
[ 前編 ]
この投稿では、最初の部分に収まらないものがあります。 これらは、
aggregation framework
にある演算子の一部であり、Webサイトのエコシステムセクションの3つの記事を
MongoDB
助けを借りてかなり自由に翻訳し、eコマースの使用事例を説明しています。
使用事例は8つの記事に分かれており、条件に応じて3つのグループに分けることができます。 翻訳に最も興味深いのは、
e-commerce
関連する3つの資料です。
集約フレームワークの演算子
原則として、
aggregation framework
には、
$project
や
$group
などの基本的な演算子があり、そこから
pipeline
チェーンが形成されます。
しかし、
$cond
ような演算子もあり、これらは常にメイン演算子の中にあります。
$ condは、次の 場合の通常の近似アナログです。
バージョン
2.6
から登場し、2つの記録形式があります。
{ $cond: { if: <boolean-expression>, then: <true-case>, else: <false-case-> } } { $cond: [ <boolean-expression>, <true-case>, <false-case> ] }
たとえば、次のドキュメントがあります。
{ "_id" : 1, "item" : "abc1", qty: 300 } { "_id" : 2, "item" : "abc2", qty: 200 } { "_id" : 3, "item" : "xyz1", qty: 250 }
qty
250
以上の場合、
discount
を
30
設定し
discount
。それ以外の場合、
discount
は
20
なります
db.test.aggregate( [ { $project:{ item: 1, discount: { $cond: { if: { $gte: [ "$qty", 250 ] }, then: 30, else: 20 } } } } ] )
得られた結果:
{ "_id" : 1, "item" : "abc1", "discount" : 30 } { "_id" : 2, "item" : "abc2", "discount" : 20 } { "_id" : 3, "item" : "xyz1", "discount" : 30 }
$ ifNull は、フィールドが存在し、nullでないことを確認します
フィールドがない場合は、目的の値に置き換えます。
{ "_id" : 1, "item" : "abc1", description: "product 1", qty: 300 } { "_id" : 2, "item" : "abc2", description: null, qty: 200 } { "_id" : 3, "item" : "xyz1", qty: 250 }
description
フィールドが存在しないか
null
場合、
Unspecified
返し
null
。
db.test.aggregate( [ { $project: { item: 1, description: { $ifNull: [ "$description", "Unspecified" ]}} } ] )
結果:
{ "_id" : 1, "item" : "abc1", "description" : "product 1" } { "_id" : 2, "item" : "abc2", "description" : "Unspecified" } { "_id" : 3, "item" : "xyz1", "description" : "Unspecified" }
$ let 変数を作成します
$let
演算子は変数を作成し、それらを使用していくつかの操作を実行できます。
この例では、2つの変数、
total
を作成し、2つのフィールド
price, tax
合計の値
total
割り当てます。 論理演算子
cond
を返す変数
discounted
結果。
その後、変数
total
と
discounted
を掛けて、それらの製品を返します。
{ _id: 1, price: 10, tax: 0.50, applyDiscount: true } { _id: 2, price: 10, tax: 0.25, applyDiscount: false } db.test.aggregate( [ { $project: { finalTotal: { $let: { vars: { total: { $add: [ '$price', '$tax' ] }, discounted: { $cond: { if: '$applyDiscount', then: 0.9, else: 1 } } }, in: { $multiply: [ "$$total", "$$discounted" ] } } } } }] ) { "_id" : 1, "finalTotal" : 9.450000000000001 } { "_id" : 2, "finalTotal" : 10.25 }
$ map は各要素に特定の式を適用します
式を各要素に適用します。この例では、配列の各要素に
+2
追加されます。
{ _id: 1, quizzes: [ 5, 6, 7 ] } { _id: 2, quizzes: [ ] } db.grades.aggregate([{ $project:{ adjustedGrades: {$map: {input: "$quizzes", as: "grade", in: { $add: [ "$$grade", 2 ] } } } } }]) { "_id" : 1, "adjustedGrades" : [ 7, 8, 9 ] } { "_id" : 2, "adjustedGrades" : [ ] }
$ setEqualsは 配列を比較します
2つ以上の配列を比較し、類似した要素が
true
場合は
true
を返し
true
。
| 例 | 結果 |
| {$ setEquals:[["a"、 "b"、 "a"]、["b"、 "a"]]} | 本当 |
| {$ setEquals:[["a"、 "b"]、[["a"、 "b"]]]} | 偽 |
$ setIntersection は一致する要素を返します
2つ以上の配列を受け取り、各入力配列に存在する要素を含む配列を返します。 配列の1つが空であるか、ネストされた配列を含む場合、空の配列を返します。
| 例 | 結果 |
| {$ setIntersection:[["a"、 "b"、 "a"]、["b"、 "a"]]} | ["B"、 "a"] |
| {$ setIntersection:[["a"、 "b"]、[["a"、 "b"]]]} | [] |
$ setUnion は、任意の入力パラメーターに存在する要素を返します。
2つ以上の配列を取り、任意の入力配列に現れる要素を含む配列を返します。
| 例 | 結果 |
| {$ setUnion:[["a"、 "b"、 "a"]、["b"、 "a"]]} | ["B"、 "a"] |
| {$ setUnion:[["a"、 "b"]、[["a"、 "b"]]]} | [["A"、 "b"]、 "b"、 "a"] |
$ setDifference もsetUnionですが、その逆も同様です
| 例 | 結果 |
| {$ setDifference:[["a"、 "b"、 "a"]、["b"、 "a"]]} | [] |
| {$ setDifference:[["a"、 "b"]、[["a"、 "b"]]]} | [「A」、「b」] |
$ setIsSubset はサブセットをチェックします
2つの配列を取り、最初の配列が2番目の配列のサブセットである場合(最初の配列が2番目の配列と等しい場合を含む)、Trueを返します。
| 例 | 結果 |
| {$ setIsSubset:[["a"、 "b"、 "a"]、["b"、 "a"]]} | 本当 |
| {$ setIsSubset:[["a"、 "b"]、[["a"、 "b"]]]} | 偽 |
$ anyElementTrue
配列を要素のセットとして評価し、いずれかの要素がTrueの場合Trueを返し、その逆の場合はFalseを返します。 空の配列はfalseを返します。 1つの引数を取ります。
| 例 | 結果 |
