家に着いたとき、私はこの問題について考えました。 フォーラムでこの問題の解決策を探しました。 誰かが私に同意しましたが、多くの人はオフセット操作がネイティブメソッドによって実行されることを考慮しました。 ネイティブメソッドの方が高速であるため、ArrayListはより速く中央に挿入されます。 最終的な反論できない答えを受け取っていないので、私は自分の研究を行うことにしました。
最初は、これらのクラスのソースコードを深く掘り下げました。 要素は、次のようにArrayListに挿入されます:最初に、必要に応じて配列が大きくなり、次に挿入ポイントの後のすべての要素が挿入された要素の数に等しい位置の数だけシフトされ(1つの要素と見なされます)、最後に挿入された要素が配置されます。 配列は、n * 1.5の速度で増加します。ここで、nは配列のサイズであり、標準条件(容量= 10)での最小増加は5要素です。 この点で、挿入のアルゴリズムの複雑さを計算するときに配列を増やす操作は無視できます。 挿入ポイントの後にある要素のシフトには、アルゴリズムの複雑度O(n)があります。 したがって、全体的な複雑さはまだO(n)です。 はい、配列を増やす操作は複雑さをわずかに増加させますが、配列を使用したアクションのネイティブ性により作業速度が向上することに留意してください。
LinkedList内のアイテムの検索は、リストの端からループで始まります。 探しているアイテムがリストの前半にある場合、検索は最初から行われ、そうでない場合は最後から行われます。 ちょうど真ん中に挿入するので、サイクルでは要素のちょうど半分を通過します。 複雑さO(n)。 挿入自体は、上で書いたように、オブジェクトを作成し、それへのリンクを指定することです。 複雑さO(1)。 繰り返しますが、オブジェクトの作成は「高価な」操作であることに留意しながら、全体的な複雑さはO(n)のままでした。
ソースコードの分析では状況が明確にならないため、テストを書き始めました。 リストの初期サイズと行の挿入数(反復回数)の2つのパラメーターへの依存関係を調査することにしました。
ソースコード例
package com.jonasasx.liststest; import java.util.ArrayList; import java.util.LinkedList; import java.util.List; public class Main { private static final int MAX_SIZE = 1000; private static final int MAX_ITERATIONS = 10000; private static final float STEP_SIZE = 2f; private static final float STEP_ITERATIONS = 5; private static final int TESTS_COUNT = 100; public static void main(String[] args) throws InterruptedException { ArrayList<String> arrayList; LinkedList<String> linkedList; for (float size = 1; size < MAX_SIZE; size *= STEP_SIZE) { for (float iterations = 1; iterations < MAX_ITERATIONS; iterations *= STEP_ITERATIONS) { double sum = 0; for (int k = 0; k < TESTS_COUNT; k++) { arrayList = new ArrayList<>(); linkedList = new LinkedList<>(); fillList(arrayList, (int) size); fillList(linkedList, (int) size); sum += Math.log10(calculateRatio(arrayList, linkedList, (int) iterations)); } double logRatio = sum / TESTS_COUNT; System.out.println(String.format("%07d\t%07d\t%07.2f\t%s", (int) size, (int) iterations, logRatio, logRatio > 0 ? "Linked" : "Array")); } System.out.println(); } } static void fillList(List<String> list, int