これは当社を代表するHabréの最初の投稿であり、サーバーおよびWebサイトCloudStats.meを監視するためのクラウドサービスのアーキテクチャについて少しお話ししたいと思います。 また、現在の統計情報を共有し、近い将来の計画についてお話ししたいと思いますが、最初にまず最初に。
1.システムアーキテクチャ
私たちのプラットフォームは、NagiosやZabbixの設定に長時間煩わされたくないが、監視に多くの時間とリソースを費やすことなくメインサーバーのパラメータを監視する必要があるシステム管理者を対象としています。 私たちは設定の数でシステムインターフェースをオーバーロードしないようにしていますので、すべてがKISSの原則に基づいて構築されています(単純に愚かにしてください)。
システム全体は、 RactiveJSを使用して、Ruby on Rails(Pythonエージェントを除き、まもなくRubyのエージェントに置き換えられます)で記述されています。 フロントエンドは、Haproxyを使用して分散される負荷であるTomcatで実行されます。 CloudFlareは、静的JS、CSS、PNGなどのファイルのみが通過するCDNとして使用します。 それにもかかわらず、このような非常に単純でまだ大規模ではないサービスであっても、混雑を避けるためにプラットフォームのすべての部分に負荷分散を適用する必要があります。
6月末のサービスアーキテクチャ:
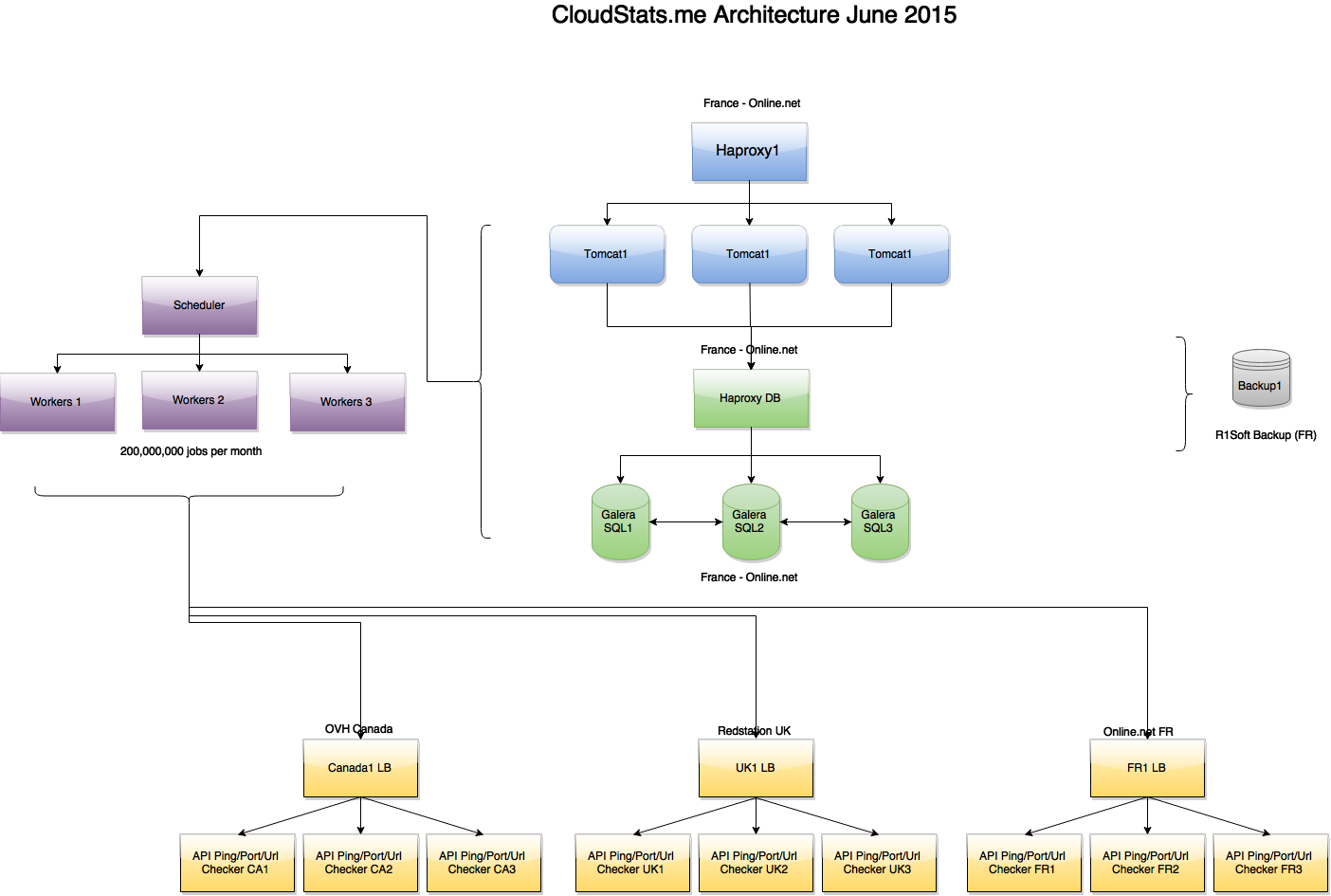
( 全体像 )