| {$ anyElementTrue:[[true、false]]} | |
| {$ anyElementTrue:[[[false]]]} | |
| {$ anyElementTrue:[[null、false、0]]} | |
| {$ anyElementTrue:[[]]} |
$ allElementsTrue
配列をチェックし、配列の1つの要素がfalseでない場合はTrueを返します。 それ以外の場合は、falseを返します。 空の配列はTrueを返します。
| 例 | 結果 |
| {$ allElementsTrue:[[true、1、 "someString"]]} | |
| {$ allElementsTrue:[[[false]]]} | |
| {$ allElementsTrue:[[]]} | |
| {$ allElementsTrue:[[null、false、0]]} |
$ cmp -2つの要素を比較します
2つの要素を比較して返します。
- 最初の値が2番目の値より小さい場合は-1。
- 最初の値が2番目の値より大きい場合は1。
- 両方の値が等しい場合は0。
{ "_id" : 1, "item" : "abc1", description: "product 1", qty: 300 } { "_id" : 2, "item" : "abc2", description: "product 2", qty: 200 } { "_id" : 3, "item" : "xyz1", description: "product 3", qty: 250 }
$cmp
を使用して、
qty
フィールドの値を
250
と比較します。
db.test.aggregate( [ { $project:{ _id: 0, item: 1,qty: 1, cmpTo250: { $cmp: [ "$qty", 250 ] } } } ] )
結果:
{ "item" : "abc1", "qty" : 300, "cmpTo250" : 1 } { "item" : "abc2", "qty" : 200, "cmpTo250" : -1 } { "item" : "xyz1", "qty" : 250, "cmpTo250" : 0 }
$ add add
{ "_id" : 1, "item" : "abc", "price" : 10, "fee" : 2 } { "_id" : 2, "item" : "jkl", "price" : 20, "fee" : 1 } db.test.aggregate([ { $project: { item: 1, total: { $add: [ "$price", "$fee" ] } } } ]) { "_id" : 1, "item" : "abc", "total" : 12 } { "_id" : 2, "item" : "jkl", "total" : 21 }
$減算 減算
日付の差をミリ秒単位で返す場合があります。
{ "_id" : 1, "item" : "abc", "price" : 10, "fee" : 2, "discount" : 5 } { "_id" : 2, "item" : "jkl", "price" : 20, "fee" : 1, "discount" : 2 } db.test.aggregate( [ { $project: { item: 1, total: { $subtract: [ { $add: [ "$price", "$fee" ] }, "$discount" ] } } } ] ) { "_id" : 1, "item" : "abc", "total" : 7 } { "_id" : 2, "item" : "jkl", "total" : 19 }
$乗算 乗算
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity": 2 } { "_id" : 2, "item" : "jkl", "price" : 20, "quantity": 1 } db.test.aggregate([ { $project: { item: 1, total: { $multiply: [ "$price", "$quantity" ] } } } ]) { "_id" : 1, "item" : "abc", "total" : 20 } { "_id" : 2, "item" : "jkl", "total" : 20 }
$除算 演算子
{ "_id" : 1, "name" : "A", "hours" : 80, "resources" : 7 }, { "_id" : 2, "name" : "B", "hours" : 40, "resources" : 4 } db.test.aggregate([ { $project: { name: 1, workdays: { $divide: [ "$hours", 8 ] } } } ]) { "_id" : 1, "name" : "A", "workdays" : 10 } { "_id" : 2, "name" : "B", "workdays" : 5 }
$ concat- ストリング連結
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" } db.test.aggregate([ { $project: { itemDescription: { $concat: [ "$item", " - ", "$description" ] } } } ]) { "_id" : 1, "itemDescription" : "ABC1 - product 1" }
$ substr は部分文字列を返します
開始インデックスと先頭からの文字数を取得します。 インデックスはゼロから始まります。
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" } { "_id" : 2, "item" : "ABC2", quarter: "13Q4", "description" : "product 2" } db.inventory.aggregate([{ $project:{ item: 1, yearSubstring: { $substr: [ "$quarter", 0, 2 ] }, quarterSubtring: { $substr: [ "$quarter", 2, -1 ] } } }]) { "_id" : 1, "item" : "ABC1", "yearSubstring" : "13", "quarterSubtring" : "Q1" } { "_id" : 2, "item" : "ABC2", "yearSubstring" : "13", "quarterSubtring" : "Q4" }
$ toLower- 小文字に変換します
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "PRODUCT 1" } db.test.aggregate([{ $project:{ item: { $toLower: "$item" }, description: { $toLower: "$description" }} }]) { "_id" : 1, "item" : "abc1", "description" : "product 1" }
$ toUpper は大文字に変換します
{ "_id" : 2, "item" : "abc2", quarter: "13Q4", "description" : "Product 2" } db.inventory.aggregate( [ { $project:{ item: { $toUpper: "$item" }, description: { $toUpper: "$description" } } } ] ) { "_id" : 2, "item" : "ABC2", "description" : "PRODUCT 2" }
$ strcasecmpは 文字列を比較します
2つの文字列を比較して返します。
- 1行目が2行目よりも「大きい」場合は1。
- 2行が等しい場合は0。
- 最初の行が2番目の行よりも「小さい」場合は-1。
演算子は大文字と小文字を区別しません。
