
私たちは長い間ここにいなかったようで、私たちは手ぶらで帰らずに戻ってきています:はい! ある時点まで、Lingualeoは、新鮮なイディオムとTEDスピーカーからの「ライブ」語彙で語彙を補充する素晴らしい方法でした。 興味深いコンテンツを学習することでスキルを開発できます。 しかし、今日、すべてが変わりました。
次の7分間で、子供の頃に学んだこと、文章のNLP解析、フロントエンド開発の最新のチップ、オンラインでの文法学習の新しい方法について学びます。
Lingualeoのアクティブユーザーは既にテストに合格しており、スキルを向上させ、リアルタイムで進行状況を監視し始めています。 文法テストの結果を見て、どこで間違いが頻繁に発生するかを見ました。 そして、ここで2つのニュースがあります。 両方ともまあまあです。
- 最初:平均して、3番目の質問ごとに、学生は間違った答えをします。
- 2番目:新しく登録されたユーザーの33%(および、これは、2番目に約400万人)が英語の文法を知らない。
何かする必要がありました。 理解が来ました:潜在意識の文法構造を記憶するための最も簡単なメカニズムが必要です! 脳にまっすぐ。 だから、野心的。
Lingualeoにはすでに文法コースがあり、理論を学ぶことができます。これは現在何十万人もの人々が行っていることです。 しかし、理論は実践することでよりよく覚えられます。 時には、何かを言うために、ルールを知る必要すらありません。 主なことは確認することです:あなたの言うことは正しいです。 可能ですか?
英語で夢見るのは正しい
私たちは夜眠れず、正式なルールを勉強するのがあまり好きではない不幸な人たちについて考えましたが、私は英語で正しく話し、書き、夢を見たいです。 私たちは、人間の脳が何を記憶し、何を忘れるべきかを決定するという事実を非難しない勤勉な学生について心配していました。
ほとんどの人は、幼少期に母国語を話し始め、時代を区別することを学びました。 大人の後に繰り返しました! 時々彼らは私たちを修正し、私たちは間違いがどこにあったかを思い出しました。 基本的な原則は、正しいパターンを模倣して再現することでした。 ここにあります-文法をアップグレードする良い方法は私たちに合っています。
だから、英語の練習のための新しいリンガレオのセクション-Grammarに会ってください。

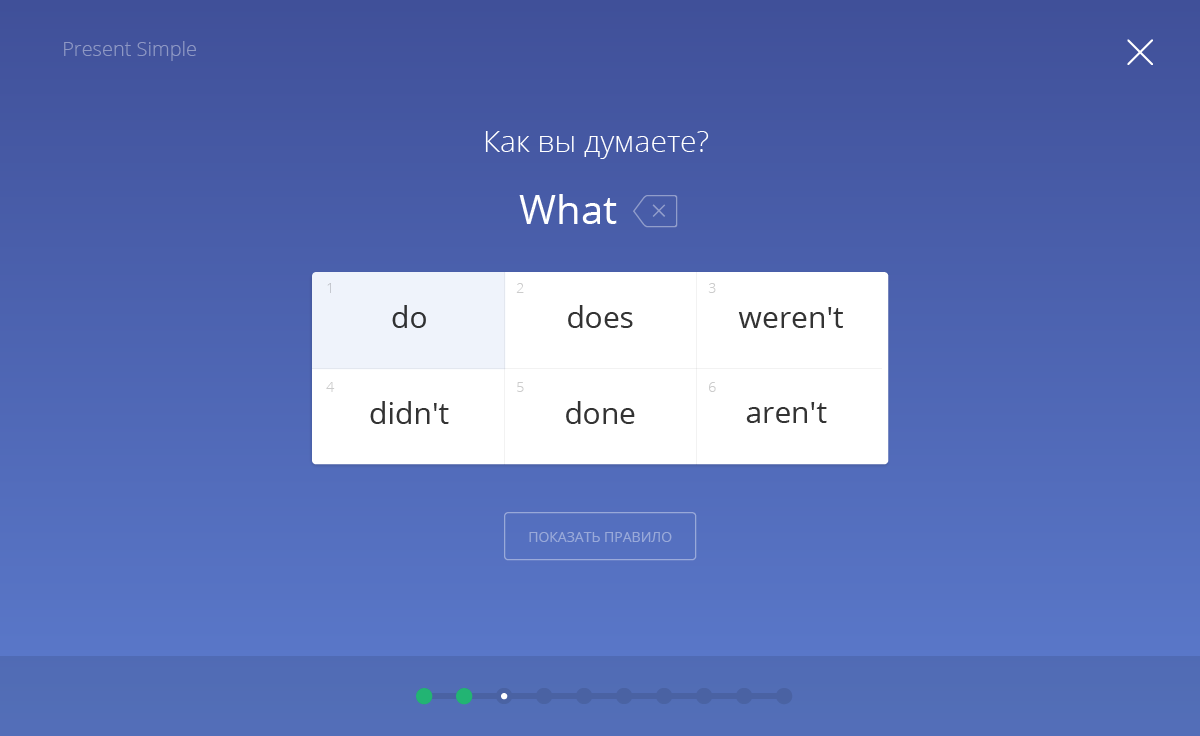
セクション内には、文法コンストラクタがあります。 ユーザーは、厳密な順序で提案された単語からフレーズを収集する必要があります。 いずれの場合も、特定の式の適用が訓練されます。 各ルールの数千の例が繰り返されることはないため、生徒は特定の例ではなく、原則そのものを覚えています。
特定の時間または文法式の使用の各ケースには、知識と知識の「強さ」の指標があります。 通常は研究されているため、緑色に変わります。 時間が経つにつれて、何かが忘れられます-この期間中にインジケータの色が変わり、レオ-材料を繰り返すことを強くお勧めします。
ちなみに、トレーニングはタスクシステムに統合されており、インターバルの繰り返しのすべての利点があります。 文法シミュレーターを使用して、語彙のトレーニングと面白い有益な資料の開発が点在しています。 これは、昨年末に目指した「インターリーブ」と同じです。
詳細については、次のいくつかの段落を読むことをお勧めします。
仕組みを理解する
現在、セクションがベータモードである間、シミュレータは無料です。 最も単純なものから最も複雑なものまで、10のルールがあります(モーダル動詞、分詞、受動態)。 このセクションは発展し、やがてすべての文法構造をカバーします。