図からわかるように、タスクは別のスケジューラノードによって作成され、複数のワーカーノードによって処理されます。これらのノードは、APIを介して、3つのゾーン(フランス、英国、米国)にあるPing /ポート/ URLチェックサーバーに接続されます。 検証サーバーの1つがいずれかのIPに対して「Ping Failed」ステータスを返した場合、誤検知を排除するために、他の2つのゾーンで追加のチェックが実行されます。 将来的には、これらすべてをフロントエンドに導入して、IPが使用できない場所を確認できるようにする予定です(たとえば、DDoSまたはルーティングの問題がある場合)。
前に書いたように、Galera MariaDBクラスターとその前のHaproxyのマスターマスタレプリケーションを使用します。 Haproxyはアーキテクチャのすべての領域にインストールされているため、ユーザーに損害を与えることなく製品の新しいバージョンを展開したり、サービスを損なうことなくバックエンドシステムを更新したりできます。 将来的には、パーティション分割の使用を開始する予定です。
2.インフラ

データセンターからは、3つのかなり一般的なDCを選択しました。これにより、インフラストラクチャコストを管理し、サービスレベルを適切なレベルに保つことができます。
メインのフロントエンドシステムがあるフランスのサーバーには、Online.netを使用しています。 選択肢はOnline.netにありました。なぜなら、 サーバー間でIPアドレスをすばやく転送できる便利なサーバーコントロールパネルがあり、リモートiDRACコンソールが存在するだけでなく、トラフィック制限やDDoS攻撃に対する保護がありません。 Online.netでは、6月に約11 Tbのトラフィックを使用しましたが、これに対する過払いはありませんでした。これは便利です。
