最初のアプローチには欠点があります-タイルには大量のストレージが必要です。 そのため、 OpenstreetMapによると、 2011年3月の時点で、タイルには54 TBのストレージスペースが必要でした。 2015年6月の現在のデータの計算によると、この数字はスケール0〜17のタイルを保存するためにすでに約100 TB(これは単なる推定値であり、実際の実験を敢行しませんでした)です。 このような見積もりの「ゲイン」は、過去にOpenStreetMapデータが大幅に補充され、2011年3月に空だったエリアが詳細になったためです。 また、PNG形式(2011年3月の OpenStreetMapの633バイトに対する平均タイルサイズは4.63KB)の非最適な圧縮(OpenStreetMapと比較して私の場合)を取り除くことも不可能です。 。 いずれにせよ、タイルストレージには非常に多くのスペースが必要ですが、すべてのサーバーが余裕があるわけではありません。 ブロックファイルシステムの場合、状況が悪化するのは、小さなサイズのタイルがブロック全体を消費するためです(103バイトのタイルはブロック全体、たとえば4KBを占めることができます)。これにより、ハードディスクの物理スペースが非効率的に使用されます。 1つのディレクトリ内に多数のタイル(大規模なマップ用)がある場合、ファイルシステムが許可するよりも多くの必要な数のファイルまたはディレクトリを保存できないという問題が依然として存在する可能性があります。 しかし、これらすべてにより、このキャンペーンは、タイルを返すためのリクエストを実行するための快適な時間を提供します。
2番目のアプローチは、タイルサーバーの容量を要求しませんが、要求されたクライアントサービスにタイルを確実に生成して提供するいくつかのサービス(PostgreSQL、Postgis、HStore、mapnik、renderd、mod_tile、apache)の組織とサポートを必要とします。 また、タイルキャッシュを定期的にクリーンアップする必要があります。 言い換えれば、タイルサーバーのハードディスクの小容量に対する支払いは、アーキテクチャの複雑さと、特定の各タイルの返却要求を完了するのにかかる時間です(私の計算によれば、1クライアントのみで最大500ミリ秒です。
この出版物では、タイルサーバーのアーキテクチャについては触れません。 最終的に、サーバーのハードウェアから始めて、独自のWebマップサービスをどのように構築するかはユーザー次第です。 この記事では、タイルストレージのいくつかの機能に注意を払い、Webマップサービスを最適に構築できることを知りたいと思います。
ところで、私は混合アプローチに基づいてWebマップサービスを構築することにしました。 実際、私のWebサービスからのユーザーリクエストの地理は非常に明確に定義されています。 つまり ユーザーが要求するマップコンテキストを事前に知っているため、このマップコンテキストでタイルを再レンダリングできます。 私の場合、必要なタイルの量は3〜17のスケールで511GBでした。 同時に、スケール3..13では、以前に知っていたマップコンテキストから開始せずにすべてのタイルを生成しました。 生成されたタイルの数と体積に関する統計情報をマップスケール別に示します。
| スケール | 生成された合計タイル | スケールの合計タイル(4 ^ズーム) | タイルの総数の%でシェアする | 生成されたタイルの量 | スケールの合計タイル | 合計タイルの%で共有 |
|---|---|---|---|---|---|---|
| 3 | 64 | 64 | 100 | 130万 | 130万 | 100 |
| 4 | 256 | 256 | 100 | 430万 | 430万 | 100 |
| 5 | 1,024 | 1,024 | 100 | 15M | 15M | 100 |
| 6 | 4,096 | 4,096 | 100 | 5,000万 | 5,000万 | 100 |
| 7 | 16 384 | 16 384 | 100 | 1億7600万 | 1億7600万 | 100 |
| 8 | 65,536 | 65,536 | 100 | 651M | 651M | 100 |
| 9 | 262 144 | 262 144 | 100 | 1.7G | 1.7G | 100 |
| 10 | 1,048,576 | 1,048,576 | 100 | 6.1G | 6.1G | 100 |
| 11 | 4 194 304 | 4 194 304 | 100 | 18G | 18G | 100 |
| 12 | 16 777 216 | 16 777 216 | 100 | 69g | 69g | 100 |
| 13 | 67108864 | 67108864 | 100 | 272g | 272g | 100 |
| 14 | 279 938 | 268 435 456 | 0.10 | 3.2G | 1.1T | 0.29 |
| 15 | 1 897 562 | 1,073,741,824 | 0.18 | 15G | 4.35T | 0.34 |
| 16 | 5 574 938 | 4,294,967,296 | 0.13 | 34G | 17.4T | 0.19 |
| 17 | 18 605 785 | 17179869184 | 0.11 | 94g | 69.6T | 0.13 |
| 合計 | 115 842 662 | 366503875925 | 0.51 | 511G | 92.8T | 0.51 |
タイルの過剰な複製
(途方もない能力に加えて)Webマップを開発するときに最初に気づいたのは、非常に頻繁に画像が繰り返されることです。 たとえば、海では、隣接する2つのタイルは同じように青く見えます。 ただし、視覚的に同じタイルとバイナリの同一タイルは2つの異なるものです。
仮説をテストして、2つの隣接するタイルのMD5チェックサムを比較したところ、同じであることが判明しました。
root@map:~# md5sum 10/0/0.png a99c2d4593978bea709f6161a8e95c03 10/0/0.png root@map:~# md5sum 10/0/1.png a99c2d4593978bea709f6161a8e95c03 10/0/1.png
これは、すべてのタイルがMD5チェックサムで一意であることを意味しますか? もちろん違います!