{ "_id" : 1, "item" : "ABC1", quarter: "13Q1", "description" : "product 1" } { "_id" : 2, "item" : "ABC2", quarter: "13Q4", "description" : "product 2" } { "_id" : 3, "item" : "XYZ1", quarter: "14Q2", "description" : null } db.inventory.aggregate([{ $project:{ item: 1, comparisonResult: { $strcasecmp: [ "$quarter", "13q4" ] } } }]) { "_id" : 1, "item" : "ABC1", "comparisonResult" : -1 } { "_id" : 2, "item" : "ABC2", "comparisonResult" : 0 } { "_id" : 3, "item" : "XYZ1", "comparisonResult" : 1 }
日付を操作する
アカウントの $ dayOfYear 日
請求書の月の $ dayOfMonth 日
$ dayOfWeek は、アカウントの曜日(1(土曜日)-7(日曜日))を返します。
$年 は 年を 返します
$ month は、アカウントの月を返します
$ week は、年の 週 番号を 0〜53の 数値として返します
$ hour は、0〜23の数値として 時間を 返します
$ minutes は、0〜59の数値として 分を 返します
$ second は、0〜23の数値として秒を返します
$ millisecond は、0〜999の数値として ミリ秒を 返します
日付の年間通算日を1〜366の数値として返します。
たとえば、1月1日に1を返します。
{ "_id": 1, "item": "abc", "date" : ISODate("2014-01-01T08:15:39.736Z") } db.sales.aggregate( [ { $project: { year: { $year: "$date" }, month: { $month: "$date" }, day: { $dayOfMonth: "$date" }, hour: { $hour: "$date" }, minutes: { $minute: "$date" }, seconds: { $second: "$date" }, milliseconds: { $millisecond: "$date" }, dayOfYear: { $dayOfYear: "$date" }, dayOfWeek: { $dayOfWeek: "$date" }, week: { $week: "$date" } } } ] ) { "_id" : 1, "year" : 2014, "month" : 1, "day" : 1, "hour" : 8, "minutes" : 15, "seconds" : 39, "milliseconds" : 736, "dayOfYear" : 1, "dayOfWeek" : 4, "week" : 0 }
$ dateToString は文字列に変換します
指定された形式に従って、日付オブジェクトを文字列に変換します。
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2014-01-01T08:15:39.736Z") } db.test.aggregate( [ { $project: { yearMonthDay: { $dateToString: { format: "%Y-%m-%d", date: "$date" } }, time: { $dateToString: { format: "%H:%M:%S:%L", date: "$date" } } } } ] ) { "_id" : 1, "yearMonthDay" : "2014-01-01", "time" : "08:15:39:736" }
製品カタログ
この章では、
MongoDB
を使用して電子商取引システムで製品カタログを設計する基本的な原則について説明します。
商品のカタログには、さまざまなタイプのオブジェクトを格納でき、各オブジェクトには独自の特性リストが必要です。
リレーショナルデータベースの場合、パフォーマンスの違いなど、同様の問題に対するいくつかの解決策があります。 これらのオプションのいくつかを見てから、これが
MongoDB
どのように処理されるかを確認します。
SQLおよびリレーショナルデータモデル
具体的なテーブルの継承(有限クラスのテーブルによる継承)
リレーショナルモデルの最初のオプションは、商品のカテゴリごとに独自のテーブルを作成することです。
CREATE TABLE `product_audio_album` ( `sku` char(8) NOT NULL, ... `artist` varchar(255) DEFAULT NULL, `genre_0` varchar(255) DEFAULT NULL, `genre_1` varchar(255) DEFAULT NULL, ..., PRIMARY KEY(`sku`)) ... CREATE TABLE `product_film` ( `sku` char(8) NOT NULL, ... `title` varchar(255) DEFAULT NULL, `rating` char(8) DEFAULT NULL, ..., PRIMARY KEY(`sku`)) ...
このアプローチには、柔軟性に関連する2つの主な制限があります。
- 実際には、新しい製品カテゴリごとに新しいテーブルが作成されます。
- 特定のタイプの製品に対するクエリの明示的な適応。
単一テーブルの継承
リレーショナルモデルの2番目のオプションは、すべての製品カテゴリに単一のテーブルを使用することです。 また、商品の種類に関するデータを保存する必要がある場合はいつでも新しい列を追加します。
CREATE TABLE `product` ( `sku` char(8) NOT NULL, ... `artist` varchar(255) DEFAULT NULL, `genre_0` varchar(255) DEFAULT NULL, `genre_1` varchar(255) DEFAULT NULL, ... `title` varchar(255) DEFAULT NULL, `rating` char(8) DEFAULT NULL, ..., PRIMARY KEY(`sku`))
このアプローチはより柔軟性があり、さまざまなタイプの製品に基づいて単一のクエリを作成できます。
複数のテーブルの継承
また、リレーショナルモデルでは、「複数のテーブルの継承」を使用できます。これは、製品のすべてのカテゴリに共通の属性がメイン
product
テーブルにあり、個別の属性(それぞれ独自のカテゴリ)に異なる属性が含まれるパターンです。
次の
SQL
例を検討してください。
CREATE TABLE `product` ( `sku` char(8) NOT NULL, `title` varchar(255) DEFAULT NULL, `description` varchar(255) DEFAULT NULL, `price`, ... PRIMARY KEY(`sku`)) CREATE TABLE `product_audio_album` ( `sku` char(8) NOT NULL, ... `artist` varchar(255) DEFAULT NULL, `genre_0` varchar(255) DEFAULT NULL, `genre_1` varchar(255) DEFAULT NULL, ..., PRIMARY KEY(`sku`), FOREIGN KEY(`sku`) REFERENCES `product`(`sku`)) ... CREATE TABLE `product_film` ( `sku` char(8) NOT NULL, ... `title` varchar(255) DEFAULT NULL, `rating` char(8) DEFAULT NULL, ..., PRIMARY KEY(`sku`), FOREIGN KEY(`sku`) REFERENCES `product`(`sku`)) ...
