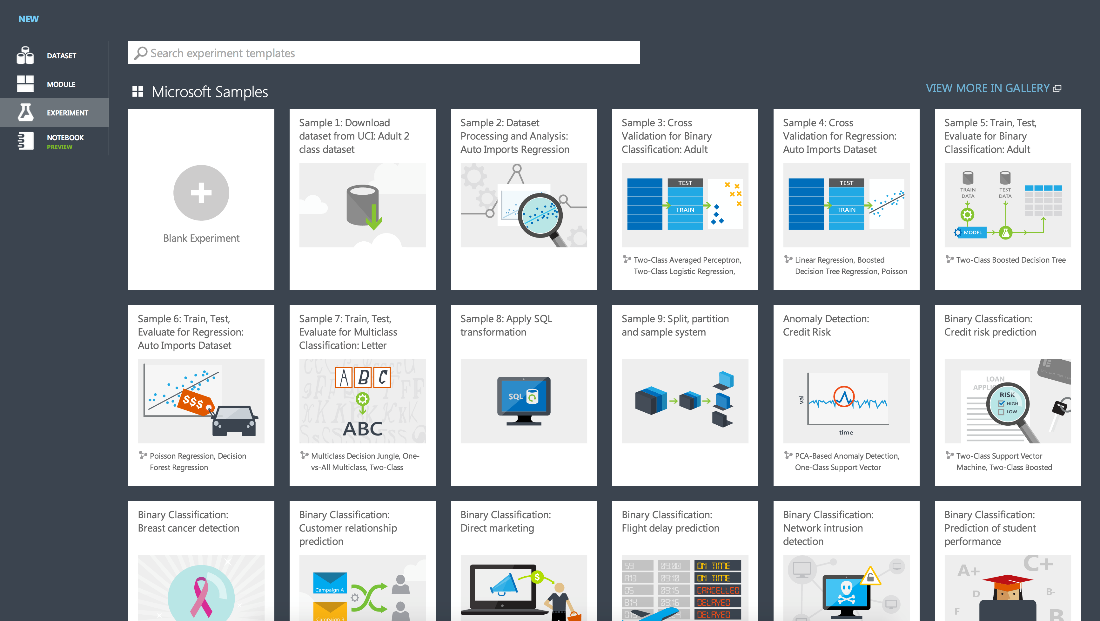
既製の実験のライブラリには、Rで次のようなモデルを開始する例があります。
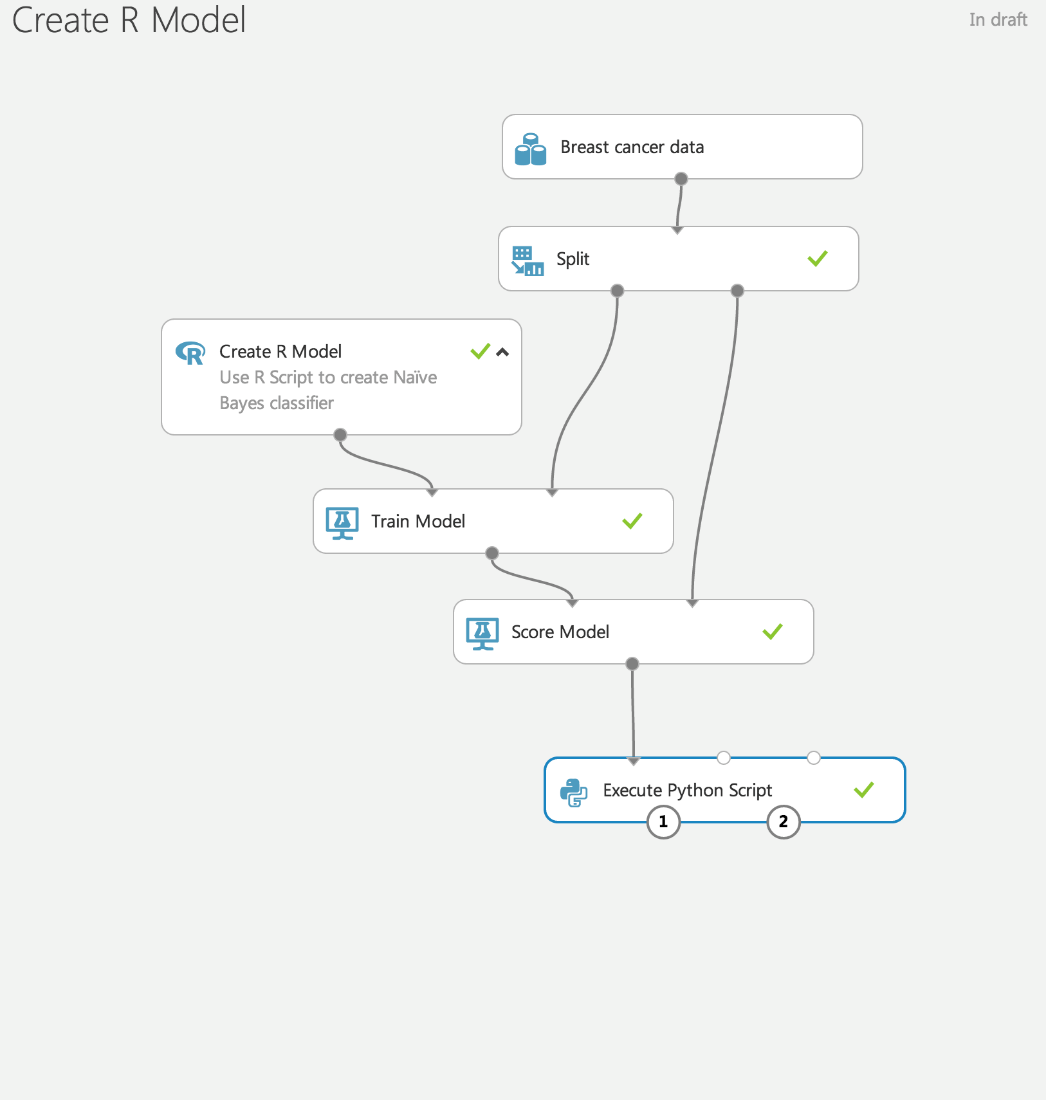
矢印で接続されたこれらのブロックは、特定のプロジェクト(または、Azure ML用語を使用するための実験)でのデータ分析のプロセスです。 この視覚化を使用すると、データ分析とCRISP-DM方法論の理解が大幅に促進されます。
この方法論の本質は次のとおりです。
- データが環境にアップロードされます。
- 有用な機能がデータから選択/作成されます
- モデルは、選択した機能でトレーニングされます。
- 別のデータセットを使用して、モデルの品質が評価されます
- 品質が不十分な場合は、手順2〜4が繰り返され、満足できる場合は、モデルがその目的に使用されます。
実験を作成するためのダイアログの記事では、最初のオプション「ブランク実験」を選択し、2ブロックをワークスペースに転送します。左側の「R言語モデル」セクションから「Rスクリプトを実行」、データ入力および出力から「ライター」。
開始するモデルは、最初の例で示したモデルよりも控えめに見えます。

「Execute R Script」ブロックに、データをダウンロードし、オブジェクトの新しいプロパティを選択し、モデルをトレーニングして予測を行うコードを配置しました。 ローカルマシンでスクリプトを実行する唯一の方法は、次の行を置き換えることです
write.csv(my_solution,file="my_solution.csv" , row.names=FALSE)
に
maml.mapOutputPort("my_solution")
ソリューションをクラウドに保存してからダウンロードできるようにするため(以下で説明します)。
Rコードの最後に、さまざまなパラメーターの重要性を示す行がありました。 スクリプト出力は、メニュー項目「Vizualize」をクリックすることにより、ブロックからの2番目の「出力」(スクリーンショットの番号「2」)で利用できます。

コードが機能するので、どの変数がタイタニックの乗客の生存にとって最も重要であるかを見ましたが、結果を取得してKaggleにアップロードする方法は?