衝突のようなものがあります。 つまり 2つの視覚的(バイナリを含む)異なるタイルは、同じチェックサムを持つことができます。 任意のサイズのファイルには小さいものの、このようなリスクがあります。 原則として、Webカードは絶対的な正確さを必要としないリソースであるため(銀行取引や外国為替相場などとは異なり)、タイルの衝突の可能性が低いことは正当化できる許容可能なリスクであると想定しています...
そして、実際には、いくつかのハッシュ関数で同一のタイルがあることを知ることは重要ですか? おそらくすでに推測したでしょう。 1つのファイルとすべての重複のマッピングを保存できる場合(たとえば、通常のシンボリックリンクを使用して)、複数の同一のタイルを保存し、それらにハードディスクを占有するのはなぜですか?
したがって、タイルの衝突の可能性が低いことは許容できるリスクであり、タイルストレージの容量に対する要件の減少を正当化します。 しかし、重複をすべて削除することでどれだけのメリットが得られますか? 私の推定によると、タイルの最大70%が複製されます。 さらに、スケールが大きいほど、この数字は大きくなります。
ハッシュ関数によるタイルの重複の除去を推測したのは私が最初ではなかったことに注意する必要があります。 そのため、 スプートニクチームはこのニュアンスを使用して、タイルキャッシュを最適に編成しました。 また、一般的なMBtiles形式では、タイルの重複排除の問題が解決されます。
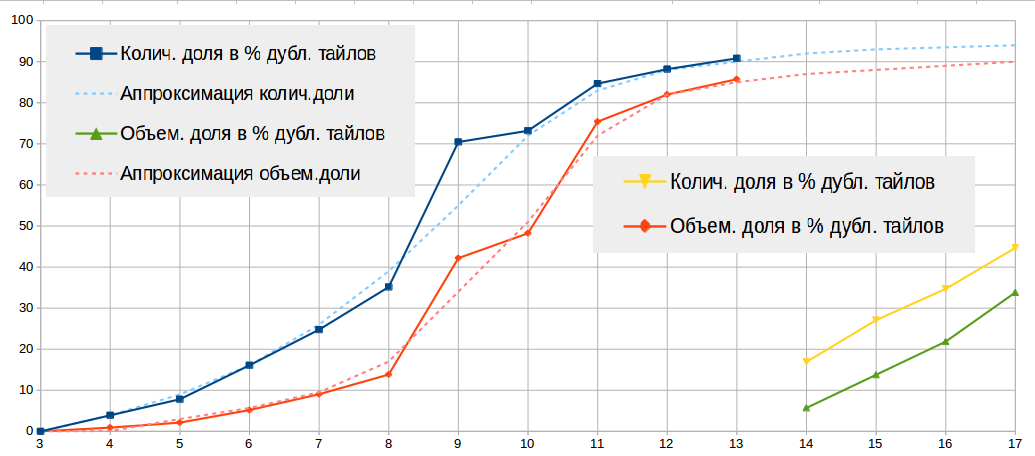
以下の表と図では、見つかったタイルの重複(MD5上)の統計を示しています。
| スケール | 総遺伝子。 タイル | 総テイク。 タイル | コリチ。 倍のシェア。 タイル | 遺伝子の量。 タイル | シンボリックリンクを作成した後のタイルの量 | ボリューム。 倍のシェア。 タイル |
|---|---|---|---|---|---|---|
| 3 | 64 | 0 | 0 | 130万 | 130万 | 0 |
| 4 | 256 | 10 | 3.91 | 430万 | 420万 | 0.92 |
| 5 | 1,024 | 80 | 7.81 | 1460万 | 14.3M | 2.13 |
| 6 | 4,096 | 659 | 09/16 | 4,970万 | 47.1M | 5.18 |
| 7 | 16 384 | 4 058 | 24.77 | 175.4M | 1億5960万 | 9.04 |
| 8 | 65,536 | 23 031 | 35.14 | 650.3M | 560.3M | 13.83 |
| 9 | 262 144 | 184 668 | 70.45 | 1710M | 989M | 42.18 |
| 10 | 1,048,576 | 767 431 | 73.19 | 6.1G | 3.1G | 48.22 |
| 11 | 4 194 304 | 3,553,100 | 84.67 | 18G | 4.4G | 75.41 |
| 12 | 16 777 216 | 14 797 680 | 88.18 | 69g | 12.4G | 82.01 |
| 13 | 67108864 | 60 945 750 | 90.82 | 271.1G | 38.7g | 85.74 |
| 14 | 279 938 | 47 307 | 16.9 | 3.2G | 185M | 5.71 |
| 15 | 1 897 537 | 514 005 | 09/27 | 14.2G | 12.3G | 13.78 |
| 16 | 5 574 938 | 1 934 553 | 34.70 | 33.8g | 26.4G | 21.86 |