このオプションは、単一のテーブル継承よりも効率的で、各カテゴリのテーブルを作成するよりもわずかに柔軟性があります。 このオプションでは、特定の製品に関連するすべての属性を取得するために「高価な」
JOIN
を使用する必要があります。
各エンティティの属性値
そして、リレーショナルモデルの最後のパターンは、
entity-attribute-value
スキーマです。 このスキームに従って、たとえば
entity_id
、
attribute_id
、および各製品の説明に使用される
value
3つの列を持つテーブルが作成されます。
オーディオ録音を保存する例を考えてみましょう。
| エンティティ | 属性 | 価値 |
| sku_00e8da9b | タイプ | オーディオアルバム |
| sku_00e8da9b | タイトル | 最高の愛 |
| sku_00e8da9b | ... | ... |
| sku_00e8da9b | アーティスト | ジョン・コルトレーン |
| sku_00e8da9b | ジャンル | ジャズ |
| sku_00e8da9b | ジャンル | 全般 |
| ... | ... | ... |
このスキームは非常に柔軟です:
どの製品にも、任意の属性セットを設定できます。 新しい製品カテゴリでは、データベースを変更する必要はありません。
このオプションの短所は、
JOIN
を含む多くのクエリが必要になることであり、これはパフォーマンスにあまり適していません。
さらに、リレーショナルデータベースシステムを使用する一部の
e-commerce
ソリューションでは、このデータをBLOB列にシリアル化します。 そして、商品の属性を見つけて分類することが難しくなります。
非リレーショナルデータモデル
mongodb
リレーショナルデータベースで
mongodb
ないため、製品カタログを作成する柔軟性の観点から追加の機会があります。
最善のオプションは、1つのコレクションを使用してすべての種類のドキュメントを保存することです。 また、ドキュメントごとに任意のスキームを使用できるため、製品のすべての特性(属性)を1つのドキュメントに保存できます。
文書のルートには、カタログ全体の検索を容易にするための製品に関する一般的な情報が必要です。 そして、すでにサブドキュメントには、各ドキュメントに固有のフィールドがあるはずです。 例を考えてみましょう:
{ sku: "00e8da9b", type: "Audio Album", title: "A Love Supreme", description: "by John Coltrane", asin: "B0000A118M", shipping: { weight: 6, dimensions: { width: 10, height: 10, depth: 1 }, }, pricing: { list: 1200, retail: 1100, savings: 100, pct_savings: 8 }, details: { title: "A Love Supreme [Original Recording Reissued]", artist: "John Coltrane", genre: [ "Jazz", "General" ], ... tracks: [ "A Love Supreme Part I: Acknowledgement", "A Love Supreme Part II - Resolution", "A Love Supreme, Part III: Pursuance", "A Love Supreme, Part IV-Psalm" ], }, }
映画に関する情報が保存されているドキュメントの場合
{ type: "Film" }
主なフィールドは、価格、配達などです。 同じままです。 ただし、サブ文書の内容は異なります。 例:
{ sku: "00e8da9d", type: "Film", ..., asin: "B000P0J0AQ", shipping: { ... }, pricing: { ... }, details: { title: "The Matrix", director: [ "Andy Wachowski", "Larry Wachowski" ], writer: [ "Andy Wachowski", "Larry Wachowski" ], ..., aspect_ratio: "1.66:1" }, }
ほとんどの場合、製品カタログの主な操作は検索です。 以下に便利なさまざまなタイプのクエリを示します。 すべての例は
Python/PyMongo
ます。
ジャンル別にアルバムを検索し、リリース年で並べ替えます
このクエリは、特定のジャンルに対応し、新しい順に並べ替えられた商品を含むドキュメントを返します。
query = db.products.find({'type':'Audio Album', 'details.genre': 'jazz'}).sort([('details.issue_date', -1)])
このクエリでは、クエリおよび並べ替えで使用されるフィールドにインデックスが必要です。
db.products.ensure_index([ ('type', 1), ('details.genre', 1), ('details.issue_date', -1)])
割引率で降順で並べ替えられた製品を検索します。
ほとんどのリクエストは特定のタイプの製品(アルバム、映画など)に対するものですが、多くの場合、特定の価格帯ですべての商品を返品する必要があります。
すべてのドキュメントにある価格フィールドを使用して検索するために、割引が有効な製品を検索します。
query = db.products.find( { 'pricing.pct_savings': {'$gt': 25 }).sort([('pricing.pct_savings', -1)])
このクエリでは、
pricing.pct_savings
フィールドにインデックスを作成します。
db.products.ensure_index('pricing.pct_savings')
MongoDB
は、インデックスを昇順または降順で読み取ることができます。
有名な俳優が演じたすべての映画を見つける
ドキュメントタイプが
"Film"
で、ドキュメント属性の値が
{ 'actor': 'Keanu Reeves' }
ドキュメントを見つけます。 結果を日付で降順に並べ替えます。
query = db.products.find({'type': 'Film', 'details.actor': 'Keanu Reeves'}).sort([('details.issue_date', -1)])
このクエリでは、次のインデックスを作成します。
db.products.ensure_index([ ('type', 1), ('details.actor', 1), ('details.issue_date', -1)])
インデックスはすべてのドキュメントにある
type
フィールドで始まり、
details.actor
フィールドに沿って進むため、検索領域を絞り込みます。 したがって、インデックスは最も効果的です。
タイトルに特定の単語を含むすべての映画を見つける
データベースの種類に関係なく、単語による検索クエリを実行するには、データベースが結果を取得するためにドキュメントの一部をスキャンする必要があります。
Mongodb
は、クエリで正規表現をサポートしています。 Pythonでは、
re
モジュールを使用して正規表現を作成できます。
