私の以前の出版物のように、方法の使用例とソリューションの視覚化が調査結果に示されています。 共クラスタリングアルゴリズムの典型的な応用分野は、バイオインフォマティクス、画像セグメンテーション、テキスト分析です。

クラスタリングの場合のように、データを共クラスタリングするには、多くのアルゴリズムがあります。 ウィキペディアは 、少なくとも22の共クラスタリング手法を報告しています。 この記事では、そのうちの1つだけの機能を示します。 この方法は、ブロッククラスタリングと呼ばれます。 その本質は、このアプローチの著者による記事からの写真で最もよく表されます[1]。
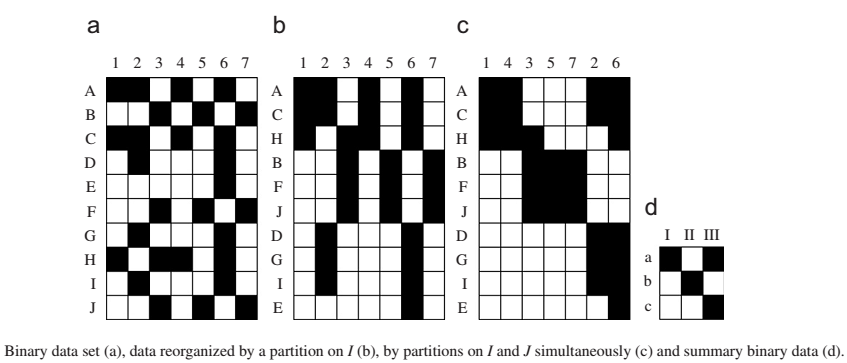
つまり、タスクは、データモザイクからブロックビュー画像を組み立てることです。 数学的には、この方法は、非負行列の3因子分解の手順を使用して形式化できます。 Vをサイズnxmの入力行列とします。 フォームで提示する必要があります
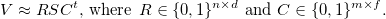
行列RおよびCの各行には1つのユニットが含まれ、残りの要素はゼロです。 行列Rの単位要素( ij ) は、行列Vの行iが j番目の水平クラスターに属することを示します。 行列Cの単一の要素( kl ) は、行列Vの列kが l番目の垂直クラスターに属することを示します。
行列RとCは、損失関数を最小化するように選択されます。
 この場合、 Dはフロベニウスのノルムによって決定されます。
この場合、 Dはフロベニウスのノルムによって決定されます。

この形式化は[2]に戻り、非負行列の直交3因子化が提案されました。 このような問題の記述により、非負行列の因数分解の方法と同様に、入力行列の指示された分解を見つけるための反復法を適用できます。
しかし、この出版物では最尤法を使用して得られたブロッククラスタリングの例を調べます。 アルゴリズムの詳細は[1]にあります。 原則として、このアプローチでは、解決策を見つけるために大きな計算コストが必要です。 しかし、利点があります。 まず、この方法を使用すると、アルゴリズムの観点から、カテゴリーデータの水平クラスターと垂直クラスターの数を最適に自動的に決定できます[3]。 第二に、アルゴリズムは、入力データのタイプ-カテゴリカル(特にバイナリ)または連続(この場合、入力データが負でないことを制限する必要はありません)を考慮することを可能にします。 計算には、R環境のblockclusterパッケージ[4]が使用されます。

この出版物の主な目的は、クラスタリングソリューションの視覚化機能を示すことです。 ブロッククラスタリングの顕著な特徴は、両方向のデータのセグメント化に加えて、このタイプのクラスタリングでは、入力データの値が変換されないことです。 唯一の順列は、入力行列の行と列です。 これにより、クラスタリングの結果として視覚化することができ、解釈が容易です。 行列の列数が数百または数千単位で測定される場合、おそらく、得られた結果の予備処理が必要になることを予約します。 ただし、以下で説明する調査結果の分析タスクでは、通常、非常に多数の変数によるクラスタリングは必要ありません。
タスクで変数のグループを選択する必要はないが、データのブロック形式を把握したい場合はどうすればよいですか? 共クラスタリングでは、変数を強制的にグループ化する必要はまったくありません。 そのような例から始めましょう。
例1:世界の自由(Freedom House 2015データ)
Freedom in the World(FIW)データは、Freedom Houseが実施した専門家の調査に基づいた195か国の政治的権利と市民の自由の比較評価です。 最大7つのサブカテゴリに集約された2015年のデータは、 こちらから入手できます 。