URL、Ping、およびポートをチェックする追加のサーバーは、OVH CanadaおよびRedstation UKにあり、必要な地理的範囲を提供します。 ただし、7月にはMicrosoft Azureプラットフォームへの移行が完了し、世界中の15のデータセンターにアクセスできるようになります。 これにより、サーバーとサイトをチェックする場所の数が増え、プラットフォーム全体のフォールトトレランスが向上します(これについては別途説明します)。
現時点では、1か月あたり約2億のチェックをすでに行っています。これには、すべてのサーバーのping(1352サーバーx 1分あたり2 ping x 60分x 24時間x 31日= 1か月あたり約1億2,000万の「pingジョブ」)が含まれますURLの確認、ポートの確認、サーバーでの統計の収集と処理など。
3.いくつかの統計:
現在、システムにエージェントがインストールされ、4分ごとに統計情報を送信する1352サーバーがシステムに追加されています。 さらに、追加された各サーバーを1分間に2回外部pingを使用してチェックします。
システムに追加されたサーバーは、2015年6月10日のピーク日に1秒あたり最大1.6テラビットのトラフィックを生成しました。 (Tb / s)。 これには、受信トラフィックと送信トラフィックの両方が含まれます。 アウトバウンドトラフィックはインバウンドよりわずかに大きくなりますが、かなり予測可能です。
2015年6月の日ごとのチャネルの使用。 ピーク日は6月10日です。
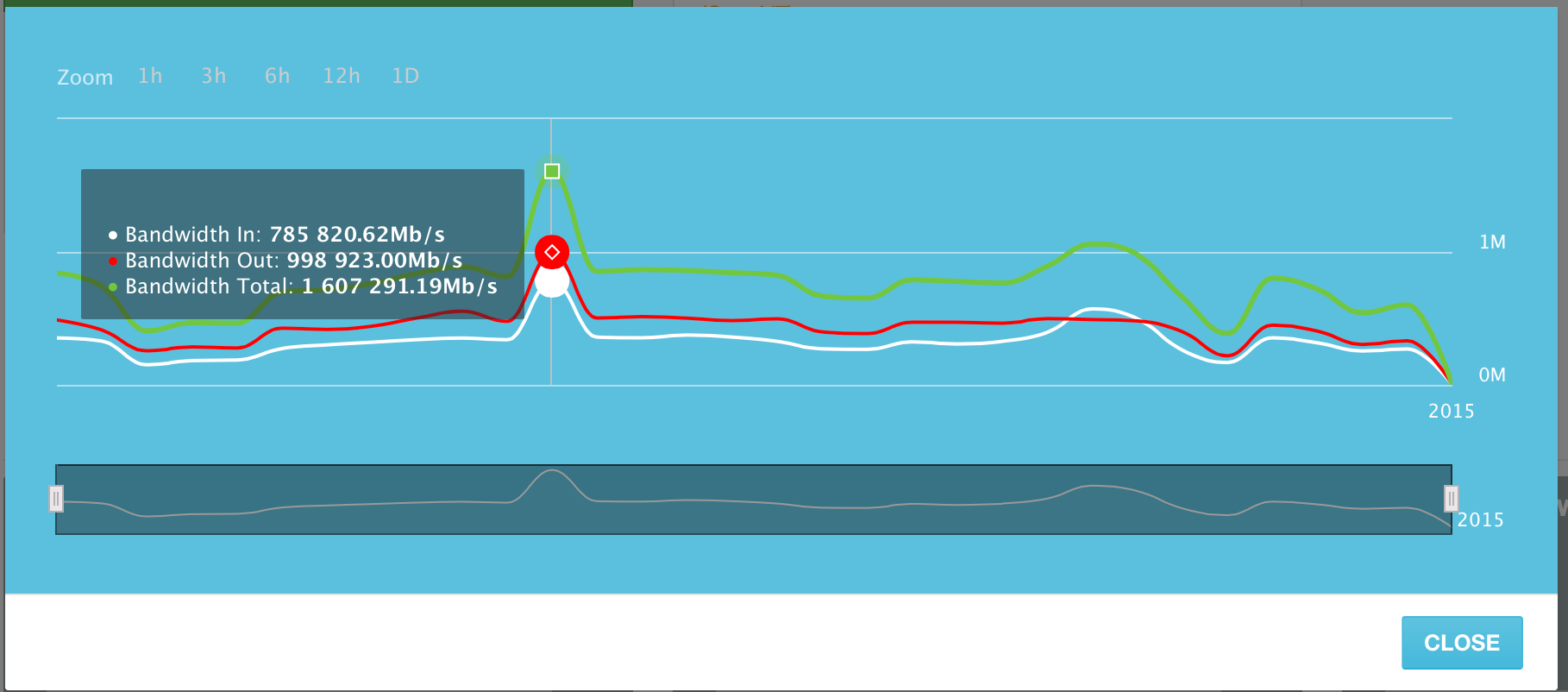
システム内のすべてのサーバーの平均チャネル使用率は、毎秒約500ギガビットです。
少し再計算すると、これらの「平均」1秒あたり500ギガビットのトラフィックにより、1日に約5,273テラバイトのデータが送信されます。 そして、これは私たちのシステムのたった1300台のサーバーによって送信されたデータの量です!