| 17 | 18 605 785 | 8 312 466 | 44.68 | 93.8G | 62G | 33.82 |
| トータル編集 | 115 842 662 | 91 084 800 | 78.63 | 511G | 164G | 07/32 |
次のことに留意する必要があります。
- 私は大都市のコンテキストでタイルを生成しましたが、それ自体がタイルの複製率を悪化させました。 大都市では、海よりも2つの同一のタイルに出会う可能性が低くなります。 したがって、スケール3〜13のデータは、地球全体でのタイルの重複の程度を示し、スケール14〜17のデータは、大都市のコンテキストでのみ重複を示します。
- スケールのタイル3 ... 10 1つのmapnikスタイルファイルで生成し、タイル11 ... 17を別のスタイルファイルで生成しました。 さらに、異なるスタイルで描画スタイルの異なるルールがトリガーされるため、異なるスケールでタイルを描画する際に不均一性が生じます。 この事実により、統計に多少のノイズが生じます。
- 原則として、いわゆる空のタイルは複製され、サイズはわずか103バイトです。 したがって、タイルストレージのサイズの大幅な削減は期待できません。これは、スケール9..12のデータで示されています。 平均して、タイルの複製率が70%の場合、スケールディレクトリのサイズをわずか50%に減らすことができます。
- 元のタイルの選択のランダム性を考慮して、スケールの統計はノイズが多い、つまり 同じタイルが10番目と12番目のスケールで発生する場合、スケール10の元のタイルを複製として取ると、スケール12のタイルと見なされ、逆も同様です。 タイルがどのように分類されたかに応じて、適切なスケールの統計にノイズが導入されます。 この点で、スケールの線に沿ってテーブルにランダム性の要素があります。 絶対的な信頼に値するのは、 「合計」の行のみです。
ブロックファイルシステムの問題について一言
遅かれ早かれ、ファイルシステムの選択の問題に直面するでしょう。 最初に、システムにすでにあるファイルシステムを使用します。 しかし、大量のデータに遭遇したり、タイルの過剰な複製に遭遇したり、並列リクエスト中に長いファイルシステムの応答で問題が発生したり、これらのディスクに障害が発生するリスクがある場合は、おそらくタイルキャッシュを配置する方法について考えるでしょう。
原則として、タイルはサイズが小さいため、 ブロックファイルシステムでのディスクスペースの非効率的な使用につながります 。また、多数のタイルはすべての空きiノードを使い果たす可能性が非常に高くなります。 ブロックサイズを小さなサイズに縮小すると、次のように最大ストレージ容量に影響します 通常、ファイルシステムはiノードの最大数によって制限されます。 重複するタイルをシンボリックリンクに置き換えても、タイルストレージに必要な容量を大幅に削減することはできません。 部分的に、ブロックの非充填の問題は、メタテーリングメカニズムの助けを借りて解決できます-いくつかのタイル(通常8x8または16x16)が特別なヘッダーを持つ単一のファイルに保存され、どのバイトに必要なタイルが含まれているかがわかります。 しかし、残念ながらメタタイルはタイルを重複排除するための労力をゼロに減らします。 2つの同一のメタタイル(集合N x Nタイル)を満たす可能性が大幅に低下し、メタファイルのヘッダー形式(8 x 8タイルのメタファイルを含む最初の532バイト)にはメタファイルのアドレスの書き込みが含まれます。 それにもかかわらず、今日では、メタタイリングを使用することで、隣接するタイルへのリクエストを「予測」できるため、タイルサーバーの応答時間を短縮できます。
いずれにせよ、タイルストレージの場合、いくつかの条件を満たしている必要があります。