これらの7つの変数の結果に基づいて、195の国のそれぞれに2つの格付け-政治的権利と市民的自由が割り当てられ、これらの格付けの結果によると、国の最終ステータスは無料、部分的に無料、非無料(3グループのみ)です。
(4.1)FIWデータを共クラスタリングするRコード
library(data.table) library(blockcluster) fiw.2015 <- fread("FIW 2015.csv") fiw.2015.clusters <- cocluster(as.matrix(fiw.2015[,LETTERS[1:7],with=FALSE]), datatype = "categorical",model = "pik_rhol_multi", nbcocluster = c(4,1), strategy = cocluststrategy(nbinititerations=100, nbxem = 20, nbtry = 20 ))
blockclusterクラスのオブジェクトの場合、plot()関数のサポートが実装されていますが、クラスタリングソリューションを表示する独自のバージョンを使用しています。
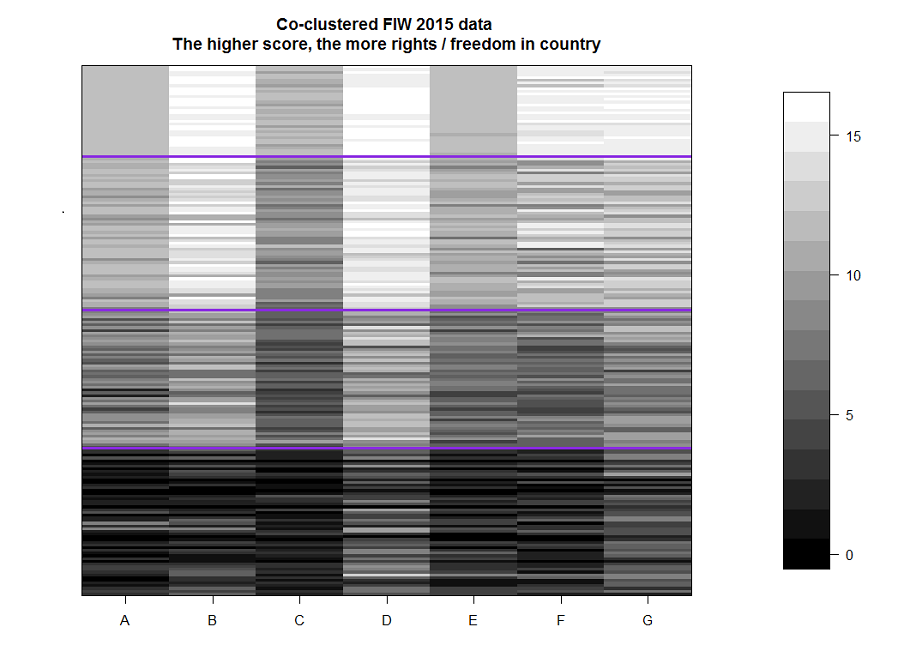
いくつかの場合を除き、すべての国のクラスタリングの結果は、レポートの上位2つのクラスターが同じステータス(無料)であるという事実に合わせて調整された、フリーダムハウスによって提案されたステータスに対応しています。 それにもかかわらず、特に変数「F」と「G」において、2番目のクラスターが最初のクラスターとは明らかに異なることが容易にわかります。 また、この結果は、一般に、各クラスターが一度にすべての変数の前のクラスターより「暗い」ことを示しています。 タブローパブリックのマップに表示されたブロッククラスタリングの結果( リンク )
私の意見では、クラスタリングのタスクは社会学的というよりもマーケティング調査を目的としています。 オーディエンスの特性のセグメンテーションと強調表示は、このようなデータの分析において非常に重要な要素です。 しかし、誰もオープンアクセスのためのマーケティング基盤を設計していません。 したがって、例として社会学的データを使用したブロッククラスタリングの図を考えてみましょう。もちろん、研究の種類は方法の本質に影響を与えません。
例2:民主主義モジュール(ヨーロッパ社会調査2012データ)
ESSプロジェクトの研究は、以前のすべての出版物で言及されています。 データを取得できる場所とデータをRにアップロードする方法を示します。調査の単位ごとに、ターゲットオーディエンスと変数を、民主主義に関する質問とともにグループ化します。
回答者は、民主主義の16の基本的価値の重要性について評価(0から10)を行い、回答者の国が現在の民間機関と権利に関する14の主張を適用した程度(0から10)を評価するよう求められました。 極値:
0-「まったく重要ではない」/「完全に真実ではない」。
10-「非常に重要」/「完全に真実」。
モジュールと質問自体に関する詳細情報は、このリンクから入手できます。
これは、エストニアからの回答者向けのロシア語のアンケートを含むpdfファイルへのリンクです。
ターゲットオーディエンスを設定します。フランスまたはロシアの15歳以上の男性です。
(5.3)ESSデータの共クラスタリングを伴うRコード