import re re_hacker = re.compile(r'.*hacker.*', re.IGNORECASE) query = db.products.find({'type': 'Film', 'title': re_hacker}).sort([('details.issue_date', -1)])
Mongodbは正規表現用の特別な構文を提供するため、クエリでは
re
モジュールなしで実行できます。 前の例に代わる次の例を検討してください。
query = db.products.find({ 'type': 'Film', 'title': {'$regex': '.*hacker.*', '$options':'i'}}).sort([('details.issue_date', -1)])
$options
特別な演算子です。この場合、検索語で大文字と小文字が区別されないことを示します。
インデックスを作成します。
db.products.ensure_index([ ('type', 1), ('details.issue_date', -1), ('title', 1) ])
このインデックスを使用すると、ドキュメント全体のスキャンを回避できます。インデックスのおかげで、
title
フィールドのみがスキャンされます。
シャーディング
スケーリングのデータベースパフォーマンスはインデックスに依存します。 シャーディングを使用してパフォーマンスを向上させると、大きなインデックスがRAMに収まります。
シャード設定で、
shard key
選択し
shard key
。これにより、
mongos
要求をシャードまたはシャードの小さなグループに直接ルーティングできます。
type
フィールドはほとんどのリクエストに存在するため、
shard key
含めることができ
shard key
。
shard key
残りについては、以下を考慮してください:
-
details.issue_date
shard key
は含まれません。このフィールドはリクエストには存在せず、ソートにのみ存在するためです。 -
detail
含まれ、頻繁に要求される1つ以上のフィールドを含める必要があります。
次の例では、
details.genre
フィールドが
type
次いで2番目に重要なフィールドで
type
ます。
Python/PyMongo
シャーディングを初期化する
>>> db.command('shardCollection', 'product', { key : { 'type': 1, 'details.genre' : 1, 'sku':1 } } ) { "collectionsharded" : "details.genre", "ok" : 1 }
失敗した
shard key
を作成したとしても、シャーディングに役立ちます:
- シャーディングは、インデックスの保存に使用できる大量のRAMを提供します。
-
MongoDB
は、シャード間でクエリを並列化し、遅延を削減します。
読書
シャーディングはスケーリングに適した方法ですが、一部のデータセットは、
mongos
クエリを目的のシャードに誘導するような方法で分割することはできません。
この場合、
mongos
はすべてのシャードにすぐにリクエストを送信し、その結果、すでにクライアントに返されます。
どのシャードを読むことが望ましいかを明確に示しているため、生産性をわずかに高めることができます。
次の例の
SECONDARY
プロパティを使用すると、接続全体のセカンダリノード(およびプライマリノード)からの読み取りが可能になります。
conn = pymongo.MongoClient(read_preference=pymongo.SECONDARY)
SECONDARY_ONLY
は、クライアントがセカンダリメンバからのみ読み取ることを意味します。
conn = pymongo.MongoClient(read_preference=pymongo.SECONDARY_ONLY)
特定のリクエストに
read_preference
を指定することもできます。たとえば、次のとおりです。
results = db.product.find(..., read_preference=pymongo.SECONDARY)
または
results = db.product.find(..., read_preference=pymongo.SECONDARY_ONLY)
カートおよび在庫管理
オンラインストアのユーザーは定期的に「バスケット」にアイテムを追加および削除するため、倉庫内の商品の量は購入中に何度も絶えず変化する可能性があります。さらに、ストアユーザーはいつでも購入を拒否し、他の予期しない問題が発生することがあります解決するには、注文をキャンセルする必要があります。
これらすべてにより、倉庫で入手可能な商品を追跡するのが少し難しくなる可能性があり、ユーザーが既に予約されている商品を「購入」できないようにする必要があります。
したがって、バスケットには時間があります。その間、バスケットが非アクティブだった場合、予約された商品は他の全員が再び利用できるようになり、バスケットは空になります。
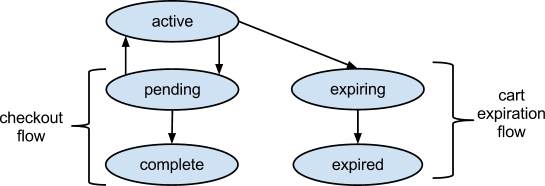
各倉庫在庫単位( SKU ;またはアイテム)の現在の在庫量を含むドキュメント、およびそれぞれの商品の数量を含むバスケットのリストは、
Inventory
コレクションに保存する必要があります。 その後、利用可能な残高がバスケットに入っていれば返却できますが、クライアントはしばらくバスケットを使用しませんでした。
次の例では、 SKUを格納する
_id
フィールド
# _id:SKU, , 16 , 1 . # id 42, 2 . c id 43. 19 . { _id: '00e8da9b', qty: 16, carted: [ { qty: 1, cart_id: 42, timestamp: ISODate("2012-03-09T20:55:36Z") }, { qty: 2, cart_id: 43, timestamp: ISODate("2012-03-09T21:55:36Z") }, ] }
この例では、シンプルなスキームが使用されています。生産では、このスキームを第2章で説明した商品のカタログと組み合わせることができます。
バスケットの通常のモデリングには、SKU、
quantity
フィールド、および
item_details
# item_details # , . { _id: 42, last_modified: ISODate("2012-03-09T20:55:36Z"), status: 'active', items: [ { sku: '00e8da9b', qty: 1, item_details: {...} }, { sku: '0ab42f88', qty: 4, item_details: {...} } ] }
運営
バスケットへのアイテムの追加バスケットを
使用する際の主なポイントは、倉庫内の既存の在庫からバスケットへの商品の移動です。
既に予約した商品をバスケットに入れないことが重要です。関数を使用してこれを実装しますadd_item_to_cart
。