これは、ラインを使用して予測を配置したブロックからの最初の出口が原因です。
maml.mapOutputPort("my_solution")
これにより、出力をRコードからWriterオブジェクトにリダイレクトし、データウェアハウスにデータセットを書き込むことができます。 設定として、実験で使用するリポジトリの名前(habrahabrdata1)と、結果を書き込むコンテナーのパスを指定しました:saved-datasets / kaggle-R-titanic-dataset.csv
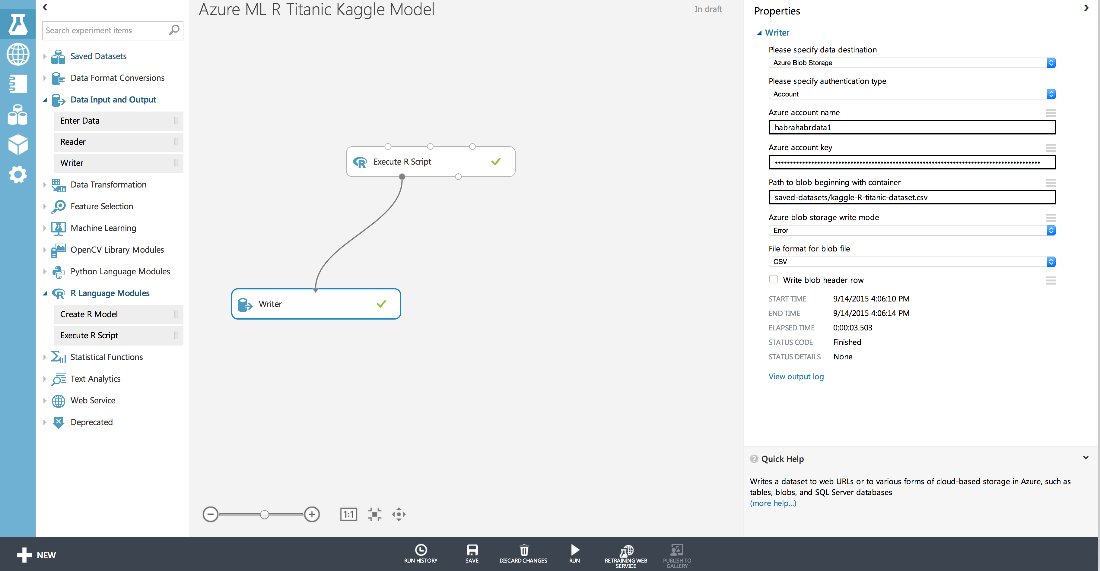
便宜上、この別個のストレージを事前に作成して、Azure MLサービスデータ間でデータが失われないようにします(実験ストレージで表示できます)。 ところで、リポジトリを作成するときは、アンダースコア「_」または大文字を使用できないことに注意してください。

モデルの予測は、クラウドストレージサービスからcsv形式ですぐにダウンロードされます。 このモデルを提出すると、結果が得られました: 0.78469
Azure Machine Learning Toolsを使用する
Azure MLのインターフェイスと作業に少し精通し、すべてが機能することを確認したので、クラウドに組み込まれたより多くの機能を使用してデータを操作できます。
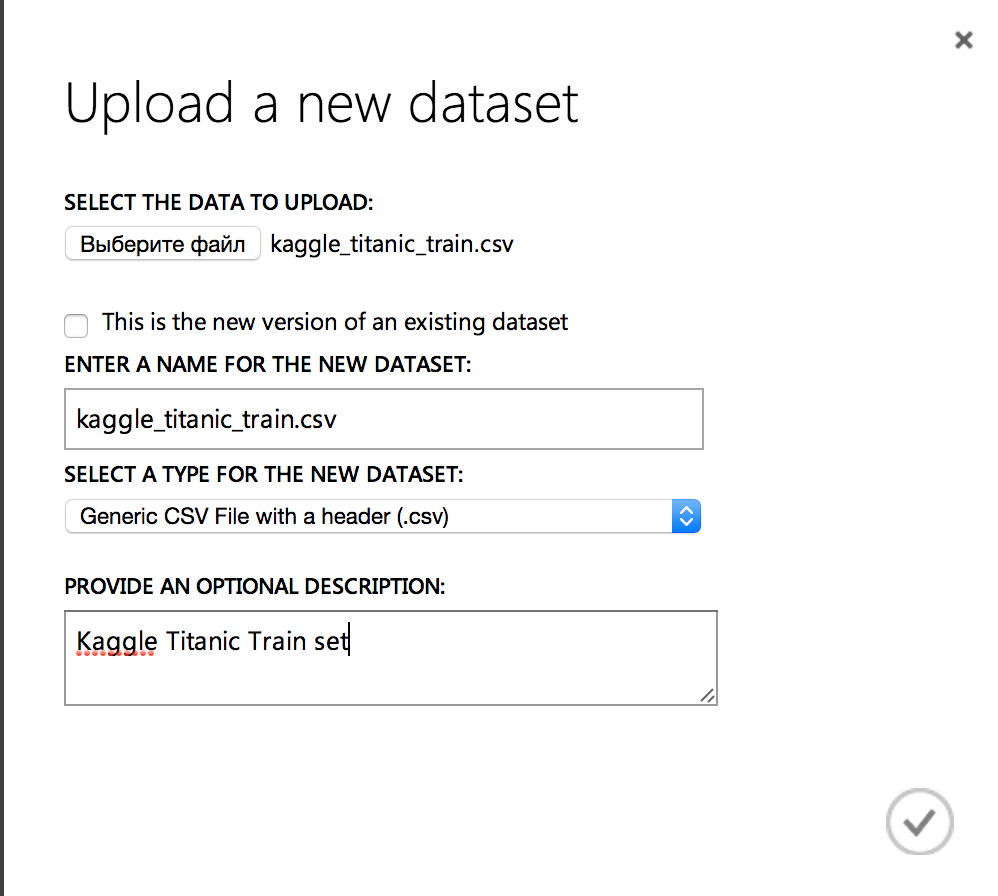
開始するには、トレーニングと評価のためにデータをクラウドにアップロードします。 これを行うには、「データセット」セクションに移動し、以前にダウンロードした.csvファイルをロードします。
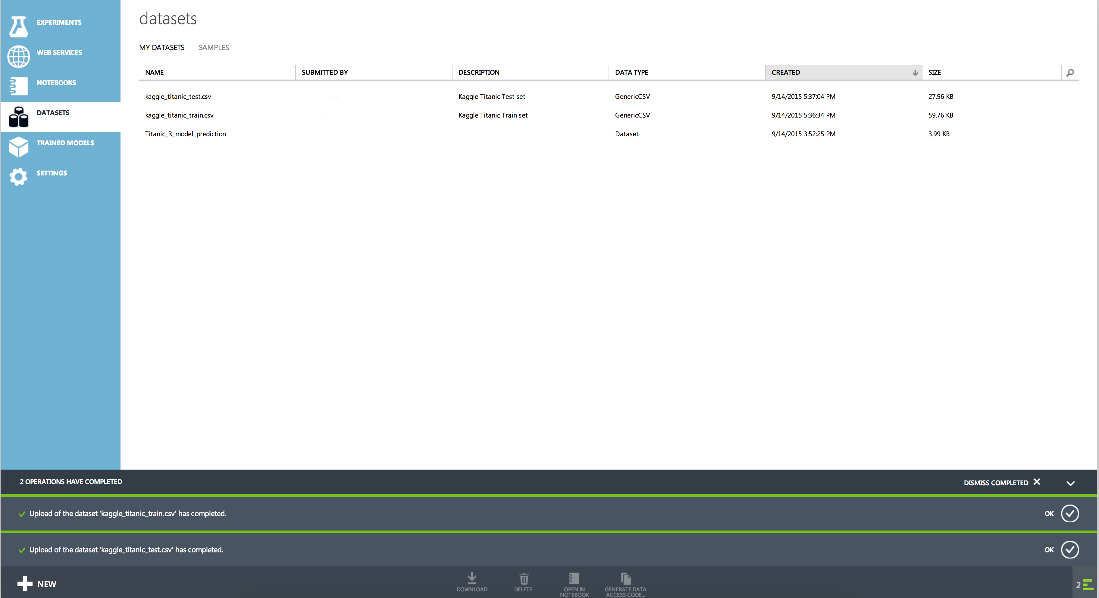
その結果、データセットは次のようになります。
したがって、以前はすべての作業を行っていたスクリプトを書き換えることができます。データをダウンロードし、初期処理を実行し、テストとトレーニングセットに分割し、モデルをトレーニングし、テストを評価しました。
単純なものから複雑なものに移行します。Rのコードはデータ処理のみを担当します。 データをアップロードし、クラウドを使用してトレーニングと品質評価のためのセットに分割します。
これを行うには、スクリプトの先頭に2行を追加します。
train <- maml.mapInputPort(1) # class: data.frame test <- maml.mapInputPort(2) # class: data.frame
そして、標識を処理するコードの後に終了します。
maml.mapOutputPort("all_data")
これで、実験の基本的なスキームは次のようになります。
そして、トレーニングセットとテストセットに分割する条件は次のようになります。
同時に、出力1には(分割条件が満たされているため)テストスイートがあり、出力2にはトレーニングがあります。
これで、AUC基準を使用して、クラウドに組み込まれたバイナリ分類アルゴリズムのパフォーマンスを評価する準備が整いました。 この実験の基礎として、 バイナリ分類子の比較の例を取り上げました。
