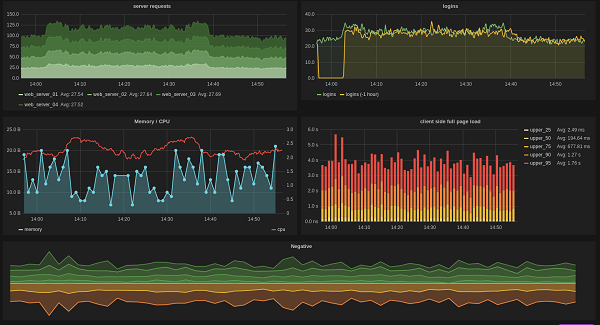
登場ストーリー
GitHub開発チームの主な目標の1つは常に高いパフォーマンスです。 「高速になるまで完全には出荷されない」という言葉さえあります(製品は、高速で動作する場合にのみ準備完了と見なされます)。 しかし、何かが高速または低速で動作していることをどのように理解するのでしょうか? 測定する必要があります。 正しく測定し、確実に測定し、常に測定します。 特にGitHubなどの負荷の高いオンラインシステムを扱う場合は、測定値を追跡し、あらゆる種類のメトリックを視覚化し、最新の状態に保つ必要があります。 したがって、メトリクスは、ほとんどダウンタイムなしで、チームがこのような高速で手頃な価格のサービスを提供できるようにするツールです。
かつて、GitHubはEtsyの開発者からstatsdと呼ばれるツールを実装した最初の1つでした。 statsdは、Node.jsで記述されたメトリックアグリゲーターです。 その本質は、あらゆる種類のメトリックを収集し、それらをサーバーに集約し、後で任意の形式で、たとえばグラフのデータ形式でGraphiteに保存することでした。 statsdはUDPソケットに基づいた優れたツールであり、メインのRailsアプリケーションで使用したり、 nc -uを呼び出すなどの単純なメトリックを収集したりするのに便利です。 statsdに送信されるサーバーとメトリックの数が増加するにつれて、この問題は後に発生し始めました。
そのため、たとえば、一部のメトリックは正しく表示されず、一部のメトリック、特に新しいメトリックはまったく収集されませんでした。 この理由は、UDPパケットのほぼ40%の損失でした。これは単に処理する時間がなく、破棄されました。 単一のUDPソケットを使用するシングルスレッドNode.jsの性質は、それ自体が感じられました。
しかし、スケーリングはそれほど簡単ではありませんでした。 パケットの収集と処理を複数のサーバーに分散させるには、IPではなくメトリック自体でシャードする必要がありました。そうしないと、各サーバーがすべてのメトリックに対して独自のデータセットを持つことになります。 また、メトリックによるシャーディングのタスクは簡単ではありません。それを解決するために、GitHubはUDPパケット用の独自のパーサーとメトリックの名前によるバランスを作成しました。
これにより状況が緩和され、statsdインスタンスの数を4つに増やすことができましたが、半分の尺度でした。
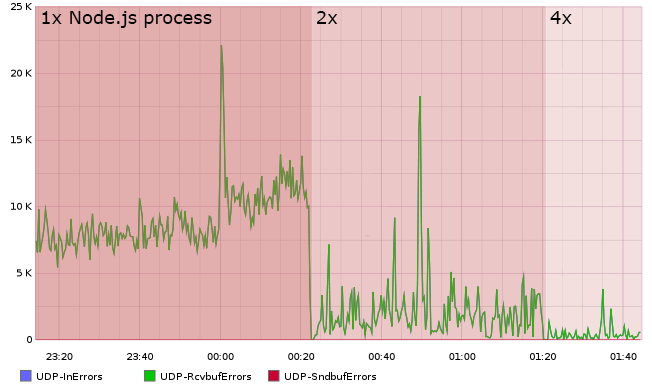
4つのstatsdサーバー、ほとんどメトリックを収集せず、UDPパケットを解析する自己記述型のロードバランサーにより、最終的に下位互換性を維持しながら、純粋なCですべてをより正確に書き直すことを余儀なくされました。 それで、ブルーベックが現れた。
ブルーベック
しかし、同じlibuvを使用してNode.jsアプリケーション(libuvに基づいてCで記述されたイベントループ)を純粋なCに書き換えることは疑わしい仕事です。 したがって、アプリケーションアーキテクチャ自体を修正することが決定されました。
最初に、彼らはソケットのイベントループを放棄しました。 実際、毎秒400万パケットが流入する場合、サイクル内で毎回スピンして、読み取る新しいデータがあるかどうかを尋ねるのは意味がありません。
イベントループは、アクセスへのシリアル化を備えた1つの共通ソケットを使用するワーカースレッドのプールに置き換えられました。 後で、Linux 3.9からのソケットのSO_REUSEPORTサポートを追加することにより、メカニズムがさらに改善され、アグリゲーター自体のソケットへのワーカーアクセスのシリアル化を拒否できるようになりました。 ( このトピックについては、 nginxがSO_REUSEPORTサポートをどのように実装したかに関する記事を読むのは興味深いでしょう )。
次に、同じメトリックで動作する複数のスレッドが存在するということは、データが分離されていることを意味します。 共有データへの安全なアクセスには、ロックなどのアクセス用の同期メカニズムが必要です。これは、データへのアクセスが競合し、必要に応じて高いパフォーマンスが得られる状況では適切ではありません。 ロックフリーアルゴリズム、特にメトリックが格納されるハッシュテーブルのロックフリー実装が救いになります。 (実際、ロックなしの読み取り専用、および書き込みの楽観的ロックがありますが、読み取り/書き込みの割合が高いアプリケーションでは、メトリック自体の追加や削除がデータ自体よりもはるかに少ないため、これは怖くありません)
第三に、1つのメトリック内のデータの集約はスピンロックを介して同期されました。これは、CPUリソースとコンテキストスイッチングの点で非常に安価なメカニズムであり、困難も生じませんでした。 同じメトリクス内でのデータの争いはほとんどありませんでした。
結果
アグリゲーターのシンプルなマルチスレッドアーキテクチャにより、良好な結果が得られました:過去2年間で、Brubeckを備えた唯一のサーバーは、ピーク負荷でもパケット損失なしで毎秒430万メトリックを処理するようになりました。 すべての情報とデータは、開発者のブログから確実に取得されます。
Brubeckがオープンソースにアップロードされました: github.com/github/brubeck
既に多くのstatsdがありますが、すべてではありません。 現在、開発は進行中であり、コミュニティはバグを見つけ、すぐに修正します。