def add_item_to_cart(cart_id, sku, qty, details): now = datetime.utcnow() # , result = db.cart.update( {'_id': cart_id, 'status': 'active' }, {'$set': {'last_modified':now}, '$push': {'items': {'sku':sku, 'qty':qty, 'details':details}}}, w=1 ) if not result['updatedExisting']: raise CartInactive() # result = db.inventory.update( {'_id':sku, 'qty': {'$gte': qty}}, {'$inc': {'qty':-qty}, '$push': {'carted': {'qty':qty, 'cart_id':cart_id, 'timestamp':now}}}, w=1 ) if not result['updatedExisting']: # , , . db.cart.update( {'_id': cart_id }, { '$pull': { 'items': {'sku': sku } } }) raise InadequateInventory()
, _id
.
— , . , .
, .
, , .
def update_quantity(cart_id, sku, old_qty, new_qty): # _id . now = datetime.utcnow() delta_qty = new_qty - old_qty # , . result = db.cart.update( {'_id': cart_id, 'status': 'active', 'items.sku': sku }, {'$set': { 'last_modified': now, 'items.$.qty': new_qty } }, w=1 ) if not result['updatedExisting']: raise CartInactive() # result = db.inventory.update( {'_id':sku, 'carted.cart_id': cart_id, 'qty': {'$gte': delta_qty} }, {'$inc': {'qty': -delta_qty },'$set': { 'carted.$.qty': new_qty, 'timestamp': now } }, w=1 ) if not result['updatedExisting']: # db.cart.update( {'_id': cart_id, 'items.sku': sku }, {'$set': { 'items.$.qty': old_qty } } ) raise InadequateInventory()
, , .
def checkout(cart_id): now = datetime.utcnow() # <code>active</code> <code>pending</code>. # cart = db.cart.find_and_modify( {'_id': cart_id, 'status': 'active' }, update={'$set': { 'status': 'pending','last_modified': now } } ) if cart is None: raise CartInactive() # ; payment try: collect_payment(cart) db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'complete' } } ) db.inventory.update( {'carted.cart_id': cart_id}, {'$pull': {'cart_id': cart_id} }, multi=True) except: db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'active' } } ) raise
, pending
. , .
- ,
cart_id
inventory
. complete
. - , , .
.
.
timeout
.
def expire_carts(timeout): now = datetime.utcnow() threshold = now - timedelta(seconds=timeout) # db.cart.update( {'status': 'active', 'last_modified': { '$lt': threshold } }, {'$set': { 'status': 'expiring' } }, multi=True ) # for cart in db.cart.find({'status': 'expiring'}): # for item in cart['items']: db.inventory.update( { '_id': item['sku'], 'carted.cart_id': cart['id'], 'carted.qty': item['qty'] }, {'$inc': { 'qty': item['qty'] }, '$pull': { 'carted': { 'cart_id': cart['id'] } } } ) db.cart.update( {'_id': cart['id'] }, {'$set': { 'status': 'expired' })
:
- , .
- , .
- ,
expired
.
status
last_modified
.
db.cart.ensure_index([('status', 1), ('last_modified', 1)])
.
: , inventory
, , , .
, inventory
carted
.
def cleanup_inventory(timeout): now = datetime.utcnow() threshold = now - timedelta(seconds=timeout) # for item in db.inventory.find( {'carted.timestamp': {'$lt': threshold }}): carted = dict( (carted_item['cart_id'], carted_item) for carted_item in item['carted'] if carted_item['timestamp'] < threshold ) # : carted, inventory for cart in db.cart.find( { '_id': {'$in': carted.keys() }, 'status':'active'}): cart = carted[cart['_id']] db.inventory.update( {'_id': item['_id'], 'carted.cart_id':cart['_id'] }, { '$set': {'carted.$.timestamp':now }} ) del carted[cart['_id']] # : carted . for cart_id, carted_item in carted.items(): db.inventory.update( { '_id': item['_id'], 'carted.cart_id': cart_id, 'carted.qty': carted_item['qty'] }, { '$inc': { 'qty': carted_item['qty'] }, '$pull': { 'carted': { 'cart_id': cart_id } } } )
«carted» , , timeout
. :
-
timeout
, - , . - , , .