1つのアルゴリズムの確認は次のとおりです。
各アルゴリズムは、kaggle_titanic_trainサンプルの一部を入力として受け取り、最適なアルゴリズムパラメーターを選択します。 これらのパラメーターはSweep Parametersブロック(詳細については、パラメーターの列挙に関する記事を参照)を使用して並べ替えられます。これにより、特定の範囲内のすべてのパラメーター、すべてのパラメーターのグリッド、またはランダムパスを使用できます。 Sweep Parameters設定で、評価基準を設定できます。 AUCをより適切な基準として設定します。
パラメータを選択した後、得られた最適なモデルは、サンプルの別の部分を使用して評価されます。 最適なパラメーターを持つモデルの結果は、実験全体の最後に表示されます。
最後のブロック「Execute R script」の最初の出口をクリックすると、結果が得られます。
最良の結果は、Two-Class SVMによって示されました。 Sweep Parametersブロックの出口をクリックして、最適なパラメーターを確認できます。
その結果、テストデータで乗客が生き残るかどうかを判断するために、最適なパラメーターでモデルを実行できます。
最適なモデルを決定するための実験を作成した後、新しいモデルは非常に単純になります。
彼女は以前のすべての実験と同じブロックを使用しています。 モデルは、Train Model入力でkaggle_titanic_trainデータセット全体を受け取り、Score Modelブロックを使用して、必要なすべての属性(Rを使用して計算した)でkaggle_titanic_testデータセットを評価(予測)します。 次に、乗客IDの列のみがセット全体から残され、予測は彼が生き残るかどうかを判断し、結果はBlobストレージに保存されます。
このモデルの結果をKaggleに送信すると、結果は0.69856になります。これは、決定木法を使用して取得した値よりも小さく、Rですべての作業を行います。
ただし、Azure ML(Two Class Decision Forest)から類似のパラメーター(ツリー数:100)で類似のアルゴリズムをトレーニングすると、結果をKaggleに送信すると0.00957改善され、0.79426に等しくなります 。
したがって、パラメータの「魔法の」列挙は、より徹底的な手動検索と、より良い結果を得ることができる専門家の仕事をキャンセルしません。
おわりに
Azure MLクラウド環境を使用して、Kaggleデータ分析コンテストに参加する可能性を検討しました:Rコードを実行する環境として、および組み込みクラウドツールを部分的に使用する(Rをプライマリ処理に残して新しい機能を生成する)
この環境は、特に分析の結果をHadoopクラスターに残しておく必要がある場合(Microsoftが実装を提供する場合)、またはWebサービスとして公開する必要がある場合に、機械学習のアプリケーションに使用できます。