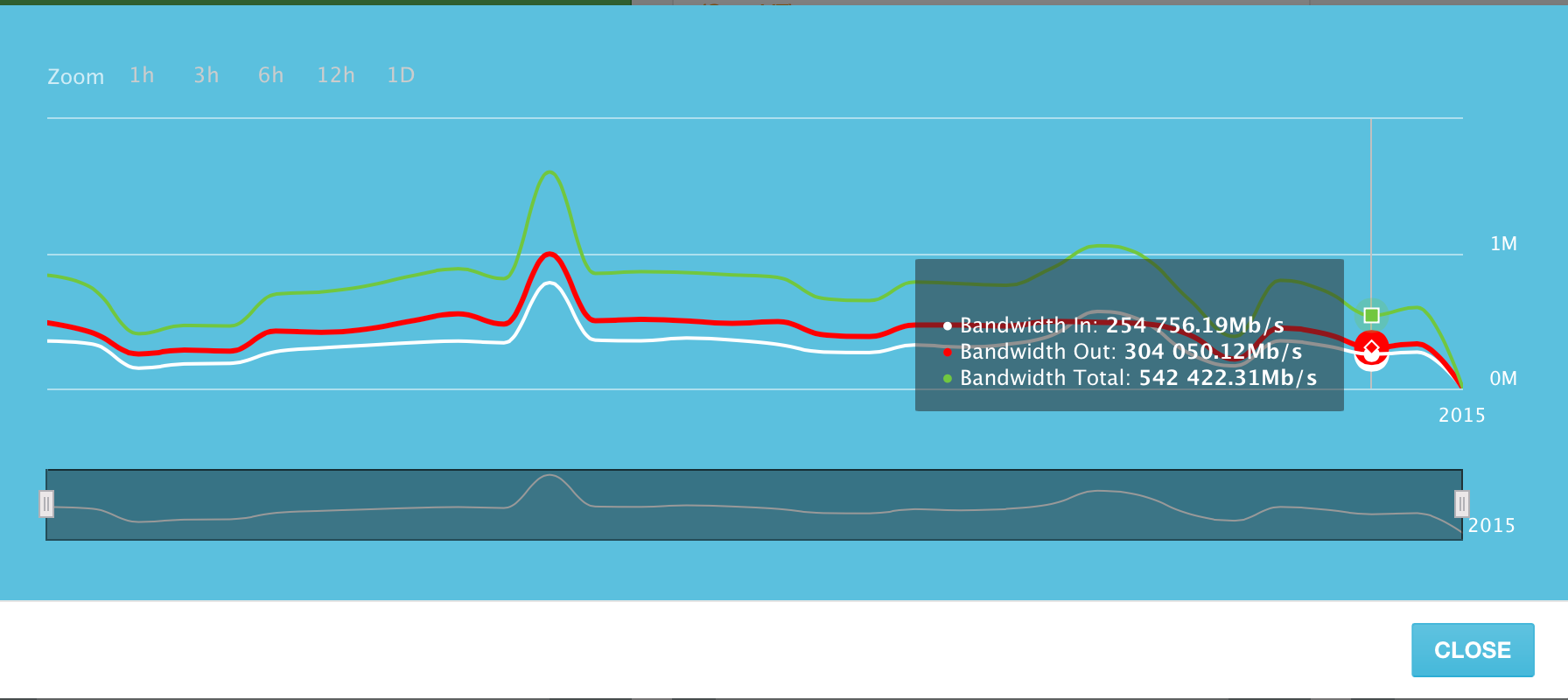
もちろん、私たちはまだ若い監視サービスですが、社内で使用して顧客に見せてアクセスできる便利でシンプルなプラットフォームを作成するために一生懸命取り組んでいます。
ただし、競合他社のモデルには従わず、「国内の新しい遺物」を作成しません。 それどころか、サーバーを監視するだけでなく、セキュリティ要素(サーバーとサイトの脆弱性をスキャンする)が存在するプラットフォームを作成したいと考えています。 1つのプラットフォームからサーバーを管理する機能、およびクラウドストレージへのデータ(バックアップ)のバックアップ。
お楽しみに!