size) { for (int i = 0; i < size; i++) { list.add("0"); } } static double calculateRatio(ArrayList<String> arrayList, LinkedList<String> linkedList, int iterations) { long l1 = calculateAL(arrayList, iterations); long l2 = calculateLL(linkedList, iterations); if (l1 == 0 || l2 == 0) throw new java.lang.IllegalStateException(); return (double) l1 / (double) l2; } static long calculateAL(ArrayList<String> list, int m) { long t = System.nanoTime(); for (int i = 0; i < m; i++) { list.add(list.size() / 2, "0"); } return System.nanoTime() - t; } static long calculateLL(LinkedList<String> list, int m) { long t = System.nanoTime(); for (int i = 0; i < m; i++) { list.add(list.size() / 2, "0"); } return System.nanoTime() - t; } }
各リストサイズと反復回数に対して、1つのArrayListおよびLinkedList配列が作成され、同じオブジェクトで満たされます。その後、速度を測定するために中央の1つのオブジェクトのn回の測定が行われます。 比較値として、ArrayListとLinkedListの実行時間の比率の10進数の対数を使用します。 この値が0未満の場合、ArrayListはLinkedListよりも高速の場合、より高速に処理します。
表にテスト結果を示します。
| 繰り返し | |||||||||||
| 大きさ | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | |
| 1 | -0.12 | 0.01 | -0.04 | 0.01 | 0,03 | -0.04 | -0.09 | -0.19 | -0.21 | -0.31 | |
| 5 | -0.14 | 0.02 | -0.02 | 0,07 | -0.08 | 0 | -0.15 | -0.31 | -0.42 | -0.52 | |
| 25 | -0.12 | 0.2 | 0.19 | 0.13 | 0,07 | 0.04 | -0.1 | -0.29 | -0.47 | -0.56 | |
| 125 | -0.31 | -0.01 | 0.01 | 0 | -0.03 | -0.11 | -0.17 | -0.35 | -0.48 | -0.57 | |
| 625 | -0.47 | -0.49 | -0.48 | -0.45 | -0.49 | -0.51 | -0.53 | -0.6 | -0.67 | -0.78 |
そしてグラフで:

リストの初期サイズはx軸に示され、線は異なる反復回数を表し、y軸にはリストの2つの実装の速度の比を示します。
リストのサイズは反復ごとに増加するため、一般的な結論を導き出すことができます。LinkListは、リストのサイズが小さいほど高速に動作します。 しかし最も重要なことは、条件を明確に指定しないと、これら2つのアルゴリズムの速度を比較することは不可能だということです!
精度を上げるために、挿入数のパラメーターを拒否し、サイズステップを1に減らしました。 サイズごとに、テストを数千回実施し、平均値を取りました。 チャートを得た:
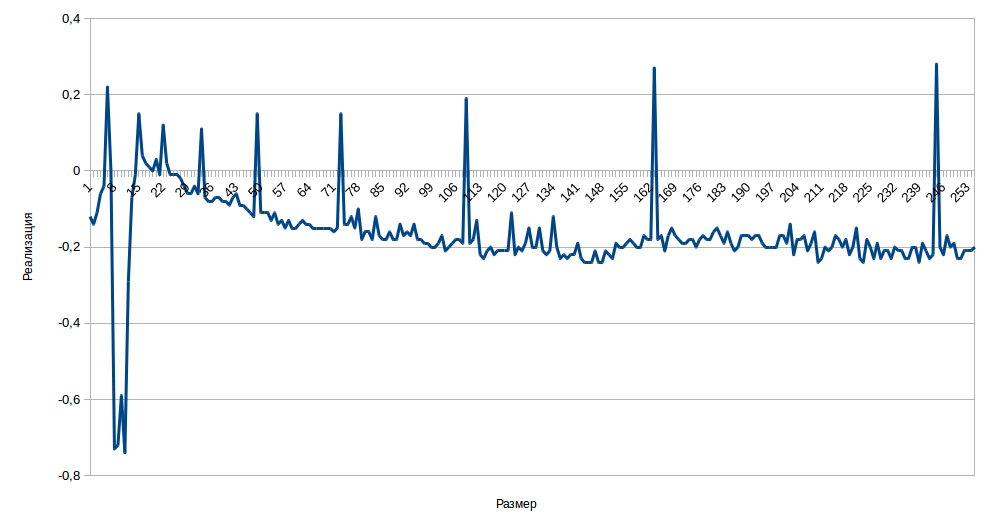
グラフはバーストをはっきりと示しています。 ArrayListが配列の増加を生成する場所に正確に配置されます。 したがって、最初にソースコードを分析して計算したように、この操作は無視できないと言えます。
一般的な結論は次のように作成できます。中央での挿入操作は、ArrayListで最も高速に発生しますが、常にではありません。 理論的な観点から、リストの初期サイズを考慮せずにこれら2つのアルゴリズムの速度を明確に比較することは不可能です。
ご静聴ありがとうございました。誰かが私の作品を面白く、そして/または役に立つと思うことを願っています。