肯定的な反応があった場合、このブログに、機械学習モデルをWebサービスとして公開する同様に詳細な例を投稿します。
Rの問題の完全な解決策
# All data, both training and test set # Assign the training set train <- read.csv(url("http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/train.csv")) # Assign the testing set test <- read.csv(url("http://s3.amazonaws.com/assets.datacamp.com/course/Kaggle/test.csv")) test$Survived <- NA all_data = rbind (train,test) # Passenger on row 62 and 830 do not have a value for embarkment. # Since many passengers embarked at Southampton, we give them the value S. # We code all embarkment codes as factors. all_data$Embarked[c(62,830)] = "S" all_data$Embarked <- factor(all_data$Embarked) # Passenger on row 1044 has an NA Fare value. Let's replace it with the median fare value. all_data$Fare[1044] <- median(all_data$Fare, na.rm=TRUE) #Getting Passenger Title all_data$Name <- as.character(all_data$Name) all_data$Title <- sapply(all_data$Name, FUN=function(x) {strsplit(x, split='[,.]')[[1]][2]}) all_data$Title <- sub(' ', '', all_data$Title) all_data$Title[all_data$Title %in% c('Mme', 'Mlle')] <- 'Mlle' all_data$Title[all_data$Title %in% c('Capt', 'Don', 'Major', 'Sir')] <- 'Sir' all_data$Title[all_data$Title %in% c('Dona', 'Lady', 'the Countess', 'Jonkheer')] <- 'Lady' all_data$Title <- factor(all_data$Title) all_data$FamilySize <- all_data$SibSp + all_data$Parch + 1 library(rpart) # How to fill in missing Age values? # We make a prediction of a passengers Age using the other variables and a decision tree model. # This time you give method="anova" since you are predicting a continuous variable. predicted_age <- rpart(Age ~ Pclass + Sex + SibSp + Parch + Fare + Embarked + Title + FamilySize, data=all_data[!is.na(all_data$Age),], method="anova") all_data$Age[is.na(all_data$Age)] <- predict(predicted_age, all_data[is.na(all_data$Age),]) # Split the data back into a train set and a test set train <- all_data[1:891,] test <- all_data[892:1309,] library(randomForest) # Train set and test set str(train) str(test) # Set seed for reproducibility set.seed(111) # Apply the Random Forest Algorithm my_forest <- randomForest(as.factor(Survived) ~ Pclass + Sex + Age + SibSp + Parch + Fare + Embarked + FamilySize + Title, data=train, importance = TRUE, ntree=1000) # Make your prediction using the test set my_prediction <- predict(my_forest, test, "class") # Create a data frame with two columns: PassengerId & Survived. Survived contains your predictions my_solution <- data.frame(PassengerId = test$PassengerId, Survived = my_prediction) # Write your solution away to a csv file with the name my_solution.csv write.csv(my_solution,file="my_solution.csv" , row.names=FALSE) varImpPlot(my_forest)
参照資料