# block.e.names are names of Democracy module variables that were taken from questionnaire. data <- subset(srv.data, cntry %in% c("FR", "RU") & gndr =='Male', select = c('cntry', block.e.names[1:30])) command <- paste("data.m <- data[,as.numeric(c(", paste(block.e.names[1:30], collapse = ","), ")) - 1]") eval(parse(text=command)) dim(data.m) <- c(length(data.m)/30, 30) data.m[is.na(data.m)] <- -1 data.clusters <- cocluster(data.m, datatype = "categorical",model = "pik_rhol_multi", nbcocluster =c(5,3), strategy = cocluststrategy(nbinititerations=100, nbxem = 40, nbtry = 40 ))
ブロックカードに結果を表示する場合、欠損値(NA)を-5に置き換えて、0から大きく異なるようにします。
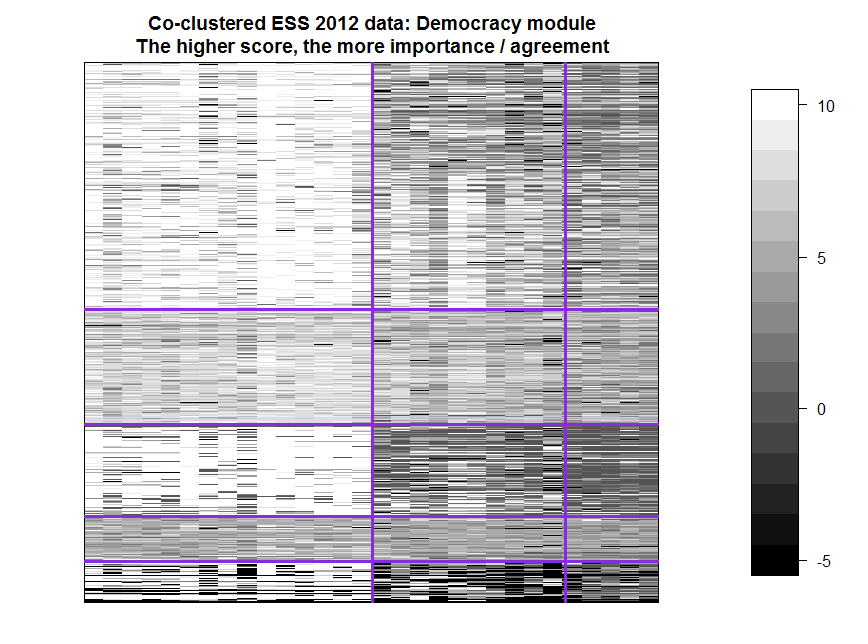
クラスターには、左から右、上から下に番号が付けられています。
まず、垂直クラスターについて。 最初の(明るい)クラスターには、民主主義の一般的な(仮説)値に関する最初の15の質問が含まれています。 最初のクラスターに分類されなかった民主主義の基本的価値に関する16の質問のうちの1つは、統合の質問(「政策決定を行う前に他の欧州諸国の政府の意見を考慮に入れることが重要です」)であり、2番目のクラスターに分類されました。 主に1番目と3番目の水平クラスターでは、3番目の垂直クラスターは2番目よりも暗いです。 この3番目のクラスターは、次の命題で構成されます

民主主義における基本的な市民的および政治的価値の重要性を強調する回答者-1および3の水平クラスター-より現実に批判的です-2および3の垂直クラスター。 3番目の水平クラスターは、最初のクラスターに比べて悲観的です。
水平クラスター2と4は垂直成分でより均一ですが、特に最初の垂直成分では、4番目は2番目よりも暗いです。 第4クラスターの回答者は、国の民主的な生活に価値があることを重要とは考えていません。
5番目の水平クラスターには、主に2番目と1番目の垂直クラスターからの多くの質問に答えなかった多くの回答者がいます。 左下隅は非常に対照的です-質問に対する回答がないか、特定の値の重要度が高いと主張されています。
例の詳細。 記事の最後にあるこのpdfは 、ブロック画像クラスタリングの結果の例と科学論文の要約のテキストを示しています。
参照:
[1] G. Govaert、M。Nadif、Bernoulli混合モデルによるブロッククラスタリング:異なるアプローチの比較、計算統計とデータ分析、第52巻、第6号、2008年2月20日、ページ3233-3245。
[2] C. Ding et al。 クラスタリングのための直交非負行列t因子分解//知識発見とデータマイニングに関する第12回ACM SIGKDD国際会議の議事録。 -ACM、2006 .-- S. 126-135。
[3] C.ケリビン等。 カテゴリデータ//統計およびコンピューティングの潜在ブロックモデルの推定と選択。 -2014 .-- S. 1-16。
[4] PS Bhatia et al。 blockcluster:バイナリ、コンティンジェンシー、連続およびカテゴリデータセット用の共クラスタリングパッケージ。 Rパッケージバージョン3.0.2
更新: (5.3)共クラスタリングのRコードで、入力行列のNA値が置き換えられた行がスキップされました。