- ディスクスペースの効率的な使用を確保します。これは、ブロックファイルシステムのブロックサイズを小さくすることで実現できます。
- 多数のファイルとディレクトリのサポートを提供する
- 要求に応じてタイルの可能な限り最速のリターンを提供します
- タイルの重複を除外
上記の要件を最もよく満たすファイルシステムはZFSです。 このファイルシステムには固定ブロックサイズがなく、ブロックレベルでのファイルの重複が排除され、頻繁に使用されるファイルのメモリにキャッシュが実装されます。 同時に、Linuxオペレーティングシステムの組み込みサポートがなく(GPLライセンスとCDDLライセンスの非互換性のため)、プロセッサとRAMの負荷が増加します(従来のExtFS、XFSなどと比較して)。これは、物理的なフルコントロールの結果です。および論理キャリア。
BtrFSファイルシステムはLinuxにやさしく、重複排除(オフライン)をサポートしていますが、実稼働システムでは非常に未加工です。
タイルの重複を排除し、ディスク領域を可能な限り効率的に使用する他のソリューションがあります。 それらのほとんどすべてが、仮想ファイルシステムを作成し、それに接続して、この仮想ファイルシステムにアクセスし、その場でファイルを重複排除し、キャッシュに入れたり、キャッシュからファイルを送信したりすることができます。
たとえば、UKSM、LessFS、NetApp、およびその他の多くは、サービスレベルでデータ重複排除を実装しています。 しかし、実稼働環境では、特に高負荷のWebサービスでは、大量のサービスに大きな問題が伴います。 したがって、本番用のタイルキャッシュアーキテクチャの選択は、耐障害性が高く、管理が容易でなければなりません。
有名なスプートニク (言及された開発者に許されます-このプロジェクトは、私のWebマップサービスを構築することに基づいて私にとってポジティブな例になりました)は、独自の重複排除アルゴリズムを実装します。これは、タイルの重複排除を可能にする特定のハッシュ関数タイルは柔軟なCouchBaseに保存されます。
また、制作に自信を持っていた手段と似たようなものを構築しようとしました。 この場合、私の選択はRedisにかかっていました。 私の経験では、タイルをRedisのメモリに配置すると、ファイルシステムに配置する場合と比べて、占有メモリ量を30%削減できることが示されています。 なぜRedisを使用すると思いますか? 結局のところ、彼はRAMに住んでいますか?
この選択にはいくつかの理由があります。 まず第一に、信頼性。 実稼働中の1年間で、Redisは非常に信頼性が高く高速なツールとしての地位を確立しています。 第二に、理論的には、メモリからの応答はファイルシステムからの応答よりも高速です。 第三に、サーバーのRAMのコストは比較的低くなり、ハードドライブの信頼性はそれほど高くなく、近年改善されています。 つまり ハードディスクを使用したサーバーの集中的な作業(タイルのアップロード時に発生する)により、サーバーの障害のリスクが大幅に増加します。 さらに、私の組織には、それぞれが515GBのRAMを備えた約100台のサーバーがありますが(小さなハードドライブを使用)、メモリにタイルを効率的に配置できます(zxyが正しくプロキシされている場合->特定のサーバー)。 いずれにしても、私の選択はRedisにかかった。 尊敬される読者には押し付けません。 独自のWebマップサービスのアーキテクチャを独自に決定できます。
この記事には、Webマップサービスの文書化されていないニュアンスについて話すという1つの目的しかありませんでした。 無駄な研究作業ではなく、できれば私の研究を犠牲にして時間とお金を節約してください!