, shard key
_id
, _id
.
mongos
_id
mongod
.
_id
shard key
.
_id
cart
, .
, , ( MD5 SHA-1) ObjectID, _id.
:
import hashlib import bson cart_id = bson.ObjectId() cart_id_hash = hashlib.md5(str(cart_id)).hexdigest() cart = { "_id": cart_id, "cart_hash": cart_id_hash } db.cart.insert(cart)
, , _id
shard key
.
, , ( Sleep ()
), .
Python/PyMongo :
>>> db.command('shardCollection', 'inventory', 'key': { '_id': 1 } ) { "collectionsharded" : "inventory", "ok" : 1 } >>> db.command('shardCollection', 'cart', 'key': { '_id': 1 } ) { "collectionsharded" : "cart", "ok" : 1 }
def add_item_to_cart(cart_id, sku, qty, details): now = datetime.utcnow() # , result = db.cart.update( {'_id': cart_id, 'status': 'active' }, {'$set': {'last_modified':now}, '$push': {'items': {'sku':sku, 'qty':qty, 'details':details}}}, w=1 ) if not result['updatedExisting']: raise CartInactive() # result = db.inventory.update( {'_id':sku, 'qty': {'$gte': qty}}, {'$inc': {'qty':-qty}, '$push': {'carted': {'qty':qty, 'cart_id':cart_id, 'timestamp':now}}}, w=1 ) if not result['updatedExisting']: # , , . db.cart.update( {'_id': cart_id }, { '$pull': { 'items': {'sku': sku } } }) raise InadequateInventory()
def update_quantity(cart_id, sku, old_qty, new_qty): # _id . now = datetime.utcnow() delta_qty = new_qty - old_qty # , . result = db.cart.update( {'_id': cart_id, 'status': 'active', 'items.sku': sku }, {'$set': { 'last_modified': now, 'items.$.qty': new_qty } }, w=1 ) if not result['updatedExisting']: raise CartInactive() # result = db.inventory.update( {'_id':sku, 'carted.cart_id': cart_id, 'qty': {'$gte': delta_qty} }, {'$inc': {'qty': -delta_qty },'$set': { 'carted.$.qty': new_qty, 'timestamp': now } }, w=1 ) if not result['updatedExisting']: # db.cart.update( {'_id': cart_id, 'items.sku': sku }, {'$set': { 'items.$.qty': old_qty } } ) raise InadequateInventory()
def checkout(cart_id): now = datetime.utcnow() # <code>active</code> <code>pending</code>. # cart = db.cart.find_and_modify( {'_id': cart_id, 'status': 'active' }, update={'$set': { 'status': 'pending','last_modified': now } } ) if cart is None: raise CartInactive() # ; payment try: collect_payment(cart) db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'complete' } } ) db.inventory.update( {'carted.cart_id': cart_id}, {'$pull': {'cart_id': cart_id} }, multi=True) except: db.cart.update( {'_id': cart_id }, {'$set': { 'status': 'active' } } ) raise
cart_id
inventory
.
complete
.
def expire_carts(timeout): now = datetime.utcnow() threshold = now - timedelta(seconds=timeout) # db.cart.update( {'status': 'active', 'last_modified': { '$lt': threshold } }, {'$set': { 'status': 'expiring' } }, multi=True ) # for cart in db.cart.find({'status': 'expiring'}): # for item in cart['items']: db.inventory.update( { '_id': item['sku'], 'carted.cart_id': cart['id'], 'carted.qty': item['qty'] }, {'$inc': { 'qty': item['qty'] }, '$pull': { 'carted': { 'cart_id': cart['id'] } } } ) db.cart.update( {'_id': cart['id'] }, {'$set': { 'status': 'expired' })
expired
.
db.cart.ensure_index([('status', 1), ('last_modified', 1)])
def cleanup_inventory(timeout): now = datetime.utcnow() threshold = now - timedelta(seconds=timeout) # for item in db.inventory.find( {'carted.timestamp': {'$lt': threshold }}): carted = dict( (carted_item['cart_id'], carted_item) for carted_item in item['carted'] if carted_item['timestamp'] < threshold ) # : carted, inventory for cart in db.cart.find( { '_id': {'$in': carted.keys() }, 'status':'active'}): cart = carted[cart['_id']] db.inventory.update( {'_id': item['_id'], 'carted.cart_id':cart['_id'] }, { '$set': {'carted.$.timestamp':now }} ) del carted[cart['_id']] # : carted . for cart_id, carted_item in carted.items(): db.inventory.update( { '_id': item['_id'], 'carted.cart_id': cart_id, 'carted.qty': carted_item['qty'] }, { '$inc': { 'qty': carted_item['qty'] }, '$pull': { 'carted': { 'cart_id': cart_id } } } )
timeout
, - , .