ルールをクリックすると、トレーニングが始まります。 1つのアプローチでは、10個の文を収集する必要があります。 学生が間違いを犯した場合、それらが強調表示され、新しいチャンスが与えられます-そして、最終的に、彼は正しい順序でチェーンを折ります。 正しく構成された提案は自動的に表明されます。 発音オプションを選択することを忘れないでください-イギリス人またはアメリカ人。

構造とユースケースの構築がまだよくわからない場合は、提案の収集を開始する前に、「ルールを表示」ボタンをクリックしてヒントを使用できます。 重要なこと-ルールは多くの例とともに母国語で説明されています。
文法コースの理論に慣れることができた人は、すぐに構成を組み立てることができます。 私たちのチームは、トレーニングがあなたを悲しませないように努力しました。 その中には何千もの例があり、教科書の叔母や叔父コンパイラによって発明されたのではなく、リンガレオジャングルのお気に入りの本や興味深い科学記事から引用されています。 はい、一部の人々はこれらの申し出をすべて数十万の資料で解析しなければなりませんでした-詳細は後ほど。
詳細に深く入ります(いいえ、真剣に)
解析は次のように機能します。コンテンツをジャングルで公開すると、NLPサービスによって処理されます。 サービスはコンテンツを文章と単語に解析し、それらのさまざまなプロパティ(文章と単語の両方)を決定します。 文の場合、これは文法モデルであり、単語の場合、頻度です。 このような処理の後、テキストはモデレートされます。 UGCコンテンツでは、文中に多数のエラーがあると想定されているため、例の総数から質的で興味深いエラーのみを選択します。 オペレーターは1つまたは複数のルールをモデルに割り当てます。その後、このモデルのすべてのオファーをトレーニングに送信できます。 タダム!
そして今、この美しさをユーザーにどのように提示するか。 Web開発では、傾向は毎週変化する可能性があり、最新のコードは1年で廃止される可能性があります。 当社の製品の歴史は5年前です。 この期間中、多くのアーキテクチャの修正と改善が行われました。 ある時点で、新しいコードを簡素化し、サポートのコストを削減するために、概念的に異なるものへの移行が必要であることが明らかになりました。 多くの議論と議論の末、次のJS技術のスタックを選択しました。
- React-独自の実装のためのAPIの基礎。
- 仮想DOM-仮想DOMと連携します。
- BEM-スタイル、リソース。
- Redux-データストリーム。
- webpack -stash:近い将来、アセンブリ全体の基礎を作る予定です。
私たちの製品に取り組むのに適した非常に快適な環境が形成されました。 最初の実験の結果は、 文法セクションと進捗ログにあります 。
最初のテスターになる
私たちが得たものを自分で見てください! 文法はすでに最初のテスターを待っています。 そして、もしあなたがエラーを見つけたら書いてください-私たちはあなたの助けが必要です!
リンガレオで毎日練習し、楽しんで結果を出しましょう! Twitter 、 Facebook 、 vkontakte 、 Instagramでニュースをフォローしてください。