import hashlib import bson cart_id = bson.ObjectId() cart_id_hash = hashlib.md5(str(cart_id)).hexdigest() cart = { "_id": cart_id, "cart_hash": cart_id_hash } db.cart.insert(cart)
>>> db.command('shardCollection', 'inventory', 'key': { '_id': 1 } ) { "collectionsharded" : "inventory", "ok" : 1 } >>> db.command('shardCollection', 'cart', 'key': { '_id': 1 } ) { "collectionsharded" : "cart", "ok" : 1 }
カテゴリツリーを商品でモデル化します。各カテゴリは、祖先のリストまたは親のリストを持つドキュメントに保存されます。
たとえば、ジャンルのリストを使用します。

これらのカテゴリのタイプは頻繁に変更されないため、モデリングでは、更新操作のパフォーマンスではなく、階層の維持に必要な操作に焦点を当てます。
この回路には次の特性があります。
- ツリーの各カテゴリは、1つのドキュメントで表されます。
-
Objectid
内部相互参照の各カテゴリー文書を識別します。 - カテゴリを持つ各ドキュメントには、人間が読める名前と、通常のURLを持つフィールドがあります。
- スキーマは、1つのクエリのみを使用してすべての祖先の取得を容易にするために、各カテゴリの祖先のリストを保持します。
次のプロトタイプを検討してください。
{ "_id" : ObjectId("4f5ec858eb03303a11000002"), "name" : "Modal Jazz", "parent" : ObjectId("4f5ec858eb03303a11000001"), "slug" : "modal-jazz", "ancestors" : [ { "_id" : ObjectId("4f5ec858eb03303a11000001"), "slug" : "bop", "name" : "Bop" }, { "_id" : ObjectId("4f5ec858eb03303a11000000"), "slug" : "ragtime", "name" : "Ragtime" } ] }
このセクションでは、Eコマースソリューションで必要になる可能性のあるカテゴリツリー操作操作について説明します。すべての例では、
Python/PyMongo
Reading and Displaying
Request カテゴリを使用します。
次のオプションを使用して、カテゴリツリーを読み取って表示します。このリクエストでは、フィールドを使用して
slug
、カテゴリに関する情報を返します
“bread crumb”
category = db.categories.find({'slug':slug}, {'_id':0, 'name':1, 'ancestors.slug':1, 'ancestors.name':1 })
フィールドに一意のインデックスを作成します
slug
。
>>> db.categories.ensure_index('slug', unique=True)
カテゴリーの追加カテゴリー
を追加するには、最初にその祖先を定義する必要があります。新しいカテゴリーを追加します-図に示すように
Swing
、カテゴリーの子孫
Ragtime
として:

祖先を除いて、カテゴリーを追加する操作は非常に簡単です。祖先を配列に追加するには、次の関数を検討してください。
def build_ancestors(_id, parent_id): parent = db.categories.find_one({'_id': parent_id}, {'name': 1, 'slug': 1, 'ancestors':1}) parent_ancestors = parent.pop('ancestors') ancestors = [ parent ] + parent_ancestors db.categories.update({'_id': _id}, {'$set': { 'ancestors': ancestors } })
ツリーを1レベル上に移動し、祖先のリストを取得する
Ragtime
必要があります。これを使用して、祖先のリストを作成できます
Swing
。
次に、ドキュメントを作成し、次の値を設定します。
doc = dict(name='Swing', slug='swing', parent=ragtime_id) swing_id = db.categories.insert(doc) build_ancestors(swing_id, ragtime_id)
新しいカテゴリを追加する操作では、デフォルトのインデックスで
_id
カテゴリの祖先 を変更できます
このセクションでは、ツリーを変更し、カテゴリの
bop
上にカテゴリを配置するプロセスを検討します
swing
。

ドキュメント
bop
を更新して、親の値を変更します。
db.categories.update({'_id':bop_id}, {'$set': { 'parent': swing_id } } )
次の関数は、先祖が保存されているフィールドを再構築します。
def build_ancestors_full(_id, parent_id): ancestors = [] while parent_id is not None: parent = db.categories.find_one({'_id': parent_id}, {'parent': 1, 'name': 1, 'slug': 1, 'ancestors':1}) parent_id = parent.pop('parent') ancestors.append(parent) db.categories.update({'_id': _id}, {'$set': { 'ancestors': ancestors } })
次のループを使用して、すべての子孫を再構築できます
bop
for cat in db.categories.find({'ancestors._id': bop_id}, {'parent': 1}): build_ancestors_full(cat['_id'], cat['parent'])
ancestors._id
更新操作に必要なフィールドのインデックスを作成します。
db.categories.ensure_index('ancestors._id')
カテゴリの名前を変更するカテゴリの名前
を変更するには、カテゴリ自体とすべての子孫の両方を更新する必要があります。
次の図に示すように、カテゴリ「Bop」の名前を「BeBop」に変更することを検討してください

。最初にすることは、カテゴリの名前を変更することです。
db.categories.update({'_id':bop_id}, {'$set': { 'name': 'BeBop' } })
次に、各子孫は祖先のリストを更新する必要があります。
db.categories.update({'ancestors._id': bop_id}, {'$set': { 'ancestors.$.name': 'BeBop' } }, multi=True)
この操作では以下を使用します。
- 位置演算子$は確実に知らないで希望の先祖を見つけます
_id
。 multi
条件の対象となるすべてのドキュメントを更新する必要があることを示すオプション。
この更新用のインデックスは既にあり
ancestors._id
ます。
シャーディング
このコレクションは非常に小さいため、このコレクションをシャーディングほとんどの場合は、制限された値です。シャードが必要な場合、
shard key
フィールドは適切
_id
です。
>>> db.command('shardCollection', 'categories', { 'key': {'_id': 1} }) { "collectionsharded" : "categories", "ok" : 1 }
PS PMに書き込むための文法エラーと翻訳エラーのリクエスト。
使用材料:
エコシステムMongoDB
集約フレームワーク
の オペレーターに関するヘルプハーバーリファレンス「デザインパターン」(ru)のシャーディングに関する記事